别再手动Prompt了——Loop Engineering让AI Agent自己干活

别再手动Prompt了——Loop Engineering让AI Agent自己干活

老周聊架构
发布于 2026-06-19 09:14:20
发布于 2026-06-19 09:14:20
"Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead." —— Addy Osmani
你有没有过这种体验:
晚上临睡前,给Claude Code说"帮我把这个Issue修了",然后设个闹钟,半夜起来看一眼结果,发现Agent跑偏了,再调一下prompt,再睡……
恭喜你,你已经在做Loop Engineering了——只不过你自己就是那个Loop。
2026年,AI Engineering领域最热的词不再是Prompt Engineering,也不是Context Engineering,而是Loop Engineering——设计一个系统,让AI Agent在你睡觉的时候自己发现工作、执行任务、验证结果、提交PR。
今天这篇文章,把Loop Engineering从概念到实战讲透。
一、从Prompt到Loop:AI工程的四次范式进化
先回顾一下我们是怎么走到这一步的:
2023年:Prompt Engineering —— 一切的起点。那时候我们研究的是"怎么写好一句话让GPT输出更准"。Chain-of-Thought、Few-shot、角色扮演……本质上是优化单次人机交互。
2025年:Context Engineering —— 当Agent需要处理的信息越来越多,单次prompt不够用了。RAG、记忆系统、工具集成……本质上是优化输入给模型的信息。Tobi Lutke(Shopify CEO)说:"Context engineering is the art of curating what goes into the limited context window."
2025-2026年:Harness Engineering —— 当Agent开始执行真实操作(写文件、调API、跑测试),光优化信息不够了,还需要一个确定性的运行时层来管控权限、预算和安全。本质上是优化执行环境。
2026年:Loop Engineering —— 终极进化。你不再是那个"按回车"的人。你设计一个自动循环系统,它自己发现工作、自己执行、自己验证、自己决定继续还是停止。本质上是优化整个工作流程。
一句话总结这四次进化的方向:从"你操作模型"到"系统自动操作模型"。
二、Loop Engineering到底是什么?
2.1 核心定义
Loop Engineering = 设计AI Agent的自主工作循环。
传统的Agent使用方式是:你发一条prompt → Agent回复 → 你看结果 → 你再发一条prompt → ……你是循环的一部分。
Loop Engineering的做法:你设计一个程序,它自动发现任务、组装prompt、调用Agent、检查结果、决定下一步——你不在循环里。
用Addy Osmani的话说:
"You write a small program that handles discovery, planning, execution, verification, and iteration, and the loop calls the model on a schedule until a stopping condition is met."
2.2 核心循环:Act → Observe → Reason → Repeat
所有Loop都遵循同一个四步模式:
- Act(行动)—— Agent执行任务(写代码、调API、查数据)
- Observe(观察)—— 系统读取执行结果(测试通过了吗?CI绿了吗?)
- Reason(推理)—— 对比目标判断:完成了?还是需要修正?
- Repeat(重复)—— 没达标就继续,达标就停止
关键区别在最后一步:传统方式是人来判断"继续还是停",Loop Engineering是系统自动判断。
2.3 两个必要条件
在你设计任何Loop之前,先检查两个前提:
条件一:触发器(Trigger)—— 什么启动这个Loop?定时任务?PR事件?CI失败?Slack消息?没有触发器的Loop需要你手动启动——那你还是在Loop里。
条件二:可验证的目标(Verifiable Goal)—— 怎么判断"完成了"?测试全绿?TypeCheck通过?Reviewer Agent批准?
如果你的任务没有可验证的目标——
"You did not build a loop. You built a very confident token furnace."
