破解 AlphaFold2 的静态构象困局:AFsample2T 让 GPCR 虚拟筛选更上一层楼

破解 AlphaFold2 的静态构象困局:AFsample2T 让 GPCR 虚拟筛选更上一层楼

DrugIntel
发布于 2026-06-04 12:14:47
发布于 2026-06-04 12:14:47

文献来源:Mitjavila-Domènech N, Díaz-Holguín A, et al. Improving AlphaFold2 Performance in Virtual Screens Targeting GPCRs by Enhancing Binding-Site Conformational Sampling. J. Chem. Inf. Model. 2026. DOI: 10.1021/acs.jcim.6c00034 机构:Uppsala University(Science for Life Laboratory)& Linköping University,瑞典 关键词:AlphaFold2 · GPCR · 虚拟筛选 · MSA 蒙版 · 构象采样 · 分子对接
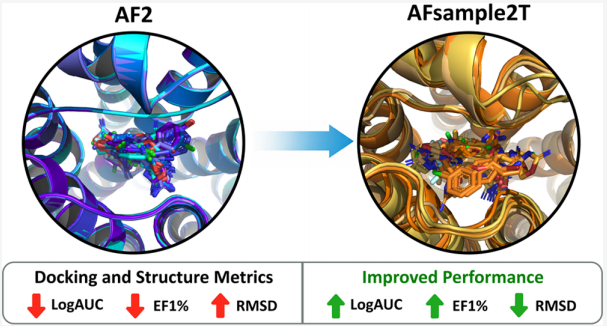
一、研究背景
1.1 AF2 的里程碑意义与内在局限
AlphaFold2(AF2)在 CASP14 评估中以压倒性优势超越传统方法,实现了蛋白质结构预测的革命性突破。然而,这一工具在基于结构的药物设计(Structure-Based Drug Design, SBDD) 中的应用面临根本性瓶颈:
AF2 的训练目标是输出单一最优静态结构,其 Evoformer 模块通过行向与列向注意力机制(row-wise and column-wise attention)充分挖掘多序列比对(MSA)中的共进化信号,将进化约束"锁定"在预测结构中。这使得 AF2 模型在构象多样性上极度匮乏:
- • 结合口袋侧链 RMSF 中位值仅 0.15 Å,而实验结构集合高达 0.58 Å
- • 骨架 RMSF 中位值仅 0.10 Å,实验结构为 0.30 Å
- • 口袋普遍偏"塌陷"、偏小,均值约 209 ų,而实验结构均值约 256 ų
1.2 GPCR:最重要也最棘手的药物靶标
