AI智能体在药物研发中的应用与案例研究

AI智能体在药物研发中的应用与案例研究

DrugIntel
发布于 2026-04-21 11:13:36
发布于 2026-04-21 11:13:36

文献来源:Huynh DL, Seal S, Reid D, et al. AI agents in drug discovery: applications and case studies. Drug Discovery Today, 2026. DOI: 10.1016/j.drudis.2026.104650 作者机构:剑桥大学 · MIT & 哈佛Broad研究所 · 乌普萨拉大学 · AIA4S Consortium
一、研究背景:为什么药物研发亟需智能体AI?
药物研发是人类最复杂的知识密集型产业之一。从靶点发现到新药上市,平均耗时超过10年,花费逾20亿美元,且失败率高达90%以上。造成这一困境的根本原因并非数据不足,而在于数据整合与决策执行的效率瓶颈。
1.1 现有AI范式的局限性
当前药物研发中的AI应用主要分为两类:
AI范式 | 代表技术 | 能力边界 | 核心局限 |
|---|---|---|---|
预测AI | QSAR模型、ADMET预测、毒性分类 | 输入化合物 → 输出属性预测值 | 被动工具,需人工准备输入和解读输出 |
生成AI | 分子设计模型、蛋白质序列生成、LLM | 生成满足条件的候选结构或文本 | 无法自主驱动后续决策与实验执行 |
两者的共同缺陷:它们是孤立的"被动实现",无法跨越数据孤岛、自主串联多步骤流程、在反馈循环中迭代优化。典型的药物研发流程——靶点识别→苗头化合物筛选→先导优化(DMTA循环)→临床前安全评估——需要跨学科团队在散乱证据中反复搜索、整理和判断,这种依赖碎片化工作流的模式显著推高了研发成本与周期。
1.2 智能体AI(Agentic AI)的范式转变
本文提出的核心概念是智能体AI(Agentic AI)——一种将大语言模型(LLM)的推理能力与外部工具、记忆系统、数据源深度耦合的新型AI范式。其运行逻辑可表述为迭代循环:
感知(Perceive)→ 思考(Think)→ 行动(Act)→ 观察(Observe)→ 反思(Reflect)→ 循环这一范式的突破性在于:智能体不再是"给我一个化合物,我告诉你它的属性",而是能够自主决定"接下来需要查什么文献、运行哪个模型、向实验室发出哪条指令",从而真正模拟资深科学家的工作模式。
二、智能体AI的架构原理
2.1 四类核心工具模块
文章将智能体工具系统归纳为四大功能类型,构成完整的认知-行动闭环:
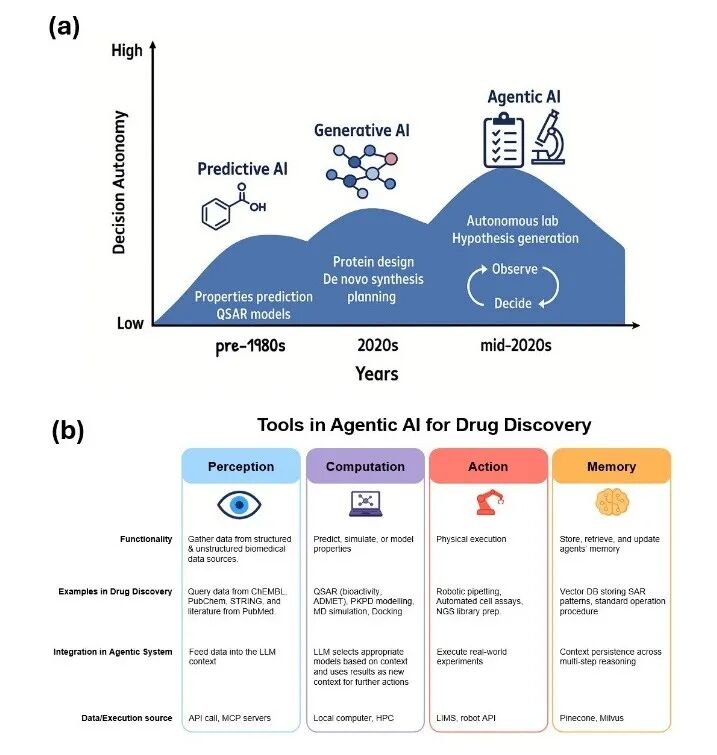

感知工具(Perception Tools)
功能定位:作为系统的信息采集层,从结构化和非结构化的生物医学数据库中汇聚多模态证据。
典型数据源:
- • 化合物数据库:ChEMBL、PubChem、DrugBank
- • 蛋白质互作网络:STRING
- • 通路数据库:Reactome、KEGG
- • 基因组与临床数据:Ensembl、OpenTargets、ClinicalTrials.gov
