卡帕西开源 AutoResearch:630 行代码让 AI Agent 自主进化训练,72 小时揽星 12.7k

卡帕西开源 AutoResearch:630 行代码让 AI Agent 自主进化训练,72 小时揽星 12.7k

运维有术
发布于 2026-04-01 19:38:05
发布于 2026-04-01 19:38:05
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 48 篇,AI星探「2026」系列第 5 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。 我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
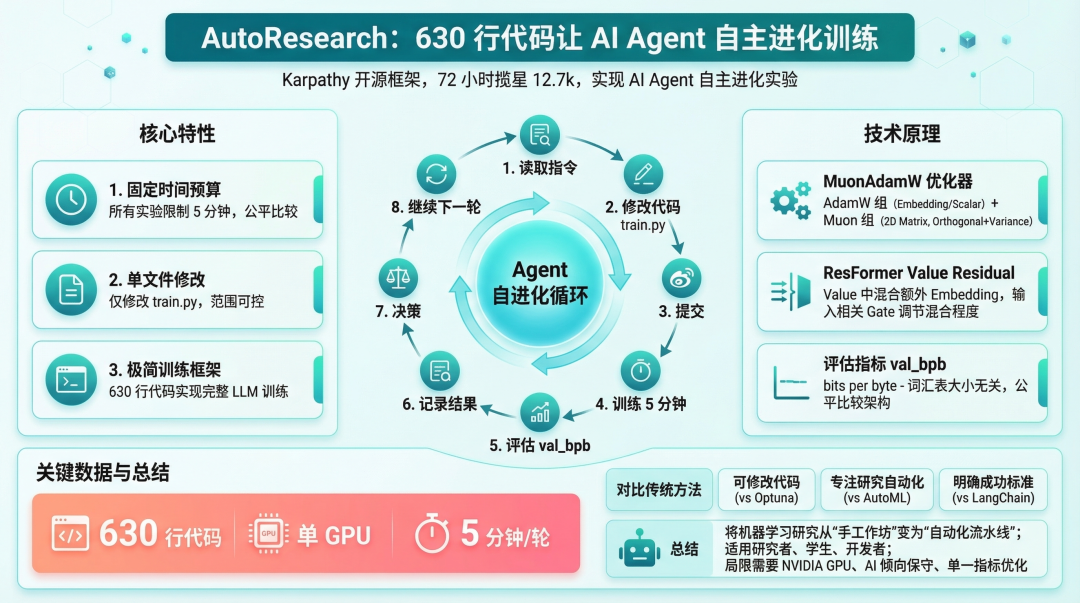
封面图:AutoResearch 工作流程示意图
Karpathy 在 Twitter 上发了这么一段话:
"从前,前沿 AI 研究是由肉身计算机在吃饭、睡觉、娱乐之间完成的,偶尔通过声波互连在'组会'仪式上同步。那个时代早已过去。现在,研究完全是运行在云端计算集群巨型结构上的自主 AI Agent 群体的领域。"
这段话的配图就是他刚开源的项目: AutoResearch。72 小时内,这个项目在 GitHub 上揽星 12.7k,Fork 数 1.7k。Shopify CEO 公开表示"膜拜"。
我翻了一圈代码和文档,发现这事的本质是:一个 630 行的 Python 项目,能让 AI Agent 在单个 GPU 上自主进行机器学习研究,每 5 分钟完成一轮实验,自动修改代码、训练模型、评估结果,然后决定是保留还是回退。
说白了,就是雇了一个 24 小时不休息的虚拟研究员。
一、这是什么?