G 蛋白偶联受体(GPCR)是人类最大的膜蛋白超家族,现有约 1/3 上市药物以其为靶点。GPCR 的结构特征使其对构象采样尤为敏感:
- • 正构结合位点(orthosteric site) 位于跨膜螺旋(TM1-7)胞外侧,因内源性配体性质(肽类/小分子/脂质等)不同而呈现高度多样的口袋形态
- • 受体存在激活态(active)与非激活态(inactive) 两大功能构象,TM6 的向外位移是关键标志
- • 胞外环 2(EL2) 在不同配体复合物晶体结构中表现出显著的构象异质性
这种天然的构象多样性,正是 AF2 默认策略所无法捕捉的。多项回顾性评估均表明,AF2 模型在 GPCR 虚拟筛选中的表现系统性差于实验结构,提示结合口袋的精细描述是制约其药物发现应用的核心瓶颈。
二、方法设计:AFsample2T 的核心策略
2.1 MSA 列蒙版的原理
MSA 列蒙版(column masking)的核心逻辑在于:通过随机遮蔽 MSA 中特定位置的列,削减 Evoformer 可获取的共进化信息量,使 AF2 在结构推断时"不得不"探索偏离进化约束的构象空间,从而产生更高的结构多样性(图 1A)。
已有工作(AFsample2,Kalakoti & Wallner, Commun. Biol. 2025)表明对全 MSA 施加 15% 蒙版可增加整体构象多样性;而本文的创新在于将蒙版靶向至结合口袋区域。
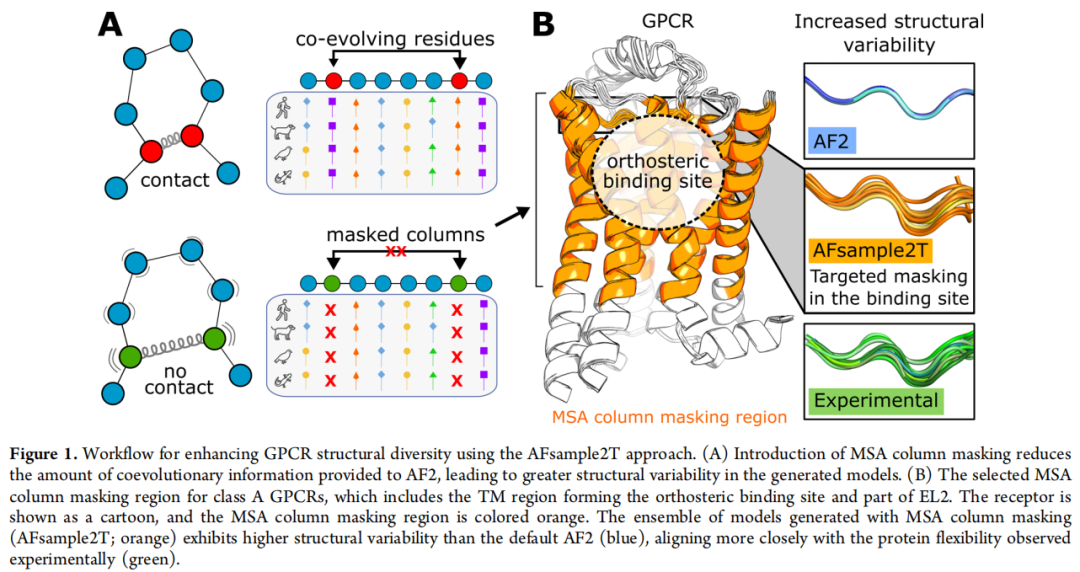
2.2 AFsample2T 的靶向设计
蒙版区域定义(class A GPCR 通用):
区域 | 具体范围 | 作用 |
|---|---|---|
胞外 TM 区 | TM 螺旋胞外侧,延伸至 PIF 保守微开关(P5×50, I3×40, F6×44)以上一个螺旋圈 | 覆盖正构口袋的主体 |
EL2 区 | 保守半胱氨酸至 TM5 之间的 EL2 片段 | 捕获环区构象异质性 |
蒙版概率梯度测试:0%(仅 dropout)、10%、20%、30%、50%
关键设计原则:靶向蒙版 vs. 全局蒙版 全局蒙版(AFsample2 15%)AUC 仅 0.38,远低于靶向蒙版(10–30%,AUC = 0.61–0.59)。全局蒙版破坏了整体折叠的进化约束,导致骨架精度下降;靶向蒙版则在保护全局结构准确性的同时,解放了口袋局部的构象探索能力。
