什么是Transformer ?现代 AI 的“数字大脑”

什么是Transformer ?现代 AI 的“数字大脑”

jeffery_jcm
发布于 2026-06-26 11:08:27
发布于 2026-06-26 11:08:27
Transformer 是由 Google 在 2017 年的论文《Attention is All You Need》中提出的。它彻底改变了机器处理语言的方式,也是如今 ChatGPT、Claude 和各种大语言模型(LLM)的底层架构。
核心是完全摒弃传统的循环神经网络(RNN)和卷积神经网络(CNN),转而提出一种仅仅依赖注意力机制(Attention Mechanism)的简单网络架构来建立输入序列和输出序列之间的全局依赖关系。
Transformer与传统循环神经网络RNN及卷积神经网络CNN在序列建模差异:

1. 核心革命:从“串行”到“并行”
在 Transformer 出现之前,主流模型(如 RNN)处理文字就像听电话:必须听完第一个词,才能听第二个词。如果你说一句话有 100 个词,模型就得按顺序处理 100 次,速度慢且容易忘掉开头的细节。
Transformer 就像是看照片:它一眼就能看到整段文字。这种“全局视野”带来了两个巨大的优势:
- 并行计算:可以同时处理所有单词,训练速度极快。
- 长距离依赖:无论第一个词和最后一个词隔多远,模型都能直接关联它们。
2. 三大核心组件
Transformer 的精妙之处在于它通过三个绝妙的设计解决了语言理解的难题。
A. 自注意力机制 (Self-Attention) —— “划重点”
这是 Transformer 的灵魂。它让每个词在处理时,都会去询问句子中其他的词:“你和我有什么关系?”
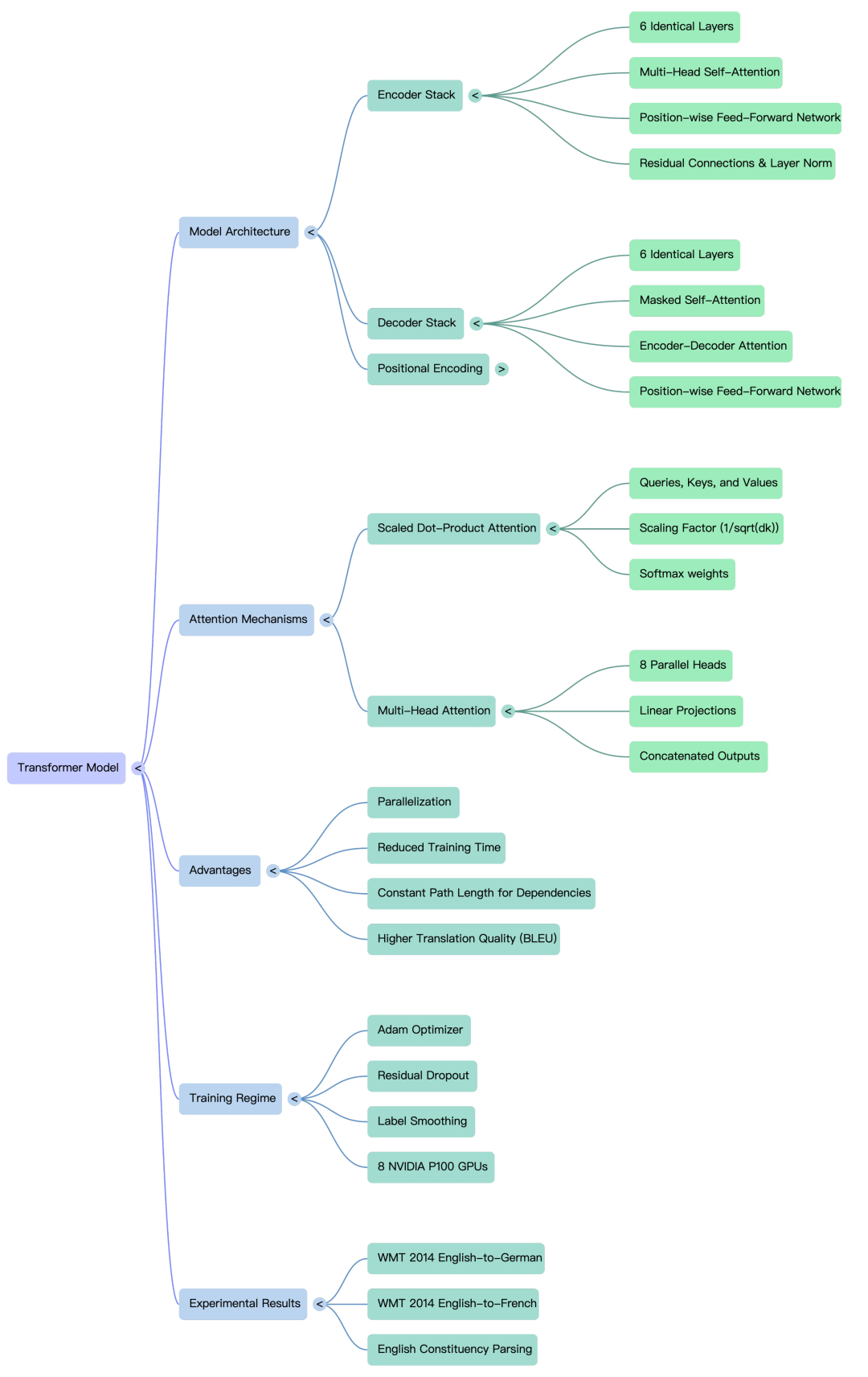
架构设计Transformer采用了经典的编码器-解码器(Encoder-Decoder)结构,但内部构件完全由堆叠的自注意力层和全连接层组成
- 编码器(Encoder): 由6个完全相同的层堆叠而成。每一层包含两个子层:一个是多头自注意力(Multi-Head Self-Attention)机制,另一个是基于位置的简单全连接前馈网络。每个子层输出后都加入了残差连接(Residual Connection)和层归一化(Layer Normalization)
- 解码器(Decoder): 同样由6个相同的层组成。在编码器的两个子层基础之上,解码器增加了一个多头注意力子层,用于对编码器的输出进行注意力计算。此外,解码器中的自注意力子层引入了掩码(Masking)机制,以防止当前位置关注到后续位置的信息,从而确保模型生成过程遵循自回归特性
