企业想自建 Agent 系统,但不知道从何入手?OpenClaw 架构全拆解

企业想自建 Agent 系统,但不知道从何入手?OpenClaw 架构全拆解

烟雨平生
发布于 2026-04-21 14:28:31
发布于 2026-04-21 14:28:31
企业想自建 Agent 系统,但不知道从何入手?OpenClaw 作为当前主流的企业级 Agent 框架,它的架构到底是怎么设计的?能为企业提供什么借鉴?
今天这篇文章,手把手和你一起拆解 OpenClaw 的核心架构,从 Gateway 到 Session、Agent、Planner、Memory、Skill、Tools,完整讲清组件关系与设计思想。 阅读本文后,你将带走:
🧠 核心认知 OpenClaw 的架构设计思想:解耦、可扩展、可维护、可防 LLM 幻觉、可保障业务数据确定性
📋 架构解析 Gateway、Session、Agent、Planner、Memory、Skill、Tools 七大核心组件工作原理
🎯 企业选型 自建 Agent vs 基于 OpenClaw 构建的对比与决策建议
💡 实战案例 电商库存同步、订单处理场景的 OpenClaw 实现(含一致性保障)
🔥 架构价值 为什么传统确定性流程依然可靠,而 OpenClaw 不会因 LLM 幻觉破坏生产数据
一、为什么企业都在搭建Agent 系统?
2023 年以来,LLM 能力快速成熟,AI Agent 从实验室走向企业生产环境。 LangChain、CrewAI、OpenClaw 等框架相继出现,企业开始真正思考:如何搭建稳定、可控、可落地的企业级 Agent 系统。
企业建设 Agent 的核心痛点:
- 框架众多,不知道如何选型
- 架构复杂,不清楚 Gateway、Session、Agent、Memory 如何协同
- 落地困难,不知道如何接入现有业务系统
- 风险未知,担心 LLM 幻觉、数据不准、不可控,不敢上生产
本文围绕 OpenClaw 架构,从设计原理到实战逻辑,一次性讲清楚。
二、OpenClaw 架构解析
2.1 OpenClaw 架构全景图
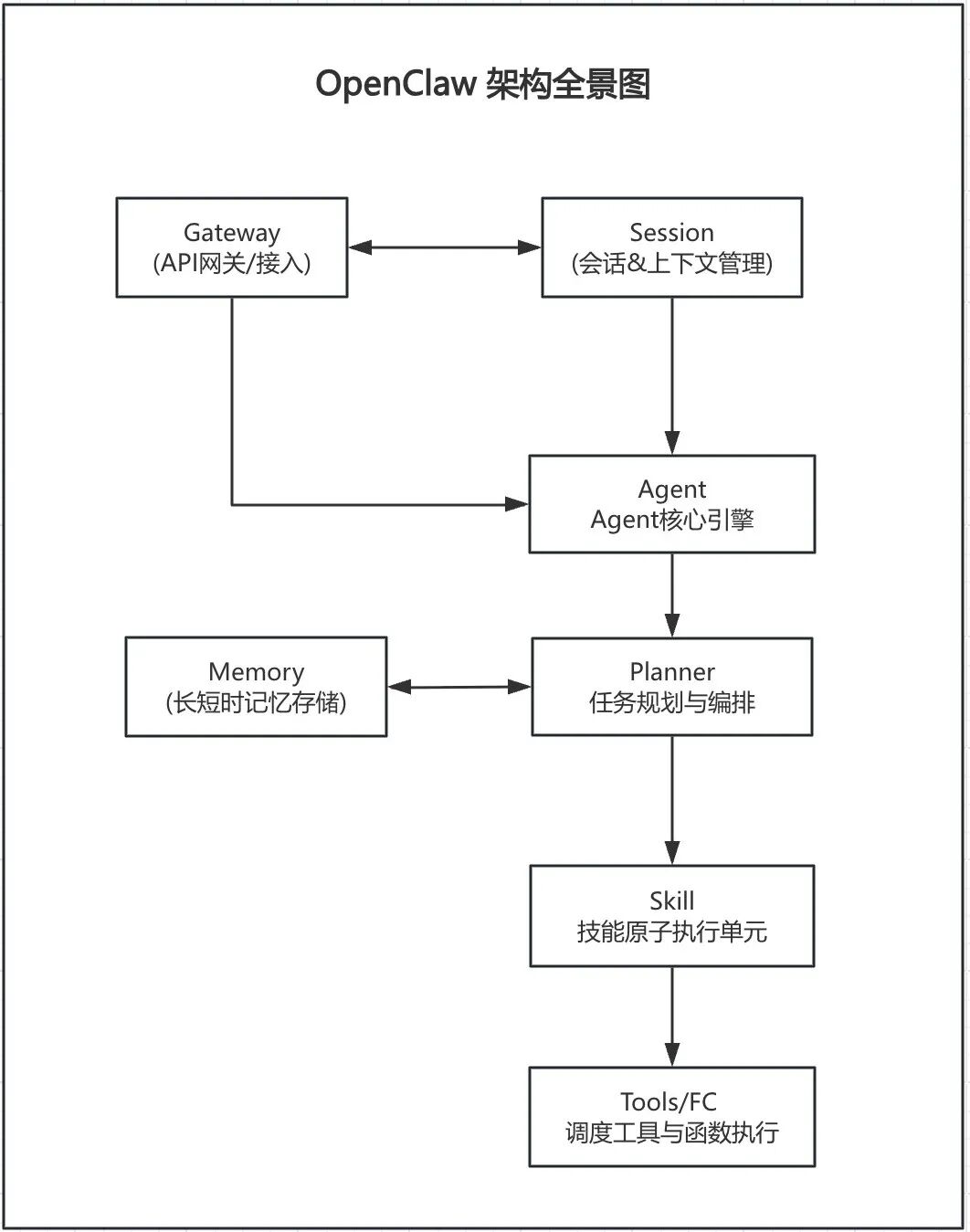
2.2 核心设计思想
OpenClaw 的核心价值一句话总结:
在完全保留原有业务系统确定性、强一致性、高可靠性的前提下,增加一层 LLM 智能调度层,实现复杂任务的自动编排。
它不是替换现有系统,而是在现有系统之上做 “大脑”。
2.3 七大核心组件说明
Gateway(API 网关)
- 统一接入 HTTP / WebSocket 请求
- 负责鉴权、路由、限流、日志
- 不参与业务逻辑,只做流量入口
Session(会话管理)
- 维护用户上下文与任务生命周期
- 存储短期对话历史
- 与 Gateway 双向交互,提供会话隔离
Agent(中枢引擎)
- 接收用户意图,调用 LLM 做理解与推理
- 调度 Planner 进行任务拆解
- 统一管理状态、异常、重试