你造的不是Loop,是一台自信满满的Token焚烧炉。
三、五大核心组件

3.1 Automations(自动触发)
Loop的起点。定义了"什么时候开始干活"。
实际做法:
- Cron定时任务:每天早上6点扫描昨日CI失败和新Issue
- GitHub Actions:PR创建时自动触发代码审查Loop
- Webhook:Slack消息触发任务分配Loop
Claude Code支持/loop命令(基于节奏的重复运行)和/goal命令(运行直到条件满足)。Codex有Automations Tab,可以设定项目+prompt+运行频率。
3.2 Worktrees(并行隔离)
当你想让多个Agent同时处理不同任务时,它们不能都在同一个工作目录里操作——会互相覆盖文件。
Git Worktree解决这个问题:为每个任务创建一个独立的工作目录副本,每个Agent在自己的副本里干活,互不干扰。
这是Loop从"单线程"扩展到"多线程"的关键基础设施。没有Worktree,你的Loop就只能一个接一个地串行处理任务。
3.3 Skills(技能复用)
如果Agent每次运行都要从零开始理解你的项目——构建命令是什么?测试怎么跑?代码风格什么规范?——那每次都要浪费大量Token。
SKILL.md文件把这些知识编码下来。一个Skill包含:
- 项目构建和测试命令
- 代码风格和架构约定
- 已知的坑和绕过方法
- 常用工具和配置
Skills是Loop的知识积累机制。 每次运行学到的新规则,写进Skill,下次运行就不用重新学。这是Loop越跑越好的关键。
3.4 Connectors(外部连接)
Loop如果只能读写文件,那它就是一个高级脚本。真正有用的Loop需要能操作真实环境:
- GitHub:创建PR、评论Issue、触发CI
- Linear/Jira:更新任务状态、移动看板
- Slack:发通知、接收指令
- 数据库/API:查询数据、调用服务
MCP(Model Context Protocol)是目前最主流的连接方式——标准化的工具接口协议,让Agent能直接调用外部工具。
3.5 Sub-agents(分工协作)
最重要的原则:写代码的Agent和审代码的Agent必须是两个Agent。
为什么?因为让一个Agent给自己的代码打分,结果一定是"写得太好了"。这是人性——不,AI性。
实践中的分工:
- Writer Agent(用强模型,如Opus/Fable 5):写代码、做修改
- Reviewer Agent(可以用便宜模型,如Sonnet/Haiku):审查代码、跑测试、对比规范
Reviewer不需要和Writer一样强。它的工作不是"写出更好的代码",而是"检查这段代码是否满足标准"。这意味着你可以用更便宜的模型做Review,大幅降低成本。
四、Open Loop vs Closed Loop
