当「模数共振」成为国策,AI 产业的底层逻辑正在改写

当「模数共振」成为国策,AI 产业的底层逻辑正在改写

javpower
发布于 2026-05-26 19:56:04
发布于 2026-05-26 19:56:04
当「模数共振」成为国策,AI 产业的底层逻辑正在改写

9th Digital China Summit opens in Fuzhou - People's Daily Online
第九届数字中国建设峰会现场:中国信通院联合中车工业研究院发布国内首部模数共振权威研究报告
5 月,福州,数字中国建设峰会。
中国信通院联合中车工业研究院发布了一份报告——《人工智能模数共振体系研究报告(2026 年)》。这份报告没有上热搜,没有引发朋友圈刷屏,但它正在 quietly 改变中国 AI 产业的底层游戏规则。
报告的核心概念只有一个词:模数共振。
这不是一个营销词汇。2025 年 9 月,南京、济南、青岛、武汉、深圳等先导区共同启动了「模数共振」行动。2026 年 1 月,工信部等八部门联合发布的《"人工智能+制造"专项行动实施意见》中,明确写入了模数共振的相关要求。
从政策层面看,模数共振已经被抬到了国家战略的高度。但产业界真正该关心的,是它到底在解决什么问题。
传统 AI 的「线性断裂」病
报告里有一个很精准的诊断:传统人工智能数据集构建呈现出典型的「线性断裂」特征。
什么意思?数据预处理完就丢进模型训练,训练过程中产生的反馈信号被截断,数据集无法根据模型表现进行动态调优。场景覆盖有盲区,特征提取能力孱弱,质量管控失效。
翻译成人话:数据团队和模型团队各干各的,数据一次性交付,模型训完就部署,两者之间没有闭环。

Transforming Manufacturing with Digital Twins and Generative AI | FXMedia: Solutions for Metaverse
NVIDIA Data Flywheel:数据飞轮效应的本质是「用数据驱动模型,用模型反哺数据」
这种「线性断裂」的直接后果是,模型难以习得稳健的泛化特性,在复杂的业务实践中落地效果大打折扣。你花了几百万标注的数据,可能根本不适合你的模型;模型在测试集上表现很好,一到真实场景就崩。
模数共振体系要解决的,就是这个问题。
模数共振的本质:双向主动机制
报告给模数共振下的定义很清晰:
建立数据质量提升、模型优化与应用反馈的协同联动及闭环迭代机制,实现数据动态适配模型需求、模型输出反哺数据质量提升。
关键词是「双向主动」。
过去是「数据供给决定模型能力」的单向逻辑。现在是「模型需要引导数据进化,数据进化反哺模型升级」。报告里用了一个很形象的词:「好数育好模,好模引好数」。
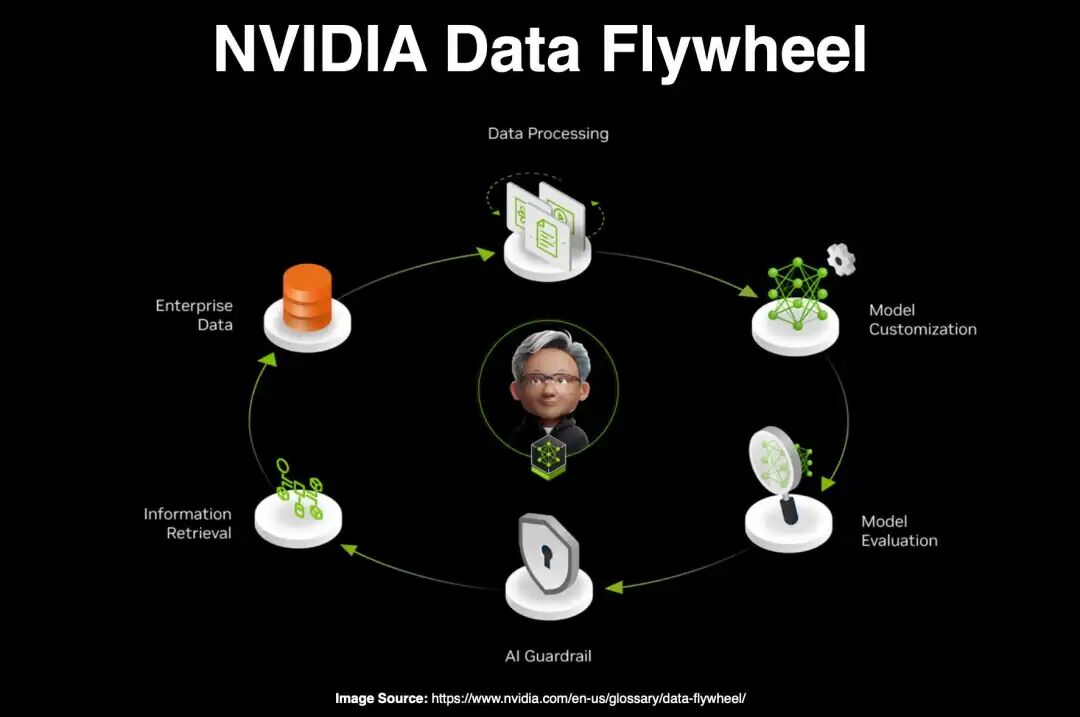
NVIDIA Data Flywheel. Exploring NVIDIA's Data Flywheel… | by Cobus Greyling | Medium
AI-Native Flywheel:数据、模型、产品、反馈、分发形成持续进化的飞轮
这个闭环怎么转?报告提出了三大核心要素、五大能力支撑、三大协同机制。
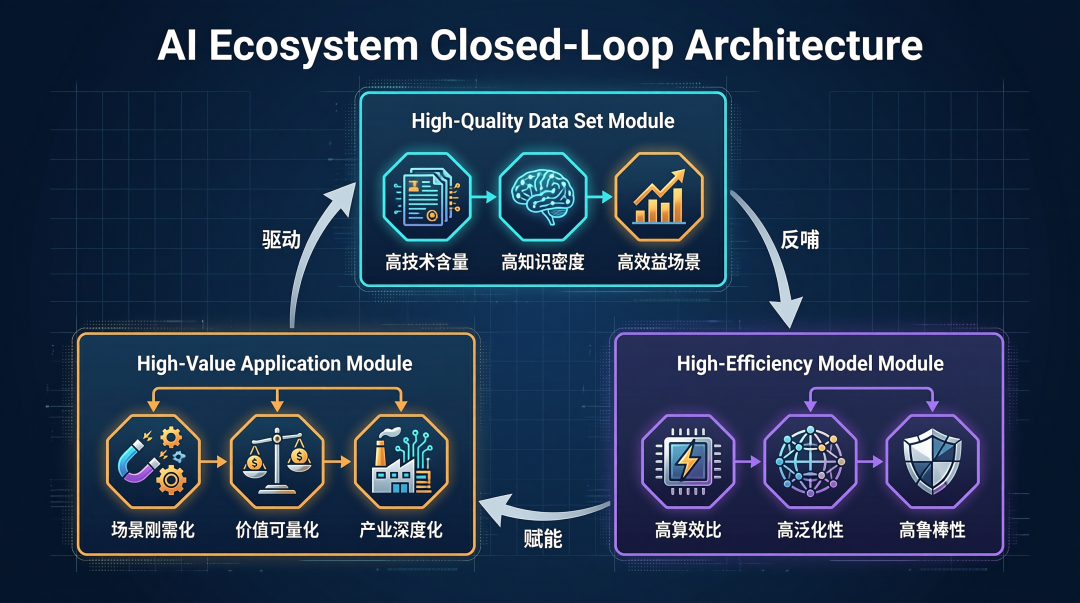
三大核心要素:数据、模型、应用

Transforming Manufacturing with Digital Twins and Generative AI | FXMedia: Solutions for Metaverse
智能制造数字孪生:模数共振的最终落点是产业深度化的高价值应用
高质量数据集是基石。报告提出了「三高」特征:高技术含量、高知识密度、高效益场景。不是简单堆规模,而是强调单位数据里的知识浓度。百度的人工智能数据智能标注平台内嵌百种智能算法,标注效率提升 50%;英伟达用 GAN 创建自动驾驶合成数据集,模拟暴雨暴雪等极端天气。
高效能模型是引擎。三个特征:高算效比、高泛化性、高鲁棒性。核心思路是「小参数、大智慧」——通过更高质量的数据和更优的训练策略,让中小模型在特定任务上超越盲目扩规模的巨量模型。
高价值应用是出口。三个特征:场景刚需化、价值可量化、产业深度化。ChestX-ray14 数据集支撑 AI 辅助诊断,肺炎识别速度达到人类的 160 倍;苏州阿丘科技的 PCB 缺陷检测,将过检率降低了 90%。
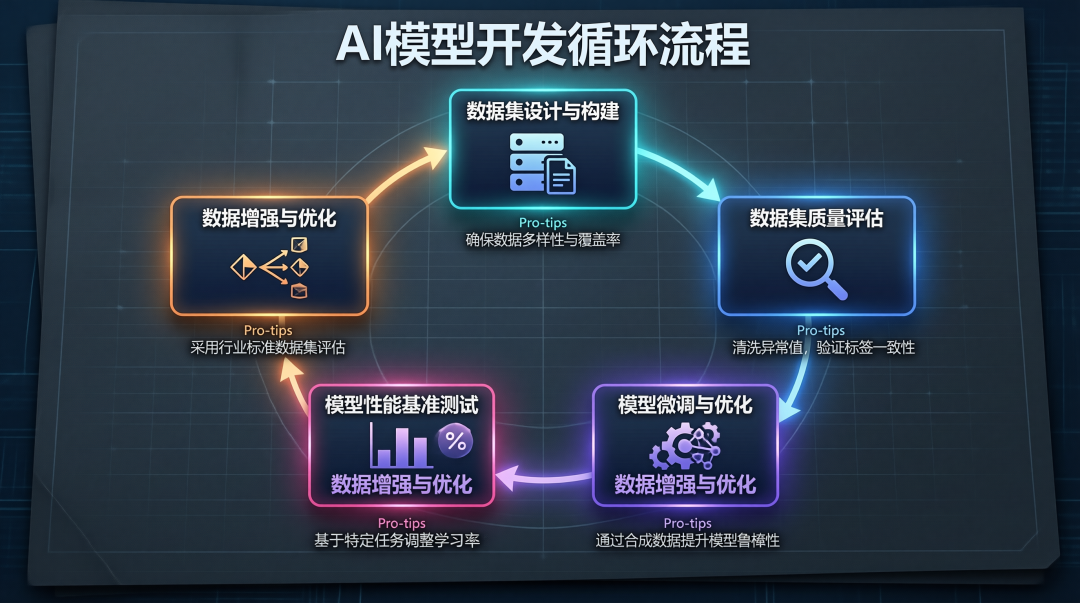
五大能力支撑:闭环怎么转起来
报告把闭环拆解成了五个环节:
环节 | 核心作用 |
|---|---|
数据集设计与构建 | 锚定模型需求,拆解为可量化的数据指标 |
