Natl. Sci. Rev. | 多模态预训练分子表示在药物发现中的应用

Natl. Sci. Rev. | 多模态预训练分子表示在药物发现中的应用

DrugIntel
发布于 2026-06-02 13:26:51
发布于 2026-06-02 13:26:51

文献来源:Wang X, Wang C, Ji B, et al. Multimodal pre-training models of molecular representation for drug discovery. National Science Review, 2026, 13: nwaf495. DOI:10.1093/nsr/nwaf495 发表机构:西北工业大学 · 湖南大学 · 香港大学 · 中国科学院上海药物研究所
一、背景:为什么药物发现需要 AI?
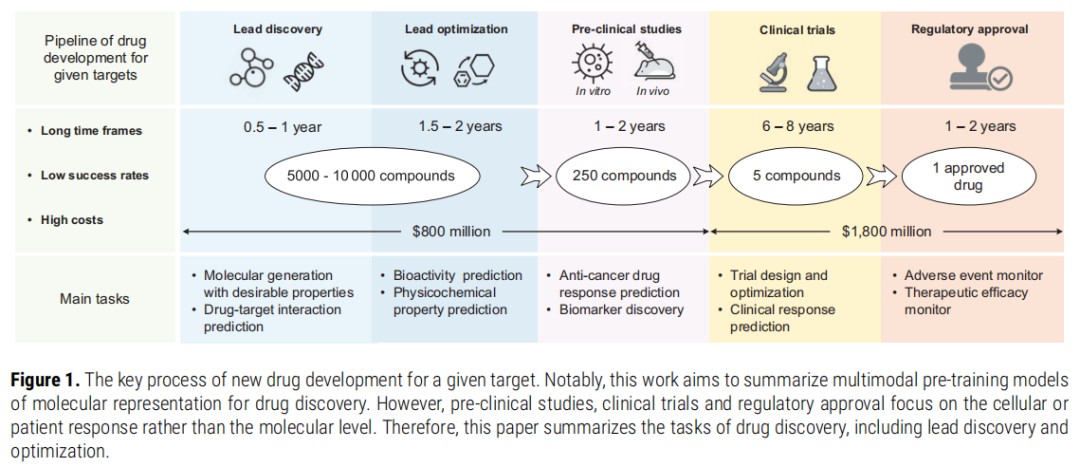
新药研发是人类健康事业中成本最高、周期最长、风险最大的科学工程之一。平均而言,一款新药从立项到获批上市需要投入约 26 亿美元、历经 10~15 年,而在初筛阶段进入研究的 5,000~10,000 个化合物中,最终能够完成临床试验并获得监管批准的仅有 1 个。更为严峻的是,每十亿美元资金所能带来的新药获批数量每九年减半——这一现象被学界称为"逆摩尔定律"(Eroom's Law)。
面对这一困境,深度学习驱动的计算方法为药物研发带来了新的可能。AlphaFold 的成功证明了 AI 在蛋白质结构预测领域的革命性潜力。然而,深度学习的性能严重依赖大规模标注数据,而真实药物发现场景中有标注的分子数据极为稀缺,这构成了深度学习大规模应用的核心瓶颈。
自监督预训练技术的兴起为破解这一困境提供了关键思路:通过在海量未标注数据上自动构造监督信号,模型得以学习分子结构背后的潜在规律,显著降低了对标注数据的依赖。这篇综述正是在这一背景下,系统梳理了当前最前沿的多模态预训练分子表示学习研究进展。
二、什么是多模态预训练模型?
2.1 核心框架
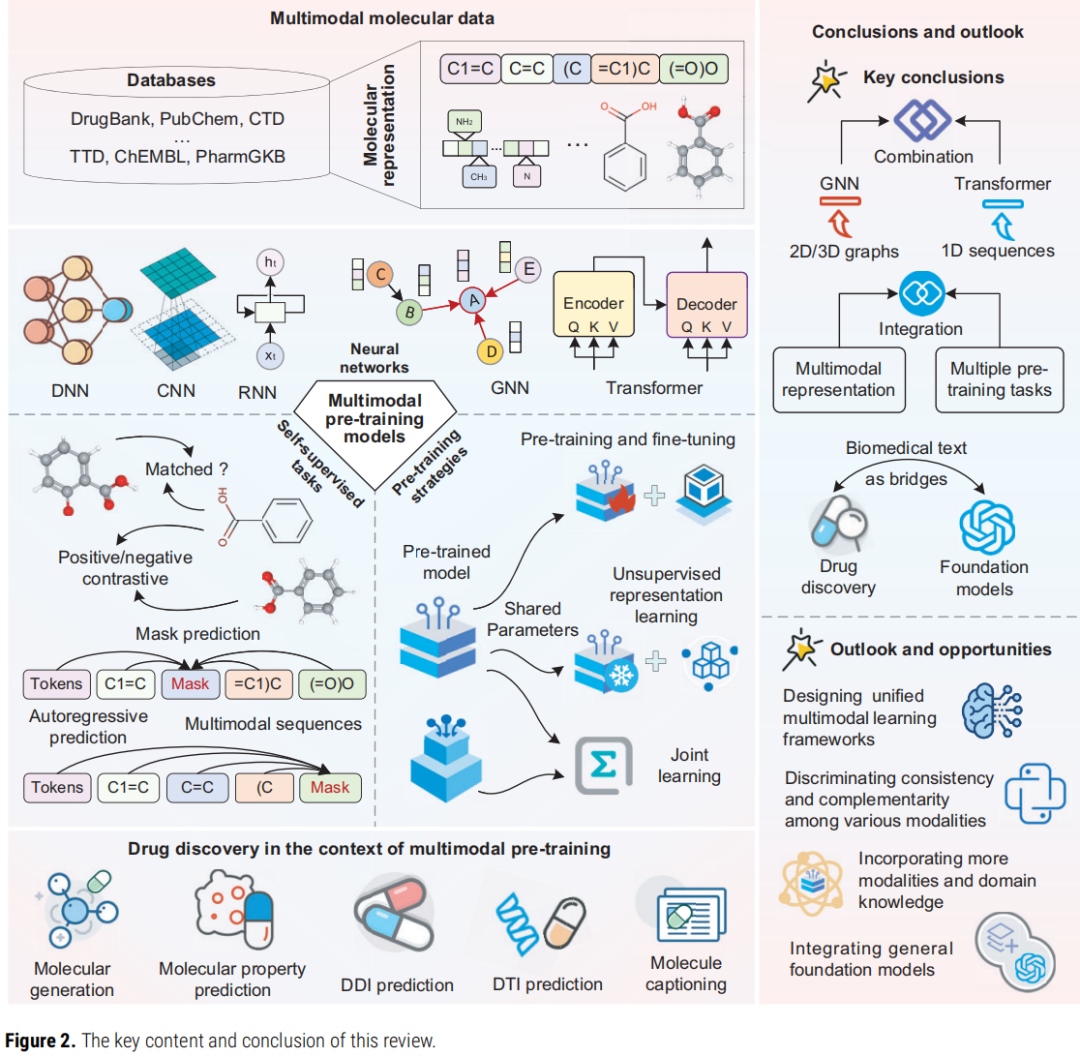
多模态预训练模型由四个核心要素构成:
要素 | 内容 |
|---|---|
多模态分子数据 | 1D 序列、2D 图、3D 几何结构、分子描述符、交互网络、文本描述 |
神经网络编码器 | DNN、CNN、RNN、Transformer、GNN 及其变体与融合体 |
自监督预训练任务 | 对比学习、匹配预测、掩码预测、自回归预测 |
训练策略 | 联合训练、无监督表示学习、预训练-微调两阶段训练 |
其核心逻辑是:让神经网络通过自动生成的伪标签(pseudo-labels)从多模态未标注数据中学习统一的分子表示,再迁移至下游药物发现任务。
2.2 与单模态预训练的根本区别