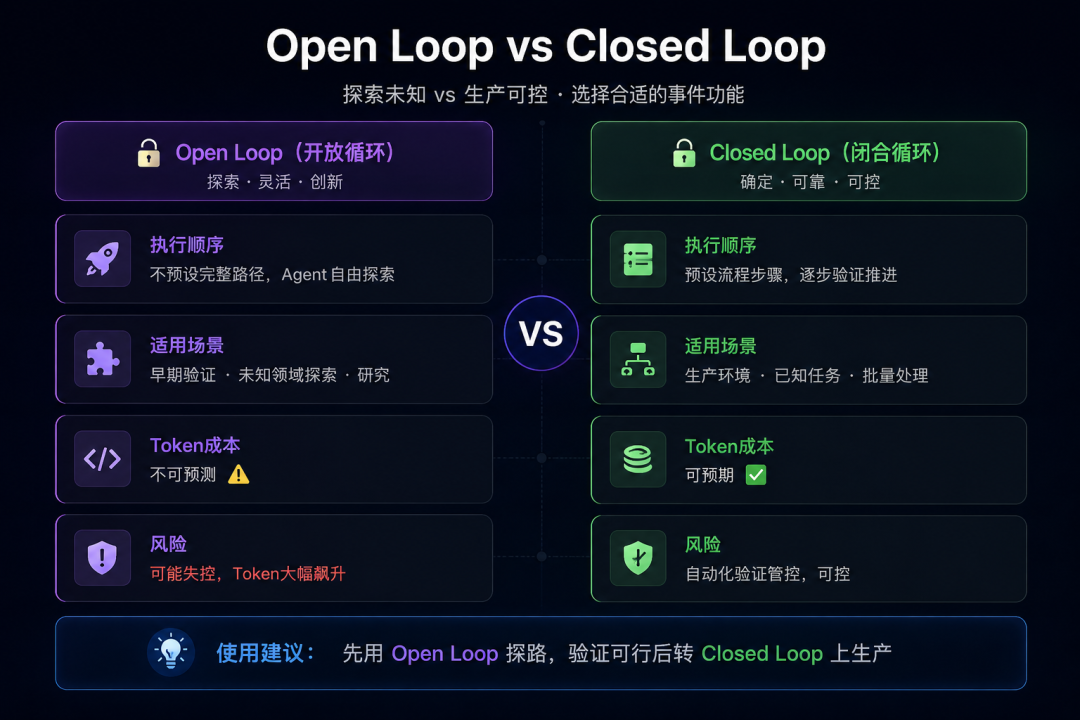
4.1 Open Loop:探索型
不预设完整路径,给Agent一个大方向,让它自己探索。
适用场景:你不确定需要做什么(原型验证、未知领域调研、"帮我看看这个代码库有什么问题")。
优点:可能发现你没想到的问题和方案。
缺点:Token成本不可预测。一个没刹车的Open Loop,一晚上能烧掉你一个月的API预算。
4.2 Closed Loop:生产型
预设完整步骤,每步都有验证标准,通过才进入下一步。
适用场景:明确知道要做什么(修特定Bug、跑固定流程、批量处理同类任务)。
优点:成本可控、结果可预测、适合无人值守。
缺点:灵活性差,遇到预设之外的情况会卡住。
老周的建议:先用Open Loop探路,验证可行性。然后把验证过的路径固化成Closed Loop上生产。
五、三大风险:你的Loop需要刹车
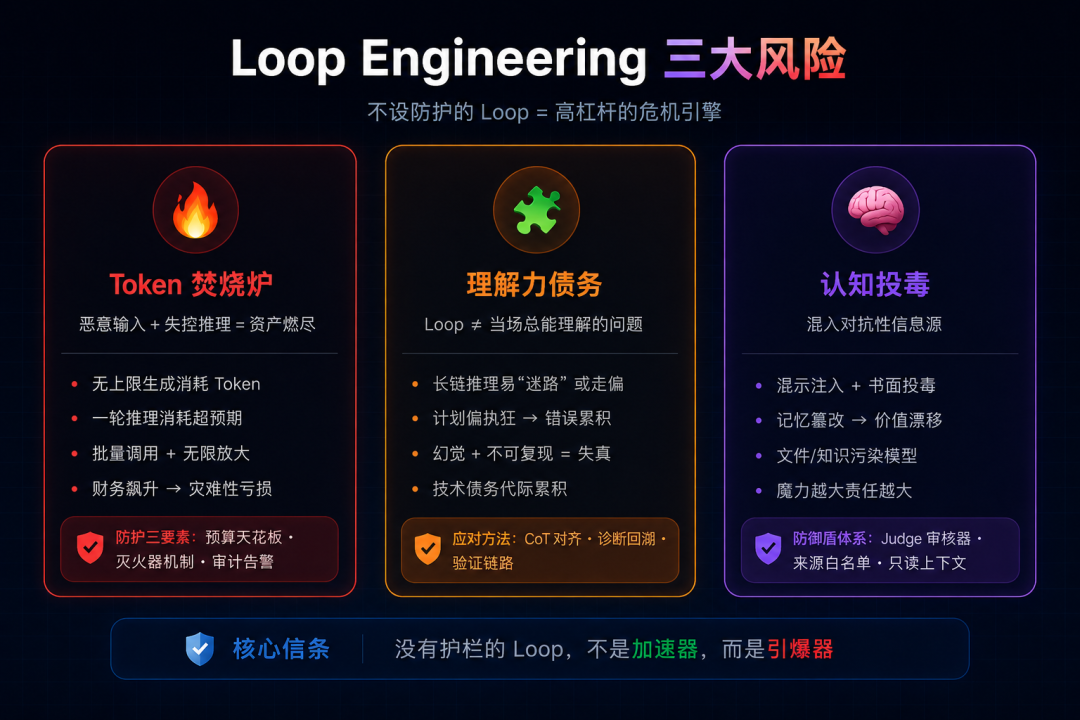
5.1 Token焚烧炉
这是最直接的风险。
没有停止条件的Loop会无限运行。如果目标定义模糊(比如"让代码更好"),Agent会永远觉得还能"更好一点"——然后你一觉醒来发现账单上多了四位数。
必须设置的三个刹车:
- 迭代上限:最多跑N次就停
- 预算天花板:最多花X美元就停
- 无进展检测:如果连续3次迭代没有实质性变化,停
1 // 伪代码:Loop的基本安全机制
2 const MAX_ITERATIONS = 10;
3 const MAX_COST_USD = 5;
4 let noProgressCount = 0;
5
6 while (!goal.isMet() && iterations < MAX_ITERATIONS && cost < MAX_COST_USD) {
7 const result = await agent.run(task);
8 if (!hasProgress(result, lastResult)) {
9 noProgressCount++;
10 if (noProgressCount >= 3) break; // 无进展,停
11 } else {
12 noProgressCount = 0;
13 }
14 iterations++;
15 }5.2 理解力债务(Comprehension Debt)
Loop跑得越快,你没写过的代码就积累得越快。
这是传统"技术债"的AI加速版:代码量增长的速度远超你理解代码的速度。某天你需要debug一个问题,发现这段代码是Loop三周前在你睡觉时写的,你完全不知道它在干什么。
应对方案:
- 强制Code Review——Loop开的PR,人必须看
- 保持Diff级别的理解——不需要逐行,但要知道每次改了什么、为什么
- 定期"理解力审计"——随机抽查Loop产出的代码,确保你还能解释它