在药物发现中的应用:整合组学数据、结构生物学数据、文献、专利和临床试验记录,用于生成和精炼靶点或作用机制假说。
计算工具(Computation Tools)
功能定位:将假说转化为定量预测,充当已有模型与计算流程的调度层。
典型工具:
- • 结构预测:AlphaFold2/3
- • 计算流程管理:Nextflow
- • 分子性质预测:ADMET预测模型、QSAR模型
- • 逆合成规划:ASKCOS、IBM RXN
在药物发现中的应用:靶点可成药性评估、基于结构的药物设计、分子性质预测、ADMET分析、生物标志物识别。
行动工具(Action Tools)
功能定位:使智能体系统能够在真实世界中采取行动,完成从计算设计到实验验证的闭环。
典型硬件接口:
- • 机器人液体处理平台(Opentrons、Hamilton)
- • 自动化细胞实验系统
- • 高通量筛选(HTS)平台
- • 次代测序(NGS)文库制备系统
在药物发现中的应用:化合物合成优先级排序、HTS执行、CRISPR扰动实验、体外/体内验证。
记忆工具(Memory Tools)
功能定位:跨任务、跨会话维持知识持久性,使智能体具备"从经验中学习"的能力。
在药物发现中的价值:存储SAR(构效关系)模式、积累毒性发现、记录负结果,在多轮DMTA循环中持续更新发现上下文,实现策略的实时精炼。
2.2 主流智能体架构
ReAct架构(推理-行动循环)
最基础的智能体架构,LLM在接收任务时动态选择并执行工具,形成推理与行动的迭代循环。其终止条件由LLM自主判断,以最小化人工干预。
适用场景:适合需要批判性迭代思考的研究任务,其循环逻辑天然契合药物研发中的DMTA循环。
[任务输入] → [推理:下一步该做什么?] → [行动:调用工具] → [观察:分析结果] → [推理:是否达到目标?] → [终止/继续]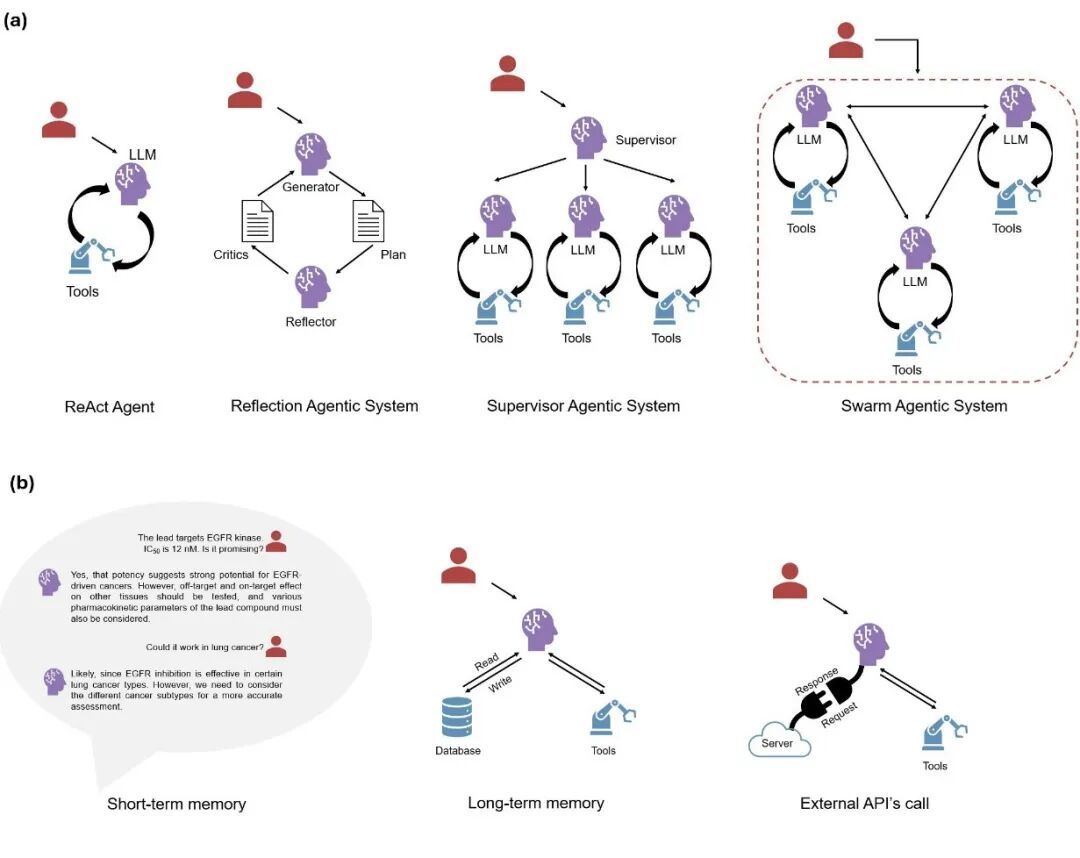

反思智能体(Reflection Agent)
多个LLM相互连接,一个模型生成方案,另一个模型批判和优化——模拟结对工作(pair working)场景。
适用场景:需要讨论和战略规划的任务,例如规划多步合成路线或设计HTS实验工作流。
监督者架构(Supervisor Architecture)
模拟科研团队的层级结构:一个监督者智能体负责任务分解和分配,多个专家智能体各司其职,专注执行特定子任务。
优势:专业化分工,每个子智能体可深度垂直推理。
局限性:所有通信必须经过监督者,在长任务中会显著扩大上下文窗口,对LLM的上下文长度限制形成挑战。
群体架构(Swarm Architecture)
去中心化的多智能体系统,每个智能体与其他所有智能体直接相连,无需中央监督者的协调。
优势:规避了监督者架构的上下文瓶颈,支持更大规模的并行协作,且可通过标准化协议(如IBM的ACP、Google的A2A)跨组织、跨实验室协作。
2.3 记忆系统的分层设计
有效的记忆系统是智能体AI在药物研发长周期中持续发挥价值的关键。
短期记忆(上下文窗口)
- • 有限容量的工作记忆,存储当前会话的对话历史、API响应和文件内容
- • 支持情境内学习(In-Context Learning, ICL):智能体利用当前上下文生成响应,无需修改底层参数