单模态预训练仅从一种表示形式(如 SMILES 序列)学习,而多模态预训练的核心优势在于:
- • 互补性(Complementarity):不同模态各自捕捉分子不同层次的特征,融合后信息更完整
- • 一致性(Consistency):同一分子在不同模态中应具有语义一致性,跨模态对齐有助于学习更鲁棒的表示
- • 泛化性:多模态联合训练能有效提升模型在小样本下游任务中的泛化能力
三、多模态分子数据:分子的六种"语言"
以苯甲酸(Benzoic Acid)为例,一个分子可以从以下六个维度被编码:
3.1 一维序列(1D Sequence)
最常见的分子序列表示是 SMILES(Simplified Molecular-Input Line-Entry System),例如苯甲酸表示为 C1=CC=C(C=C1)C(=O)O。其优势是存储紧凑、便于与文本模型直接结合;劣势是无法显式编码原子间的空间关系。此外,SELFIES(Self-Referencing Embedded Strings)作为更具鲁棒性的分子字符串表示,在生成任务中展现出优越性。
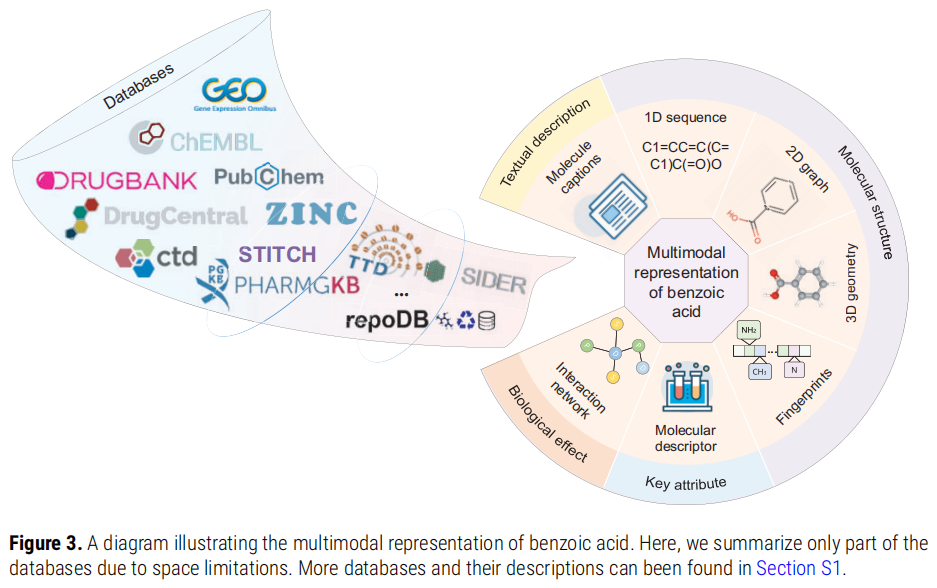
3.2 二维分子图(2D Molecular Graph)
将原子视为节点、化学键视为边,构造分子图。2D 图能够显式捕捉原子间的连接拓扑,是图神经网络(GNN)的标准输入格式。与 1D 序列相比,2D 图保留了更多结构语义信息。
3.3 三维几何结构(3D Geometry)
在 2D 图基础上,进一步引入原子的三维空间坐标,描述分子的真实立体构型。对于药物-靶点结合预测而言,3D 结构至关重要——分子的构象直接决定其与受体的结合能力(锁钥原理)。
3.4 分子描述符与指纹(Molecular Descriptors & Fingerprints)
分子描述符是反映分子物理化学性质的结构化数值向量,分子指纹则是基于子结构特征的二值化向量(如 Morgan 指纹)。两者适合作为 DNN 的直接输入,且计算高效。
3.5 分子交互网络(Molecular Interaction Network)
以生物实体(基因、蛋白质、药物、疾病等)为节点、已知的相互作用关系为边,构建异质网络(Heterogeneous Network)。与其他模态相比,交互网络能够编码"多药多靶多疾病"的系统生物学知识,对多组学融合和药物重定向任务尤具价值。
3.6 分子文本描述(Molecule Captions)
以自然语言形式描述分子的名称、化学式、结构特征、生物活性及功能特征。文本描述是最直观、最易被非化学背景读者理解的模态,也是大语言模型(LLM)与药物发现领域衔接的核心桥梁。不同来源(DrugBank、PubChem、ChEMBL 等)对同一分子的描述风格存在差异,标准化不足是当前挑战之一。
