
Agent 可观测性与评测:从 trace 到回放的完整链路
### —— 当 Agent 进了生产,"能跑"和"敢上"之间隔着一整套基础设施 --- ## 引言:被严重低估的"看见与衡量" 回顾前三篇文章——Skills 规范、MCP 治理、编排框架选型。它们共同回答了一个问题:**怎么把 AI 能力工程化地搭起来**。 但搭起来不是终点。真正的考验是**它能不能持续跑下去**。 而能不能持续跑下去,取决于一件被严重低估的事: > **你能不能"看见"它在做什么,并"衡量"它做得怎么样。** 这件事的名字是**可观测性 + 评测**。 听起来朴素,但绝大多数 AI 团队在这件事上的现状是这样的: - 用户反馈"Agent 答错了"——你打开日志,看到一堆模糊的 JSON,**还原不出当时发生了什么**; - 上线一个 prompt 改动——你不知道它**让哪些场景变好了、哪些变差了**; - Skill 加载了,但**没人知道它实际被激活了几次、误触发了几次**; - 用户的同一句问题,**昨天答得对,今天答错了,你不知道为什么**; - 想做回归测试——你**没有任何历史轨迹**可以对比; - 想算单次对话成本——你**只能看月账单**。 **这不是 prompt 写得不好,也不是模型不行——这是基础设施缺失**。 传统软件工程花了 20 年发展出来的"APM、Tracing、Logging、Metrics、CI/CD、Canary"那一整套,**在 AI 工程上几乎要重新走一遍**。但 AI 工程有两个传统软件没有的特性: 1. **不确定性**——同样的输入两次结果可能不一样; 2. **昂贵**——每次调用都在花钱。 这意味着你不能照搬传统 APM 那一套。**AI 时代的可观测性 + 评测,是一套需要重新设计的基础设施**。 这篇文章不讲"上 Datadog / Langfuse / LangSmith"——那是工具问题。我们讲**原则与设计**: 1. AI 系统该观测什么?传统 trace 为什么不够? 2. Trace schema 该怎么设计才能撑住未来的查询需求? 3. 回放(Replay)为什么是 AI 可观测的命门?怎么做? 4. Cost / Latency / Quality 这三件事怎么同时盯? 5. 