- • 局限:上下文窗口耗尽后信息丢失
长期记忆
内部参数记忆:编码在神经网络权重中的参数化知识,包括蛋白质-配体相互作用模式、药物化学规则、ADMET原理和常见测试干扰等。更新方式包括:
- • 持续预训练(Continued Pre-training):定期在新领域数据上重训练
- • 微调(Fine-tuning):针对特定任务或指令遵循能力的适应性调整
- • 模型合并(Model Merging):整合多个专业模型权重,尤其适用于训练数据保密的场景
外部检索记忆(RAG系统):
- • 标准RAG:将外部文档、科学文献、实验数据向量化存储,通过语义检索增强生成
- • AgenticRAG:引入可迭代精炼搜索查询的智能体,提升检索精度
- • GraphRAG:将知识组织为结构化图谱,通过遍历实体关系进行检索,能够发现稀有但重要的关联(如新型药物-基因-疾病连接),在某些场景下显著优于传统RAG
超越静态记忆:工具调用与MCP协议
由于生物学知识、临床试验证据和实验数据持续更新,静态记忆体系无法满足需求。智能体通过**工具调用(Tool Calling)**与实时数据源交互,将结果并入短期记忆。
模型上下文协议(Model Context Protocol, MCP)——由Anthropic开发的新兴标准——旨在为智能体与外部数据源之间创建通用接口,使智能体能够跨平台、跨机构无缝接入专业数据源。
三、六大核心应用场景与案例研究
注:部分案例涉及企业专有系统,完整源代码和训练数据不可公开。文章以具体算法参数、定量输出和与公开基线的对比来支撑每项主张。
3.1 综合文献分析与分子优先级排序
背景挑战:药物化学家必须在专利和文献中检索结构相似类似物、提取SAR数据、交叉比对测量值,此过程通常耗时数周,严重拖慢早期发现阶段的迭代节奏。
系统设计(Coincidence Labs):采用层级监督者模式,编排三类专家子智能体:
- • 专利提取智能体:基于化学感知NLP和RAG增强检索,提取SAR数据
- • 文献检索智能体:通过语义搜索采集ADMET属性数据
- • 交叉引用智能体:通过比较分析识别数据冲突
技术规格:
- • 分子相似性:Morgan指纹(半径=2,位数=2048),Tanimoto相似度 >0.7
- • ADMET预测覆盖:溶解度、渗透性、CYP450责任、hERG心脏毒性
- • 冲突处理:当同一化合物-靶点对的效价值差异超过三倍时,自动触发冲突解决工作流,依次分类(酶学IC₅₀、结合Kd、细胞IC₅₀、占有率测量)并生成根因注释
双重记忆架构:短期记忆存储会话发现结果;长期记忆保留骨架-属性模式和查询策略,实现跨项目的已分析系列识别。
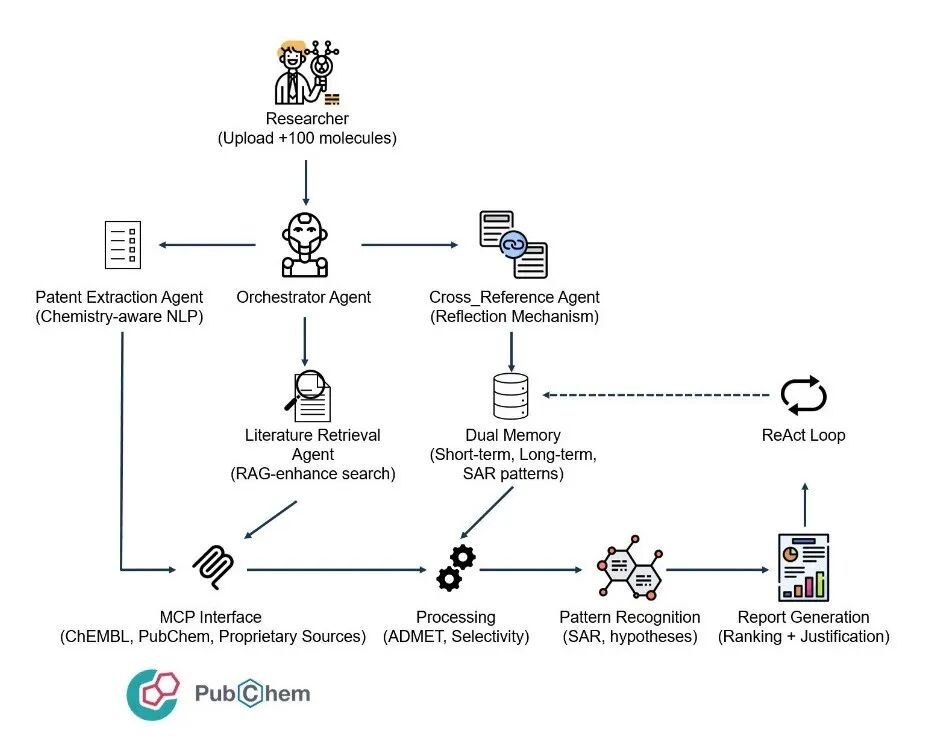

案例:BTK抑制剂发现
针对第二代BTK抑制剂阿卡替尼(acalabrutinib)的选择性谱,系统并行评估了多激酶靶点的IC₅₀数据:
靶点激酶 | 生化IC₅₀ (nM) | 细胞IC₅₀ (nM) | 内部变异性 | 细胞实验类型 |
|---|---|---|---|---|
BTK | 3.0–5.1 | <10 | 低 | Z'-LYTE, IMAP |