2.3 集成策略与激活/非激活态建模
AFsample2T 集成组成:
每个受体:1,000 个模型
├── 0% 蒙版 + dropout:250 个(激活态 125 + 非激活态 125)
├── 10% 蒙版 + dropout:250 个
├── 20% 蒙版 + dropout:250 个
└── 30% 蒙版 + dropout:250 个两大功能构象的建模:
- • 非激活态:仅输入受体序列(AF2 monomer)
- • 激活态:输入受体序列 + 异三聚体 G 蛋白(Gα/β/γ)序列(AF2-Multimer),通过 G 蛋白的胞内结合引导 TM6 向外位移
验证表明该策略可可靠地区分 TM6 特征性构象(与 Chiesa et al. 2025 的结果一致)。
三、实验设计与评估体系
3.1 结构精度评估(10 个 class A GPCR)
基准数据集:
受体 | 实验结构数量 | 内源性配体类型 |
|---|---|---|
5-HT₁A(血清素受体) | 4 | 单胺 |
A₂A(腺苷受体) | 35 | 嘌呤核苷 |
D₁(多巴胺受体) | — | 单胺 |
D₂ | — | 单胺 |
H₁(组胺受体) | — | 胺类 |
M₄(毒蕈碱受体) | — | 乙酰胆碱 |
MT₁(褪黑素受体) | — | 吲哚胺 |
μ-阿片受体 | — | 内源性肽 |
TAAR1(痕量胺受体) | 13 | 痕量胺 |
(共 10 个) | 共 119 个 | 多样化 |
排除低分辨率结构、重复配体复合物、结合位点突变体后,保留 61 个结构用于精度基准测试。
评估指标:
- • 以结合位点残基(配体周围 5 Å 内)的对称感知侧链 RMSD 为核心指标
- • 计算不同 RMSD 阈值(1.0–2.0 Å)下实验结构被捕获的比例曲线,并以 AUC 量化
- • pLDDT(预测局部距离差异检验)和 PAE(预测比对误差)评估模型置信度
- • 使用 MDTraj 计算 RMSF(均方根波动)评估集成构象多样性
- • 使用 Schrödinger SiteMap 计算口袋体积
3.2 虚拟筛选评估
分子对接工具:DOCK3.8(基于物理评分函数,含 vdW、静电、配体去溶剂化项)
配体集构建:
- • 活性化合物:从 ChEMBL v33 获取(pKᵢ/pKd/pIC₅₀/pEC₅₀ ≥ 6.0),经标准化(去盐、互变异构体、电荷中和)和聚类(Morgan 指纹,Tanimoto = 0.5)后,每受体保留 52–202 个配体
- • 诱饵分子:从 ZINC20 按性质匹配生成,每受体 2,580–10,375 个
评估规模:对 10 个 GPCR 的所有模型(AF2 + AFsample2T,各 1,000 个)及 119 个实验结构进行对接,累计预测打分超过 240 万亿个复合物构象
评估指标:
- • LogAUC / aLogAUC:ROC 曲线半对数面积(调整后去除随机基线),正值代表优于随机
- • EF1%:ROC 曲线在 1% 假阳性率处的早期富集因子
- • 分析维度:集成的中位值(随机选模型的期望表现)和 top 1% 最大值(配体引导选模型的最优表现)
四、核心结果
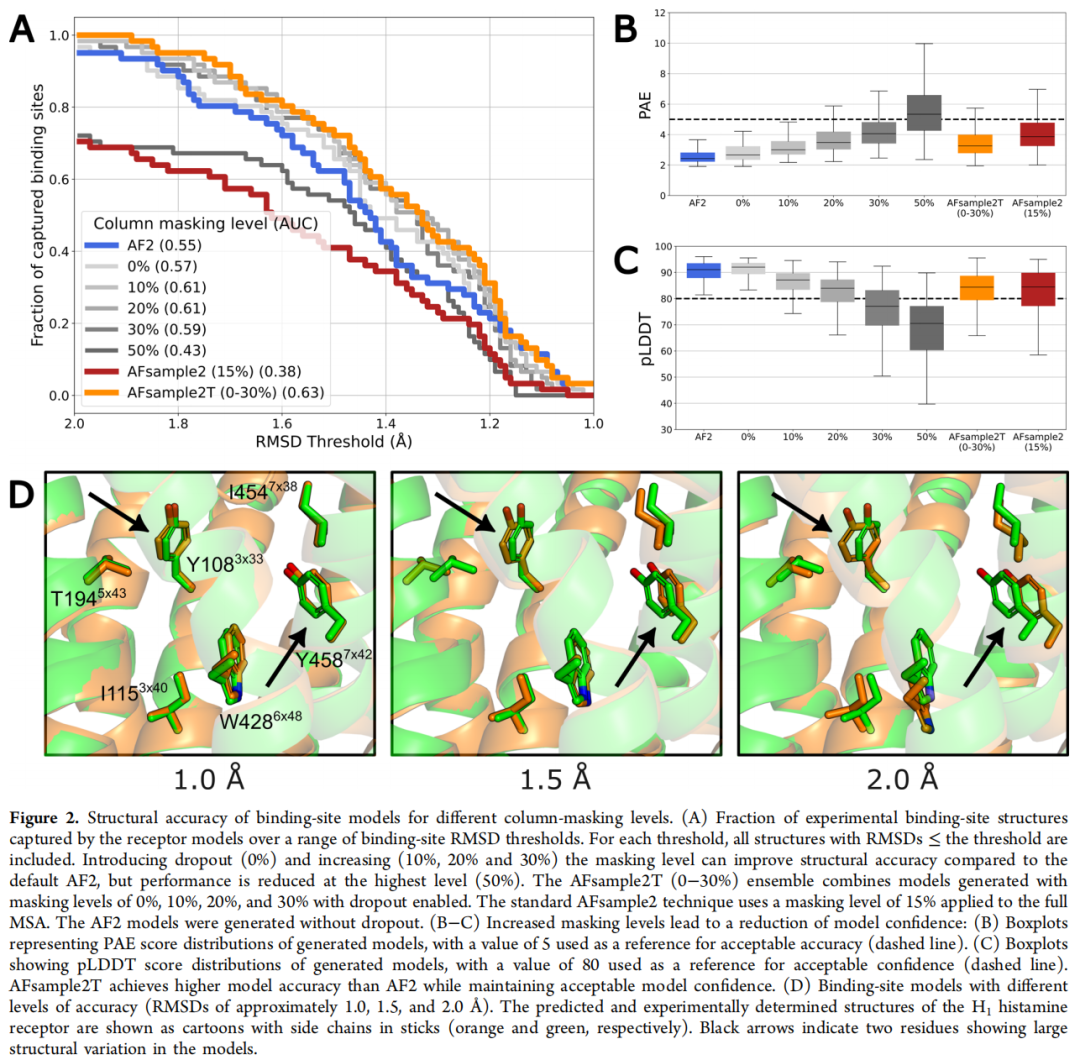
4.1 构象精度:全面优于默认 AF2
结合位点 RMSD-AUC 汇总:
方法 | AUC | 说明 |
|---|---|---|
默认 AF2 | 0.54 | 基线 |
+ Dropout(0%蒙版) | 0.57 | 仅 dropout 即有提升 |
10% 靶向蒙版 | 0.61 | +13%(相对 AF2) |
20% 靶向蒙版 | 0.61 | 同上 |
30% 靶向蒙版 | 0.59 | 小幅下降 |
50% 靶向蒙版 | 0.43 | 骨架被破坏,不可用 |
AFsample2(全局 15%) | 0.38 | 低于 AF2 基线 |
AFsample2T(0–30% 集成) | 0.63 | 最优,+17% |
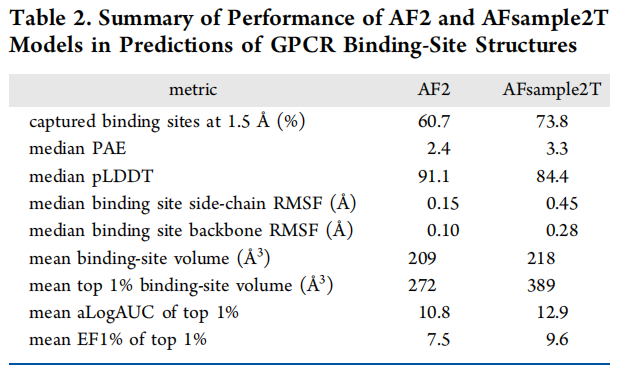
在 RMSD ≤ 1.5 Å 阈值下,AFsample2T 集成捕获了 73.8% 的实验结合位点构象,而 AF2 仅为 60.7%(提升 22%)。
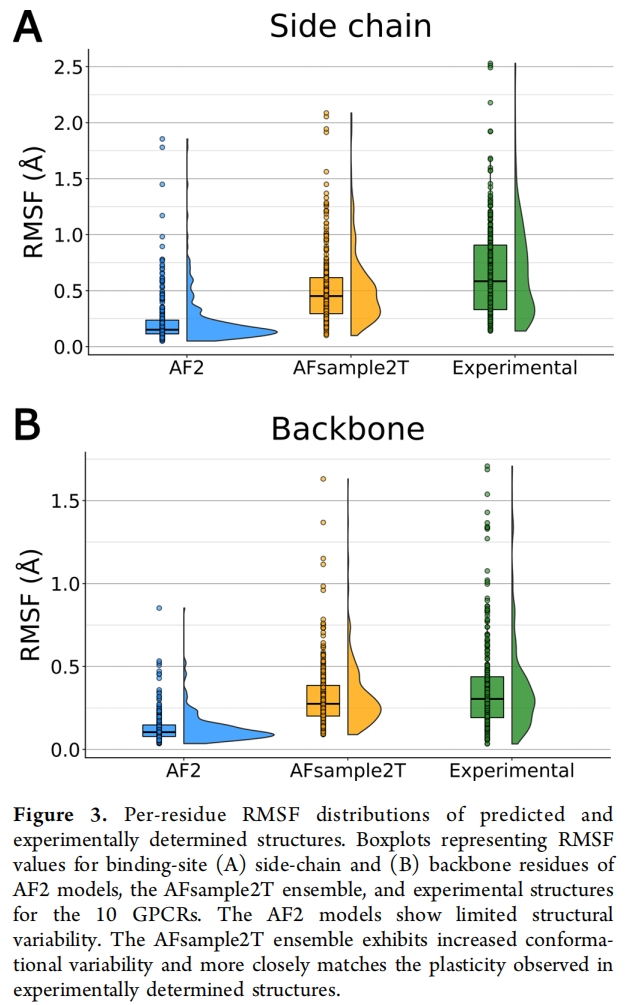
4.2 构象多样性:接近实验水平
RMSF 对比(10 个 GPCR 中位值):
指标 | AF2 | AFsample2T | 实验结构 |
|---|---|---|---|
侧链 RMSF(Å) | 0.15 | 0.45 | 0.58 |
