下一代多肽药物:AI驱动的超天然氨基酸全流程设计体系

下一代多肽药物:AI驱动的超天然氨基酸全流程设计体系

DrugIntel
发布于 2026-05-29 12:59:27
发布于 2026-05-29 12:59:27
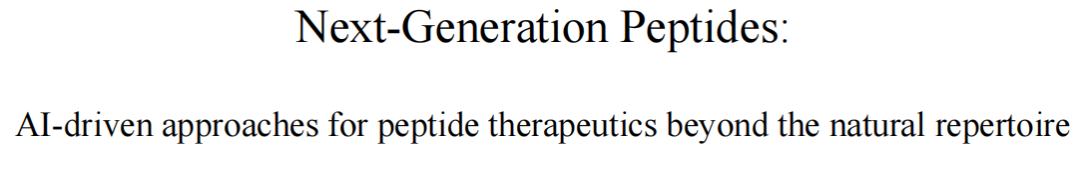
原文信息 题目:Next-Generation Peptides: AI-driven approaches for peptide therapeutics beyond the natural repertoire 作者:Gökçe Geylan 类型:博士学位论文 发表年份:2026 DOI:10.63959/chalmers.dt/5824
一、研究背景与动机
1.1 多肽药物的战略价值
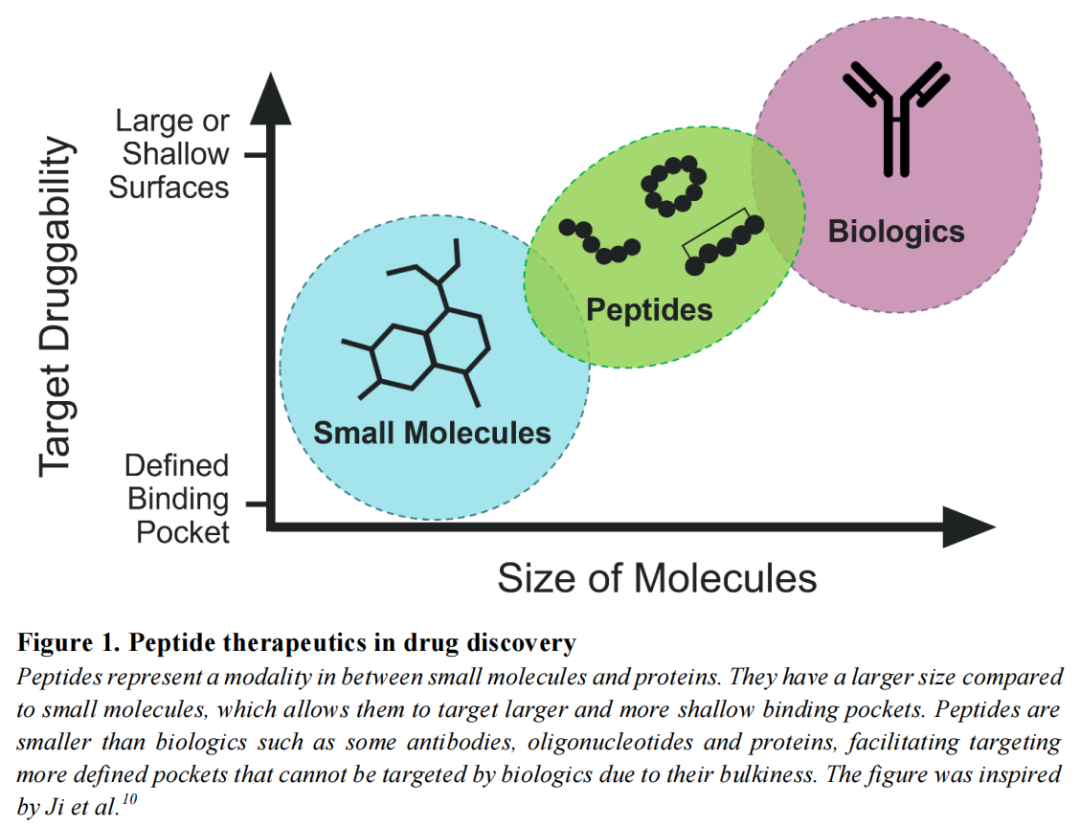
多肽(Peptide)作为介于小分子药物与大分子生物制剂之间的"第三条路线",近年来在药物研发领域的战略地位急剧上升。2023年,司美格鲁肽(Semaglutide)凭借减重适应症创下全球药物销售纪录,将多肽疗法的潜力推向公众视野。事实上,多肽类药物凭借其独特的物理化学特征,已在多个治疗领域形成不可替代的优势:
- • 靶点适配性优势:多肽拥有较大的分子表面积与模块化结构,可靶向小分子无法涉足的浅表或大面积结合口袋,尤其擅长干预蛋白-蛋白相互作用(PPI)——这类靶点约占全部潜在药物靶点的60%以上。
- • 安全性优势:天然来源或类天然结构使多肽具有较低的免疫原性与脏器毒性,副作用谱相较于合成小分子更为温和。
- • 膜通透性潜力:部分环状多肽(尤其是含疏水修饰者)可通过被动扩散穿越细胞膜,这是蛋白质类生物制剂所不具备的能力,使其具备口服生物利用度与胞内靶点可及性的发展空间。
- • 生产与修饰的便利性:相比抗体等大分子,多肽的化学合成成本更低,序列与化学空间的可修饰性更强。
1.2 核心瓶颈:优化难题的三重挑战
然而,多肽药物的研发并非坦途。将一条具备初步活性的多肽命中物(Hit)发展成为可上市的独立药物(Standalone Drug),必须在以下三个维度同时满足苛刻的多参数优化(MPO)要求:
挑战维度 | 具体问题 |
|---|---|
代谢稳定性 | 天然肽键对蛋白酶高度敏感,胃肠道中的胃蛋白酶可迅速将其水解,导致口服生物利用度极低;血浆半衰期通常以分钟至小时计 |
膜通透性 | 多肽骨架亲水性强,难以自发穿越脂质双分子层,限制其对胞内靶点的可及性 |
溶解度 | 增强通透性往往需要引入疏水基团,而溶解度与通透性之间存在固有张力 |
专利保护 | 由天然氨基酸构成的多肽序列若与自然界已知序列相似,则难以获得有效专利保护 |
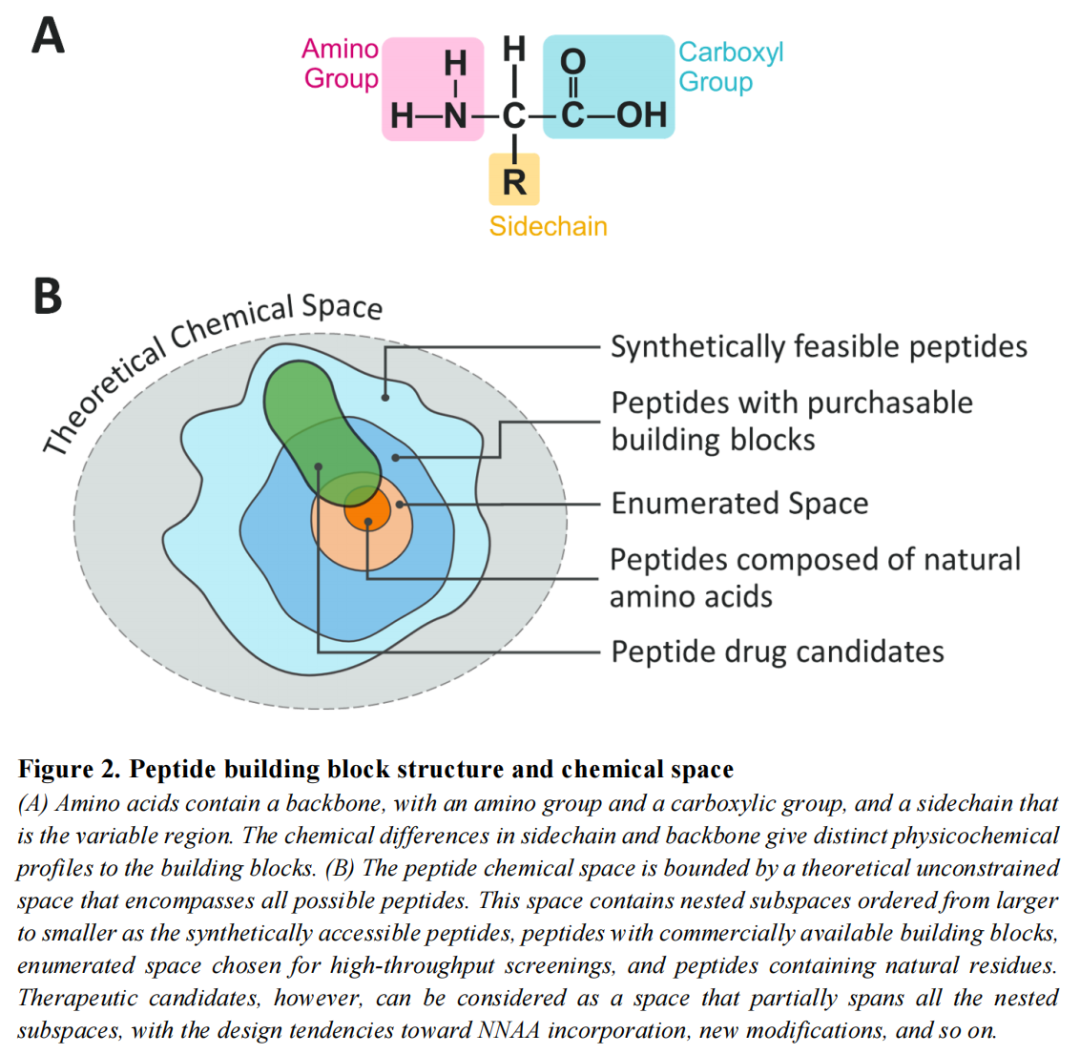
1.3 非天然氨基酸(NNAA)的引入:化学空间的爆炸性扩张
解决上述挑战的核心策略之一是引入非天然氨基酸(Non-Natural Amino Acids, NNAAs)。从化学视角看:
- • 天然蛋白质编码的20种氨基酸构成了最小的"天然多肽化学空间";
- • 数量庞大的NNAAs(据估计可合成的小分子化学空间约达10^60种)使多肽化学空间近乎无界;
- • 骨架N-烷基化、立体构型反转(D-氨基酸)、侧链延伸/环化等修饰手段可系统性调控多肽的ADME性质。
司美格鲁肽中仅含一个NNAA(2-氨基异丁酸,Aib),便足以显著提升酶降解抵抗力、延长半衰期,从而支撑每周一次的给药方案。
然而,这一化学空间的扩张也带来了计算与实验层面的双重挑战:
- 1. 化学空间规模呈指数级增长(n个构建块×L个位置 = n^L种组合),传统枚举筛选难以穷尽;
- 2. 每个新型NNAA在用于固相多肽合成(SPPS)前均需完成独立的合成设计与保护基策略规划;
- 3. 现有AI工具绝大多数仅支持20种天然氨基酸,无法处理NNAAs,形成能力缺口。
正是在这一背景下,本论文系统构建了覆盖"设计—预测—合成评估"全流程的AI工具链,为NNAA驱动的下一代多肽药物研发提供了完整的计算解决方案。
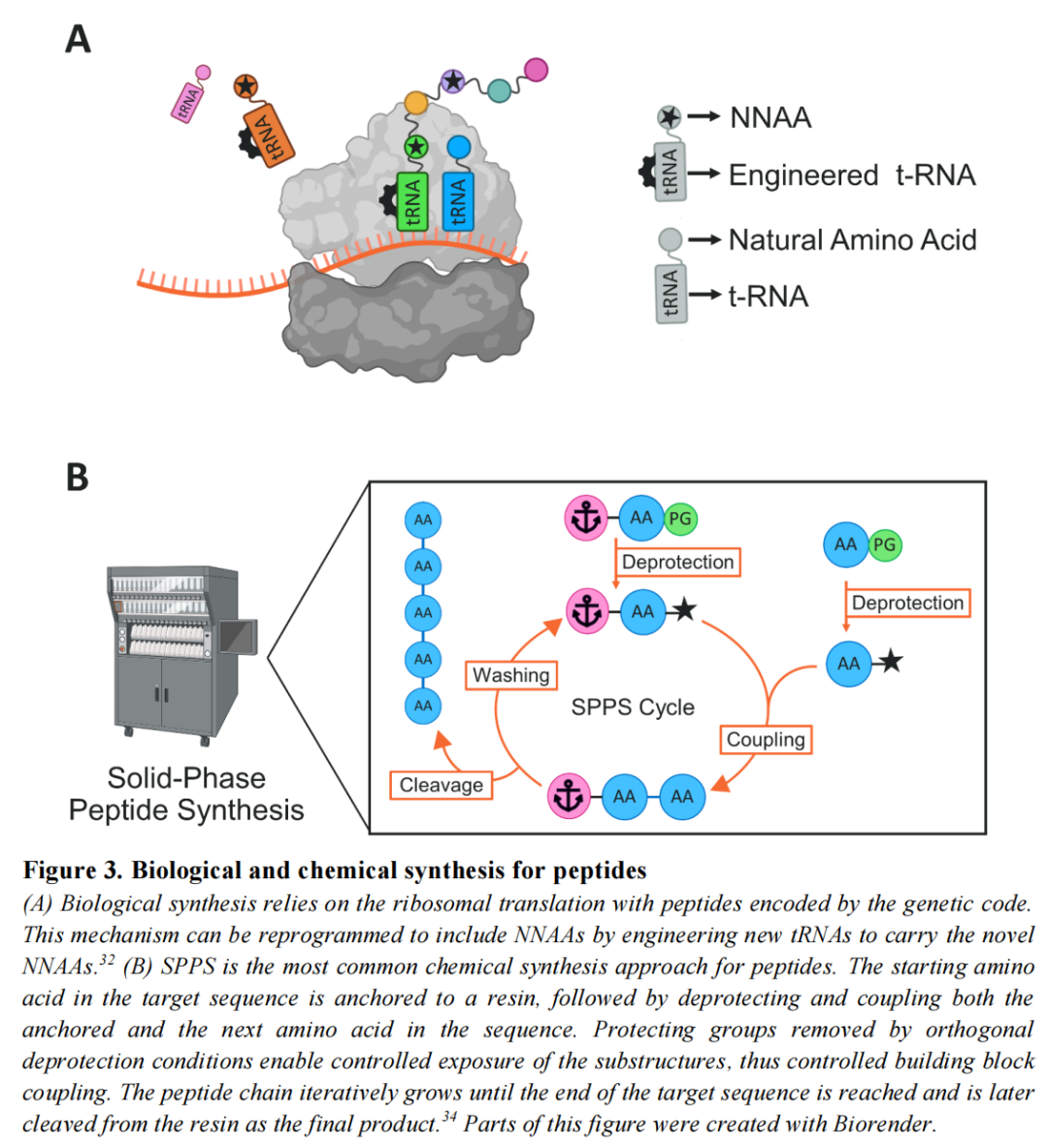
二、研究框架与论文结构
本论文以三大核心问题为主轴,对应四篇发表或在投的学术论文:
研究框架
├── 设计层:如何生成化学多样、含NNAA的多肽候选分子?