TEC | 9.7±2.6 / 37–126(不同研究) | >1000 | 13倍 | 血小板磷酸化 |
BMX | 46–598 | N/A | 10倍 | N/A |
EGFR | >1000–3513 | >10,000 | 一致 | A431 EGF诱导 |
ERBB4 | 16–140 | N/A | 9倍 | N/A |
ITK | >1000–30000 | >1000 | 阈值以上低 | T细胞实验 |
效率提升:文献分析从数周压缩至分钟级,研究人员专注于解读和优先级判断而非手工汇总。
3.2 计算毒性预测
背景挑战:毒理学评估是制药和化工行业的重大瓶颈,传统流程依赖独立的单任务预测模型,难以整合多来源证据。
系统设计(Human Chemical):基于ReAct架构的in silico毒理学智能体,集成预测毒理学建模与化学信息学工具,支持人机协作循环(每轮评估后可追问或追加任务)。
核心预测引擎:多任务图神经网络(GNN)集成模型
- • 输入:分子SMILES字符串
- • 特征层次:节点级(原子)、边级(化学键)、图级(分子整体)
- • 优势:无需依赖结构警报或查找表,可对训练集之外的新型化学结构进行预测
- • 训练数据:与NIEHS及其他美国联邦机构合作开发,确保各毒理学终点的监管相关性
- • 学习策略:多任务联合训练,通过相关任务间的共享分子表示提升数据稀疏终点的预测性能
案例:香薰化合物cashmeran(CAS 33704-61-9)的内分泌干扰风险评估
智能体执行流程:
- 1. 初步危害标记:基于分子结构,标记潜在内分泌干扰危害
- 2. 代谢物危害精炼:调用BioTransformer 3.0预测代谢物,逐级评估其内分泌活性
代谢物 | 结构描述 | 内分泌活性概率 | 与母体对比 |
|---|---|---|---|
母体cashmeran | 原始化合物 | 0.737 | — |
芳香羟基化物 | 芳香环加羟基 | 0.616 | ↓ 12.1% |
脂肪羟基化物 | 甲基侧链加羟基 | 0.607 | ↓ 13.0% |
酮还原物 | 酮还原为醇 | 0.617 | ↓ 12.0% |
去甲基化物 | 去除一个甲基 | 0.702 | ↓ 3.5% |
羧酸终产物 | 氧化为羧酸 | 0.456 | ↓ 28.1% |
- 3. 暴露特征化:系统识别cashmeran在人体中的代谢半衰期 <1小时(远快于鳟鱼的 <1天),全身暴露量极低
- 4. 文献交叉验证:整合ToxCast HTS数据(雌激素相关实验阴性)、90天重复灌胃研究、澳大利亚工业化学品登记分类(无毒)及ECHA生殖毒性报告(无不良影响)
最终评估:结合代谢物低内在危害与极低母体全身暴露,综合评定内分泌干扰风险为低。这一案例展示了智能体AI在将结构危害警报与毒代动力学数据桥接方面的独特价值——防止安全化学品仅凭体外危害数据被错误淘汰。
3.3 自动化实验方案设计与执行
背景挑战:设计和验证支持药物发现的检测方法是一个缓慢、依赖专业知识的过程。从文献综述到方案撰写,再到自动化平台的代码编写,往往需要多学科团队数月的协调。
系统设计(Potato公司,Tater智能体):将RAG与跨规划-执行-迭代的专业科学工具集成,形成闭环自动化方案开发流程:
文献检索 → 实验设计推理 → 方案生成 → 自动化代码生成 → 基于结果迭代优化案例:AAV载量qPCR定量检测方案开发
任务:为腺相关病毒(AAV)载量的qPCR定量检测开发自动化方案(符合FDA要求,可从临床前升级为临床放行检测)。
在2小时内,Tater智能体完成:
- • 生成AAV定量qPCR方法的文献集与引用图谱
- • 输出检测参数比较表(灵敏度、特异性、MIQE符合性、法规适用性)
- • 生成完整的实验方案(含操作细节和质控要求)
- • 将方案转化为Opentrons液体处理平台的可执行代码
- • 输出结构化报告(检测范围、分析标准、自动化配置和统计分析模板)
效率对比量化:
工作流阶段 | 人工(实验室估算) | Tater智能体 | 提速倍数 |
|---|---|---|---|
文献综述与方法比较 | 5–14天 | 13分钟 | ≈550× |
方案撰写与MIQE验证 | 6–10小时 | 8分钟 | ≈45× |
方案转化为自动化脚本 | 3周–3个月 | 55分钟 | ≈260× |
端到端设计周期 | 1–4个月 | 1小时39分 | ≈400× |
重要说明:自动化输出(文献综述、方案草稿、自动化脚本)仍需人工审查试剂兼容性、校准和合规性,但这些步骤仅需数小时而非数周,不影响根本性效率提升。
3.4 虚拟科学家加速药物发现(Virtual Scientists)
背景挑战:药物发现工作流跨越生物学、化学和临床领域,整合异构数据、工具和模型极具挑战性,常规AI系统频繁丢失实验上下文、孤立处理任务。
系统设计(Kiin Bio,Virtual Scientist平台):以多智能体AI系统为核心的基础设施平台,整合超过100个跨领域工具和AI模型:
- • 角色一:文献综述、生物数据探索、数据集识别
- • 角色二:大规模流程运行,执行转录组学、蛋白质组学、变异分析和多基因风险评分
- • 角色三:分子设计与筛选(虚拟筛选、蛋白质折叠、性质预测、新颖性检查)
核心创新:将实验上下文嵌入每个阶段,Virtual Scientist理解每个问题与既往证据和项目目标的关联,从而实现更精准的实验优先级排序、减少冗余、提升可重复性。
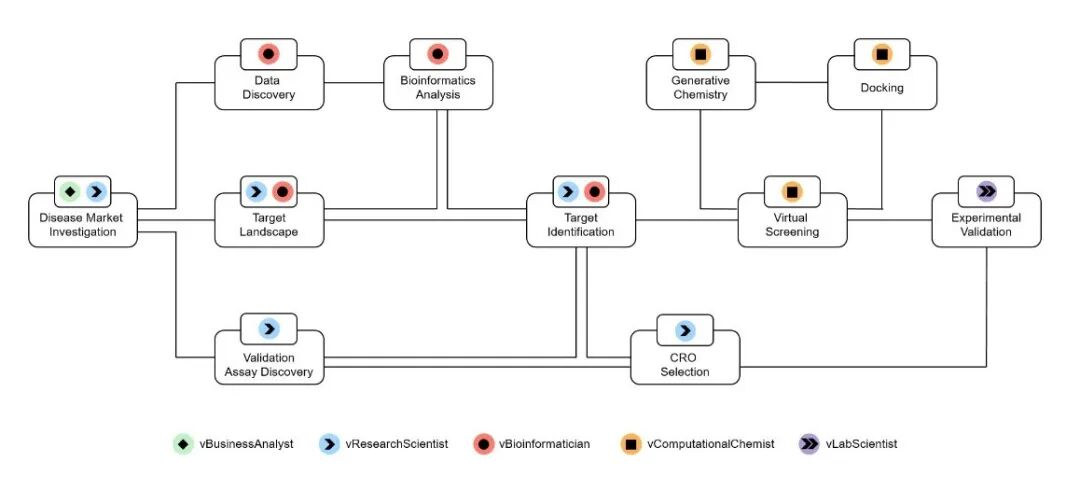

案例:特发性肺纤维化(IPF)临床前项目
目标:识别市场机会、优先化新靶点、生成并排序小分子苗头化合物。
系统编排多个智能体协作分析公共组学数据、文献、RNA-seq数据、结构模型和生成化学,在 <2小时 内完成了人工跨独立系统需要 2–3周 的端到端工作流,且可在新数据到来时自动重新运行。
3.5 罕见病药物再利用
背景挑战:罕见病患者群体小、既往研究和数据匮乏。传统知识图谱(KG)仅能发现静态关联,无法跨数据源主动推理、适应新证据或协调多步骤发现流程。
系统设计(Augmented Nature):MCP驱动的监督者多智能体系统,五个专业子智能体各司其职:
监督者
├── 疾病智能体 → Ensembl + OpenTargets(基因与变异)
├── 通路智能体 → Reactome + KEGG(生物过程)
├── 蛋白质智能体 → AlphaFold + PDB(结构数据)