骨架 RMSF(Å) | 0.10 | 0.28 | 0.30 |
均值口袋体积(ų) | 209 | 218 | 256 |
top 1% 口袋体积(ų) | 272 | 389 | — |
AFsample2T 骨架 RMSF 中位值(0.28 Å)已非常接近实验结构(0.30 Å),说明其构象集成不仅仅是侧链旋转体的变化,而是真正采样到了口袋骨架的物理运动范围。
EL2 构象异质性(以 TAAR1 为例):
- • AF2 生成的 13 个模型 EL2 构象几乎完全重叠
- • AFsample2T 的 13 个随机抽样模型展现出与 13 个实验结构相当的构象多样性
- • 相同趋势在其余 9 个 GPCR 中均得到验证
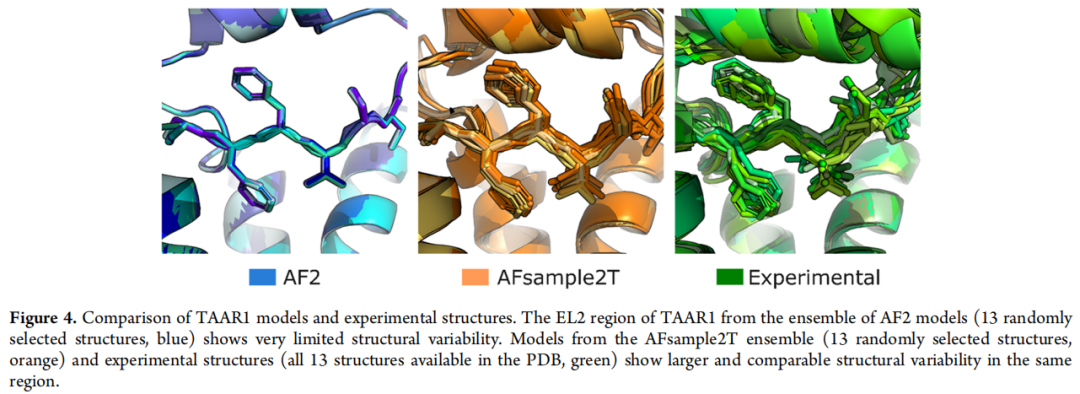
μ-阿片受体的特殊案例:AF2 生成偏塌陷的口袋,AFsample2T 集成中的口袋体积分布与实验结构更为一致,这也是 AFsample2T 在 RMSD 阈值 1.15–1.30 Å 区间表现突出跳升的原因。
4.3 虚拟筛选:配体引导选模型可媲美实验结构
中位性能对比(不使用配体引导,随机选模型):
指标 | 实验结构 | AF2 | AFsample2T |
|---|---|---|---|
aLogAUC 中位值 | 11.2 | 4.4 | 4.2 |
EF1% 中位值 | 4.1 | 1.6 | 1.6 |
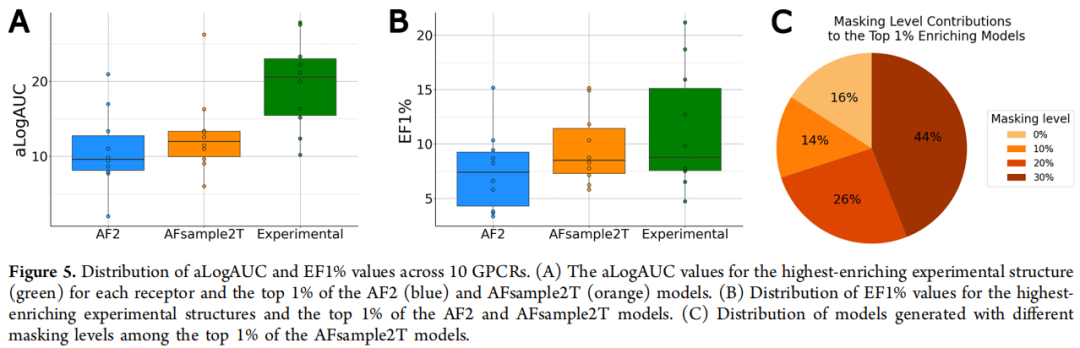
无配体引导时,实验结构仍有显著优势——这与已有评估(Díaz-Rovira et al. 2023, Zhang et al. 2023)一致。
top 1% 性能对比(配体引导选模型):
指标 | 实验结构最优 | AF2 top 1% | AFsample2T top 1% |
|---|---|---|---|
aLogAUC | 19.6 | 10.8 | 12.9 |
EF1% | 11.3 | 7.5 | 9.6 |
关键结论:AFsample2T top 1% 模型的 aLogAUC 和 EF1% 均达到甚至超过实验结构中位水平(aLogAUC = 11.2,EF1% = 4.1)。这意味着:在拥有少量已知配体的情况下,使用 AFsample2T + 富集度筛选,可以找到媲美一般实验结构的预测模型。