- 不直接读写业务数据
Planner(任务规划器,OpenClaw 灵魂)
- 接收 LLM 生成的步骤,做强规则校验
- 负责任务排序、依赖检查、边界约束
- 拦截非法、矛盾、危险操作
- 是防止幻觉进入生产系统的第一道防线
Memory(记忆存储)
- 只存储真实执行结果,不存储 LLM 推理内容
- 记录:工具返回原始数据、执行状态、时间戳、版本号
- 后续规划基于真实历史,不基于 LLM 复述
Skill(业务技能单元)
- 封装一段完整业务逻辑(如:库存同步、订单审核)
- 是可复用、可测试、可监控的原子能力
- 内部做幂等、重试、回滚
Tools(工具执行层)
- 真正与数据库、API、第三方平台交互的入口
- 对应原有系统的标准接口
- 所有生产数据读写都在这里发生,完全确定性
三、OpenClaw 架构最关键价值
LLM 幻觉不会影响生产系统数据准确性。
OpenClaw 从架构层面彻底隔离 LLM 与真实业务数据,保证幻觉无法污染生产库、无法造成脏数据、无法破坏一致性。
具体保障机制:
3.1. LLM 只做 “规划”,不碰 “数据”
- LLM 只负责:意图理解、步骤建议、自然语言生成
- LLM 不负责:查询库存、计算数值、修改订单、写入数据库
- 任何真实读写必须通过 Tools 调用原有确定性系统
LLM 再怎么胡说,都只能 “建议怎么做”,不能 “真的改数据”。
3.2. Planner 做硬规则校验,拦截幻觉
Planner 内置业务约束(代码写死,无 AI):
- 库存不能为负
- 调拨数量不能超过可用量
- 禁止越权操作
- 步骤必须符合业务流程
LLM 生成幻觉步骤 → 被 Planner 直接拒绝 → 不会执行。
3.3. Skill 原子化 + 幂等 + 事务回滚
- 每个 Skill 具备独立异常捕获
- 多平台操作失败自动回滚
- 支持幂等,重复调用不重复扣减
- 即使 LLM 重复调用,业务依然安全
3.4. Memory 只存真实结果,不相信 LLM 复述
Memory 中存储的是:
- Tools 返回的原始结构体
- 执行成功 / 失败状态
- 时间、操作人、任务快照
不存储 LLM 生成的总结、推断、猜测。 后续任务永远基于真实历史,不会 “用幻觉继续推理”。
3.5. Tools 是唯一真实入口,完全继承原有可靠性
Tools 本质就是:
- 现有微服务 API
- 库存系统接口
- 订单服务
- 数据库 DAO
它们本身就是经过线上验证、带事务、可监控、可降级的确定性逻辑。 OpenClaw 没有创造新的执行层,只是调度已有的可靠执行层。
四、组件职责与技术栈一览
组件 | 核心职责 | 技术方向 |
|---|---|---|
Gateway | 接入、路由、鉴权、限流 | HTTP/WebSocket、JWT、Redis 限流 |
Session | 会话隔离、上下文管理 | Redis 存储、Pub/Sub 同步 |
Agent | 意图理解、状态调度 | TypeScript、LLM API、ReAct |