5.3 认知投降(Cognitive Surrender)
这是最隐蔽的风险。
用Loop逃避思考,和用Loop放大思考,做的是同一个动作,但结果完全相反。
放大思考:你深入理解问题,设计精确的验证标准,用Loop自动化执行部分——你的判断力被放大了。
逃避思考:你不想理解问题,把一切都扔给Loop,期待它自己搞定——你的能力在退化。
判断标准很简单:如果你能向别人解释清楚你的Loop为什么这么设计,你就是在放大思考。如果你说不清楚,你就是在逃避。
六、实战案例:每日自动修Bug
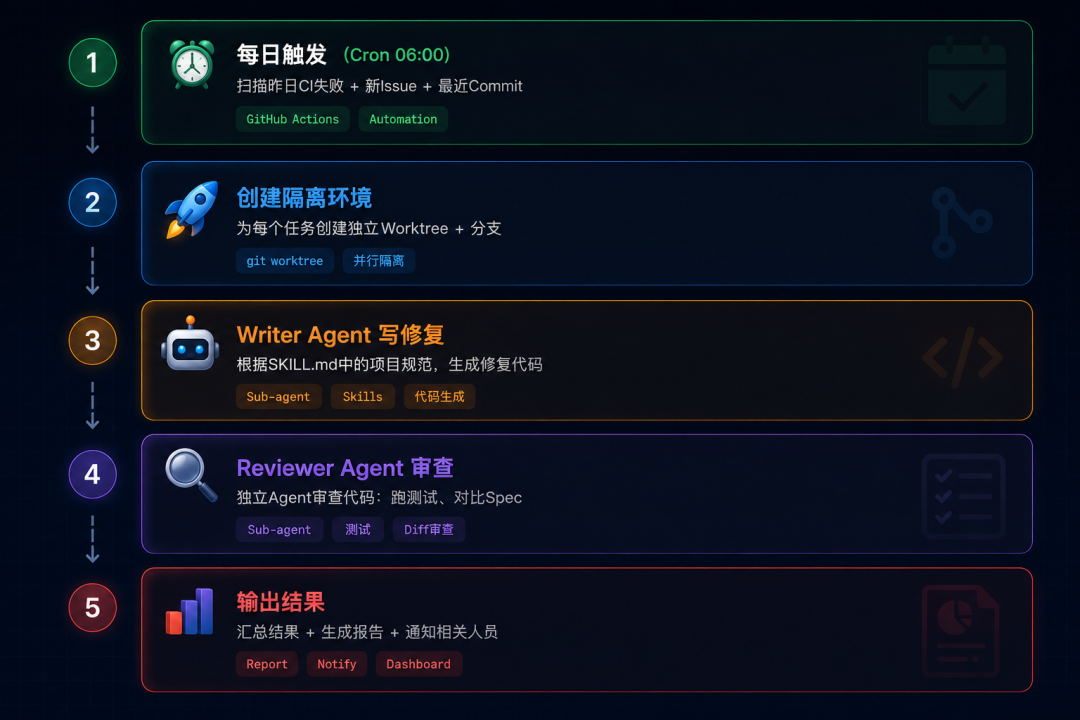
让我用一个具体场景展示Loop Engineering的实际运作:
6.1 场景描述
你的团队有一个中等规模的代码仓库,每天会产生一些CI失败和新Issue。你想让一个Loop每天自动处理其中的简单任务。
6.2 Loop设计
1 触发器:每日早6:00 Cron
2 目标:修复昨日CI失败 + 处理标记为"good-first-issue"的Issue
3 停止条件:所有任务处理完 OR 迭代超过20次 OR 花费超过$106.3 执行流程
Step 1 — 发现工作
Automation触发后,通过GitHub API扫描:
- 昨日失败的CI Workflow
- 标签为
good-first-issue的新Issue - 最近Commit引入的lint错误
产出一个任务列表,写入状态文件loop-state.md。
Step 2 — 创建隔离环境
为每个任务创建独立的Git Worktree:
1 git worktree add ../fix-ci-123 -b fix/ci-123
2 git worktree add ../fix-issue-456 -b fix/issue-456多个任务可以并行处理,互不干扰。
Step 3 — Writer Agent执行修复
Writer Agent读取SKILL.md了解项目规范,然后:
- 分析失败原因(读CI日志)
- 生成修复代码
- 本地运行测试确认修复有效
Step 4 — Reviewer Agent验证
独立的Reviewer Agent(可以用更便宜的Sonnet模型):
- 检查代码是否符合项目规范
- 确认测试全绿
- 对比Diff和Issue描述,确认修复了正确的问题
Step 5 — 输出结果
- 验证通过 → 自动创建PR,发Slack通知
- 验证失败 → 放入Triage Inbox,等待人工处理
- 更新
loop-state.md,记录已处理的任务
6.4 效果
每天早上打开电脑,2-3个PR已经在等你Review了。简单的lint修复、依赖更新、test fix,Loop已经自动处理了。你只需要看一眼Diff,确认没问题,点Merge。
你从"写修复代码的人"变成了"Review修复代码的人"。 杠杆倍率:至少3-5倍。