AutoResearch 的核心是一个自进化的实验循环。
传统的研究流程是这样的:你有个想法 → 改代码 → 训练模型 → 看结果 → 再改代码。每一步都需要人工干预,而且不同实验的训练时长可能不一样,导致结果不可比。
AutoResearch 的做法是:固定时间预算 + 单一评估指标 + 自动决策。
具体来说:
- 固定 5 分钟训练时间:不管你改了什么,训练时间都是 5 分钟。这让所有实验结果可以直接比较。
- 单一评估指标 val_bpb:验证集的 bits per byte。这个指标和词汇表大小无关,不同架构的模型也能公平比较。数值越低越好。
- 自动决策:AI 修改代码后,训练完自动评估。如果 val_bpb 降低了 → 保留修改;如果没改进 → git reset 回退。
整个项目就三个核心文件:
- prepare.py:固定不变,定义数据加载和评估函数
- train.py:AI 唯一可以修改的文件,包含模型、优化器、训练循环
- program.md:人类编写的研究指令
人类只需要在 program.md 里写清楚研究方向和规则,剩下的全都交给 AI。
二、核心特性
特性一:固定时间预算的公平比较
这是 AutoResearch 设计思路的精髓。
传统超参数调优有个问题:不同配置的训练时长可能差很多。有的跑 10 分钟,有的跑 1 小时,结果怎么比?没法比。
AutoResearch 的解决方案很简单:把训练时间固定为 5 分钟。
# prepare.py
TIME_BUDGET = 300 # 5分钟(秒)
这样做的好处:
- 可比性:所有实验都在相同的计算预算下进行
- 可预测性:每小时约 12 轮实验,8 小时约 100 轮
- 公平性:避免"跑得久就效果好"的假象
代价是:不同计算平台(H100 vs RTX 3090)的结果不可直接比较。但 Karpathy 的观点是,这反而是优势 - 找到特定平台在时间预算内的最优模型。
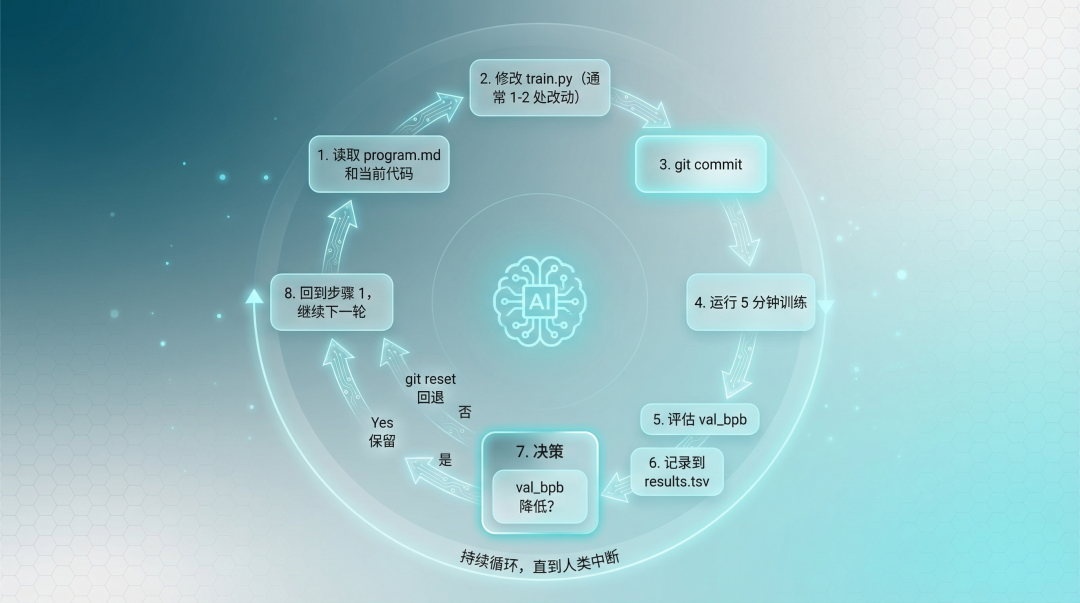
配图2:AutoResearch 自进化循环流程图 - 展示 8 步循环:读取指令、修改代码、提交、训练、评估、记录、决策、循环
配图2:AutoResearch 自进化循环流程图
特性二:单文件修改的范围控制
AI 只被允许修改一个文件:train.py。
这个约束看起来限制性很强,但实际上很聪明:
- diff 易审查:每次实验的改动都在一个文件里,git diff 清晰可见
- 范围可控:防止 AI 乱改评估工具或数据加载器
- 职责分离:prepare.py 是"规则",train.py 是"策略"
AI 可以在 train.py 里改的东西:
- 模型架构(层数、注意力机制、激活函数...)
- 优化器设置(学习率、权重衰减...)
- 训练超参数(批量大小、梯度累积...)