数据集质量评估 | 信通院发布「可信 AI 数据集质量评估体系 2.0」,覆盖完整性、准确性、一致性、多样性、时效性、合规性 |
模型微调与优化 | 指令微调数据集结构化设计,参数「精准触达、最小干预」 |
模型性能基准测试 | 「方升」大模型基准测试体系 3.0,覆盖 BOT/GOT/AOT/IOT/AIOT 五个维度 |
数据增强与优化 | 基于性能反馈的「精准靶向」优化,分层分级修复数据质量 |
这五个环节不是线性串联,而是循环反馈。测试暴露的模型短板,回溯到数据源头;数据优化后,重新训练、重新测试、重新评估。
三大协同机制:让闭环自动跑起来
模型-数据关联映射关系是导航系统。不同模型类型对数据分布的需求完全不同:NLP 模型需要语义连贯性、句法规范性;CV 模型需要像素级清晰度、特征显著性;多模态大模型需要跨模态语义对齐。OpenAI 的 GPT-4o 和 DALL-E 3,就是两种完全不同的数据映射策略。
模数闭环迭代能力机制是生命力源泉。规则迭代、技术迭代、机制迭代三层驱动。优必选在打造 Thinker 通用基座模型时,建立了「弱监督+自监督+少量人工校验」的动态迭代体系,标注成本降低 99%,效率提升超百倍。
模型自适应性能测试系统是质检中枢。突破「固定测试集+单一指标」的局限,实现场景自适应、指标自适应、反馈自适应。商汤科技在自动驾驶测试中,构建「基础指标+核心指标+特色指标」的三层体系,全面评测复杂路况下的性能。
从「模数共振」到「数据飞轮」
报告的最后提出了一个愿景:
数据和模型的深度融合,最终实现「数据即模型、模型即数据」的共生状态。
这和 NVIDIA 的 Data Flywheel、Cursor 的 Post-Training 闭环,本质上是同一件事——让数据和模型形成自我强化的飞轮。
区别只在于,NVIDIA 和 Cursor 是在企业层面做闭环,而中国信通院和中车工业研究院,是在国家层面搭建这套体系。
报告给出了四条落地建议:
- 统筹推进行业数据集建设与模型优化:通识数据集+行业大模型做底座,专识数据集+特色智能体做垂直适配
- 持续完善模型性能评测能力机制:从单一评分向持续改进赋能演进
- 探索建立模数共振生态协同机制:打造「模数共振空间」创新载体,破解数据孤岛与信任难题
- 加强模数共振关键要素保障:技术攻关、标准引领、生态培育、人才建设
架构文章推荐