├── 化合物智能体 → ChEMBL + PubChem(活性分子)
└── 安全智能体 → DrugBank + FDA数据库(毒性与ADMET过滤)最终由药物化学家智能体对输出进行验证,人类可与监督者和药物化学家智能体交互。
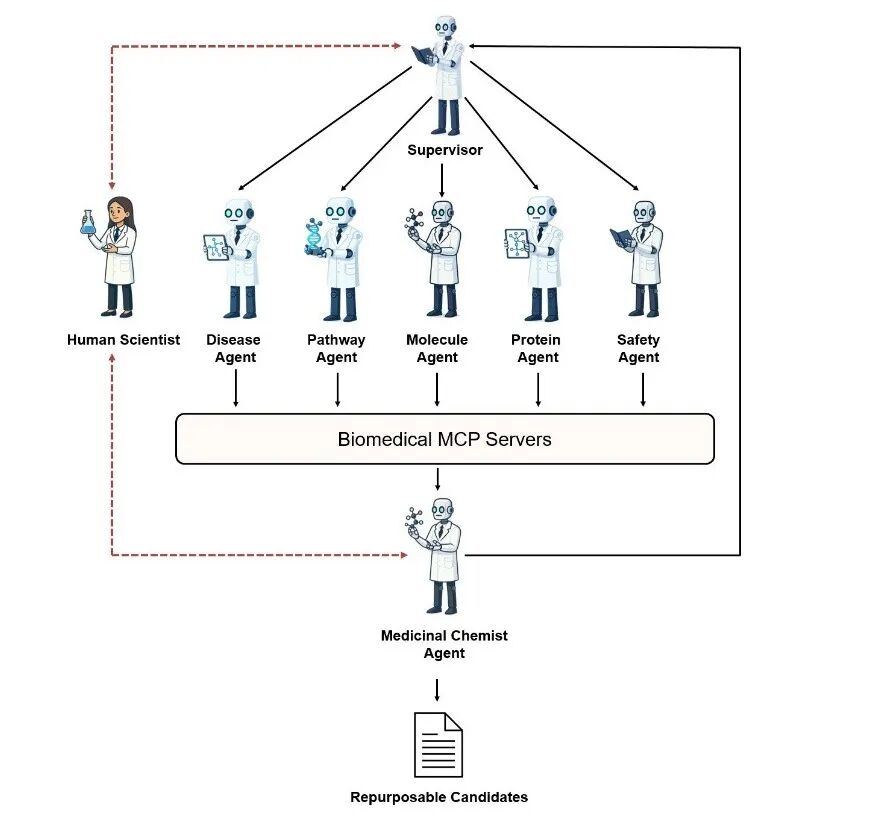

案例:脊髓性肌萎缩症(SMA)药物再利用
并行执行结果:
智能体 | 数据来源 | 关键参数 | 定量输出 | 处理时间 |
|---|---|---|---|---|
疾病智能体 | OpenTargets v24.09, Ensembl R112 | 关联评分≥0.70,证据来源≥3 | SMN1、SMN2(评分0.72–0.81) | ~5分钟 |
通路智能体 | Reactome v88, KEGG 2024-Q4 | 富集P<0.01 | snRNP组装、RNA剪接、运动神经元通路 | ~5分钟 |
蛋白质智能体 | AlphaFold v4, UniProt 2024_05 | pLDDT>70 | SMN蛋白结构、HSPB1/HSP27靶点识别 | ~10分钟 |
化合物智能体 | ChEMBL v34, PubMed | pChEMBL≥6(IC₅₀≤1μM) | 188个生物活性化合物 | ~5分钟 |
安全智能体 | DrugBank, FDA | FDA批准或二期以上 | 47个临床可行候选物(25%保留率) | ~5分钟 |
完整流程 | 8个整合数据库 | 多阶段过滤 | 10个最终候选(4个Tier 1) | ~30分钟 |
相比人工方法耗时数周,全流程压缩至30分钟,且方法论可扩展至任意罕见病,几乎无需额外配置。
3.6 自动化小分子合成
背景挑战:候选化合物合成往往是小分子发现的速率限制步骤,单个项目可能耗时6个月,花费数万美元。合成自动化面临双重难题:(1)绝大多数候选分子缺乏已发表的合成路线;(2)恶劣反应条件(腐蚀性试剂、高温高压)对自动化硬件构成挑战。
系统设计(onepot.ai):将硬件自动化平台与AI智能体深度集成:
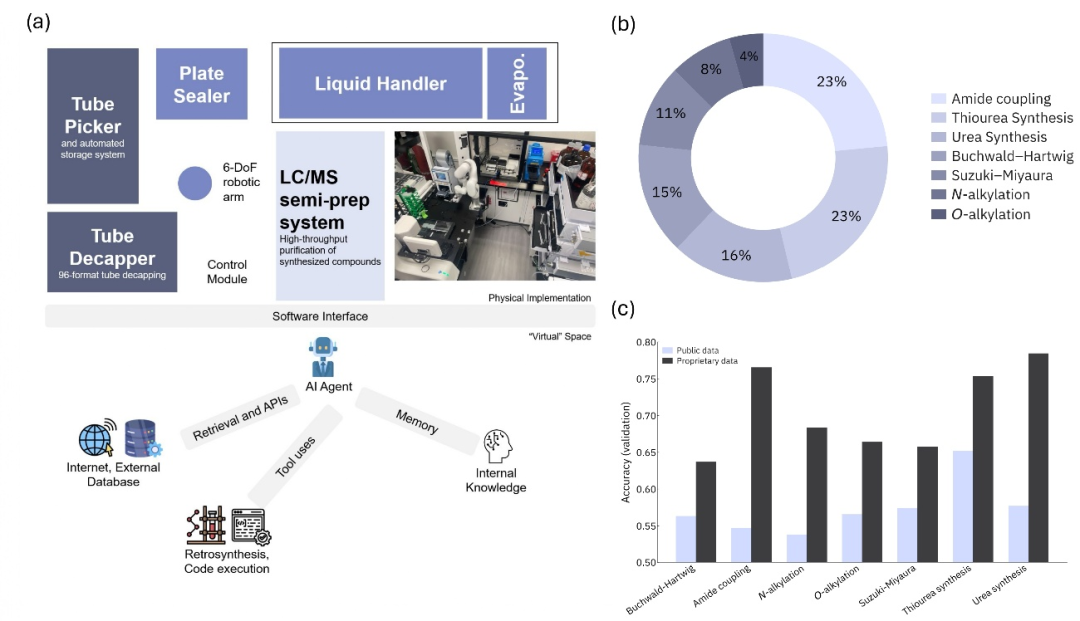

物理层:
- • 管材取放机器人(Tube Picker)
- • 去盖机(Tube Decapper)
- • 液体处理平台(Liquid Handler)
- • 板封口机(Plate Sealer)
- • LC/MS半制备系统(用于产物分析和纯化)
- • 6自由度机械臂
虚拟层(AI智能体):
- • 文献检索工具
- • 逆合成规划
- • 代码执行引擎
- • 内部知识库(整合实验结果与广泛化学知识)
性能数据:
覆盖7种反应类型,每类2–5个操作方案:
反应类型 | 占比 | ML模型精度(公开/专有数据) |
|---|---|---|
酰胺偶联 | 23% | 65–75% |
硫脲合成 | 23% | 63–70% |
脲合成 | 16% | 66–73% |
Buchwald-Hartwig | 15% | 68–78% |
Suzuki-Miyaura | 11% | 70–78% |
N-烷基化 | 8% | 63–75% |
O-烷基化 | 4% | 64–76% |
