TPAMI 2026 | TSF:面向传感器人体行为识别的三重谱融合方法

TPAMI 2026 | TSF:面向传感器人体行为识别的三重谱融合方法

时空探索之旅
发布于 2026-07-03 20:21:45
发布于 2026-07-03 20:21:45
标题: Triple Spectral Fusion for Sensor-based Human Activity Recognition
作者: Ye Zhang, Longguang Wang, Qing Gao, Chaocan Xiang, Mohammed Bennamoun, Yulan Guo
单位:中山大学,重庆大学,西澳大学
📄 论文:https://arxiv.org/abs/2605.02743
🔮IEEE链接:https://ieeexplore.ieee.org/abstract/document/11509656
💻 代码:https://github.com/crocodilegogogo/TSF-TPAMI2026
🔥 关键词:人体活动识别,时间序列,频域融合
TPAMI 2026 | 不用摄像头,也能理解人体行为:TSF 三重频域融合框架解析

点击文末阅读原文跳转本文arXiv链接
序言
基于传感器的人体活动识别(HAR)领域主要利用惯性测量单元(IMU)的姿态、运动及上下文数据来识别日常活动。尽管基于学习的方法已取得诸多进展,但由于异质传感器数据融合过程复杂,且难以建立长期上下文关联,从时间维度开展信息融合仍颇具挑战。