- 注意力机制: 架构依赖缩放点积注意力(Scaled Dot-Product Attention)。为了防止在维度较大时点积数值过大导致Softmax函数梯度极小,模型通过除以维度的平方根来进行缩放。模型还使用了多头注意力(Multi-Head Attention),允许模型在不同位置联合关注来自多个不同表示子空间的信息
- 位置编码(Positional Encoding): 由于模型自身没有循环和卷积结构,为了让模型理解序列中词语的相对或绝对位置,在底部的输入和输出嵌入层中加入了基于正弦和余弦函数的位置编码
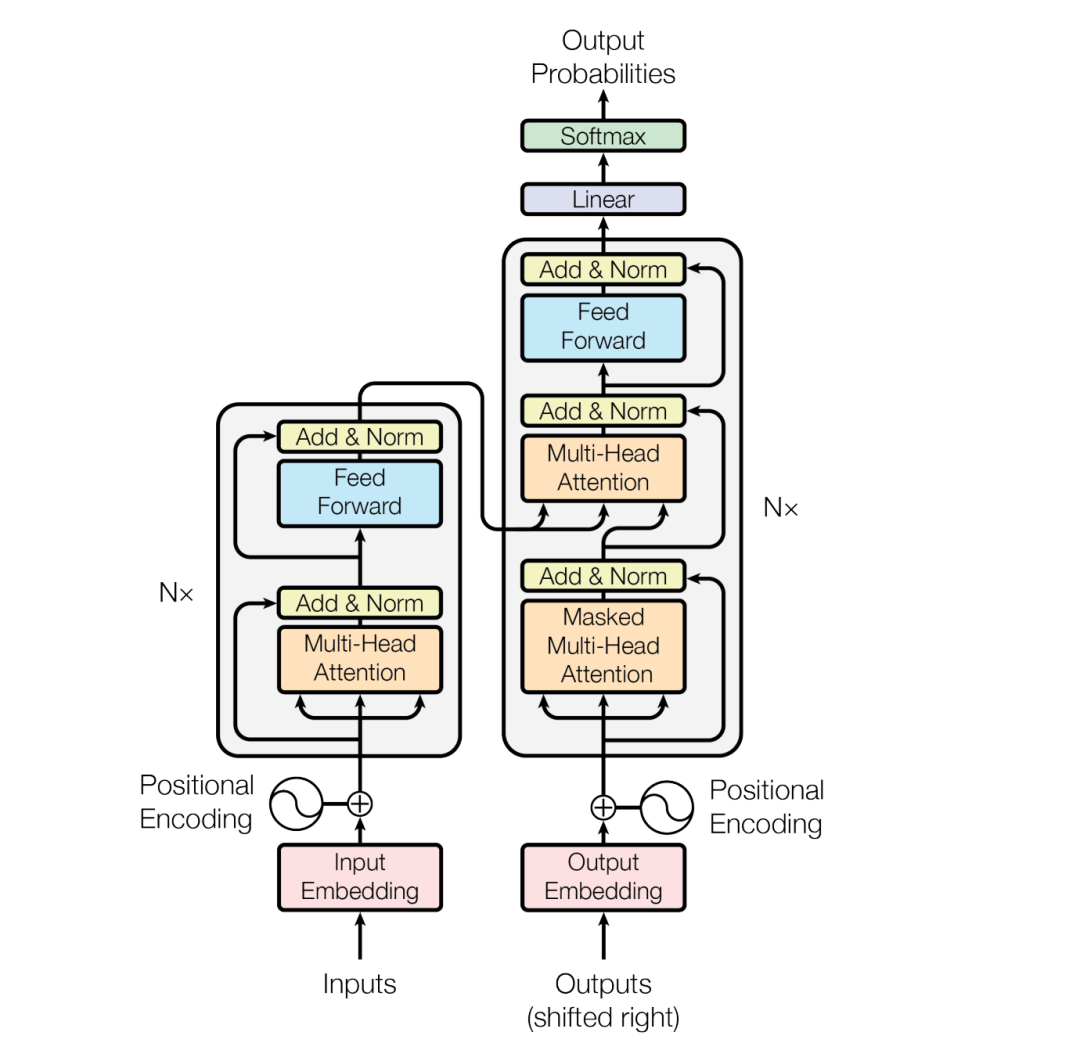
Transformer —— 模型架构
自注意力机制:Transformer 架构的灵魂
Transformer 的核心创新在于缩放点积注意力(Scaled Dot-Product Attention),其设计灵感可以追溯到信息检索系统 。在该机制中,输入的每个 Token 都会被映射为三个不同的向量:查询向量(Query, Q)、键向量(Key, K)和值向量(Value, V)
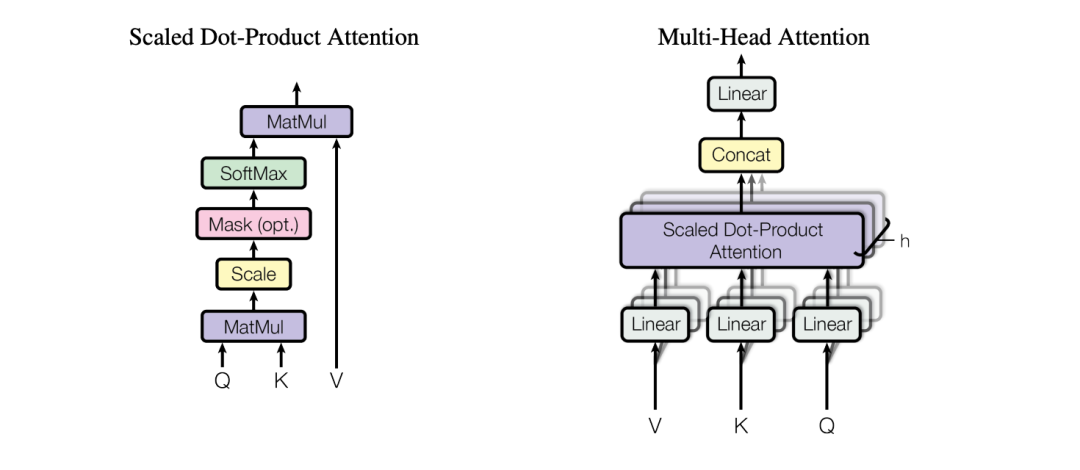
(左)缩放点积注意力。(右)多头注意力由多个并行运行的注意力层组成。
模型会为每个词计算三个向量:
- 查询向量 (Query, Q):我想找什么?