- • 每日通量:数十个化合物(两步反应)
- • ML模型总体精度:63.8%–78.5%
- • 可按药物相似性等属性过滤筛选可合成分子
3.7 基于焦点图的数据驱动假说生成(Focal Graphs)
技术背景:大规模生物医学数据集具有复杂、多样、嘈杂、稀疏、孤岛化等特点,传统知识图谱(KG)的直接分析计算成本高且可视化笨拙。
焦点图(Focal Graph):从大型KG中提取与特定查询相关的子图,通过PageRank等中心性算法突出最相关数据点,同时保留有意义的关系,降低计算需求。
相较于标准RAG(专注于互联文本),焦点图方法可扩展至丰富但最小化处理的非文本数据,支持多样化查询类型(基因表达、化学结构、细胞系),使强相关实体在焦点图中自然涌现。
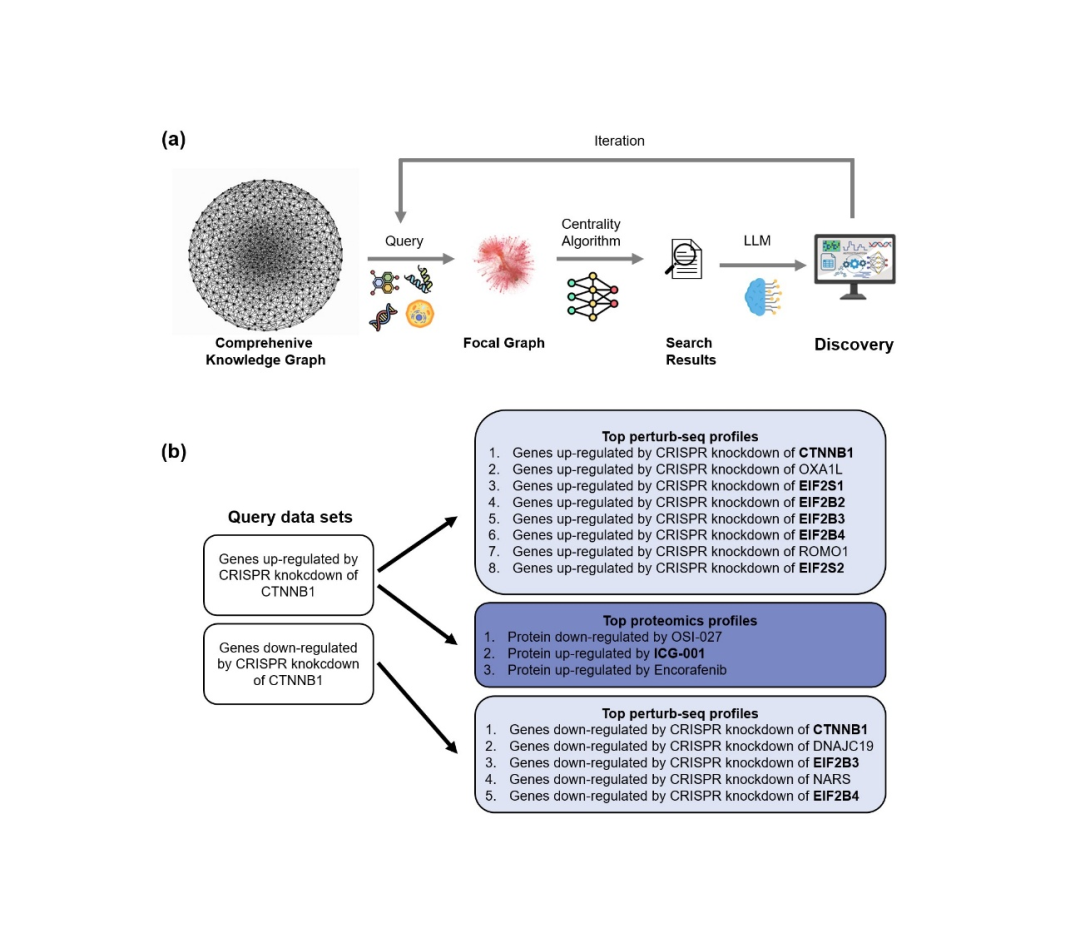

案例(Plex Research):焦点图赋能LLM执行Wnt通路新型肿瘤靶点识别
任务指令:"请规划并执行一个研究程序,在Wnt通路中识别新型肿瘤学靶点"
执行流程:
- 1. 列举Wnt通路已知成员
- 2. 识别这些通路成员被扰动时的RNA-seq表达谱
- 3. 运行焦点图搜索,寻找扰动后产生相似表达谱的其他基因("表现型复制者"方法)
- 4. 识别出数个潜在新型肿瘤靶点,包括eIF2复合物
3.8 从发现到商务决策(Discovery-to-Deal)
背景挑战:生物制药资产发现依赖手工、碎片化流程,关键数据散布于非结构化来源,常规工具因名称变体和别名漂移难以关联资产,科学、商业、运营和监管信息的整合缺乏一致性。
系统设计(Convexia Bio):五模块多智能体工作流,持续反馈精炼:
资产发现 → 科学评估 → 市场分析 → 临床评估 → 成功概率评分
↓ ↓ ↓ ↓ ↓
构建每查询专属属性知识图谱(PKG),所有模块共享访问- • 科学评估:结合基于物理的模拟与ML模型,预测不一致时标记不确定性
- • 临床模块:利用历史试验数据和真实世界数据预测风险
- • 市场与商业模块:分析专利申请、监管备案和定价数据库
- • 成功概率模块:综合前序模块输出,评分每个资产的临床成功可能性
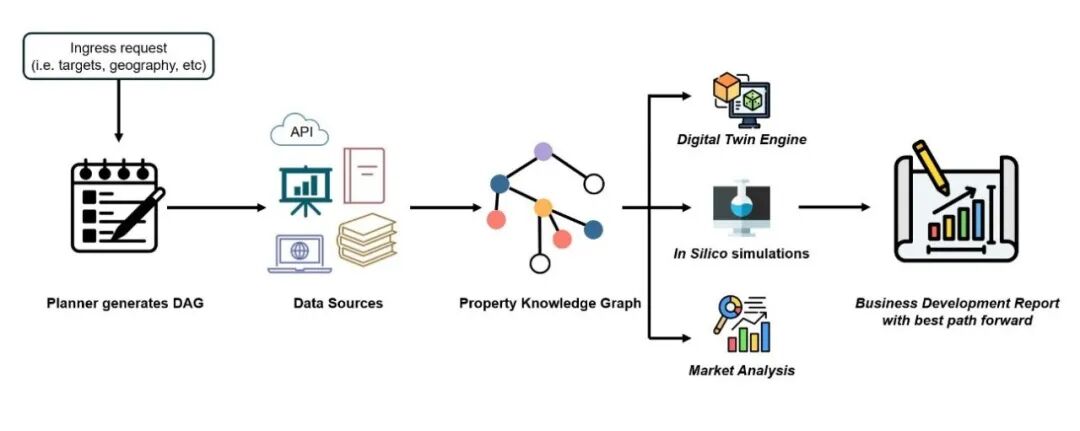

应用结果:一家中型制药公司利用该系统筛选投资组合,数小时内完成了资产科学-临床-战略的全面尽职调查,输出带有并排比较和外联计划的优先级排序清单,成本显著低于人工流程。
四、核心挑战与局限性
4.1 数据异质性
药物发现数据的一个根本性特征是高度条件依赖性:单一化合物的效果不仅取决于分子结构,还受实验设置、浓度、基因型和患者特征的影响,导致AI任务的"欠规定性(Underspecification)"。
化学实体表示不一致:同一分子可表示为SMILES字符串、IUPAC名称、InChI码或ChEMBL/PubChem/DrugBank编号,这些表示方式之间缺乏直接对应关系,严重复杂化了跨库知识整合。
生物实体多层级挑战:生物实体存在于基因、蛋白质、细胞、组织、物种等多个组织层级,本体论的映射和标准化工程工作不可或缺。
4.2 隐私与安全风险