│ └── Paper I:PepINVENT — 生成式多肽设计模型
│
├── 预测层:如何可靠评估生成分子的药理性质?
│ ├── Paper II:环状多肽膜通透性预测的适用域方法论
│ └── Paper III:不确定性感知评分融入强化学习优化循环
│
└── 合成层:如何评估设计分子的实际可合成性?
└── Paper IV:NNAA-Synth — NNAA合成规划与可行性评估工具这一框架的独特之处在于将多肽设计问题重新定义为小分子配体设计问题——氨基酸本质上是小分子,因此针对小分子开发的一整套AI工具(生成模型、逆合成规划、ADME预测)均可迁移应用于含NNAA的多肽,从而绕开多肽领域标注数据严重匮乏的核心困境。
三、Paper I — PepINVENT:超越天然氨基酸的生成式多肽设计
3.1 方法创新:从序列语言到化学语言
现有多肽生成模型普遍将氨基酸视为离散符号(如字母"A"代表丙氨酸),本质上是在序列空间中进行组合搜索。这一范式有两大根本局限:
- 1. 固定词表问题:模型只能生成词表内的氨基酸,无法探索词表外的新型NNAA;
- 2. 化学盲问题:模型不理解氨基酸的原子级化学结构,无法感知结构相似性或化学合理性。
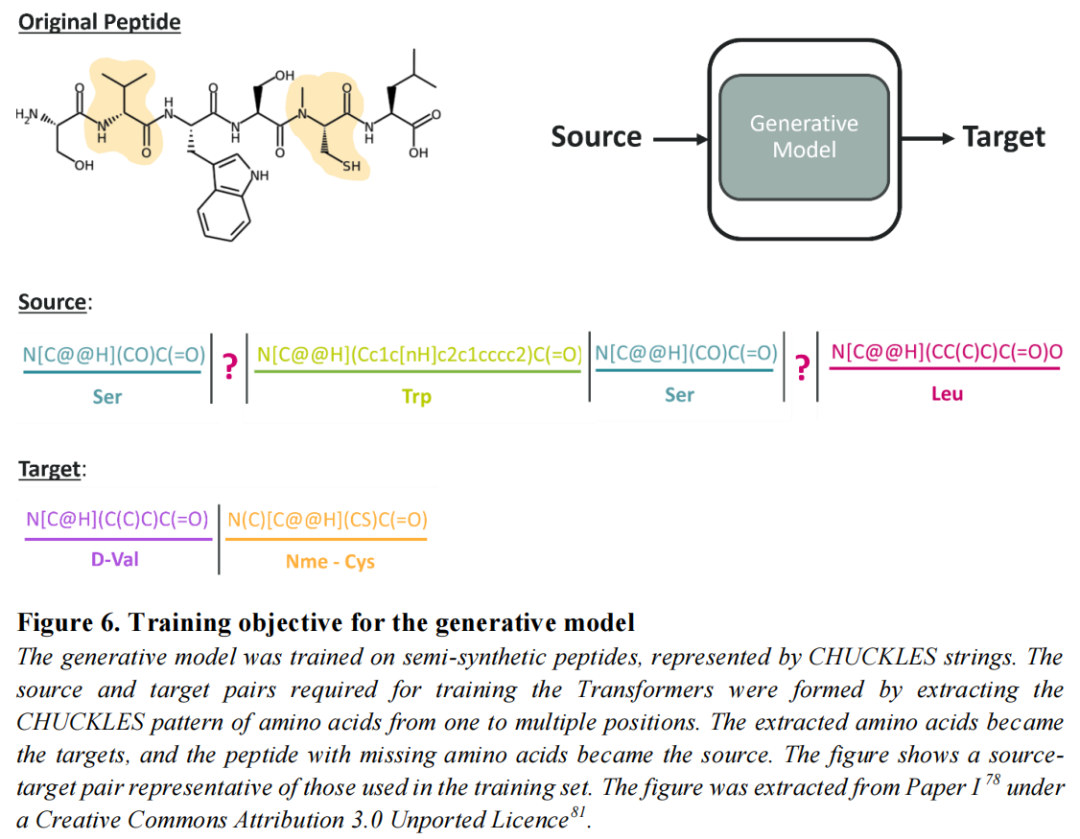
PepINVENT的核心创新在于采用原子分辨率的化学表示——以CHUCKLES格式编码每个氨基酸的完整SMILES字符串,将多肽序列转化为原子级的化学语言。这一转变的意义在于:
- • 模型不再受限于预定义词表,理论上可生成任意化学结构的氨基酸;
- • 原子级表示天然支持化学有效性约束,保障生成分子的化学合理性;
- • 模型可学习氨基酸的化学相似性,实现结构感知的迁移与泛化。
3.2 数据工程:百万半合成多肽训练集
为克服标注数据稀缺的问题,论文采用半合成数据生成策略构建训练集:
- • 规模:共生成100万条半合成多肽(训练集90%,验证集5%,测试集5%);
- • 建筑块多样性:融合20种天然氨基酸 + 10,000种NNAAs(来自Amarasinghe等人枚举的α-氨基酸库,均具备商业合成前体);
- • 拓扑多样性:线性肽、头尾环化、侧链-尾部环化、二硫键桥接等四种拓扑类型均衡分布;
- • 修饰多样性:涵盖立体构型变体(D-氨基酸)和骨架N-甲基化修饰。
训练任务设计(文本填充范式):随机遮蔽每条训练多肽中最多30%的氨基酸位置(替换为占位符"?"),将"含遮蔽位的多肽源序列"→"被遮蔽的氨基酸目标序列"构成有监督的配对训练数据。
这一设计直接对应实际的先导化合物优化场景:药效团残基固定,可修饰位点开放探索。
3.3 模型架构:Transformer + REINVENT强化学习框架
3.3.1 生成器架构
采用编码器-解码器Transformer架构,相较于循环神经网络(RNN)在处理多肽这类较长SMILES序列时具有显著优势——自注意力机制可有效捕获长程依赖,避免RNN在序列延伸时的化学有效性衰减。
模型形式化描述为:
训练目标为最小化目标序列的负对数似然(NLL):
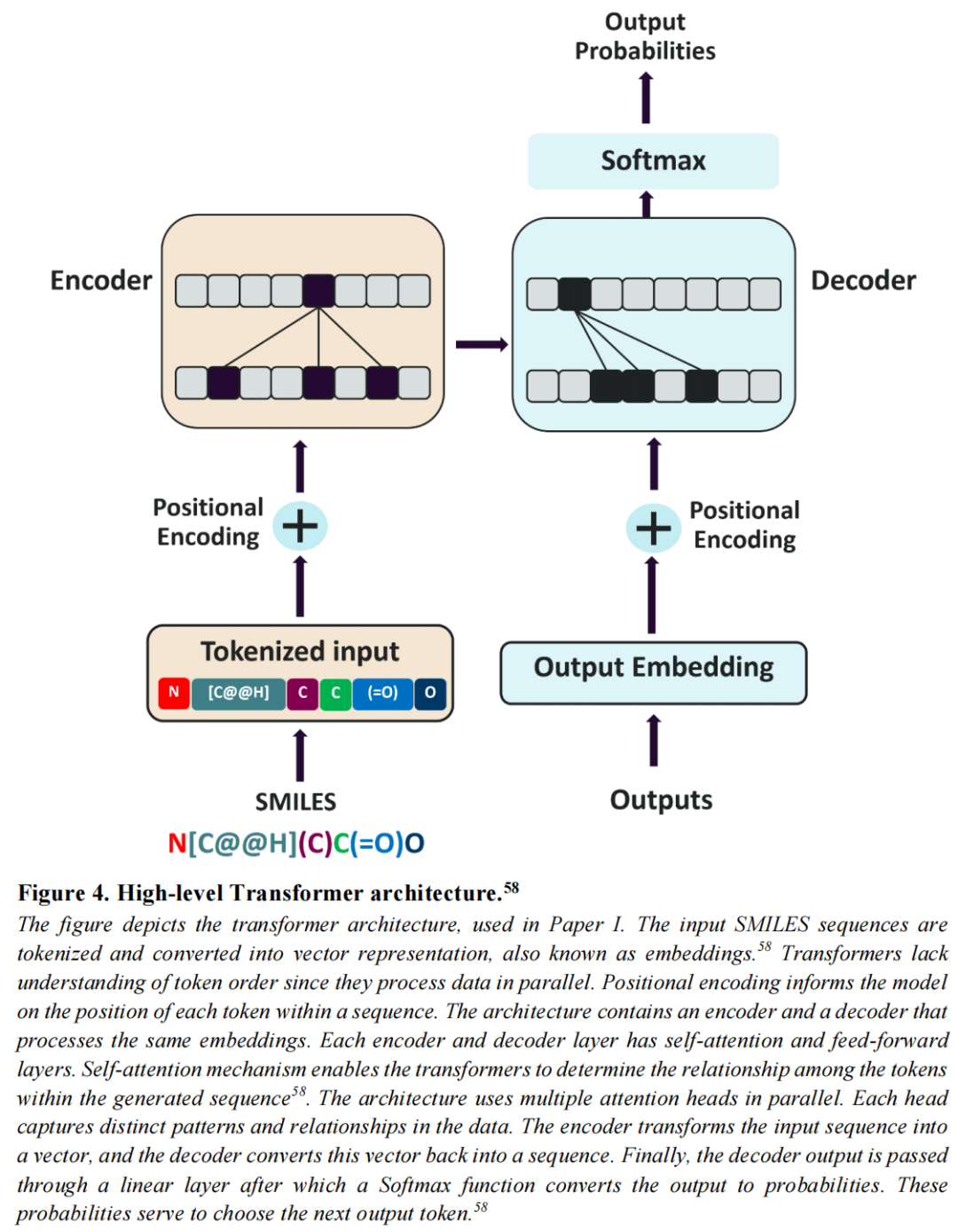
3.3.2 强化学习优化框架
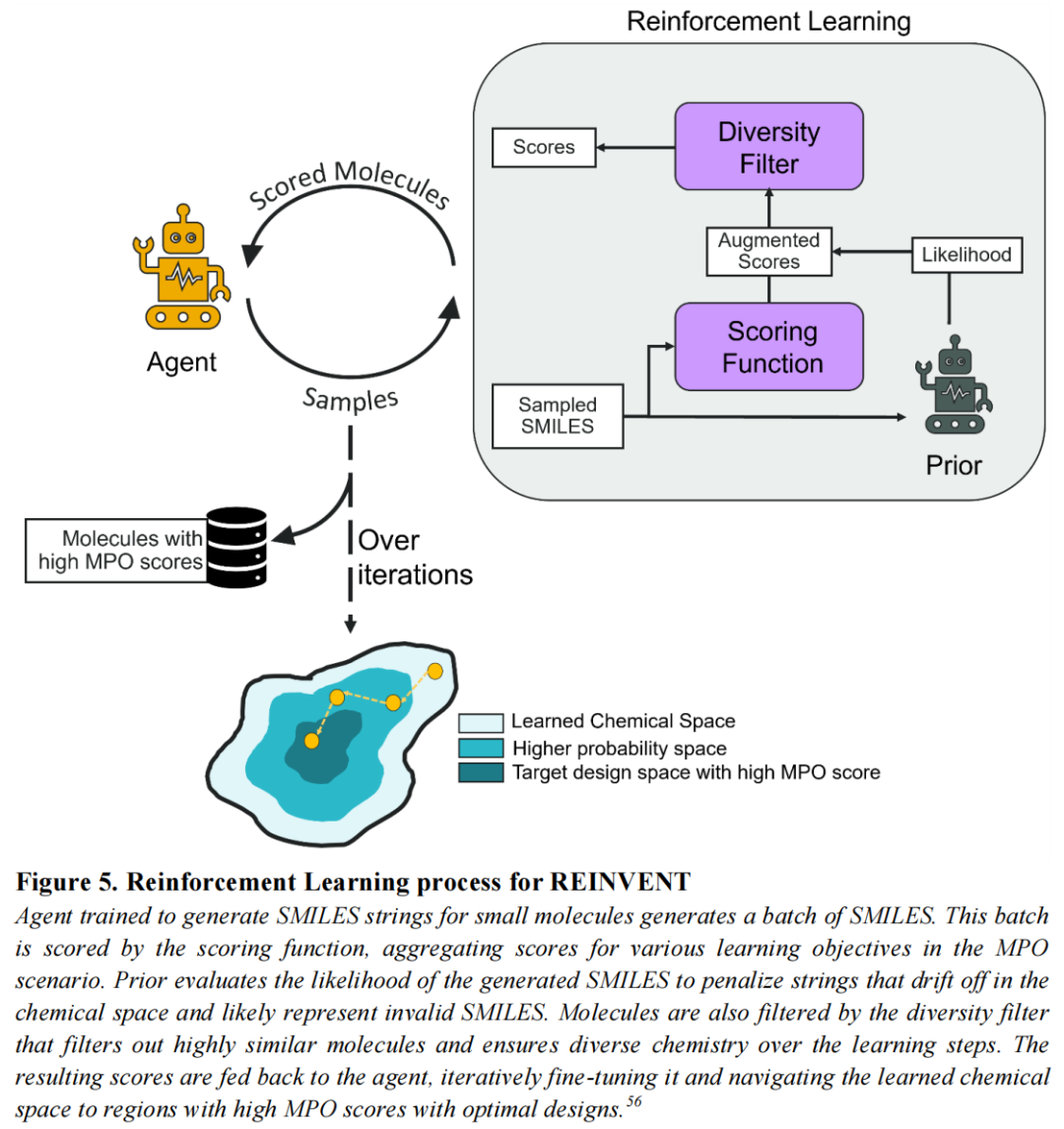
基于REINVENT的策略梯度框架,将生成器(Agent)与多目标评分函数(Scoring Function)耦合,实现性质导向的迭代优化:
- • Actor(智能体):Transformer生成器,通过多项分布采样生成多肽SMILES;
- • Prior(先验):预训练模型的静态副本,用于计算NLL正则化项,防止生成器过度偏离学习到的化学语法;