- 训练循环逻辑
但不能碰的东西:
- prepare.py(只读)
- 评估函数 evaluate_bpb(基准指标不能改)
- 安装新依赖(保持环境稳定)
特性三:极简但完整的训练框架
虽然只有 630 行代码,但包含了一个完整的 LLM 训练框架:
模型架构:
- 标准 Transformer decoder-only
- RMSNorm 标准化
- RoPE 旋转位置编码
- GQA(Grouped Query Attention)
创新特性:
- ResFormer Value Residual(混合 value embedding)
- Sliding Window Attention(滑动窗口注意力)
- ReLU² 激活函数
- Softcap Logits(限制 logits 范围)
优化器:
- MuonAdamW(组合优化器,对不同参数使用不同策略)
- 学习率调度(支持 warmup 和 warmdown)
- 梯度累积(模拟大批量训练)
性能优化:
- torch.compile 编译优化
- bfloat16 混合精度训练
- GC 管理(禁用自动 GC,避免停顿)
完整的训练流程,一个 GPU 就能跑起来。
三、技术原理
Agent 自进化机制
整个循环是这样的:
1. AI 读取 program.md 和当前代码
2. 修改 train.py(通常 1-2 处改动)
3. git commit
4. 运行 5 分钟训练
5. 评估 val_bpb
6. 记录到 results.tsv
7. 决策:
- val_bpb 降低 → 保留提交
- val_bpb 变差/相同 → git reset
8. 回到步骤 1,继续下一轮
关键是决策机制:
# 伪代码
if val_bpb_improved:
keep_commit() # 保留修改,继续前进
else:
git_reset() # 丢弃修改,回到上一个最佳版本
这确保了每次保留下来的改动都是真正有效的。失败的实验立即回退,避免错误累积。
简化性标准也是重要的一环:
- 相同条件下,越简单越好
- 0.001 val_bpb 改进 + 20 行 hacky 代码 → 不值得
- 0.001 val_bpb 改进 + 删除代码 → 值得
- ~0 改进 + 更简单代码 → 值得
这避免 AI 为了微小改进而堆砌复杂代码。
MuonAdamW 优化器
这是 AutoResearch 技术上的一大创新。它对不同类型的参数使用不同的优化策略:
AdamW 组:
用于 token embeddings、LM head、value embeddings 等参数:
embedding_lr = 0.6 # embedding 学习率
unembedding_lr = 0.004 # lm_head 学习率
scalar_lr = 0.5 # scalar 学习率
adam_betas = (0.8, 0.95)
标准 AdamW 算法,学习率按模型维度缩放。