四、神经网络框架:为不同模态选择合适的编码器
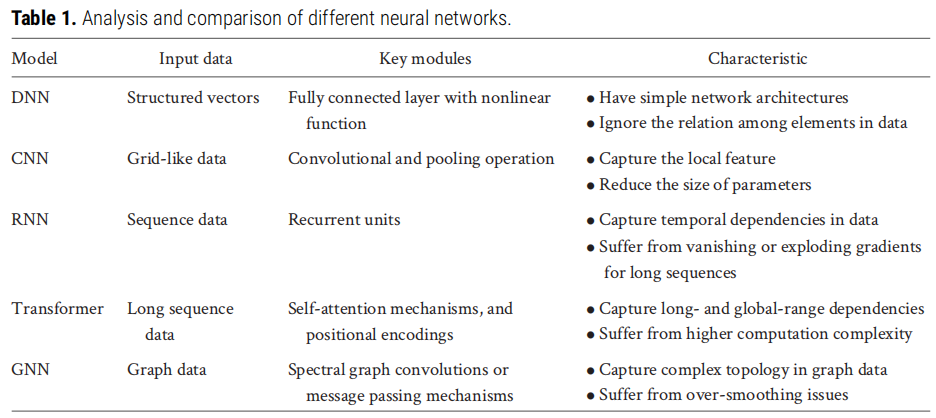
4.1 五类经典网络框架对比
网络类型 | 适用模态 | 核心模块 | 主要优势 | 主要局限 |
|---|---|---|---|---|
DNN | 结构化向量(描述符/指纹) | 全连接层 + 非线性激活 | 架构简单,计算高效 | 忽略元素间依赖关系 |
CNN | 网格数据(分子图像)、1D 序列 | 卷积 + 池化操作 | 捕捉局部特征,参数共享 | 难以处理全局依赖 |
RNN | 时序序列(SMILES、文本) | GRU/LSTM 循环单元 | 捕捉序列时序依赖 | 长序列梯度消失/爆炸问题 |
Transformer | 长序列数据 | 多头自注意力 + 位置编码 | 捕捉长程全局依赖 | 计算复杂度随序列长度平方增长 |
GNN | 图结构数据(2D/3D 分子图、交互网络) | 谱图卷积 / 消息传递机制 | 捕捉图拓扑结构 | 深层 GNN 存在过度平滑(over-smoothing)问题 |
4.2 Transformer 的核心架构及其在药物发现中的扩展
Transformer 采用编码器-解码器(Encoder-Decoder)框架:
- • 编码器:多个相同模块堆叠,每个模块包含多头自注意力层 + 前馈网络层,配合残差连接和层归一化。多头注意力机制的核心作用是学习序列中不同位置(如 SMILES token)之间的长程依赖关系。
- • 解码器:在编码器结构基础上增加掩码注意力层,确保当前位置仅能依赖左侧已知信息,主要用于自回归生成任务。
Transformer 的两个重要变体在药物发现中尤受关注:
- 1. Vision Transformer(ViT):将分子结构图像切分为 patch 序列后输入 Transformer,代表性工作如 ISMol 将 2D 分子图像化并送入 ViT 进行性质预测。
- 2. 图 Transformer(Graphormer):为 Transformer 引入中心性编码(Centrality Encoding)、空间编码(Spatial Encoding)和边特征编码(Edge Encoding),使其能够处理图结构数据,在分子属性预测上表现优越。代表性工作包括 MAT、Transformer-M、MOLEBLEND、Interformer 等。
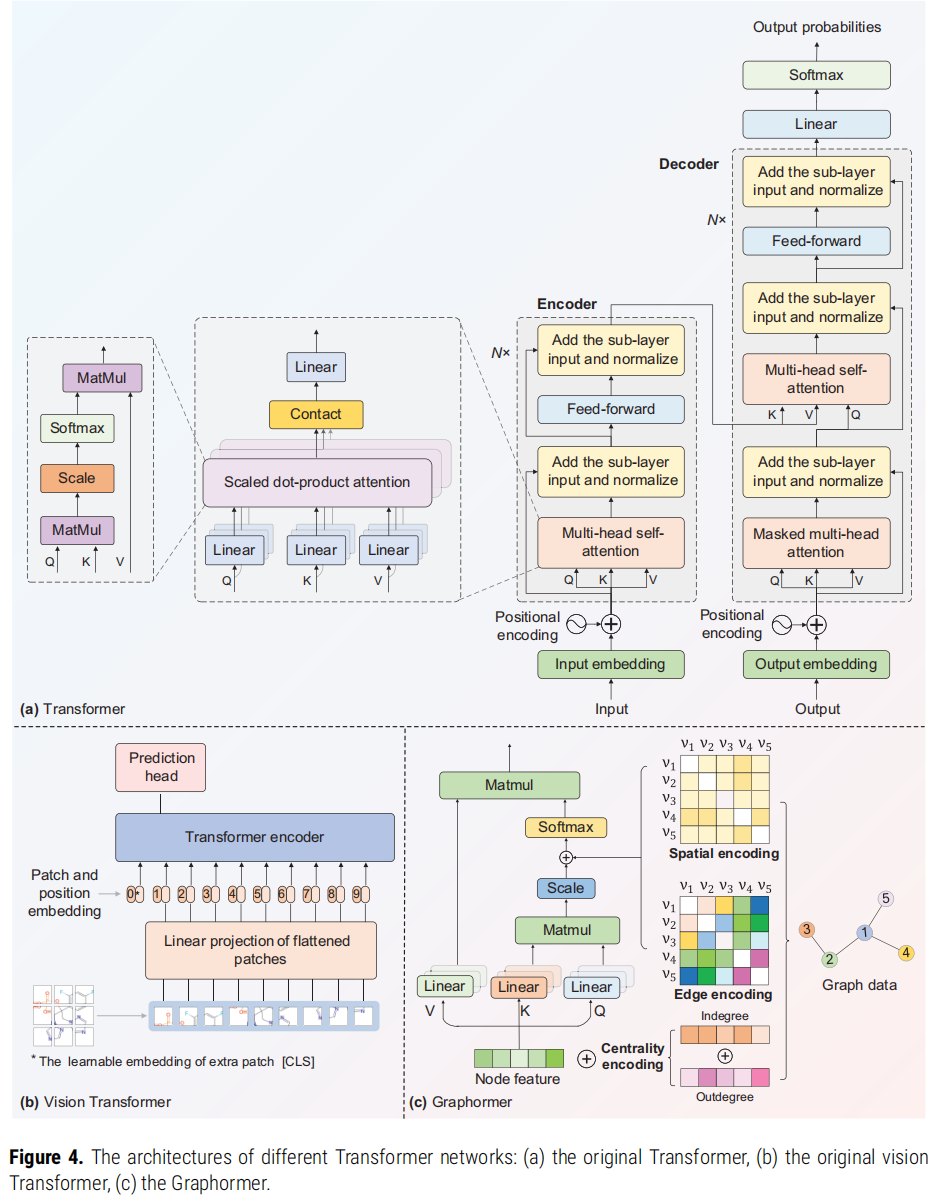
4.3 趋势:Transformer 与 GNN 的融合
文章指出,当前最主流的编码器设计模式是同时使用 Transformer 处理 1D SMILES 序列和 GNN 处理 2D/3D 分子图,两者结合能够覆盖分子从序列到拓扑结构的不同尺度特征。这种"序列+图"双塔编码架构已在大量工作中得到验证,是当前多模态预训练的主流框架。