本文研究者提出一种专为人体活动识别设计的新型三谱融合框架(TSF, Triple Spectral Fusion)。首先,研究者开发了一种自适应互补滤波技术以实现噪声抑制,并将每个惯性测量单元的传感器划分为姿态与运动模态节点。鉴于惯性测量单元节点可构成动态异质图,研究者进一步在图傅里叶域内应用自适应滤波,以融合同质与异质节点的信息。此外,本文还采用了自适应小波频率选择方法,用于抑制上下文冗余并缩短特征长度。该方法同时强化了基于时间戳的图聚合效果与长期上下文的关联性。本文所提出的框架在傅里叶域、图傅里叶域与小波域均采用自适应滤波,可实现高效的多传感器融合与上下文关联。在10个基准数据集上开展的大量实验结果,证明了该框架具备优异的性能表现。
1. 论文背景
当手机放进口袋、手表戴在手腕、穿戴设备贴在身体不同位置时,惯导传感器其实一直在记录人体运动的细微变化:加速度、角速度、姿态变化,以及不同身体部位之间的协同关系。基于传感器的人体活动识别要做的,就是从这些看似杂乱的时间序列中,判断用户正在走路、骑车、上下楼、跑步,还是执行某类复杂动作。
这项技术的应用非常广泛:健康监测、运动分析、智能家居、工业作业辅助、康复训练评估等,都需要系统在不依赖摄像头的情况下理解人的状态。与视觉方案相比,传感器方案更保护隐私,也更适合在遮挡、低光、非固定场景中长期运行。
问题在于,传感器数据天然“不干净”:不同 IMU 传感器物理含义不同,噪声类型不同;多个佩戴位置之间既有共性,也有差异;人的活动频率又远低于传感器采样频率,导致长序列中充满冗余。论文提出的三重频域融合框架(TSF, Triple Spectral Fusion)框架,正是围绕这些痛点展开。
2. 论文方法
2.1 之前的方法存在的问题
之前的 HAR 模型,包括时序基础模型,大多沿着时间维度建模:CNN 负责提取局部模式,Transformer 负责建立长期依赖,GNN 则用于描述多传感器之间的关系。这条路线有效,但忽略了三个关键问题。