- • Scoring Function(评分函数):聚合多个评分组件,通过加权算术均值或几何均值合并: 或
- • Diversity Filter(多样性过滤器):惩罚高度相似骨架的重复生成,防止模态坍塌(Mode Collapse)。
3.4 性能评估结果
3.4.1 生成质量(400条测试多肽 × 1000次采样)
指标 | 集束搜索(Beam Search) | 多项采样(Multinomial) |
|---|---|---|
化学有效率(Peptide Validity) | 99% | 98% |
唯一性(Peptide Uniqueness) | 100% | 98% |
拓扑完成正确率 | — | 98% |
- • 任务完成几乎无失败:仅1个测试用例出现0.3%的位置数量错误;
- • 四种拓扑类型(线性/头尾环化/侧链-尾环化/二硫桥)表现一致,无拓扑偏好;
- • 单环结构的环闭合原子可被模型正确感知并在生成氨基酸中复现,证明模型捕获了多肽的长程化学依赖。
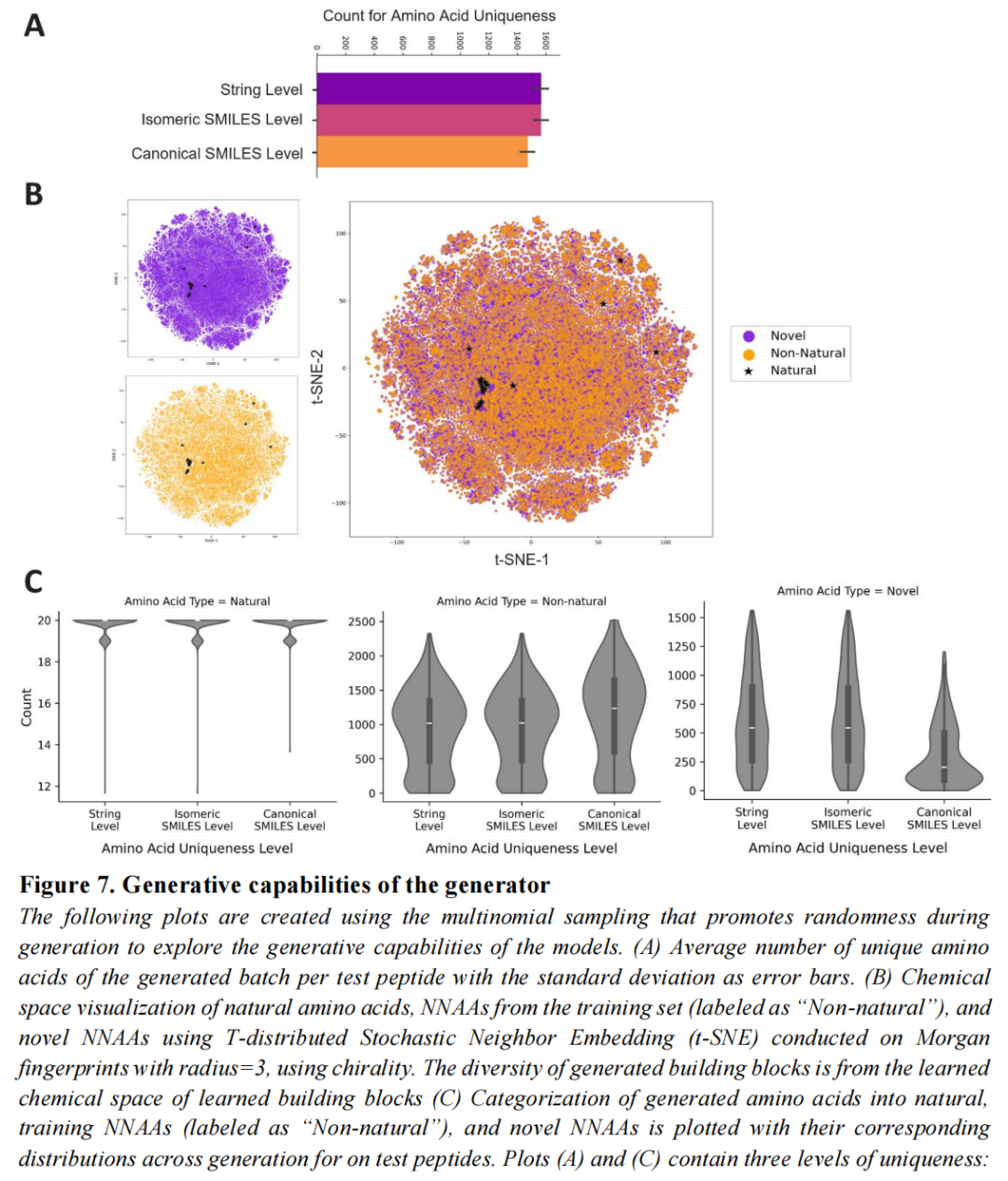
3.4.2 化学空间探索能力
在多项采样模式(探索模式)下,每条测试多肽平均产生:
- • ~1600条不同SMILES字符串 → ~1400种规范化学式不同的氨基酸;
- • 涵盖训练集天然氨基酸(重现已知)+ 训练集NNAAs(重现学习的非天然氨基酸)+ 全新NNAAs(侧链创新,超出训练集范围);
- • 新型NNAAs在化学空间中的分布紧邻训练集NNAAs的已知区域,说明模型在插值而非外推,符合可控的化学探索预期。
3.4.3 MPO应用案例
以一条与HIV复制通路靶蛋白结合的9肽药效团序列作为查询起点,设置六项评分组件(最大环尺寸、CAMSOL-PTM溶解度、膜通透性分类器、亚结构警报过滤、多样性过滤、环拓扑约束),运行1000步强化学习优化:
- • 溶解度与亚结构警报均在400步内收敛至高分区;
- • 通透性分类器预测概率从初始的0.13稳步上升至批次均值0.40~0.45,部分候选分子突破0.75;
- • 生成多肽的化学有效率全程维持在90%以上(探索阶段)至95%以上(利用阶段)。
3.5 局限性说明
- • 较长多肽的泛化性尚未充分验证,目前集中于10肽以内;
- • 双环、钉合肽(Stapled Peptide)等复杂拓扑未涵盖于训练集;
- • 合成可行性约束在生成阶段未内嵌,需后处理评估(由Paper IV解决);
- • 强化学习收益在遮蔽位点极少时受限,大幅度性质跃迁需要较多可修饰位点。
四、Paper II — 环状多肽膜通透性预测:适用域方法论
4.1 问题背景:公开数据集的结构性缺陷
细胞膜通透性是多肽药物进入胞内靶点的必要条件。PAMPA(平行人工膜通透性实验)以低成本、高通量著称,是公开通透性数据最为丰富的来源。CycPeptMPDB数据库汇聚了35项发表研究中的6,876条环状多肽通透性数据(PAMPA实验,log P > -6判定为可通透)。
然而,这一数据集存在两个严重的结构性缺陷,对预测模型的开发产生根本性影响:
缺陷一:类别不平衡 研究人员倾向于发表"成功"案例——即那些经修饰后变为可通透的多肽,导致数据集中可通透样本占比过高(各来源中"可通透"类占56%~90%)。
缺陷二:来源域高度不一致 不同研究团队采用不同的合成策略、修饰手法和多肽骨架,形成化学空间中高度分离的"岛屿"。PCA可视化清晰显示各来源数据集在化学空间中几乎无重叠,导致传统随机划分的训练/测试集评估严重高估模型的真实泛化能力。
4.2 评估框架设计