各受体 top 1% aLogAUC(部分亮点):
GPCR | AF2 top 1% | AFsample2T top 1% |
|---|---|---|
TAAR1 | — | 32.0(实验最优 27.8) |
μ-阿片受体 | — | 16.2(实验最优 15.2) |
D₁ | — | AFsample2T 中位值优于 AF2 |
5-HT₁A | — | AFsample2T 中位值优于 AF2 |
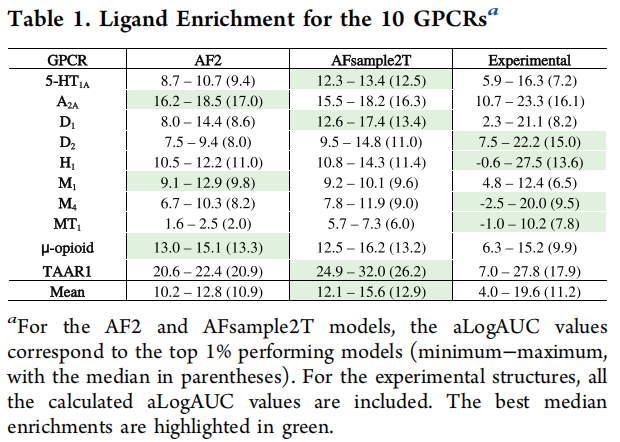
AFsample2T 集成在七个受体中(5-HT₁A、D₁、D₂、H₁、M₄、MT₁、TAAR1)的中位富集度优于 AF2。
最优蒙版概率分布(top 1% 模型来源):
蒙版概率 | 贡献比例 |
|---|---|
0%(仅 dropout) | 14% |
10% | 26% |
20% | 44% |
30% | 16% |
不同蒙版概率的互补贡献验证了集成策略的合理性:20% 蒙版贡献最多,但其他档位同样不可或缺。
4.4 模型数量分析
分析 10、100、250、500、1000 个模型的结果表明:生成 100–250 个模型即可获得接近 1,000 个模型水平的最大富集度。这一发现对实际应用具有重要的计算成本指导意义。
五、讨论:方法定位与适用边界
5.1 与相关方法的比较
方法 | 原理 | 优势 | 局限 |
|---|---|---|---|
AFsample2T(本文) | 局部 MSA 列蒙版 | 构象多样性 + 模型置信度平衡;靶向效率高 | 依赖构象选择模型;不适用于强诱导契合 |
全局 MSA 蒙版(AFsample2) | 全 MSA 蒙版 | 适合捕获大构象变化(激活/非激活态) | 破坏整体折叠精度,口袋精度反而更低 |
MSA 浅采样(SPEACH_AF等) | 减少 MSA 行数 | 适合探索替代构象状态 | 同样侧重大范围构象变化 |
MD 精修 | 物理力场模拟 | 基于物理原理,可采样连续轨迹 | 膜蛋白系统计算代价极高;预测结构起点质量影响大 |
AlphaFold3 / Boltz-2 | 配体-受体共折叠 | 直接预测复合物构象 | 结合位点建模精度尚待系统评估;依赖训练数据中相似配体 |