- IMU 内部的传感器不应被一视同仁。重力计和陀螺仪都与姿态有关,但噪声特性不同;线性加速度计则更直接反映运动变化。
- 多佩戴位置、多模态节点之间既有同质信息,也有异质信息。只做普通图 聚合,容易把有价值的节点差异过度平滑。
- 传感器采样频率往往高于人体活动频率,长序列里存在大量冗余。直接把全部时间点送入Transformer 或 GNN,不仅增加计算量,也会干扰上下文关联。
针对这些问题,TSF 将人体活动识别问题拆解到三个频域空间中处理:在傅里叶视角下抑制 IMU 噪声,在图傅里叶域中融合多传感器节点,在小波域中筛选最有用的时间频带。它不是简单堆叠网络模块,而是把信号处理先验变成可训练、可自适应的深度模型。
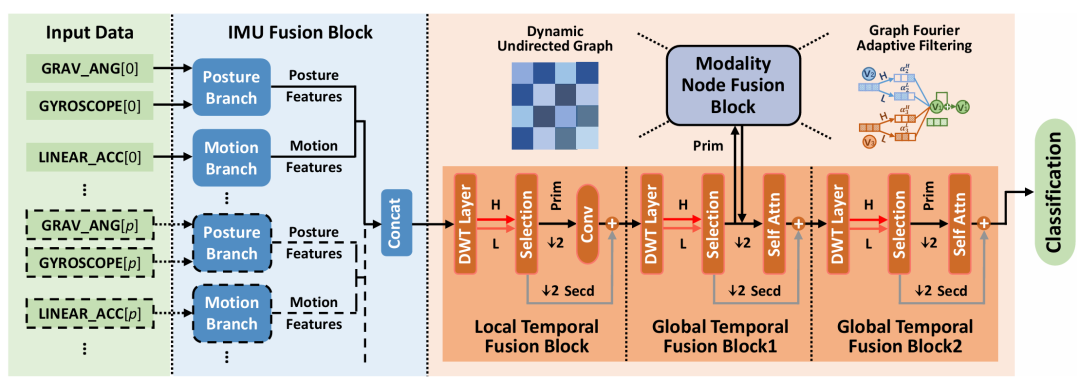
图 1 TSF 总体框架:从 IMU 融合、模态节点融合到时间信息融合,最终完成活动分类
2.2 第一重频域重合:把IMU内部的噪声先处理干净
TSF 的第一步,是重新理解一个 IMU 内部的传感器组合。重力计可以估计姿态角,但容易受到高频噪声影响;陀螺仪短时精度好,却会随时间积分产生低频漂移;线性加速度计则更像是在描述运动强度与速度变化。
论文借鉴无人机姿态估计中常用的互补滤波思想:让重力计走低通滤波,让陀螺仪走高通滤波,再把二者融合为更可靠的姿态信息。不同的是,TSF 没有使用固定参数,而是将互补滤波改造成可学习的神经网络模块。具体来说,宽核因果卷积像一个滑动时间窗口,只保留当前和过去的有效信息,避免未来信息泄漏;姿态传感器注意力则自动学习不同时间点上重力计与陀螺仪的权重。
这样做的价值在于:模型不再被动接受原始 IMU 信号,而是先根据传感器物理特性完成一次“降噪与分工”。姿态信息和运动信息被组织为两个不同的模态节点,为后续跨节点融合打下基础。