评测体系怎么从"一次性 eval"升级到"持续 eval"? 6. 离线 eval 和线上 telemetry 怎么打通? 7. 哪些是反模式?哪些是必须躲开的坑? **不绕弯子,直接进入正文。** --- ## 一、AI 可观测性 vs 传统可观测性:到底差在哪 要做好 AI 可观测,先要认识到它**和传统系统的可观测性完全不是一回事**。 ### 1.1 三类传统可观测信号 传统软件工程的可观测性主要靠"三剑客": | 信号 | 用途 | 典型工具 | |------|------|---------| | **Logs** | 离散事件记录 | ELK、Loki、CloudWatch | | **Metrics** | 数值聚合(QPS、延迟、错误率) | Prometheus、Datadog | | **Traces** | 跨服务请求链路 | Jaeger、Zipkin、OpenTelemetry | 这套体系**回答的是**: - 系统现在健康吗? - 这个请求经过了哪些服务? - 错误集中在哪个组件? ### 1.2 AI 系统的"独有问题" 但 AI 系统还要回答另一批问题,传统三剑客**回答不了**: | 问题 | 传统三剑客能答吗 | |------|----------------| | 这次对话模型为什么这样回答? | 不能 | | 同样输入再来一次会怎样? | 不能(需要 replay) | | 这个 Skill 该激活时激活了吗? | 不能(需要语义判定) | | 这个 prompt 改动影响了哪些场景? | 不能(需要 eval) | | 单次对话成本是多少? | 不能(需要 token 计费) | | 模型表现今天比昨天差吗? | 不能(需要质量评估) | **这些问题的共同点**:它们不是"系统跑没跑"的问题,而是"系统做得怎么样"的问题。 **传统可观测关心 Liveness,AI 可观测还要关心 Quality**。 ### 1.3 三件事必须同时盯 AI 系统的可观测,本质上是同时盯三件事: 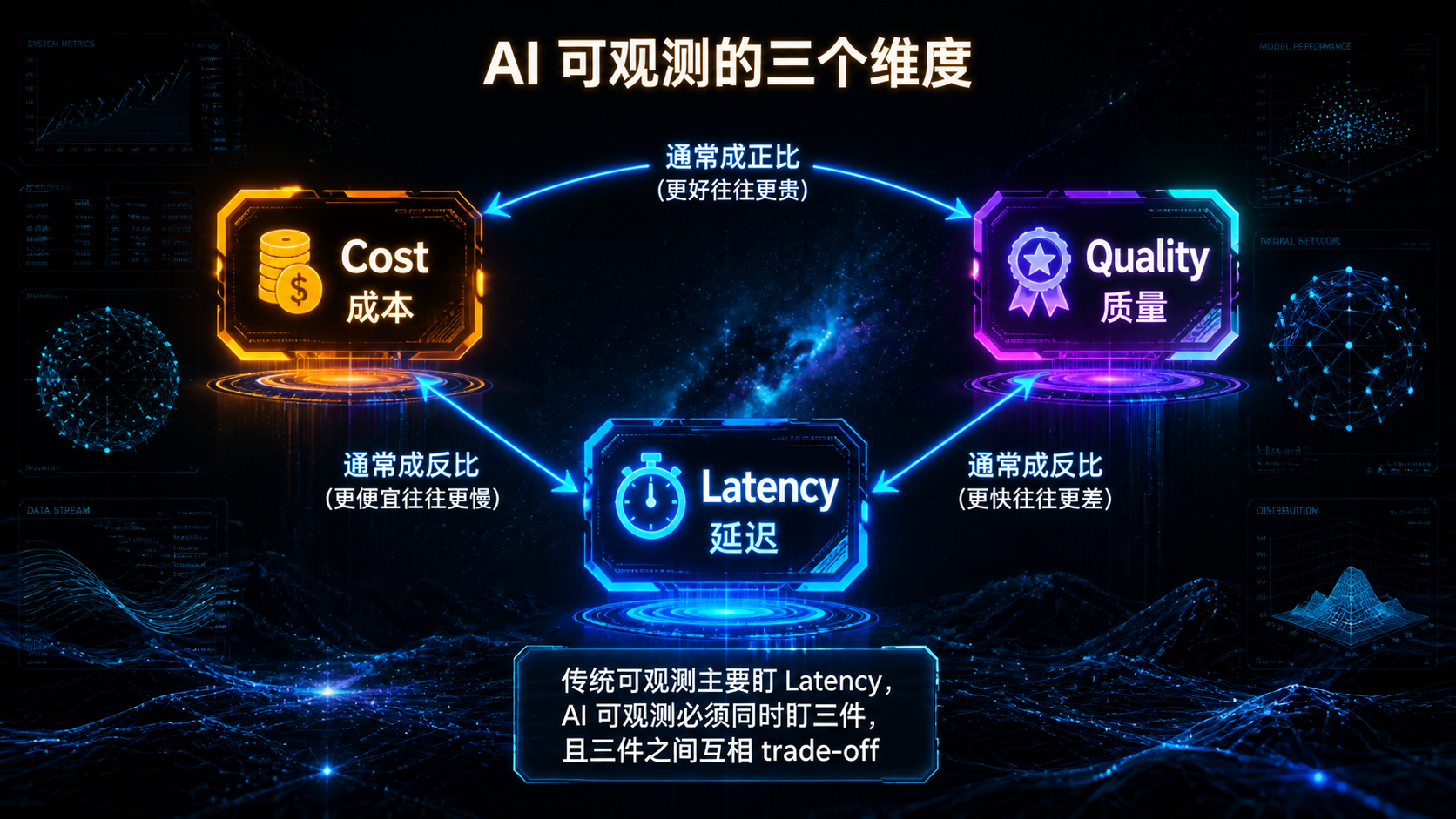 **关键洞察**: - 任何一件单独优化都会让另两件恶化; - 任何决策(换模型、改 prompt、加 Skill)都要看**三件一起变了多少**; - 没有同时盯三件的能力,AI 系统的优化就是**盲人摸象**。 