五、多模态自监督预训练任务
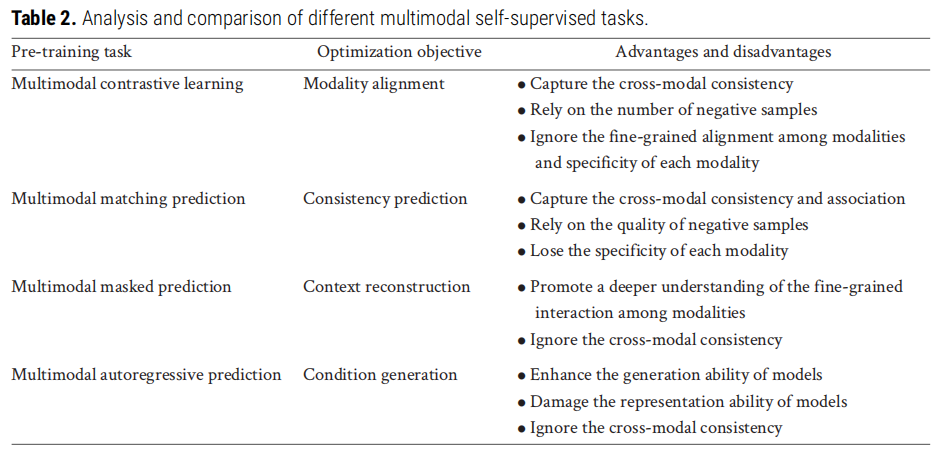
5.1 四类任务的系统对比
预训练任务 | 优化目标 | 核心优势 | 主要局限 |
|---|---|---|---|
对比学习 | 模态对齐 | 捕捉跨模态一致性;可利用大批量负样本避免模型崩溃 | 依赖大量负样本;忽略模态细粒度对齐与各模态独特性 |
匹配预测 | 一致性分类 | 捕捉跨模态关联;通过注意力机制建模细粒度交互 | 依赖负样本质量;正负对识别较简单,限制学习难度 |
掩码预测 | 上下文重建 | 深度理解模态内部精细结构与跨模态细粒度交互 | 忽略跨模态全局一致性 |
自回归预测 | 条件生成 | 增强模型的生成能力 | 仅利用单向信息;削弱表示与理解能力;较少生成任务需求 |
5.2 对比学习 vs. 匹配预测的关键差异
两者都以"正样本对"(同一分子的两种模态)和"负样本对"(不同分子的两种模态)为训练信号,但存在本质区别:
- • 对比学习:最大化正样本对的表示相似度,最小化负样本对的相似度;性能与负样本数量高度相关;可以通过大批量训练生成充足负样本。
- • 匹配预测:将样本对是否匹配作为二分类任务;性能与负样本质量高度相关;通常在模态特异性编码器后接注意力机制或多层感知机,能够更好地建模跨模态精细交互。
部分工作(如 ISMol、MolCA)将两者结合以实现互补,取得了更好的效果。
5.3 掩码预测的跨模态扩展
掩码预测最初由 BERT 提出用于自然语言处理,其核心思想是遮盖输入的部分信息后要求模型恢复。多模态掩码预测将这一思想扩展至跨模态场景:将不同模态的输入统一转化为序列,随机遮盖部分 token,要求模型利用其他模态的信息来恢复被遮盖内容。这一机制能够强迫模型学习模态间的深层语义对应关系。
5.4 多任务预训练的趋势
由于各预训练任务捕捉分子特征的侧重点不同,越来越多的研究通过加权求和多个预训练任务损失来进行联合训练,以期获得更全面、更通用的分子表示。这本质上是一个多任务学习问题,但也带来了超参数复杂度增加、不同任务收敛速度不一致等挑战。
六、自监督训练策略
6.1 三类训练策略对比
训练策略 | 预训练模型的角色 | 核心优势 | 主要挑战 |
|---|---|---|---|
联合训练 | 正则化/辅助项 | 增强对下游任务的适配性;缓解灾难性遗忘 | 降低模型通用性和可迁移性 |
无监督表示学习 | 特征提取器(冻结) | 保证通用性;防止小样本过拟合 | 无法捕捉下游任务特异性特征 |
预训练-微调两阶段 | 编码器参数初始化 | 兼顾通用性与任务适配性;适用于多种下游任务 | 全参数微调计算成本高;存在灾难性遗忘和过拟合风险 |