诱导契合对接(IFD) | 对接中允许受体灵活 | 针对特定配体的口袋适应 | 依赖单配体;不适用于 scaffold-agnostic 虚筛 |
5.2 方法局限性
- 1. 诱导契合场景受限:AFsample2T 基于构象预选(conformational selection)模型,如果某配体结合引发显著的诱导契合效应,预生成的集成可能无法覆盖相应构象
- 2. AF2 训练数据偏差:10 个基准受体中有 4 个结构包含在 AF2 训练集,模型对未知结构受体的泛化性能可能偏低
- 3. 无配体场景表现有限:中位富集度(反映无配体引导时的性能)仍显著低于实验结构;针对完全无配体信息的孤儿受体,虚筛结果可靠性存疑
- 4. 受体构象能量估计未纳入:集成对接目前未对不同构象进行能量权重校正,进一步结合构象能量惩罚项(如 Kamenik et al. 2021 框架)可能带来额外提升
- 5. GPCR 特化设计:蒙版区域基于 GPCR 的保守拓扑定义,应用至其他靶标类别(如激酶)需重新定义靶向区域
5.3 方法延伸与展望
- • 变构位点应用:将靶向蒙版指向 GPCR 变构口袋(如 TM束内腔侧),有望生成适用于变构虚筛的构象集成
- • 激酶及其他靶标类别:作者明确指出方法可迁移至激酶等具有保守折叠的靶标家族,源代码已开源
- • 模板偏向策略结合:未来可将 AFsample2T 与 AF2 中的模板偏向(template-biased)策略(Sala et al. 2023;Chiesa et al. 2025)结合,进一步提升特定功能构象的建模精度
- • 共折叠方法评估:随着 AF3 和 Boltz-2 等配体-受体共折叠方法的成熟,与 AFsample2T 的系统性对比将是重要研究方向
六、实操指南:如何将 AFsample2T 用于 GPCR 虚筛
推荐工作流程(四步)
步骤 1:生成 AFsample2T 集成
├── 确定目标受体的激活/非激活态(是否纳入 G 蛋白)
├── 定义靶向蒙版区域(胞外 TM + EL2,参照 GPCRdb 编号)
├── 四档蒙版概率(0/10/20/30%),各生成 ≥62 个模型
└── 推荐集成规模:≥250 个模型(计算资源充足时建议 1,000 个)
步骤 2:对接已知配体与诱饵分子
├── 活性化合物:≥10 个已知配体(聚类后)