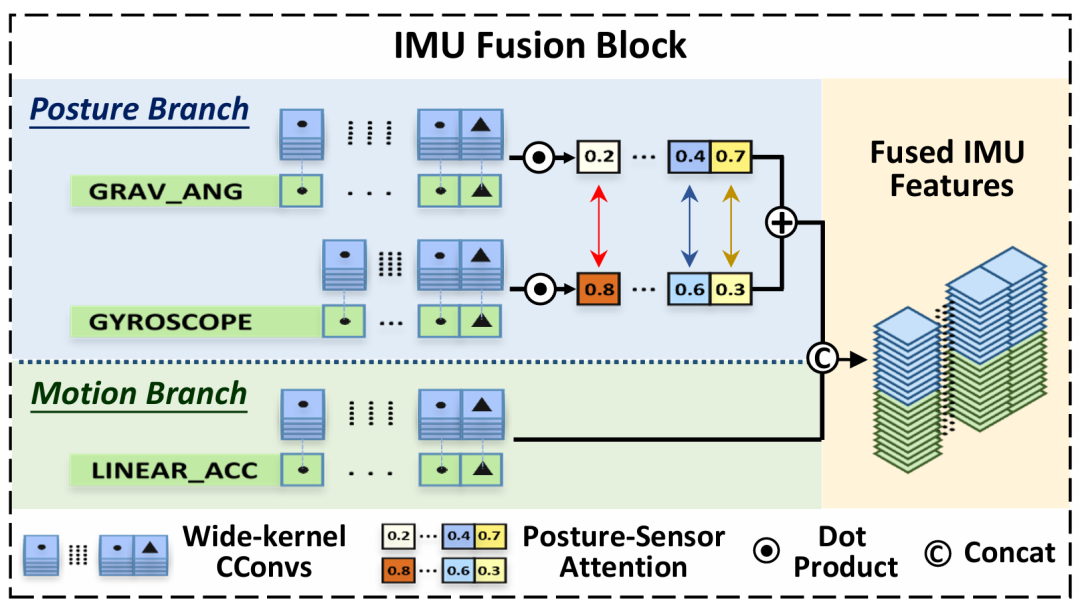
图 2 IMU 融合模块:姿态分支融合重力计与陀螺仪,运动分支处理线性加速度
2.3 第二重频域融合:在图傅里叶域里融合相同点和不同点
TSF 的第一步,是重新理解一个 IMU 内部的传感器组合。重力计可以估计姿态角,但容易受到高频噪声影响;陀螺仪短时精度好,却会随时间积分产生低频漂移;线性加速度计则更像是在描述运动强度与速度变化。
当系统同时使用多个 IMU 或多个身体佩戴位置时,每一个姿态分支、运动分支都可以看作图中的一个节点。传统 GNN 往往倾向于平滑邻居节点,让相似节点更接近;这有助于提取共性,但也可能抹掉对识别很关键的差异。
TSF 的做法更细:它在图傅里叶域中同时设计低通滤波器和高通滤波器。低通滤波器提取节点之间的同质信息,例如多个传感器共同反映“正在跑步”的周期性;高通滤波器保留异质信息,例如某个手臂或腿部节点对区分相似动作特别关键。
更重要的是,图的边权不是固定的。TSF 会根据不同活动、不同受试者、不同时间戳动态学习带符号的邻接矩阵:正权重表示节点更相似,适合保留同质信息;负权重表示节点更不同,适合突出异质信息。这样,模型能根据场景自适应决定“该融合”还是“该保留差异”。
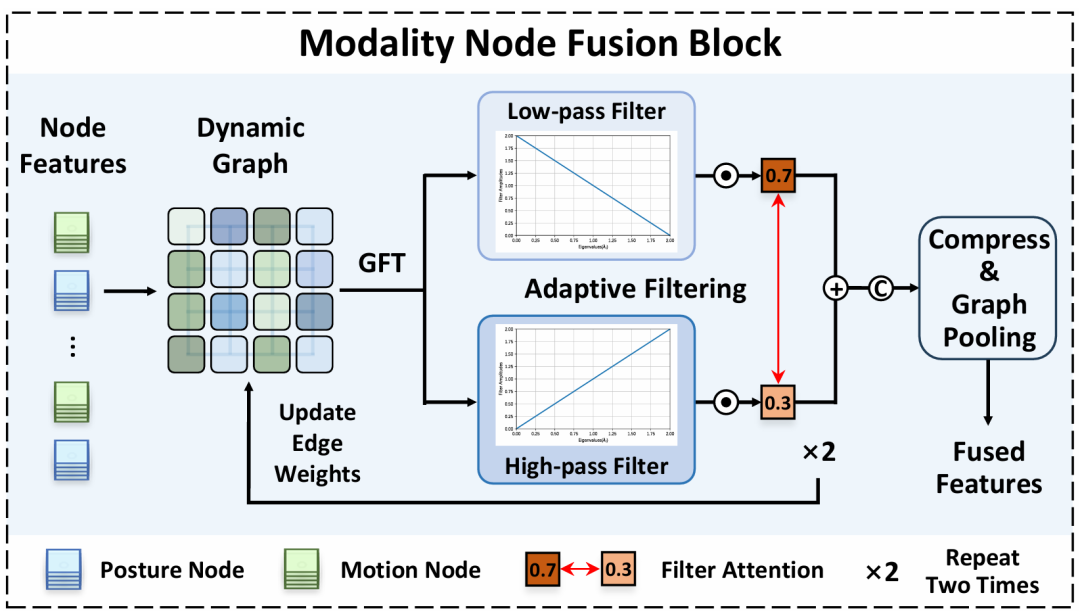
图 3 模态节点融合模块:通过图傅里叶域的低通/高通滤波完成自适应融合
2.4 第三重频域融合:用小波变换把长序列压缩到关键频带
人体活动通常持续数秒到数分钟,而传感器采样率可能达到几十甚至上百 Hz。直接把所有时间点用于上下文建模,不仅计算开销大,而且会让模型在冗余片段中分散注意力。