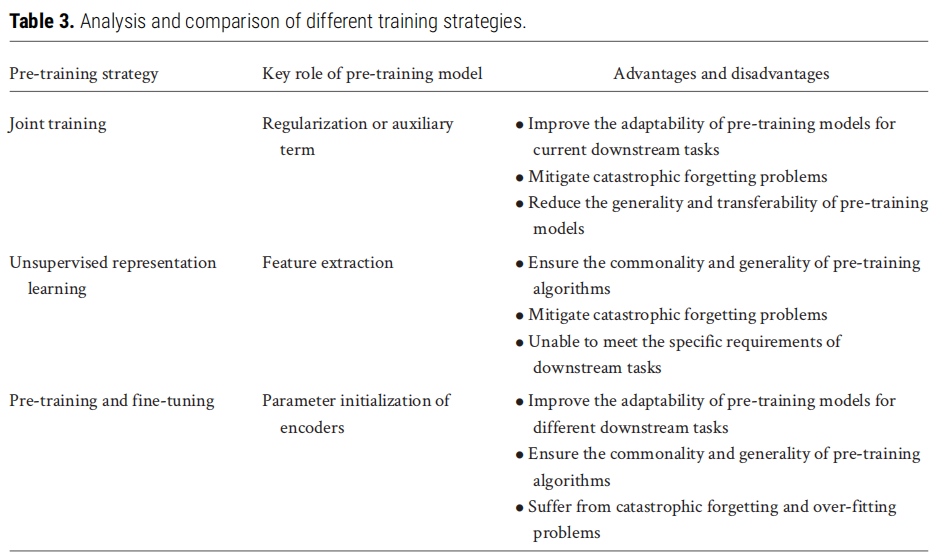
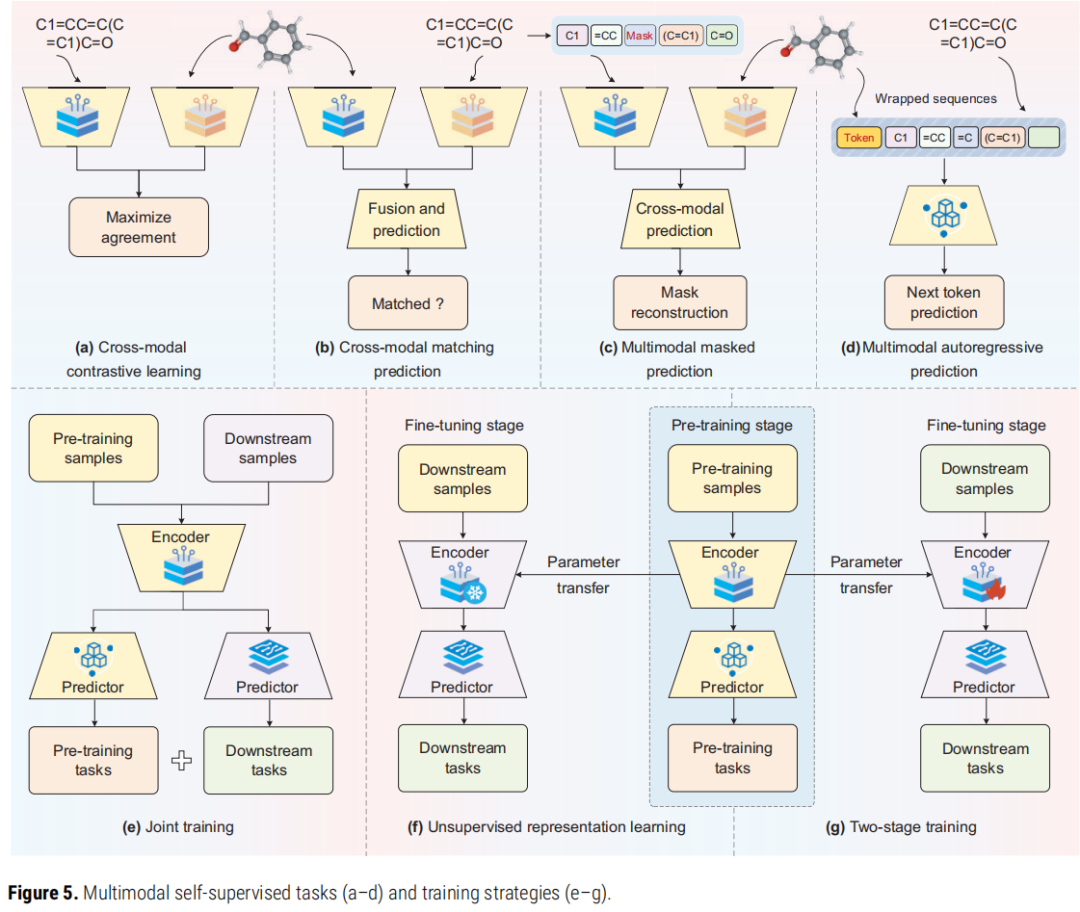
6.2 参数高效微调技术(PEFT)
随着预训练模型参数规模增大,全参数微调的计算成本急剧上升。参数高效微调技术(Parameter-Efficient Fine-Tuning, PEFT)通过仅调整少量参数来实现接近全参数微调的效果,主要包括三类方法:
- • 加法式微调(Additive):在预训练模型中插入可训练的 Adapter 模块或 Prompt 向量,冻结原始参数
- • 选择式微调(Selective):仅微调预训练模型中的特定层或参数子集
- • 重参数化微调(Reparameterized,如 LoRA):通过低秩分解近似参数更新,显著减少可训练参数量
当前在药物发现领域,两阶段训练(预训练-微调)已成为主流范式,而重参数化微调仍处于探索阶段。
6.3 提示学习(Prompt Learning)
为缓解预训练任务与下游任务之间的分布偏移(negative transfer)问题,部分工作探索了基于提示学习(Prompt Learning)的微调策略,通过设计任务特定的提示模板来弥合两阶段的语义鸿沟,代表性工作包括 KANO 和 BioT5。
七、药物发现核心任务中的应用进展
7.1 分子生成(Molecular Generation)
任务目标:设计具备目标性质(高亲和力、低毒性、高活性、结构新颖性)的候选分子。
方法脉络:
- • 1D 序列生成:以 SMILES 为化学语言,训练类 GPT 自回归模型逐 token 生成分子序列,代表性工作如 TamGen、MolGPT。在微调阶段常结合强化学习优化生成分子的生化性质。
- • 3D 结构生成:将原子三维坐标视为语言表达,与 SMILES 联合构建 GPT 式自回归模型,代表性工作如 3DSMILES-GPT;Lingo3DMol 提出对扰动分子进行 2D+3D 双表示重建的自回归预训练,在口袋感知的三维分子生成中表现出色。
- • 文本驱动生成:基于 SMILES-文本混合语料,利用掩码 span 恢复预训练 T5 模型,实现从文本描述到分子结构的双向翻译(代表:MolT5),以及集成 SMILES、2D 图、分子图像和文本描述的多模态对比学习+匹配预测范式(代表:GIT-Mol)。
7.2 分子性质预测(Molecular Property Prediction)
任务目标:根据分子结构推断其生化活性、物理化学特性等,是药物筛选的核心环节。
主流范式:大多数方法采用双编码器设计——Transformer 处理 SMILES,GNN 处理 2D/3D 分子图——并以跨模态对比学习作为核心预训练任务。代表性工作包括:
- • graphMVP:基于 2D/3D 图的多视图对比预训练