Muon 组:
用于所有 2D 矩阵参数(Q、K、V、O、MLP 权重等):
matrix_lr = 0.04 # matrix 学习率
momentum = 0.95 # Nesterov momentum
ns_steps = 5 # Newton-Schulz 迭代步数
beta2 = 0.95 # 方差减少的 beta2
weight_decay = 0.2 # cautious weight decay
Muon 算法的核心是三步:
- Nesterov Momentum:加速收敛
- Polar Express 正交化:使用 Newton-Schulz 迭代近似正交化,比 SVD 快得多
- NorMuon 方差减少:类似 Adam 的二阶矩估计,更稳定
关键代码片段:
# Polar Express 正交化
X = g / (g.norm() * 1.02 + 1e-6)
for a, b, c in polar_express_coeffs[:ns_steps]:
A = X @ X.T # 或 X.T @ X
B = b * A + c * (A @ A)
X = a * X + X @ B # 或 B @ X
g = X
这个优化器的设计思路是:矩阵参数需要正交化和方差控制,而标量参数用标准 AdamW 就够了。
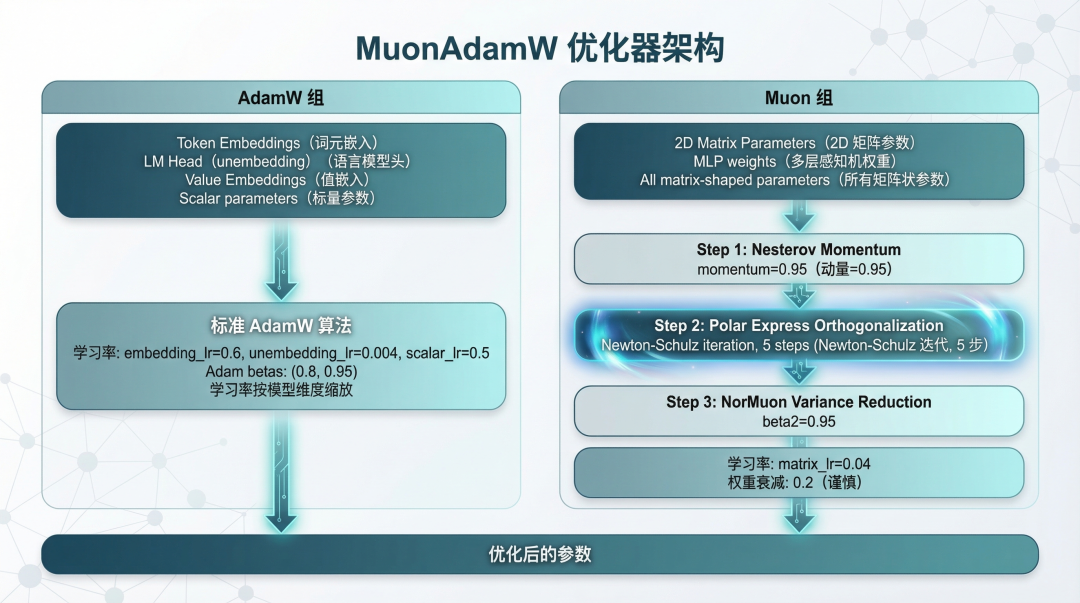
配图3:MuonAdamW 优化器架构 - 展示 AdamW 组和 Muon 组的不同处理流程
配图3:MuonAdamW 优化器架构
ResFormer Value Residual
这是模型架构上的创新:
# 混合 value embedding,使用 input-dependent gate
if ve is not None:
ve = ve.view(B, T, self.n_kv_head, self.head_dim)
gate = 2 * torch.sigmoid(self.ve_gate(x[..., :self.ve_gate_channels]))
v = v + gate.unsqueeze(-1) * ve
作用:在 Value 中混合额外的 embedding。
机制:使用输入相关的门控(gate)调节混合程度。
优势:增强模型表达能力,类似 ResNet 的残差思想。
简单说,就是让模型在计算注意力时,能够根据输入动态调整 value 的表示。
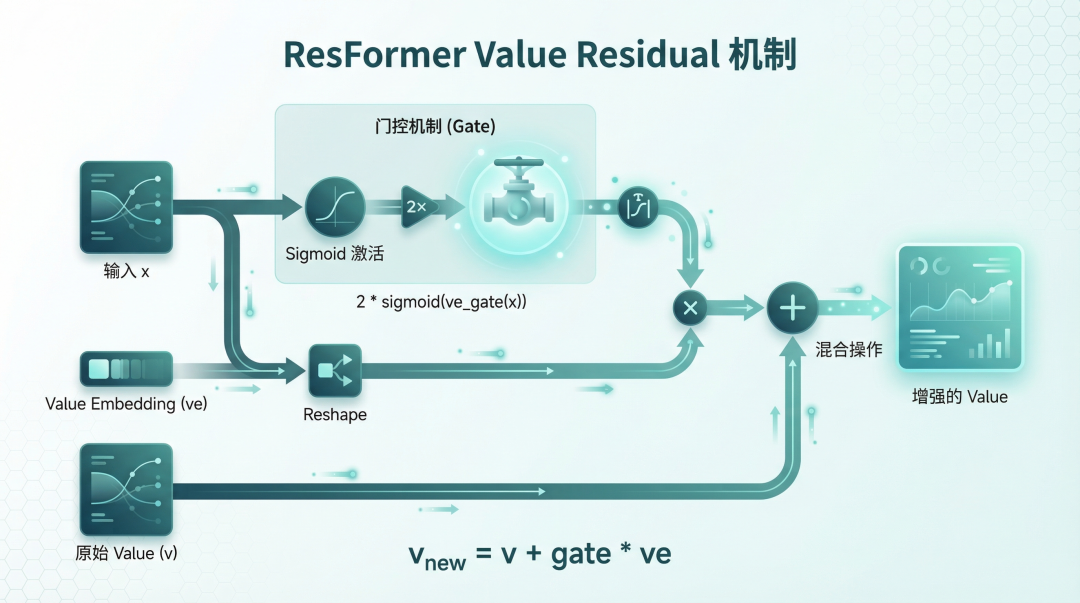
配图4:ResFormer Value Residual 机制示意图 - 展示 gate 如何根据输入动态调节 value embedding 的混合
配图4:ResFormer Value Residual 机制示意图
评估指标 val_bpb
为什么用 bits per byte(BPB)而不是 perplexity?