- 键向量 (Key, K):我能提供什么?
- 值向量 (Value, V):我的实际内容是什么?
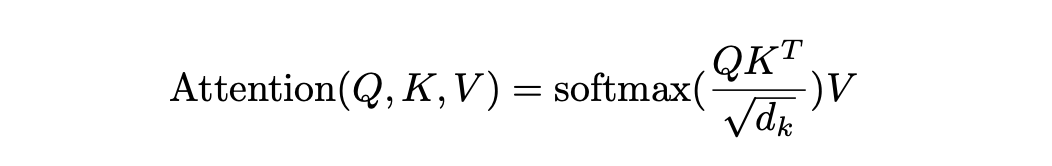
类比:就像在一场社交舞会上,你想找会跳探戈的人(Q)。你观察每个人的名牌(K),发现只有张三名牌写着“探戈高手”。于是你走向张三,获取了他的跳舞技能(V)。
B. 多头注意力 (Multi-Head Attention) —— “多角度观察”
如果只用一组Q, K, V,模型可能只关注语法。但语言是复杂的,我们需要同时关注:
- 这一对词是否有指代关系?
- 它们是否是主谓关系?
- 它们的情感色彩是否一致?
“多头”意味着模型同时开启多组注意力机制,就像派出了 8 个或 12 个观察员,有的盯着语法,有的盯着语义,最后汇总信息。
C. 位置编码 (Positional Encoding) —— “给单词编号”
既然 Transformer 是“一眼看完”整句话,它就会丢失单词的先后顺序(“狗咬人”和“人咬狗”在它看来是一样的)。
为了解决这个问题,研究者给每个单词注入了一个位置标签。这个标签不是简单的 1, 2, 3,而是使用正弦和余弦函数生成的独特信号,让模型既知道词的绝对位置,也能感知词与词之间的相对距离。
3. 宏观结构:编码器与解码器
三类主流 Transformer 架构的差异及其典型代表
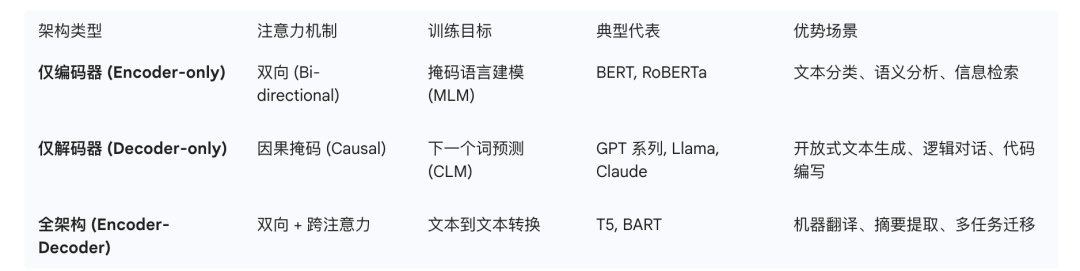
传统的 Transformer 由两大部分组成:
- 编码器 (Encoder):负责“阅读理解”。它把输入的句子(比如英文)转化为一种高维的、充满语义信息的数字表示。
- 解码器 (Decoder):负责“表达输出”。它参考编码器的信息,并结合自己已经生成的词,预测下一个词该说什么(比如翻译成中文)。
注意:现在的 GPT 系列模型通常只使用“纯解码器”架构,而 BERT 则只使用“纯编码器”架构。
4. 运行流程图解
如果你向 Transformer 输入一句话,它会经历以下步骤:
- 词嵌入 (Embedding):把单词变成一串初始数字。
- 加上位置信息 (Positional Encoding):让数字带上顺序感。
- 进入多层堆叠块:
- 自注意力层:理解上下文。
- 残差连接与归一化:防止神经网络太深导致信息丢失(类似于“划重点后还要看原稿”)。
- 前馈神经网络 (Feed Forward):对每个词的信息进行深度加工。
- 输出预测:算出下一个词出现的概率分布。
5. 为什么它改变了世界?