- • 3D-Infomax:最大化 2D GNN 与 3D 几何表示的互信息
- • MOLEBLEND:多模态预训练融合序列与图结构的模态混合
- • KANO:融合知识图谱的分子对比学习与功能提示
越来越多的工作将对比学习、掩码预测和匹配预测组合使用以提升性质预测精度,并探索加入更多模态(生物医学文本、交互网络)和领域知识(功能团、合成可及性评分)。
7.3 药物-药物相互作用预测(DDI Prediction)
任务目标:识别药物联用时发生不良反应的风险,对临床合理用药具有重要意义。
技术特点:与分子性质预测类似,大多数多模态方法将对比学习作为核心任务,但重点在于对齐分子结构模态与分子交互网络模态。异质图神经网络(Heterogeneous GNN)被广泛用于编码包含药物-靶点-疾病-副作用等多类关系的分子交互网络。代表性工作包括 H2D(层次异质图学习框架)和 HetDDI(预训练异质图模型)。
7.4 药物-靶点相互作用预测(DTI Prediction)
任务目标:判断给定药物分子与靶点蛋白是否能够结合,同时支持药物重定向(Drug Repositioning)。
技术特点:
- • 基于 SMILES 和 2D 分子图,综合运用掩码预测和对比学习训练 Transformer 和图卷积网络
- • 部分工作从分子图与交互网络出发,通过跨尺度图对比学习预测药物-靶点结合亲和力
- • BioT5 将分子 SELFIES、蛋白质序列和通用文本进行包裹序列(Wrapped Sequences)融合,并采用基于提示的微调策略缩短预训练与 DTI 预测的任务差距
7.5 分子描述生成(Molecule Captioning)
任务目标:给定分子结构,自动生成涵盖分子名称、化学式、结构特征和功能描述的文字说明。
技术特点:分子描述生成被视为分子与语言的双向翻译任务(同时包含 caption 生成与文本驱动的分子生成)。类似于图像描述生成(Image Captioning),大量工作参考了 BLIP-2 的 Q-Former 架构——通过可学习的查询向量(Query Transformer)桥接冻结的分子编码器与大语言模型(LLM),使 LLM 能够解读分子结构信息。代表性工作包括 MolCA、3D-MOLM、MolFM 等。
八、两大核心趋势(作者归纳)
综述作者明确归纳了两条具有参考价值的上升趋势:
趋势一:Transformer + GNN 跨尺度分子表示学习
越来越多的研究将 Transformer 与 GNN 整合为统一编码器,配合多种自监督预训练任务,学习覆盖序列到空间结构的跨模态分子表示,从而提升药物发现任务的精度。
- • 动因:1D 序列与 2D/3D 图结构各有信息盲区,融合两者能捕捉更全面的分子特征
- • 典型架构:SMILES-Transformer(序列编码) + Graph-Transformer/GNN(图编码) + 跨模态对比学习/匹配预测