├── 诱饵分子:每活性分子匹配 ≥50 个诱饵(ZINC 来源)
└── 对接工具:DOCK3.8 或同类物理评分工具
步骤 3:配体引导模型筛选
├── 计算每个模型的 aLogAUC 和 EF1%
├── 选取 top 1% 高富集模型(约 10 个模型/1,000 集成)
└── 人工检查:验证关键相互作用(氢键、疏水接触)是否合理
步骤 4:前瞻性大规模虚筛
└── 使用 1–3 个 top 模型对目标化合物库进行全面对接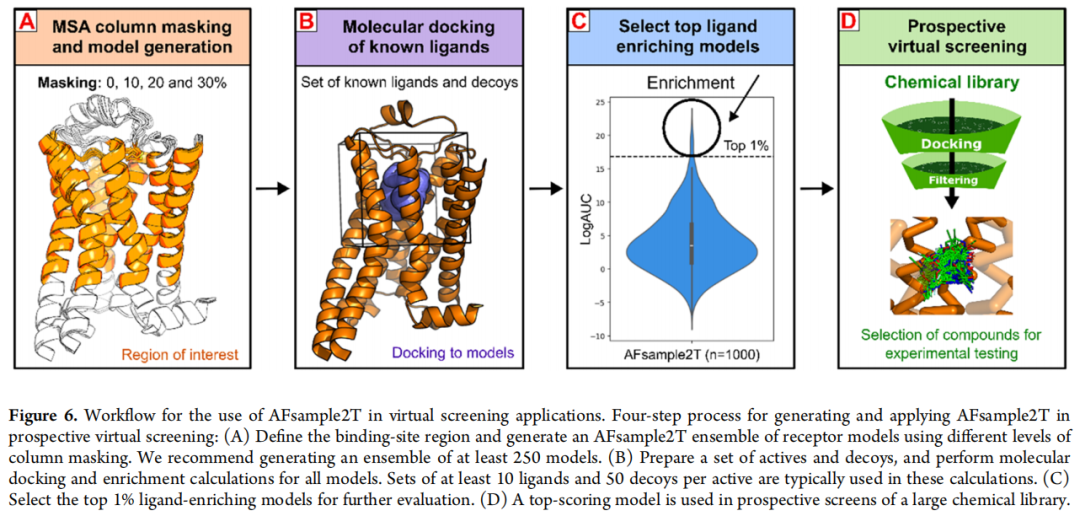
决策树:实验结构 vs. AFsample2T
是否存在受体实验结构?
├── 是 → 是否有多个配体-受体复合物结构?
│ ├── 是 → 优先使用实验结构(通常 ≥1 个结构可达 top AFsample2T 水平)
│ └── 否(仅 1 个或无配体结构)
│ └── 该结构富集度是否良好?
│ ├── 是 → 使用实验结构
│ └── 否 → 考虑使用 AFsample2T 补充
└── 否 → 使用 AFsample2T + 配体引导筛选
(如无任何已知配体,则为高风险场景,结果可靠性存疑)写在最后
这篇工作的核心贡献在于识别并缓解了 AF2 用于药物发现时的具体瓶颈——不是笼统地"增加采样多样性",而是有针对性地在结合口袋区域释放进化约束,并通过严格的回顾性虚拟筛选评估验证了方法的实用性。
方法的优雅之处在于其极简的设计逻辑:仅需修改 MSA 输入(局部蒙版),无需改变 AF2 网络架构,无需额外训练,即可在结构质量与构象多样性之间实现有效的工程化权衡。
对药物发现社区的实践意义:
- 1. 为无实验结构或实验结构质量有限的 GPCR 提供了可行的虚筛策略
- 2. 证明了"集成+配体引导筛选"的范式可将 AF2 模型的虚筛性能提升至接近实验结构水平
- 3. 提供了可直接复用的开源工具和方法学指南
- 4. 方法可扩展至其他靶标类别,具有广泛适用性
局限性提示:方法效果高度依赖配体引导的模型筛选——在无已知配体的场景中,AFsample2T 的优势尚未被充分验证,仍需谨慎解读中位富集度数据。此外,方法与新兴共折叠工具(AF3、Boltz-2)的系统比较将是判断未来技术路线选择的关键。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号