BPB = total_nats / (log(2) * total_bytes)
BPB 的优势:
- 词汇表大小无关:不同架构的模型可公平比较
- 标准化:信息论标准指标
- 稳定性:比 perplexity 更稳定
计算方式:
@torch.no_grad()
def evaluate_bpb(model, tokenizer, batch_size):
token_bytes = get_token_bytes(device="cuda") # 每个 token 的字节长度
val_loader = make_dataloader(tokenizer, batch_size, MAX_SEQ_LEN, "val")
steps = EVAL_TOKENS // (batch_size * MAX_SEQ_LEN)
total_nats = 0.0
total_bytes = 0
for _ in range(steps):
x, y, _ = next(val_loader)
loss_flat = model(x, y, reduction='none').view(-1)
y_flat = y.view(-1)
nbytes = token_bytes[y_flat]
mask = nbytes > 0# 排除特殊 tokens
total_nats += (loss_flat * mask).sum().item()
total_bytes += nbytes.sum().item()
return total_nats / (math.log(2) * total_bytes)
特殊 tokens(字节长度为 0)被排除,只计算真实内容的压缩率。
四、实战演示
环境准备
# 1. 安装 uv 项目管理器
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. 克隆项目
git clone https://github.com/karpathy/autoresearch.git
cd autoresearch
# 3. 安装依赖
uv sync
# 4. 下载数据和训练分词器(一次性,约 2 分钟)
uv run prepare.py
# 5. 手动运行单次训练(约 5 分钟)
uv run train.py
硬件要求:
- 最低配置:RTX 3090 (24GB VRAM)
- 推荐配置:H100 (80GB VRAM)
如果显存不足,可以调整这些参数:
# train.py
DEPTH = 4 # 降低层数(默认 8)
DEVICE_BATCH_SIZE = 64 # 降低批量大小(默认 128)
# prepare.py
MAX_SEQ_LEN = 1024 # 降低序列长度(默认 2048)
运行 Agent
准备工作完成后,启动一个 Claude Code 会话,输入:
Hi have a look at program.md and let's kick off a new experiment!
let's do the setup first.
Agent 会自动:
- 读取 program.md 和相关文件
- 创建实验分支
- 验证数据和环境
- 初始化 results.tsv
- 开始第一轮实验
监控实验
查看实验记录:
# 查看最近 10 轮实验
tail -n 10 results.tsv
# 查看所有保留的改进
grep "keep" results.tsv
# 统计成功率
awk -F'\t' '{count[$4]++} END {for(s in count) print s, count[s]}' results.tsv
results.tsv 的格式:
commit val_bpb memory_gb status description
a1b2c3d 0.9979 45.06 keep 尝试了 ReLU² 激活函数
e4f5g6h 0.9985 45.12 discard 调整学习率,效果变差
status 字段说明:
keep:保留的改进discard:变差或相同,已回退crash:实验失败
program.md 编写技巧
好的示例:
Focus on reducing training loss by exploring:
1. Different attention mechanisms (try Linear Attention, Flash Attention)
2. Alternative activation functions (test SwiGLU, GeGLU)
3. Novel normalization techniques
Constraints:
- Do NOT change random seed (it doesn't count as real improvement)
- Do NOT increase model size beyond 100M parameters
- Simplicity is preferred: a 0.001 improvement with 20 lines is not worth it
不好的示例:
Try to improve the model. # 太宽泛
鼓励创新:
You are a creative ML researcher. Don't just tweak hyperparameters -
try fundamentally different approaches. Read recent papers for inspiration.