TSF 引入离散小波变换(DWT),把输入特征分解为低频和高频两个分量,并将长度减半。随后,模型通过 Gumbel-Softmax 机制自适应选择“主频带”:如果当前样本的有效信息主要在低频,就走低频;如果动作变化更快、振动更明显,就保留高频。未被选择的次要分量并不会被简单丢弃,而是作为残差项保留,降低信息损失风险。经过多级小波分解与选择,TSF 可以把特征长度逐步压缩到原来的 1/8,同时仍保留与活动识别最相关的时间-频率结构。这使后续的图聚合和自注意力建模更高效,也更聚焦。
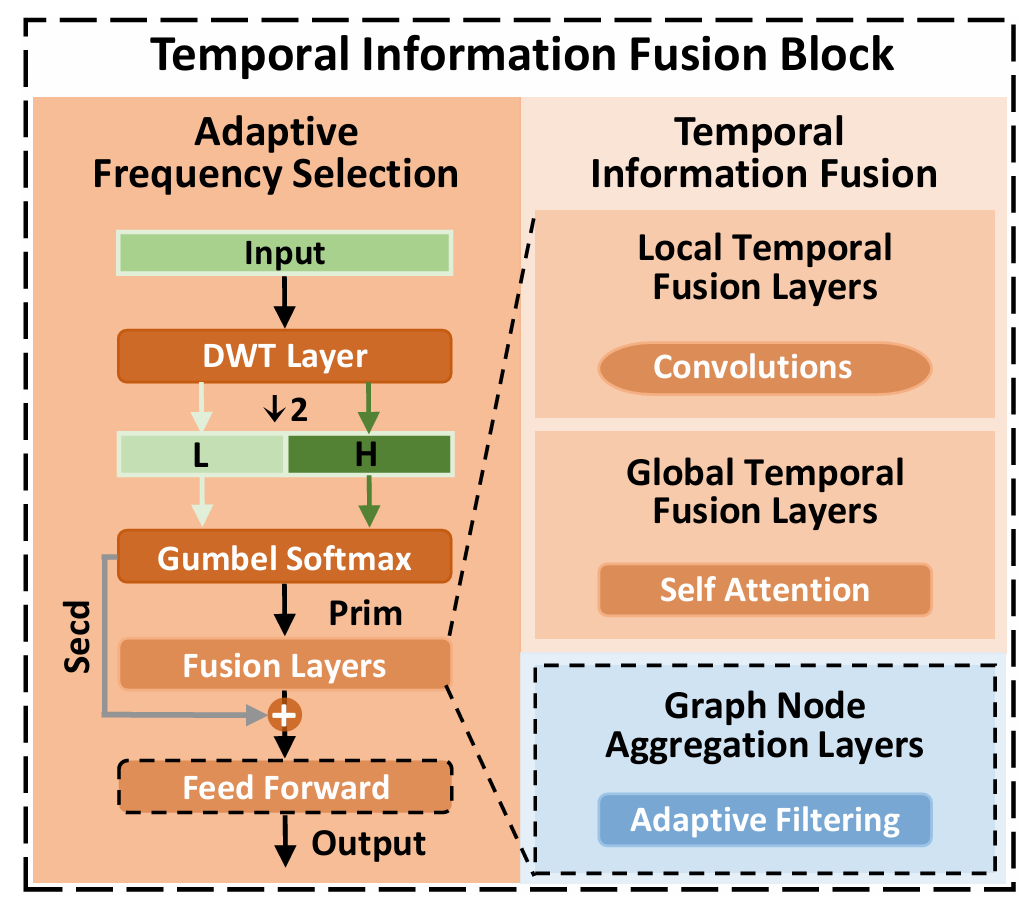
图 4 时序融合模块:DWT 分解后自适应选择主频带,再进行局部卷积、全局自注意力和图节点聚合
3. 实验结果
论文在十个公开 HAR 数据集上进行了实验验证,包括五个手机数据集(HAPT、MotionSense、SHL2018、HHAR、MobiAct)和五个可穿戴设备数据集(Oppo、PAMAP2、DSADS、RealWorld、SHO)。评价指标采用宏平均 F1 与加权 F1,并使用留一受试者交叉验证等策略评估方法的泛化能力。
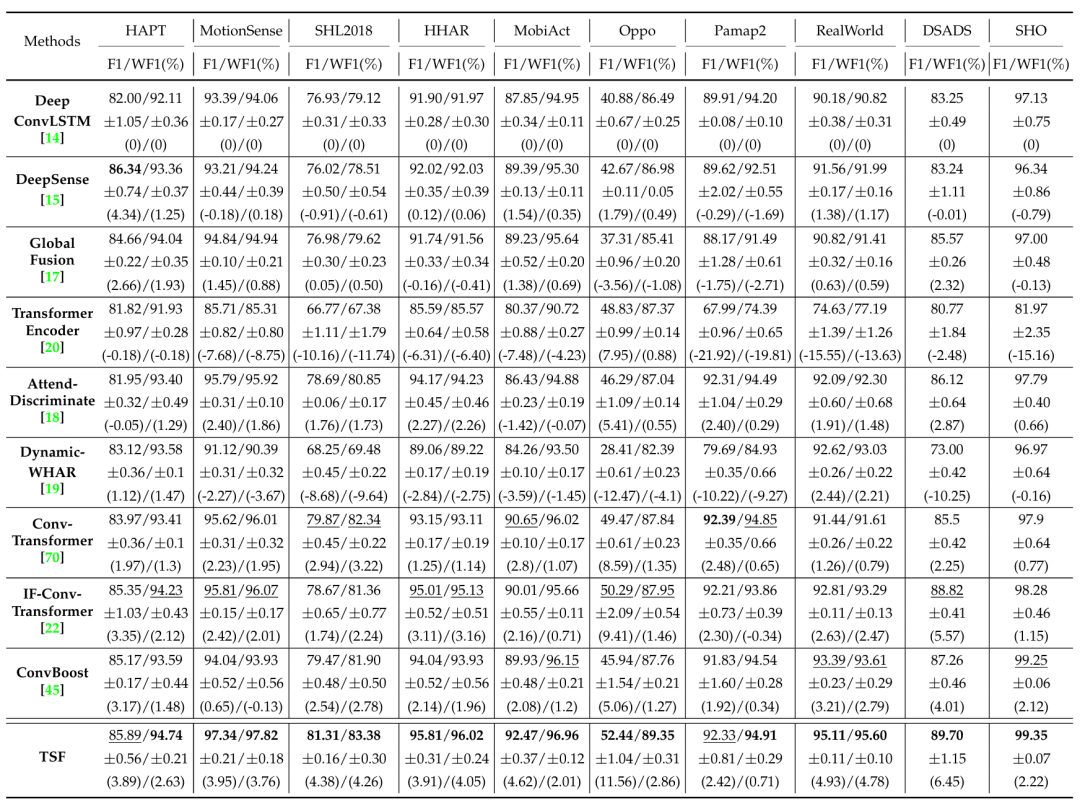
图 5 不同模型的实验结果对比
从结果看,TSF 在几乎所有数据集上取得领先或接近最优的表现。与经典基线 DeepConvLSTM 相比,TSF 在十个数据集上的平均 F1/WF1 从 83.34%/90.41% 提升到 88.18%/93.78%。与其前序工作 IF-ConvTransformer 相比,TSF也从 86.73%/92.47% 进一步提升到 88.18%/93.78%。
4. 从消融与可视化看:TSF 为什么有效?