Claude Code 团队协作实战:统一风格、约束边界、共享配置、审查流程 作者:刘宏宇 阅读原文
这篇文章和模数共振报告形成了有趣的呼应。
模数共振讲的是数据和模型的协作闭环。刘宏宇的文章讲的是AI 编程工具在团队中的协作闭环——统一风格、约束边界、共享配置、审查流程。
两者共同指向一个趋势:AI 时代的协作,核心不是「谁更聪明」,而是「谁更懂规则」。
当 Claude Code 这样的 AI 编程工具进入团队,代码审查的流程、风格约束的边界、共享配置的管理,都需要被重新定义。这和模数共振中「规则迭代」的逻辑完全一致——工具在变,协作规则必须跟着变。
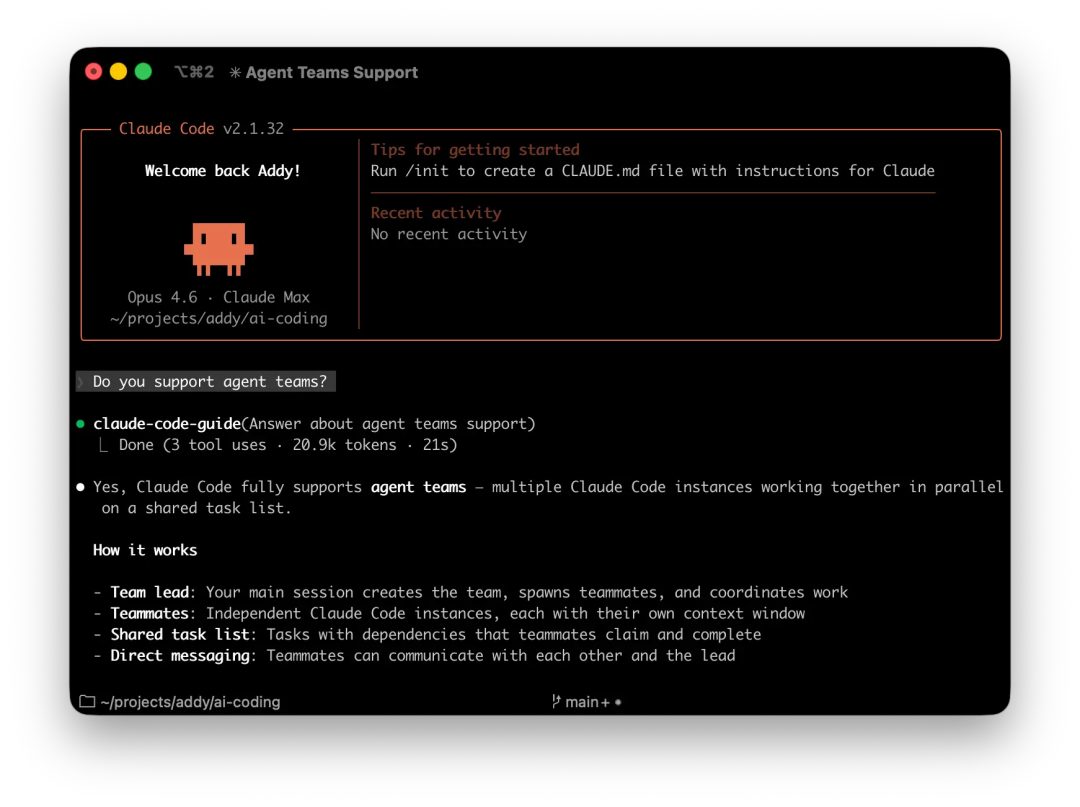
Claude Agent Teams: Why AI Coding Is About to Feel Like Managing a Real Engineering Squad
Claude Code Agent Teams:AI 编程正在从「个人助手」进化为「团队协作」
今日一言
架构评审的目标不是批准或否决,而是把各种取舍暴露出来,让团队能够做出知情的决策。
这句话的锋利之处在于,它戳破了技术评审中最常见的幻觉——以为评审是在「判断对错」。
实际上,绝大多数技术决策没有绝对的对错,只有取舍。性能 vs 可维护性,交付速度 vs 技术债务,一致性 vs 灵活性。评审的价值,不是给出一个 yes/no 的裁决,而是把每个选择背后的代价摊在桌面上,让团队在信息充分的前提下做判断。
这和模数共振报告的精神内核是一致的:不是单向的「数据决定模型」或「模型决定数据」,而是双向的「暴露取舍、知情决策」。
写在最后
模数共振不是一个新概念。物理学里,共振是指两个振动频率相同的物体,一个振动会引起另一个振动,能量在两者之间高效传递。
把它搬到 AI 产业里,含义很直白:当数据的质量频率和模型的需求频率对齐时,整个系统的能量会被放大。
中国信通院和中车工业研究院的这份报告,本质上是在给产业界提供一个「调频指南」——怎么让数据和模型共振起来,怎么让共振的能量转化为产业价值。
对于做 AI 的企业来说,这不是一个「要不要参与」的选择题,而是一个「怎么参与才能不被甩下车」的生存题。
数据飞轮一旦转起来,落后者连追赶的机会都没有。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号