- • 代表工作:graphMVP、3D-Infomax、MOLEBLEND、MolLM、MoleculeSTM 等
趋势二:分子文本描述成为 LLM 与药物发现的核心桥梁
分子描述(Molecule Captions)作为简洁的生物医学文本,为药物发现与大语言模型的深度融合提供了关键接口。
- • 动因:文本描述是最接近自然语言的分子表达形式,可直接利用 LLM 的理解与推理能力
- • 实现路径:混合 SMILES 序列与生物医学文本进行预训练(MolT5、BioT5)→ 引入 Q-Former 架构桥接分子编码器与冻结 LLM(MolCA、3D-MOLM)
- • 潜力:推动分子生成、性质预测、药物重定向等任务的可解释性与知识迁移能力
九、挑战与未来机遇
9.1 设计统一灵活的多模态框架
当前瓶颈:现有框架多以粗粒度的对比学习或匹配预测为主要对齐手段,难以捕捉模态内的精细语义结构;同时,实际场景中样本常缺失某些模态,缺乏自动处理缺失模态的弹性机制。
潜在路径:参考计算机视觉中的 BEiT-3、VLMO 等统一多模态框架——将不同模态数据统一编码为序列,送入 Transformer 学习通用表示;设计条件推断机制以处理模态缺失情形。
9.2 区分并利用跨模态一致性与互补性
当前瓶颈:现有多任务预训练框架存在信息冗余——共享空间中可能混入各模态的独特特征,而模态特异性空间可能丢失共有特征,既增加计算冗余,又降低表示质量。
潜在路径:借鉴信息论框架(如互信息最大化/最小化),显式地将跨模态共享信息与模态特异信息解耦,建立同时学习一致性与互补性的多任务预训练目标。
9.3 引入更多模态与领域先验知识
新兴数据模态:
- • 分子视频(Molecular Videos):捕捉分子动力学过程中的时序构象变化,代表性工作如基于分子视频的基础模型
- • 单细胞 RNA 测序数据(scRNA-seq):提供细胞水平的基因表达谱,助力个性化精准医疗
- • 细胞图像(Cell Painting):高通量显微镜图像编码了药物处理后细胞表型的丰富信息
可融合的先验知识:
- • 功能团(Functional Groups):化学反应活性的核心单元,可作为子图层次的语义先验
- • 粗粒度模型表示(Coarse-Grained Representation):通过降低分子自由度加速动力学模拟
- • 分子基序(Motifs):频繁出现的子结构模式,携带生物活性相关语义
- • 合成可及性评分(Synthetic Accessibility Score, SA):指导生成模型产生实际可合成的分子
9.4 与通用基础模型深度融合
当前瓶颈:现有分子预训练模型多仅整合 1D 特征(如 MolT5、BioT5),未能充分利用通用大语言模型在长文档逻辑推理和跨领域知识整合方面的能力。