4.1 IMU 融合模块
消融实验表明,IMU 融合模块对性能提升贡献显著。去掉该模块后,十个数据集的平均 F1/WF1 从 88.18%/93.78% 降至 85.84%/92.11%;使用传统固定参数互补滤波替代自适应设计后,平均性能进一步下降至 84.81%/91.44%。这意味着,传感器物理先验需要与数据驱动学习结合,而不是简单作为静态预处理。
噪声实验也很直观:当输入逐步加入高频或低频噪声时,带有 IMU 融合模块的 TSF 更能保持稳定;注意力权重会随着噪声类型变化而调整,体现出自适应互补滤波的作用。
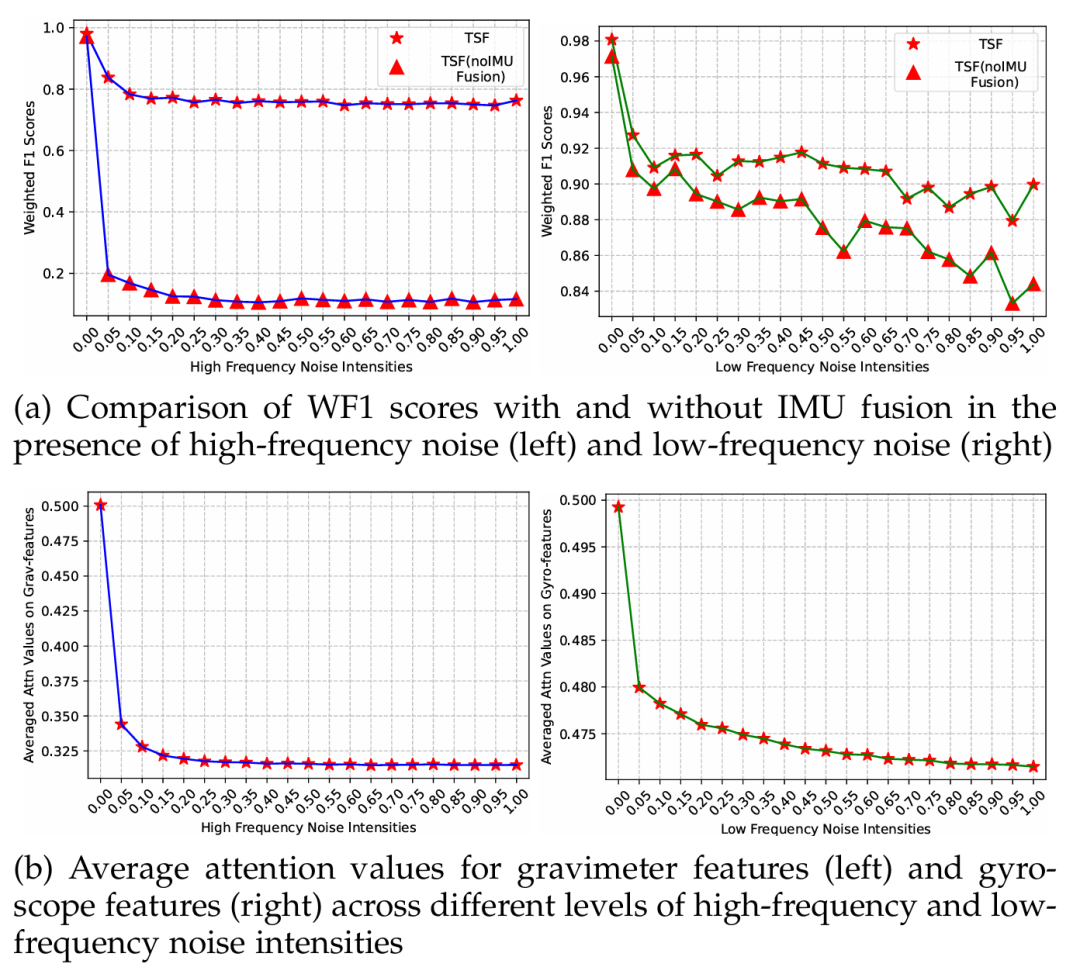
图 6 噪声强度变化下的 IMU 融合模块消融实验结果与姿态传感器注意力变化情况
4.2 模态节点融合模块
将模态节点融合模块替换为 MLP 后,十个数据集的平均 F1/WF1 从 88.18%/93.78% 降至 86.98%/93.14;只保留低通或只保留高通时,分别降至 87.53%/93.25% 和 87.62%/93.29%;把动态邻接图改成静态全连接图后,则降至 87.32%/93.17%。