Planner | 任务规划、规则校验、步骤编排 | 规则引擎、状态机 |
Memory | 长短时记忆、执行历史 | Redis、MySQL、向量库 |
Skill | 业务逻辑封装、异常处理 | 多语言、事务、幂等、回滚 |
Tools | 真实业务执行、数据读写 | 内部 API、DB、第三方接口 |
五、自建 Agent vs 基于 OpenClaw
维度 | 完全自建 | 基于 OpenClaw 构建 |
|---|---|---|
开发成本 | 高 | 低 |
架构可控性 | 最高 | 高(可扩展 Skill/Tools) |
上线速度 | 慢 | 快 |
维护成本 | 高 | 低 |
hallucination 治理 | 需从零设计 | 框架内置 |
适合场景 | 超大型、高合规、高度定制 | 绝大多数企业场景 |
建议:
- 中小企业、互联网业务:直接用 OpenClaw 快速落地
- 中大型企业:OpenClaw + 自定义 Skill / Tools
- 金融、政务等高合规场景:可借鉴 OpenClaw 架构思想自建
六、实战:电商库存同步与订单处理
场景 1:多平台库存同步
传统方式:硬编码、胶水代码、难以扩展、异常处理复杂。
OpenClaw 方式:
- Agent 理解 “同步库存” 意图
- Planner 生成执行步骤并校验合法性
- Skill 负责编排:查订单 → 扣减各平台库存
- Tools 真正调用淘宝 / 京东 / 拼多多接口
- 任意一步失败,Skill 自动回滚
- Memory 记录真实执行结果,不依赖 LLM 总结
场景 2:自动化订单审核
- 用户下单
- Agent 接收任务
- Planner 规划:查库存 → 验价格 → 查用户信用
- Skill 按序执行
- Tools 调用订单 / 库存 / 用户系统
- 全部通过则自动审核通过,否则拒绝并给出原因
整个流程中:
- LLM 只做理解和步骤建议
- 真实判断与数据操作全由原有系统保证
- 幻觉无法影响最终结果
七、总结
- OpenClaw 不是替换原有系统,而是增强 原有确定性库存 / 订单 / 交易系统完全保留,OpenClaw 只做智能调度层。
- 架构分层清晰,安全边界极强 Gateway → Session → Agent → Planner → Memory → Skill → Tools 每一层职责单一,幻觉被层层拦截。
- LLM 只负责 “思考怎么干”,不负责 “真的去干” 所有生产数据读写都走传统可靠接口,从根源杜绝数据错乱。
- 企业落地 Agent 真正安全可行 OpenClaw 通过规划器校验、技能原子化、事务回滚、记忆真实化, 让 LLM 智能与业务确定性可以共存。
如果你正在设计企业级 Agent 架构,OpenClaw 的分层思想、执行边界设计、幻觉治理思路,都具备很强的直接借鉴价值。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号