潜在路径:
- • 以 Q-Former 或类似轻量级投影模块为接口,将分子表示注入冻结的通用 LLM(如 LLaMA、GPT-4 系列)
- • 探索分子-文本-图像-音频的跨模态通用基础模型,实现生物医学知识与通用世界知识的双向迁移
- • 通过 PEFT 技术(如 LoRA)使通用 LLM 高效适应分子任务,降低计算门槛
十、代表性方法汇总
按任务分类
应用任务 | 代表性方法 | 主要特点 |
|---|---|---|
分子生成 | TamGen, MolGPT, ChatMol, Lingo3DMol, 3DSMILES-GPT | 自回归预训练;强化学习微调 |
分子性质预测 | graphMVP, 3D-Infomax, MOLEBLEND, KANO, MolLM, MoleculeSTM | 对比学习为主;2D/3D 多模态融合 |
DDI 预测 | MRCGNN, H2D, HetDDI, CSCo-DTA | 图对比学习;异质图神经网络 |
DTI 预测 | DrugLAMP, BioT5, MoMu | 掩码/对比学习;提示学习微调 |
分子描述生成 | MolT5, MolCA, GIT-Mol, MolFM, 3D-MOLM, UniMoT | Q-Former 架构;文本-分子双向翻译 |
按预训练任务分类
预训练任务 | 代表方法 |
|---|---|
对比学习 | graphMVP, 3D-Infomax, MoleculeSTM, GeomGCL, MIRACLE |
掩码预测 | ISMol, MolT5, BioT5, GIT-Mol, U2-3DPT |
匹配预测 | MolCA, ISMol, MGIB |
自回归预测 | TamGen, MolGPT, Lingo3DMol, ChatMol, UniMoT |
多任务组合 | MOLEBLEND, KANO, MolFM, 3D-MOLM |
写在最后
文章贡献
- 1. 系统性:覆盖多模态分子表示的六种模态形式、五类神经网络框架、四类预训练任务和三种训练策略,构建了完整的知识体系
- 2. 前瞻性:明确归纳"Transformer+GNN 融合"与"分子文本桥接 LLM"两大趋势,为后续研究指明方向
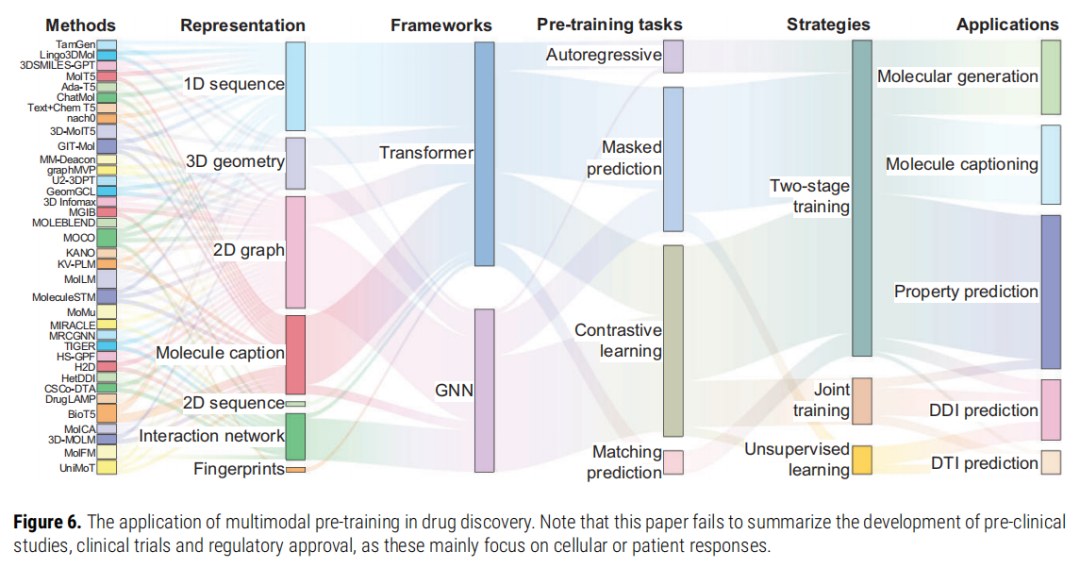
- 3. 实用性:图 6 的全景汇总图(方法-表示-框架-任务-策略-应用的多维映射)具有极高的检索参考价值
- 4. 开放性:配套 GitHub 仓库(https://github.com/AISciLab/MultiPM4Drug)整理了关键参考文献,方便复现追踪
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号