论文采用留一数据源评估(Leave-One-Source-Out Evaluation)策略,选取数据量最大的4个来源(Furukawa 2016 / Chugai 2013 / Kelly 2021 / Townsend 2020,各占总数据集9.7%~44.9%)逐一作为外部测试集,训练4种机器学习算法(RF / SVM / XGBoost / LightGBM),共建立16个模型。
分子描述符采用2048位手性感知Morgan指纹(半径r=4),保留立体化学信息以捕获D-氨基酸替换、N-甲基化等微小修饰。
4.3 共形预测(Conformal Prediction)方法论
4.3.1 CP基本原理
共形预测是一种分布无关(Distribution-Free)、模型无关(Model-Agnostic)的不确定性量化框架,其核心特性在于:在可交换性(数据独立同分布)假设下,以用户指定的置信水平为硬约束,统计保证预测集合的有效性。
具体流程(归纳式共形预测,ICP):
- 1. 训练集划分为"适当训练集"(用于模型训练)+ "校准集"(用于校准);
- 2. 对校准集每个样本计算非符合度分数(Nonconformity Score)——在本文中为模型预测属于某类别的概率;
- 3. 对新样本,基于其非符合度分数与校准集的比较计算共形p值(分别针对两类);
- 4. 根据用户指定的显著性水平α(=1 - 置信水平),输出预测集合:{可通透} / {不可通透} / {两者均可能} / {空集}。
采用Mondrian ICP(按类别独立校准)以处理类别不平衡,避免多数类主导校准结果。
二分类预测集合规则:
预测集
输出 | 含义 | 有效性要求 |
|---|---|---|
单一类别 {0} 或 {1} | 高置信度单标签预测,效率最高 | 预测类别须为真实类别 |
双类别 {0,1} | 模型无法在该置信水平下区分两类 | 真实类别涵盖于集合内(有效但低效) |
空集 ∅ | 非符合度异常,置信水平无法满足 | 可视为预测失败(需人工审核) |
评估指标:有效性(Validity) = 正确单标签 + "两者均可" / 真实类别样本数;效率(Efficiency) = 单标签预测数 / 真实类别样本数。
4.3.2 三种校准策略的系统比较
校准策略 | 校准集组成 | 有效性 | 效率 |
|---|---|---|---|
源域校准(基线) | 训练集的随机分层子集 | 高(但在目标域虚高) | 低(大量"两者均可"输出) |
混合校准 | 源域校准集 + 20%目标域样本 | 轻微下降 | 中等提升 |
目标域校准(最优) | 100%目标域少量代表性样本 | ≥80%(满足置信水平要求) | 显著提升 |
核心结论:校准集与测试集的可交换性是共形预测效率的决定因素。仅需少量目标域实验数据(样本量远小于有效重训练所需)对已训练模型进行重校准,即可在无需重新训练模型的前提下,将模型适用域扩展至新的化学空间,且统计有效性有保证。
这一结论对于实际的多肽药物研发具有重要工程价值:研究团队只需对新化学系列的少量化合物进行实验表征,即可使现有预测器在该新化学空间获得可靠预测能力。
五、Paper III — 不确定性感知评分融入强化学习反馈循环
5.1 问题的根本性
在Paper I建立的PepINVENT生成框架中,强化学习依赖评分函数对每步生成的多肽批次进行评分。当预测模型(如通透性分类器)被用作评分组件时,存在一个根本性问题:
随着强化学习引导生成器探索越来越新颖的化学空间,生成的多肽逐渐偏离预测模型的训练分布,模型进入适用域外(Out-of-Domain)区域,其预测实质上退化为随机猜测。