这意味着,人体活动识别既需要提取不同传感器之间的共性,也需要保留姿态节点和运动节点、不同身体位置节点之间的差异;图关系也必须随样本和时间变化而自适应变化。
图傅里叶域的动态边权也提供了可解释性:在固定活动中,不同节点高度相关,模型倾向于提取同质信息;而在更自由、更复杂的活动中,节点差异本身变得重要,模型会通过负边权保留异质信息。这说明 TSF 可以在活动场景中动态选择融合策略。
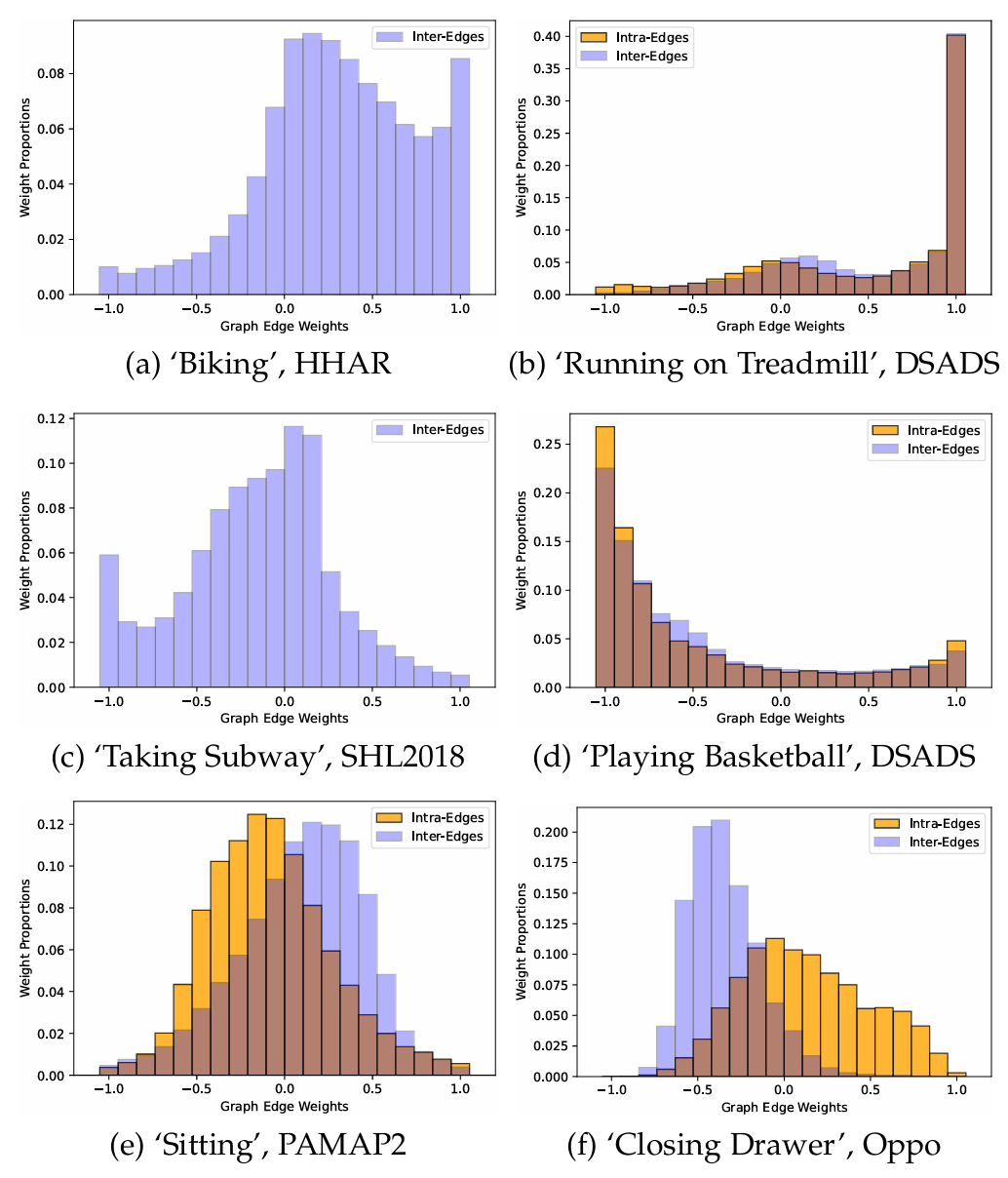
图 7 不同活动场景下的图边权分布,正权重偏向同质融合,负权重偏向异质差异保留
4.3 时频成分选择模块
时频成分选择模块的消融实验结果表明,去掉该模块后,平均 F1/WF1 从 88.18%/93.78% 降至 87.26%/93.05%;如果固定选择低频或高频主分量,分别为 87.68%/93.41% 和 86.21%/92.65%;用普通池化替代则降至 86.61%/92.43%。