七、Loop Engineering三大判断标准
在你兴奋地开始设计Loop之前,先问自己三个问题:
问题一:这个任务重复吗?(Repetitive)
如果一个任务只会做一次,直接prompt就行了。Loop的投入(设计触发器、写Skill、设验证标准)只有在任务反复出现时才有回报。
问题二:成功标准可验证吗?(Reviewable)
"测试全绿"是可验证的。"代码写得好"不是。如果你说不清"什么算完成",这个任务不适合Loop。
问题三:值得投入吗?(Valuable)
设计一个Loop需要时间。如果任务每次只花5分钟、每月才出现一次,直接手动做可能更划算。Loop适合频繁出现的、有明确标准的、有足够价值的任务。
三个条件都满足,上Loop。缺任何一个,直接prompt。
八、Claude Code和Codex的Loop能力
目前两个主流的Coding Agent平台都原生支持Loop Engineering:
Claude Code提供:
/loop—— 基于节奏的重复运行/goal—— 运行直到条件满足(模型判断终止)- Hooks —— 生命周期事件回调
- 定时任务 + GitHub Actions集成
- Worktree隔离 + Sub-agent支持
Codex提供:
- Automations Tab —— 项目+prompt+频率配置
- Triage Inbox —— 未处理任务收集
- Agent Skills —— 用
$name调用 - TOML配置Sub-agents
- Connector集成
重要发现:两个平台的底层原语是相同的——Automations、Worktrees、Skills、Connectors、Sub-agents。这意味着你的Loop设计不依赖于具体平台,可以在两个平台之间迁移。
写在最后
Loop Engineering的本质不是"让AI干更多活",而是改变你和AI的关系。
以前你是操作员——坐在键盘前,一条一条发指令。
现在你是架构师——设计循环、定义标准、部署系统,然后去做更有价值的事。
但这里有一条红线:你必须始终是那个理解系统的人。
Addy Osmani说得好:Loop Engineering比Prompt Engineering难,因为它迫使你做判断——什么应该自动化,什么需要人工Review。如果你把这个判断权也交给Loop,你就不再是工程师了。
一句话总结:Loop Engineering不是让你不用干活,而是让你只干最重要的活——设计系统、定义标准、做判断。剩下的,让Loop跑。
我是老周,一个在架构领域摸爬滚打多年的技术人。如果这篇文章对你有帮助,欢迎点赞、在看、转发三连。关注「老周聊架构」,每周深度解读AI和架构的最新趋势
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号