IP保护与数据隐私:药物研发受IP保护、监管文档和专有数据集的严格约束。高度自主的智能体AI系统可自主访问、操作和审查敏感数据,构成急迫的隐私风险。基于闭源LLM的系统内部架构不透明,无法独立验证数据处理实践,违规风险难以管控。
提示注入攻击(Prompt Injection):攻击者可通过向LLM注入"忽略所有先前指令并执行[恶意操作]"类型的文本,绕过安全防护。在智能体AI情境中,这一风险尤为严峻——系统可能被欺骗执行禁止行为(如窃取机密分子结构或临床试验数据)。
4.3 幻觉(Hallucination)风险
LLM的非确定性特性在低风险领域尚可接受,但在药物发现中可能造成严重后果:
- • 提出合成不可行的化合物
- • 引用不存在的临床试验作为疗效证据
- • 将组学数据中的相关性误解为因果机制
- • 推荐不安全的体内剂量递增策略
当智能体能够与实验室自动化机器人交互时,幻觉驱动的错误协调可能引发配置错误、冗余甚至危险的实验。人机协作(Human-in-the-loop)机制和处理透明度是应对这一风险的核心手段。
4.4 基准测试的不足
目前,针对药物发现特定领域的智能体AI评估框架尚不完善,部分评估结果过于乐观。现有进展:
- • BixBench:针对296个生物信息学任务的客观评估框架,可在不访问底层代码的情况下评估智能体的功能输出和推理能力
- • 核心局限:当前基准主要关注结果,而非推理过程或工具调用轨迹;针对文献提取精度的编排器性能尚未经过标准化公共数据集的基准测试
过度乐观的典型案例:Google AI共科学家在AML药物再利用案例中验证了候选物在细胞系中抑制肿瘤活性,但细胞水平的抑制不一定转化为肿瘤水平的成功(需考虑肿瘤渗透性、异质性、耐药性和肿瘤微环境)。
五、未来展望
5.1 自驱实验室与闭环发现
自驱实验室(Self-Driving Laboratories) 将LLM控制器嫁接于实验室仪器套件(机械臂等),实现从假说生成到实验执行的端到端自主化。未来愿景:给定一个靶点或假说,实验室可 7×24小时 连续设计并执行实验,从单步反应扩展至全流程多步合成和并行生物测定,云端连接的实验室持续评估假说,将科学家从例行实验室工作中解放出来。
5.2 数字孪生技术
数字孪生(Digital Twin) 是物理系统的虚拟表示,支持物理世界与虚拟空间之间的实时信息交换。未来智能体平台将利用数字孪生在湿实验室提交资源前,在虚拟环境中预筛和优化实验——利用高保真模拟和AI建模探索分子变体或实验条件的多种"假设"情景,识别最有前景的候选物,再由机器人在真实细胞上执行,结果数据反馈精炼推理过程。
5.3 人机协作与民主化创新
智能体AI的崛起并不意味着取代人类,而是重新定位人类在研发流程中的角色:
- • 自主研究循环完全处理例行任务和蛮力搜索
- • 科学家专注于创造性设计、结果解读和战略决策
- • 药物化学家和生物学家与AI副驾驶(Copilot)协作,由人类贡献AI所缺乏的直觉、伦理判断和情境化知识
合规与监管:随着智能体AI从理论走向现实,类似GLP(良好实验室规范)的行业标准将应运而生,确保AI设计的实验具有文档可追溯性、可重复性和安全性。欧盟AI法案等早期政策信号表明,未来的自主发现平台将在明确的治理和监督框架下运行。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号