- 可扩展性 (Scalability):只要增加层数和参数,它的性能就会不断提升,没有明显的上限。
- 通用性:它不仅能处理文字,现在也被证明能处理图像 (Vision Transformer)、音频甚至蛋白质序列。
- 涌现能力:当模型变得足够大时(如 GPT-4),它开始表现出类似推理、编程和逻辑思考的能力。
验证方法:
- 机器翻译任务基准测试: 在标准的英语到德语(English-to-German)和英语到法语(English-to-French)翻译任务上评估模型的翻译质量(BLEU分数)以及训练的计算成本(FLOPs),并与现有的最先进模型(包括单模型和集成模型)进行严格对比
- 模型消融实验(Model Variations): 通过系统地改变基础模型的各项参数(如注意力头的数量、键/值维度大小、模型深度、丢弃率、位置编码方式等),在开发集上测试成绩变化,以此验证Transformer各个组件的必要性和最佳配置
- 泛化能力验证: 将该模型应用于输出受强结构约束且序列比输入更长的**英语成分句法分析(English Constituency Parsing)**任务,分别在大规模数据和有限数据条件下测试其表现,以证明模型不仅局限于机器翻译,还能很好地泛化到其他序列转换任务
多模态:
Transformer 架构天生适合处理不同模态的数据对齐。CLIP 模型利用两个独立的 Transformer 编码器(一个视觉,一个文本),通过对比学习将它们映射到一个统一的语义空间 。在这种共享空间内,一幅“狗在草地上跑”的图像与这句话的文本向量会自然地靠拢,而与“汽车”的向量远离 。这种统一的表征方式不仅赋能了零样本(Zero-shot)图像分类,也成为了后续 DALL-E 等图像生成模型的核心灵魂 。
Transformer 架构自 2017 年诞生以来,已经从一个简单的翻译模型进化为现代人工智能的“通用处理器”。它的成功并非偶然,而是其核心设计理念与现代计算硬件发展趋势完美契合的结果:全自注意力的并行性解决了训练速度问题,残差连接与层归一化解决了深度堆叠问题,而缩放定律则揭示了模型表现随资源投入而单调提升的宏观规律 。
从理解人类语言到解析视觉信号,再到跨模态的创意生成,Transformer 展示了其作为一种通用计算范式的巨大潜力 。尽管目前仍面临着平方复杂度开销、数据质量瓶颈以及能效比挑战,但诸如 FlashAttention、RoPE 和混合专家架构(MoE)等创新技术的不断涌现,正在持续拓宽这一架构的边界 。在可预见的未来,Transformer 及其演进版本仍将是通往更高级别人工智能——乃至人工通用智能(AGI)——的核心路径
《Attention Is All You Need》https://arxiv.org/abs/1706.03762
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号