你在项目中用过类似的自动化实验方案吗?欢迎在评论区聊聊你的经验。
五、与传统方法对比
vs 超参数调优工具(Optuna, Ray Tune)
维度 | AutoResearch | 传统调优 |
|---|---|---|
搜索空间 | 代码级修改(架构、算法) | 预定义参数空间 |
搜索策略 | LLM 引导的智能搜索 | 贝叶斯优化、网格搜索 |
人力投入 | 只需编写初始指令 | 需定义搜索空间、目标函数 |
创新能力 | 可探索架构变化 | 仅限参数调优 |
计算效率 | 序列化,避免浪费 | 并行 sweep,计算密集 |
核心差异:AutoResearch 不只是调参,可以修改代码本身。LLM 的"理解"使搜索更智能,而非盲目搜索。
vs AutoML(AutoGluon, H2O)
维度 | AutoResearch | AutoML |
|---|---|---|
目标 | AI 研究自动化 | ML pipeline 自动化 |
适用场景 | 模型架构和训练研究 | 特征工程、模型选择 |
可解释性 | 高(所有改动都在 git 中) | 低(黑箱自动化) |
灵活性 | 修改代码,探索新方法 | 在预定义选项中选择 |
人类角色 | 研究指导者 | 监督者 |
核心差异:AutoResearch 是研究工具,AutoML 是应用工具。
vs Agent 框架(LangChain, AutoGPT)
维度 | AutoResearch | 通用 Agent 框架 |
|---|---|---|
专注领域 | 机器学习研究 | 通用任务自动化 |
工作流 | 固定的实验循环 | 可定制的工具链 |
评估机制 | 明确的 val_bpb 指标 | 依赖 LLM 自我判断 |
可靠性 | 高(每次实验可验证) | 低(结果不确定性高) |
核心差异:AutoResearch 有明确的成功标准(val_bpb),通用 Agent 框架的评估更主观。

配图5:AutoResearch vs 传统超参数调优对比 - 多维度对比展示 AutoResearch 的优势
配图5:AutoResearch vs 传统超参数调优对比
六、最佳实践
1. 明确研究方向
在 program.md 中提供具体的指导:
# 好的示例
Explore three directions:
1. Attention: Try Flash Attention 3, Linear Attention
2. Activation: Test SwiGLU, GeGLU, compare with ReLU²
3. Normalization: Experiment with different LayerNorm variants
# 不好的示例
Try different things. # 太模糊
2. 设置边界和约束
避免 AI 做无意义的"改进":
Constraints:
- Do NOT change random seed
- Do NOT increase model size beyond 100M parameters
- Do NOT modify evaluation harness
- Simplicity matters more than micro-optimizations
3. 定期检查实验日志
# 每小时检查一次
watch -n 3600 'tail -n 20 results.tsv'
# 分析失败模式
grep "crash" results.tsv | tail -n 10
如果发现:
- 多次 crash → 可能是显存不足或代码 bug
- 大量 discard → 搜索空间不合适
- 改进停滞 → 需要调整研究方向
4. 利用 git 历史回溯
# 查看某个成功实验的具体改动
git show <commit-hash>
# 对比两次实验
git diff <commit1> <commit2> train.py
5. 资源配置建议
短期测试:1-2 小时(12-24 轮实验)
中期实验:过夜(8 小时,约 100 轮)
长期研究:数天(需定期检查和调整 program.md)
七、总结
AutoResearch 的核心价值在于:把机器学习研究从手工作坊变成了自动化流水线。
技术亮点:
- 固定时间预算确保实验可比性
- 单文件修改降低复杂度
- MuonAdamW 优化器创新
- 630 行代码实现完整流程
适用场景:
- ML 研究者快速验证想法
- 学生学习训练流程
- 独立开发者低成本探索
- 团队提升实验效率(24/7 运行)
局限性:
- 需要 NVIDIA GPU(最好是 H100)
- AI 默认倾向保守改动
- 只优化单一指标(val_bpb)
- 不同平台结果不可直接比较
从 Hacker News 的讨论看,社区对这个项目的期待很高。有人预测"AI 研究自动化将导致递归自我改进,最终实现超级智能"。也有人认为"'AI Ops'将成为标准职位,Harness Engineer 和 Agent Reliability Engineer 会像 DevOps 一样重要"。
说实话,AutoResearch 还没到"颠覆研究范式"的程度。但它确实展示了一种可能性:AI Agent 可以在特定领域(机器学习研究)实现高度自动化,而且代码和结果完全可审查、可追溯。
Karpathy 在 program.md 里写了这么一句话:NEVER STOP。无限循环,直到人类中断。
这大概就是对自进化 Agent 最好的描述。
相关资源
GitHub 仓库:https://github.com/karpathy/autoresearch
Karpathy 的推文:https://x.com/karpathy/status/2029701092347630069
Hacker News 讨论:https://news.ycombinator.com/item?id=47291123
数据集 climbmix-400b-shuffle:https://huggingface.co/datasets/karpathy/climbmix-400b-shuffle
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号