在此情况下,高模型预测值(如"通透概率=0.9")并不意味着真实的通透可能性高,而可能仅仅反映模型在陌生化学空间中的无根据自信(Overconfidence)。这会导致强化学习被误导,在无法可靠预测的化学区域"狂奔"而不自知。
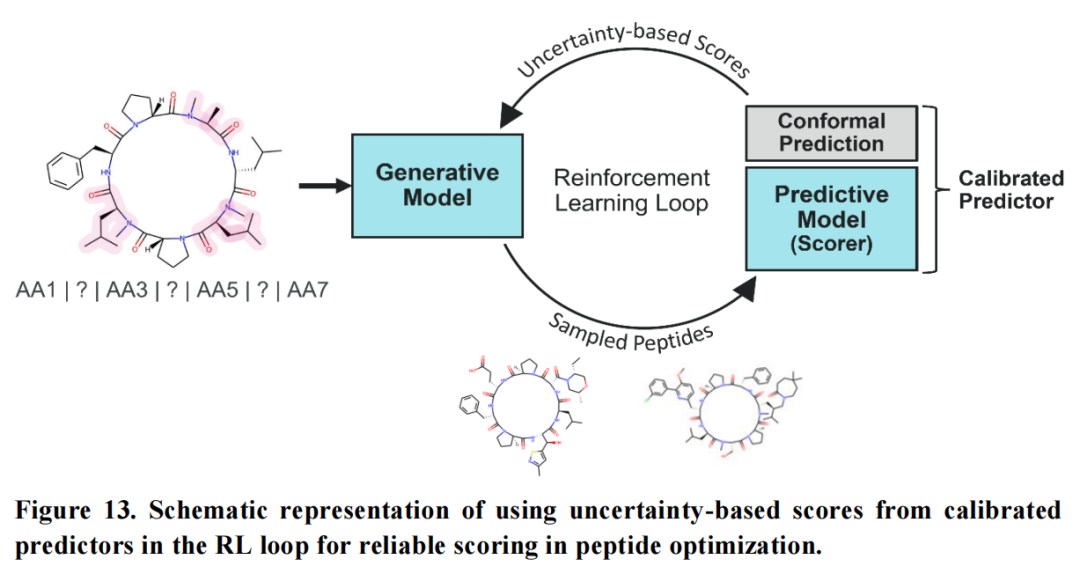
5.2 六种奖励策略的系统基准测试
论文在150条测试多肽(6-/7-/10-mer环状多肽,来自Baker et al.独立数据集,未用于模型训练与校准)上,对比了六种将通透性预测融入RL奖励的策略,监控350步学习过程中P0(非通透类共形p值)与P1(通透类共形p值)的演化:
策略 | 奖励信号 | 过渡点(步数)↓越小越好 | P0均值最终达到 < 0.2? |
|---|---|---|---|
基线:原始模型概率 | P(通透类) | 163 | 否 |
最大化P1 | CP p1 | — | 否 |
最大化1-P0 | CP 1-p0 | — | 否 |
最大化P1-P0 | CP p1-p0差值 | — | 否 |
严格奖励(Harsh) | 二元:P0≤0.2且P1≥0.2得1,否则得0 | 110 | 否(350步内未达到) |
软性奖励(Soft) | 分段:同时满足得1,单一满足得0.5,否则得0 | 77 | 是 |
过渡点定义为批次平均P1首次超越P0的学习步骤——代表生成器开始稳定生产被预测为"可通透"类别的多肽。
软性奖励函数的形式化定义:
(单条件满足)(双条件满足)
5.3 关键发现与机制解析
- • 软性奖励的效率优势:通过对"部分满足"状态给予中间奖励(0.5分),软性函数为生成器提供了更平滑、更连续的优化梯度,而严格奖励的稀疏信号导致生成器长期处于"无梯度"区域,收敛极慢;
- • 化学多样性未受损:与基线方法相比,软性奖励条件下生成多肽的Tanimoto相似度分布无显著差异,说明置信度约束未造成多样性坍塌;
- • 化学有效性保持:软性奖励产生的有效多肽数量与基线相当(Wilcoxon检验p<0.05仅针对严格奖励,软性奖励无统计差异);
- • 全面超越孤立p值策略:单独最大化P1或1-P0均无法同时满足Mondrian ICP的双类别决策要求,说明两类p值的联合决策特性需要在奖励函数中得到整体体现。
六、Paper IV — NNAA-Synth:从分子设计到固相合成的全链路可行性评估
6.1 问题的多层次复杂性
当生成式模型(如PepINVENT)提出含新型NNAA的多肽时,实验验证面临两层合成挑战:
第一层:NNAA本身是否可合成? 许多新型NNAAs不具备商业供货,需要作为小分子合成问题独立规划多步合成路线。
第二层:合成的NNAA是否具备SPPS兼容性? 即便NNAA可以合成,若其所有活性基团无法被正交保护基体系有效保护,则无法直接用于固相多肽合成(SPPS)。正交性要求不同活性基团的保护基在各自特异的去保护条件下独立脱除,互不干扰。
仅评估NNAA的"小分子合成可行性"而忽略保护基策略,可能导致合成可行性判断严重失真(例如,一个"易合成"的NNAA可能因无法实现有效正交保护而完全无法用于SPPS)。
6.2 NNAA-Synth工具链架构
NNAA-Synth是一个端到端的三模块工具链,输入为任意NNAA的SMILES字符串,输出为各保护形式对应的合成可行性评分:
NNAA (SMILES)
│
▼
[模块1] 化学信息学保护基规划工作流
│ ├── SMARTS活性基团检测(骨架氨基/羧基 + 侧链活性基)
│ ├── 骨架保护:Fmoc (氨基, 碱性脱除) + tert-Butyl (羧基, 酸性脱除)
│ └── 侧链保护:正交选项(Bn / Allyl / PMB / TMSE,需氢化/氧化/氟化脱除)
│ → 输出:1 至 32 种正交保护形式