这就是为什么 AI 可观测必须**自上而下重新设计**——不是在传统 APM 上加几个 metric 就够的。 --- ## 二、Trace Schema:可观测的"基础设施级决策" 如果说 Registry 是 MCP 治理的真相之源,那么 **Trace Schema 是 AI 可观测性的真相之源**。 ### 2.1 为什么 Schema 这么关键 很多团队的 telemetry 演进路径是这样的: 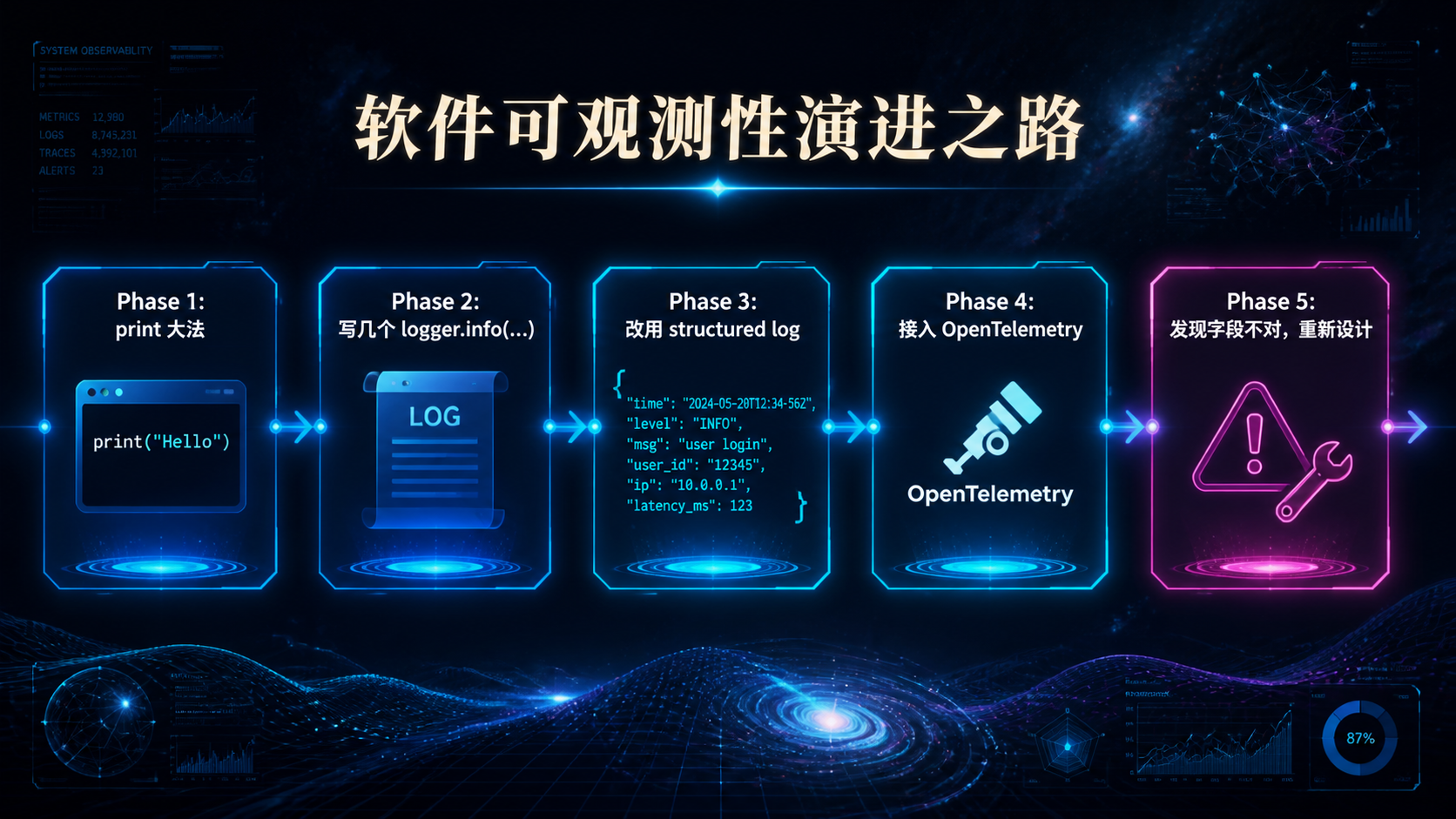 **Phase 5 永远会到来**——因为前期没想清楚 schema,所有数据都是"半结构化"的,**无法支撑后期复杂查询**。 到那时你想回答"上周哪些 Skill 误激活率超过阈值",发现日志里**根本没记 Skill 激活事件的语义信息**——只能重新埋点,等数据攒够。 **Schema 是基础设施级决策**——一旦定下来,三个月内基本无法重构。 ### 2.2 AI Trace 的事件层级 设计 schema 的第一步:**承认 AI 系统的事件是分层的**。 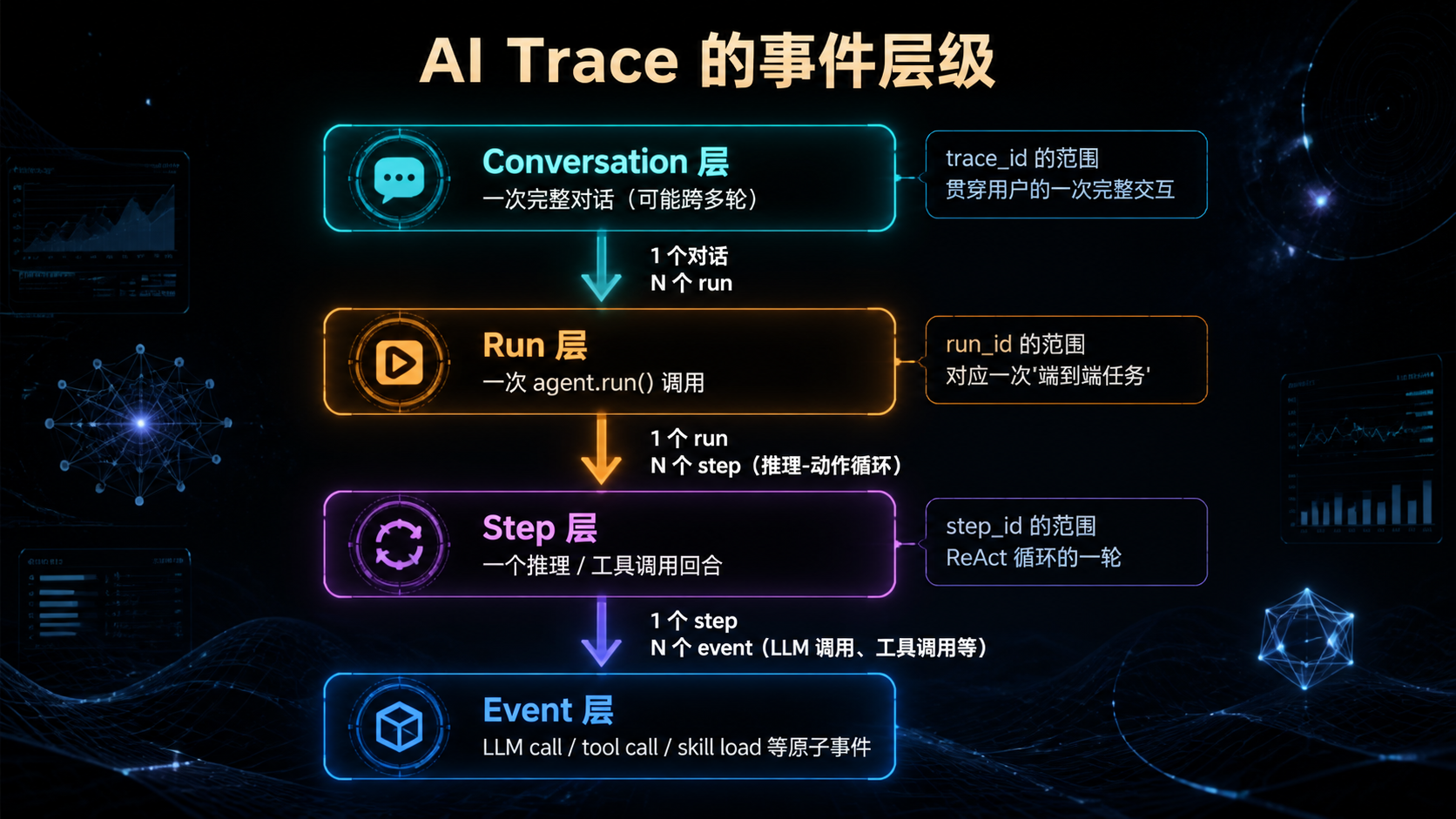 **关键设计**:每一层都有自己的 ID,但**通过父子关系链起来**。 这让你能回答完全不同粒度的问题: - "用户 X 上周所有对话的平均时长" → Conversation 层; - "这个 Skill 平均要几个 step 完成" → Run 层; - "tool call 失败率分布" → Event 层。 ### 2.3 最小 Schema 设计 下面是一个**够用、可扩展**的最小 schema: ```yaml # Event 层(最细粒度) event: event_id: uuid # 全局唯一 parent_step_id: uuid # 所属 step parent_run_id: uuid # 所属 run parent_conversation_id: uuid # 所属对话 trace_id: uuid # 与 parent_run_id 一致或更大范围 timestamp: iso8601 