这说明,大多数人体活动确实偏低频,但不能简单固定低频,更不能把小波选择等同于普通下采样。可视化分析进一步说明,模型会根据不同人、不同动作、不同重复试次选择不同的分解路由。动作较快或周期波动更明显的样本更可能选择包含高频的路径,而较平稳的样本更偏低频路径。这样,TSF 在进入图聚合和自注意力前,先判断“有效信息在哪个频带”,既减少冗余计算,也提高上下文建模的针对性。
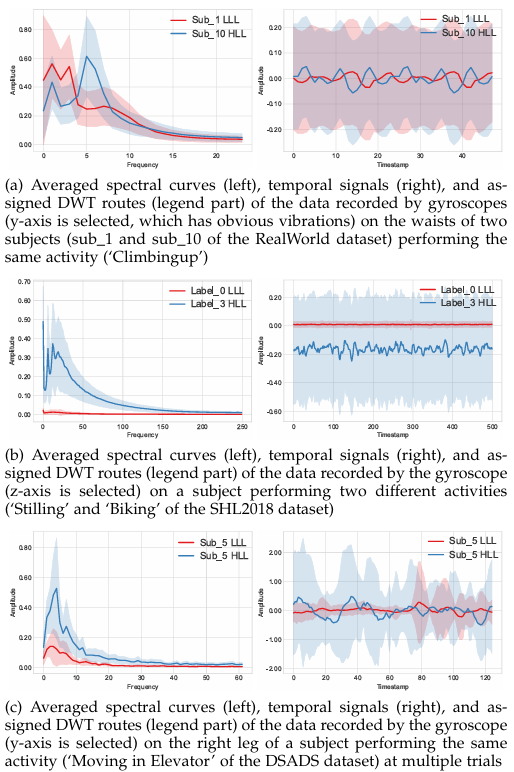
图 8 自适应时频选择路由可视化:不同受试者、动作类别会形成不同的低频/高频选择路径
5. 总结
人体活动识别看似是一个分类问题,背后却牵涉信号噪声、传感器结构、身体运动规律和长时序上下文。该工作的价值不只在于性能提升,更在于展示了一种新的建模思路:将传统信号处理中的频域滤波、小波分解、图谱分析转化为可训练模块,并与深度学习端到端联合优化。这使得 TSF 既有信号处理的可解释性,又有深度学习的自适应能力。这种“物理先验+自适应学习”的路线,可能会成为传感器智能的重要方向。
从 “传感器记录了什么”,到 “系统理解了什么”,TSF 向前迈出了一步。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号