│
▼
[模块2] AiZynthFinder 逆合成规划
│ ├── 蒙特卡洛树搜索 (MCTS) + 神经网络决策
│ ├── 反应模板库:USPTO专利数据训练
│ ├── 起始原料库:eMolecules + 保护基化合物
│ └── 特殊处理:复杂保护基视为整体,优先寻找含保护基的商业原料
│ → 输出:每种保护形式的多条候选合成路线
│
▼
[模块3] 双模型合成可行性评分
├── Chemformer可行性评分(反应级别)
│ ├── 预训练Transformer,输入反应物 → 预测产物Top10
│ ├── 真实产物在Top10内 → 步骤得分 = 产物似然
│ ├── 不在Top10内 → 步骤得分 = 0
│ └── 路线总分 = 各步骤得分之积(0分为过滤器,剔除不可行路线)
│
└── 专家增强可行性评分(路线级别)
├── 描述符:反应级 + 路线级 + 目标分子级特征
├── 预测路线可行性:"Good"(<5分)/ "Plausible"(5-9分)/ "Bad"(≥9分)
└── 融合:到历史数据的潜空间距离 + 路线长度惩罚两个模型的互补性:Chemformer在单步化学反应合理性上具有局部精确度,专家增强模型在路线整体质量评估上具有全局视角;双模型联合评分的鲁棒性显著优于单一模型。
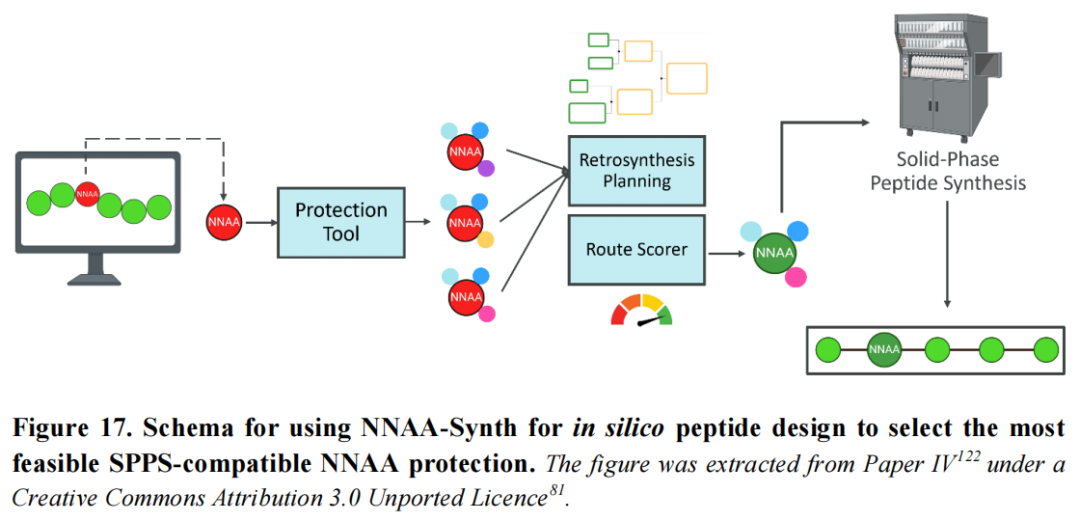
对9,985个公开NNAAs进行系统评估,保护基规划产生15,508种保护形式(约1/3的NNAAs需要侧链保护,最多产生32种保护变体):
评估维度 | 完整保护库(15,508个) | 最优保护子库(9,985个,每个NNAA选最优保护) |
|---|---|---|
起始原料可及性 | 89.26% ± 10.40% | 89.19% ± 11.27% |
平均反应步数 | 8.95 ± 4.92 | 8.60 ± 4.98 |
Chemformer可行性评分(均值) | 0.05 ± 0.15 | 0.07 ± 0.16 |
专家增强可行性评分(均值,越低越好) | 8.63 ± 5.48 | 7.86 ± 5.40 |
不可行比例(任何保护形式下) | — | ~17% |
路线直达可购买前体比例 | — | ~25% |
关键发现:简单的路线统计指标(步数、前体可及率)不足以区分建筑块的合成难度,需要结合双模型可行性评分进行综合判断。
6.4 案例研究一:最优保护策略选择
以NNAA "2G6"为例(含侧链活性基,生成4种正交保护形式):
保护组合 | 反应步数 | 前体可及率 | Chemformer评分 | 专家增强评分 | 综合结论 |
|---|---|---|---|---|---|
Fmoc + tBu + Allyl | 3 | 100% | 0.137 | 4.31(Good) | 推荐 |
Fmoc + tBu + Bn | 3 | 100% | 0.344 | 5.12(Plausible) | 可行 |
Fmoc + tBu + PMB | 5 | 100% | 0.011 | 7.13(Plausible) | 一般 |
Fmoc + tBu + TMSE | 17 | 90% | 0.001 | 19.91(Bad) | 不推荐 |
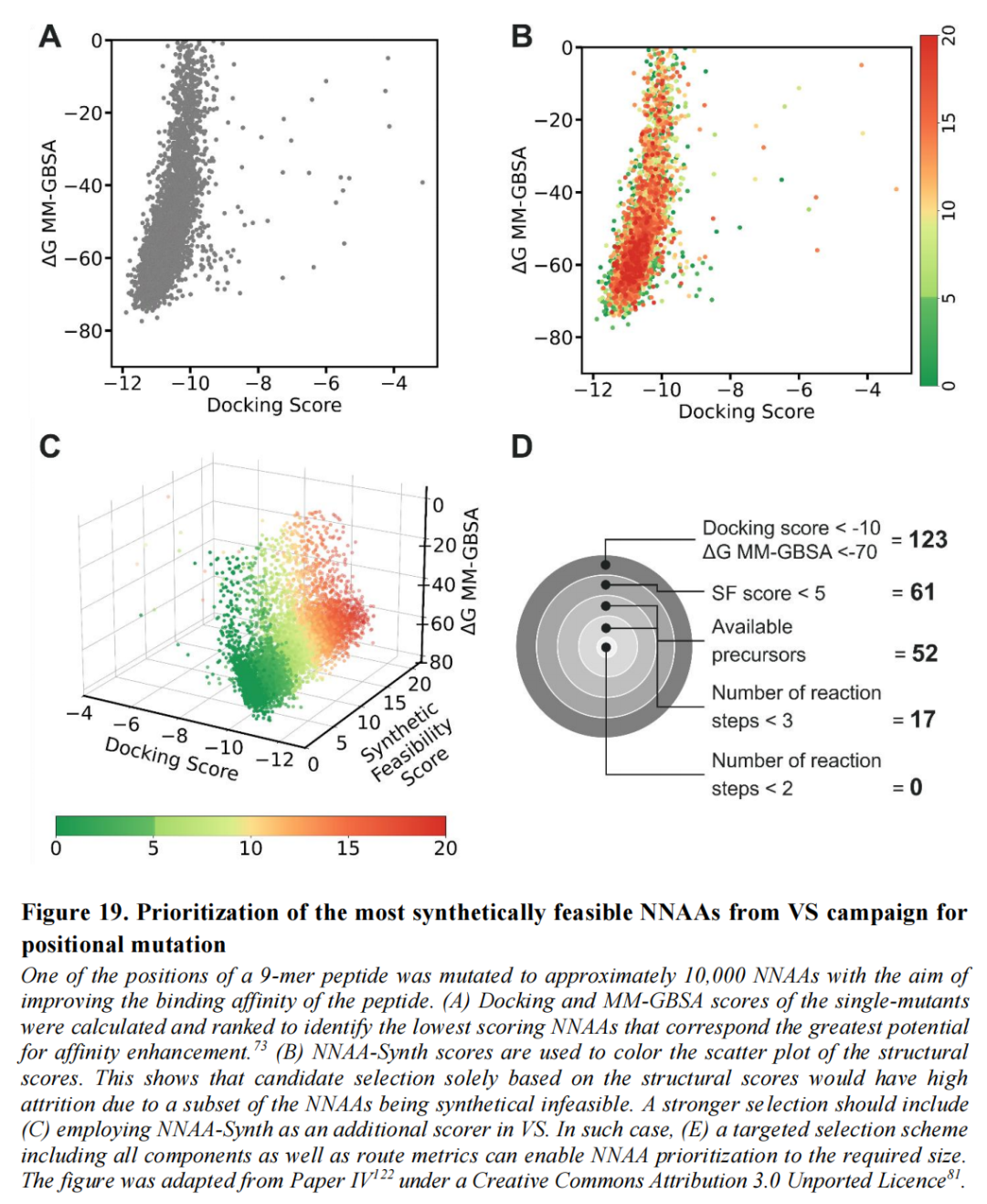
6.5 案例研究二:虚拟筛选后处理中的NNAA优先级排序
将NNAA-Synth作为结构筛选后的合成可行性过滤层,对某9肽单点突变的约10,000个NNAA变体进行三维优先级排序(对接评分 × MM-GBSA评分 × NNAA合成可行性):