duration_ms: int kind: enum # llm_call | tool_call | mcp_call | skill_tier1_loaded | skill_tier2_activated | skill_tier3_resource_read | checkpoint_saved | interrupt | error # LLM 调用专属 model: str # claude-3-5-sonnet-20241022 等 model_version: str input_tokens: int output_tokens: int cached_tokens: int # prompt caching 命中 cost_usd: float finish_reason: str # stop | tool_use | max_tokens | error # Tool / MCP 调用专属 tool_name: str mcp_server_id: str # 如果是 MCP input_size_bytes: int output_size_bytes: int outcome: enum # success | error | timeout | cancelled error_class: str # 见 §2.5 # Skill 专属 skill_name: str skill_version: str tier: int # 1 | 2 | 3 # 通用扩展 metadata: map<str, any> # 业务自定义字段,但不放 PII ``` **关键设计原则**: 1. **每个字段都有明确的查询用途**——没有"未来可能有用"的字段; 2. **PII 默认不进 trace**——payload 在外层处理(见 §2.6); 3. **error_class 是枚举**——见 §2.5; 4. **cost_usd 是必填**——这是 AI 可观测最重要的字段之一。 ### 2.4 不要落 payload 默认值 最容易做错的事:**默认把所有 LLM 输入输出落库**。 