全部NNAA变体(~10,000个)
└── 结构打分筛选(对接 < -10 且 MM-GBSA < -70):→ 123个候选
└── 合成可行性过滤(Expert-Augmented Score < 5):→ 61个候选
└── 前体可及性要求(Available Precursors):→ 52个候选
└── 反应步数约束(< 3步):→ 17个候选(推荐直接合成验证)这一案例有力证明:仅依据结构评分筛选出的"最佳"候选中,相当比例的NNAAs在实际合成中面临重大障碍,忽略合成可行性将造成严重的实验资源浪费与迭代延误。
七、方法论创新的全局评估
7.1 核心方法论贡献汇总
创新维度 | 具体贡献 | 解决的关键痛点 |
|---|---|---|
化学表示层 | CHUCKLES编码使多肽设计获得原子分辨率,突破固定词表限制 | 生成模型无法处理NNAA的根本障碍 |
数据工程层 | 百万半合成数据集跨越自然与非自然氨基酸边界 | NNAA标注数据稀缺问题 |
不确定性量化层 | 共形预测(CP)方法论系统化应用于多肽ADME预测 | 预测模型适用域外可靠性缺失 |
域适应层 | 目标域小样本重校准实现无需重训的适用域扩展 | 新化学系列模型迁移成本高 |
奖励函数层 | 共形效率作为RL奖励直接优化预测置信度 | 生成过程中模型漂移导致评分失真 |
合成评估层 | 保护基策略+逆合成+双模型评分的SPPS兼容合成可行性评估 | "可设计"到"可合成"的执行鸿沟 |
7.2 与现有工作的横向比较
维度 | 现有主流工作 | 本论文 |
|---|---|---|
氨基酸词表 | 固定于20种天然氨基酸,或少量预定义NNAA | 开放式:任意原子级化学结构 |
拓扑支持 | 通常单一拓扑(如仅线性或仅环状) | 线性/头尾环化/侧链-尾环化/二硫桥 |
不确定性量化 | 极少涉及,或仅使用模型内置置信度 | 分布无关共形预测,统计有效性保证 |
合成可行性 | 通常作为事后过滤,不考虑SPPS保护基需求 | 与SPPS保护基规划深度集成 |
数据依赖 | 依赖大量NNAA实验标注数据 | 将问题转化为小分子问题,复用小分子工具 |
八、当前局限性与未来展望
8.1 现有局限
- • 生成模型的拓扑边界:双环肽、Stapled Peptide等特殊拓扑未被训练集覆盖,泛化能力存疑;
- • 长肽的合成评估:NNAA-Synth目前评估的是建筑块级别可行性,未涉及完整肽链的SPPS整体效率(聚合效率、氨基酸组成对合成难度的系统影响);
- • 相同活性基团的多拷贝保护:当侧链含有多个相同活性基团时,NNAA-Synth统一施加同一保护基,无法实现位点特异性区分;
- • 结构感知的生成:当前生成框架基于序列优化,未融入蛋白结合口袋的三维结构信息;
- • 跨域可交换性阈值:目标域重校准的有效边界(即化学空间差异达到多大时重校准失效)尚未系统研究。
8.2 未来发展方向
- • 共折叠(Co-folding)驱动的结构打分:AlphaFold/AlphaFold3对多肽-蛋白质复合体结构预测的融入,可实现基于结合亲和力的直接结构优化;
- • 拓扑扩展:将双环肽、大环非肽杂环结构纳入训练集;
- • SPPS效率预测:开发基于序列组成的SPPS整体效率模型,从建筑块级升级至多肽链级的合成可行性评估;
- • 主动学习与DMTA闭环:将生成、预测、合成评估工具链与自动化合成平台的湿实验反馈形成真正的主动学习闭环;
- • 不确定性感知扩展:将软性共形效率奖励框架推广至更多ADME/活性预测任务,建立广义的"置信度引导生成"范式。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号