为什么这是事故级反模式? - **PII 泄漏**:用户聊天内容、上传的文件、对话上下文都可能包含 PII; - **凭据泄漏**:错误处理不严的话,凭据可能出现在 prompt 里; - **存储爆炸**:单次对话 100KB,每天 100 万次对话 = 100GB; - **合规风险**:GDPR / CCPA 对存储用户内容有明确要求。 **正确做法**:默认只记 size 和 hash,按需采样 + 显式 allowlist 才采全文。 ```yaml event: ... input_size_bytes: 4823 input_hash: sha256:abc123... # 用于关联但不暴露内容 input_preview: "前 100 字符..." # 可选,受 allowlist 控制 full_input_stored: false # 标识是否采样了全文 ``` **例外**:评测环境、debug 环境可以全采。**生产环境默认不采**。 ### 2.5 错误分类不能用自由文本 新人最容易犯的错: ```yaml error_class: "Connection refused, retrying..." # 反模式 ``` 这种"自由文本"错误信息**无法聚合统计**。半年后你想看"timeout 类错误占比",没检查。 正确做法:**预定义错误枚举**。 ```yaml error_class: # 模型相关 - model.timeout - model.rate_limit - model.context_too_long - model.invalid_response - model.refusal # 工具相关 - tool.not_found - tool.invalid_args - tool.execution_failed - tool.timeout # MCP 相关 - mcp.connection_lost - mcp.protocol_error - mcp.auth_failed # Skill 相关 - skill.activation_failed - skill.tier3_load_failed - skill.script_failed # 业务相关 - business.invalid_input - business.policy_violation # 兜底 - unknown ``` **`unknown` 必须能进一步细分**——发现 `unknown` 多了就要分裂出新枚举值。 ### 2.6 PII 与凭据:从设计层堵死 PII 保护不是"在日志里做 redact"——那是**事后补救**,永远会有遗漏。 正确做法是**从 schema 设计就分层**: 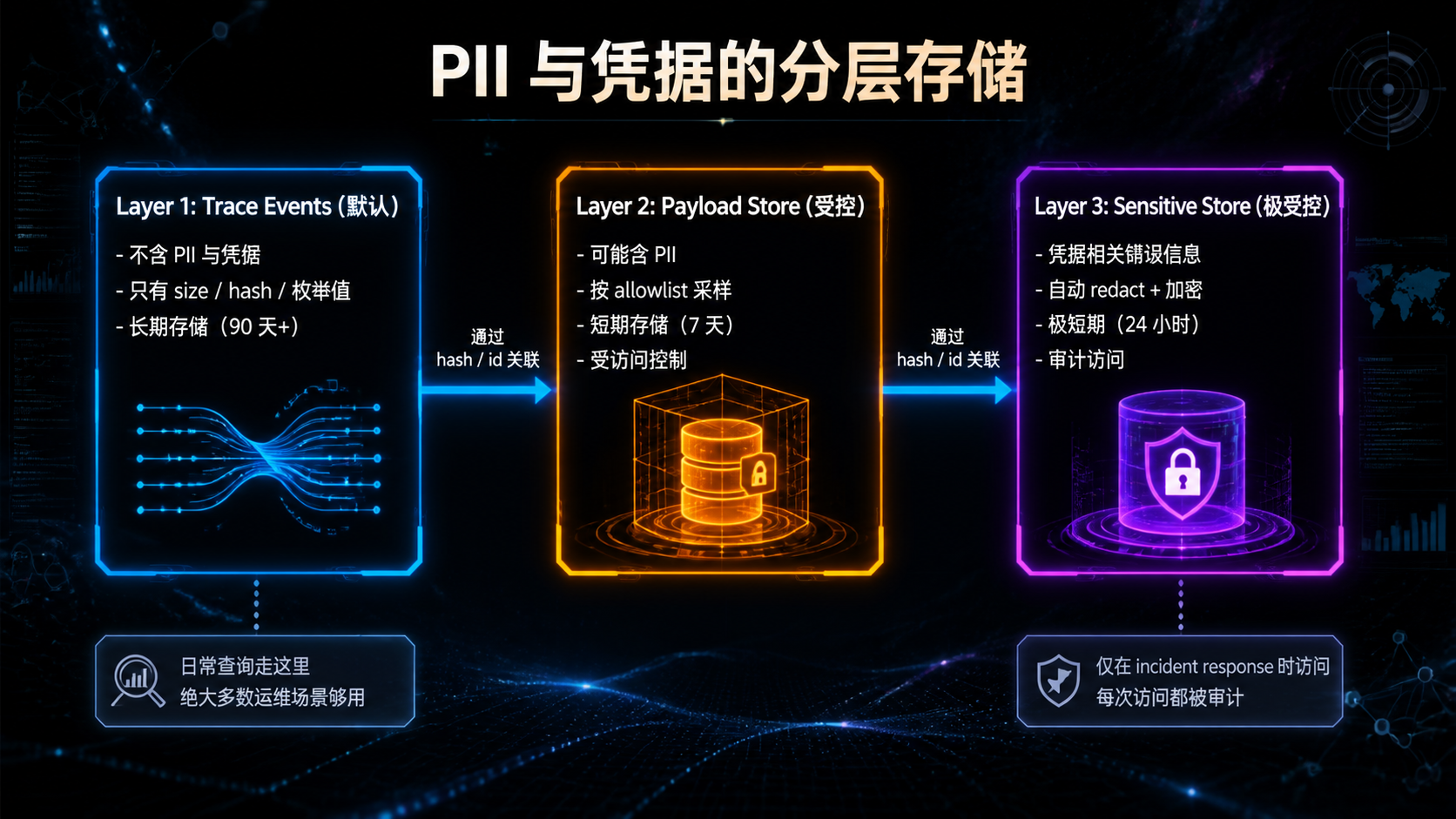 **三层存储原则**: 1. **Layer 1(trace)**:永远不含敏感数据,可以放心长期存; 2. **Layer 2(payload)**:可能含 PII,访问受控,短期存; 3. **Layer 3(sensitive)**:凭据相关,加密 + 审计 + 极短期。 **通过 hash / id 跨层关联**——查询时按需 join。 这样既能回答"上周哪些 conversation 调用了 X tool"(Layer 1 就够),又能在事故响应时按需访问 payload,**不在日常查询时暴露敏感数据**。 --- ## 三、Replay:AI 可观测的命门 讲完 trace,进入这篇文章最关键的概念——**回放(Replay)**。 如果说 trace 让你"看见发生了什么",**replay 让你"让它再发生一次"**。这是 AI 系统区别于传统系统的根本能力。 ### 3.1 为什么 Replay 是 AI 时代的特有需求 传统系统的 bug: > "用户点击按钮没反应。" > → 看日志,发现几个 service 返回了 500。 > → 看 stack trace,定位到具体代码行。 > → 修。 AI 系统的 bug: > "用户问'帮我订机票',Agent 答了一段无关的内容。" > → 看日志,**模型的输出就是那段无关内容**。 > → 看 prompt 和 tool 调用——**都符合预期**。 > → 这个 case **不可重现**——模型有不确定性。 **这是 AI 系统的特有困境**:错误本身在数据里,但**无法直接归因到代码**。 Replay 的作用,是把这种"不可重现"的 bug **变成可重现的**。 ### 3.2 Replay 要存什么 要做 Replay,trace 还不够——你需要存"足够还原现场"的所有东西。 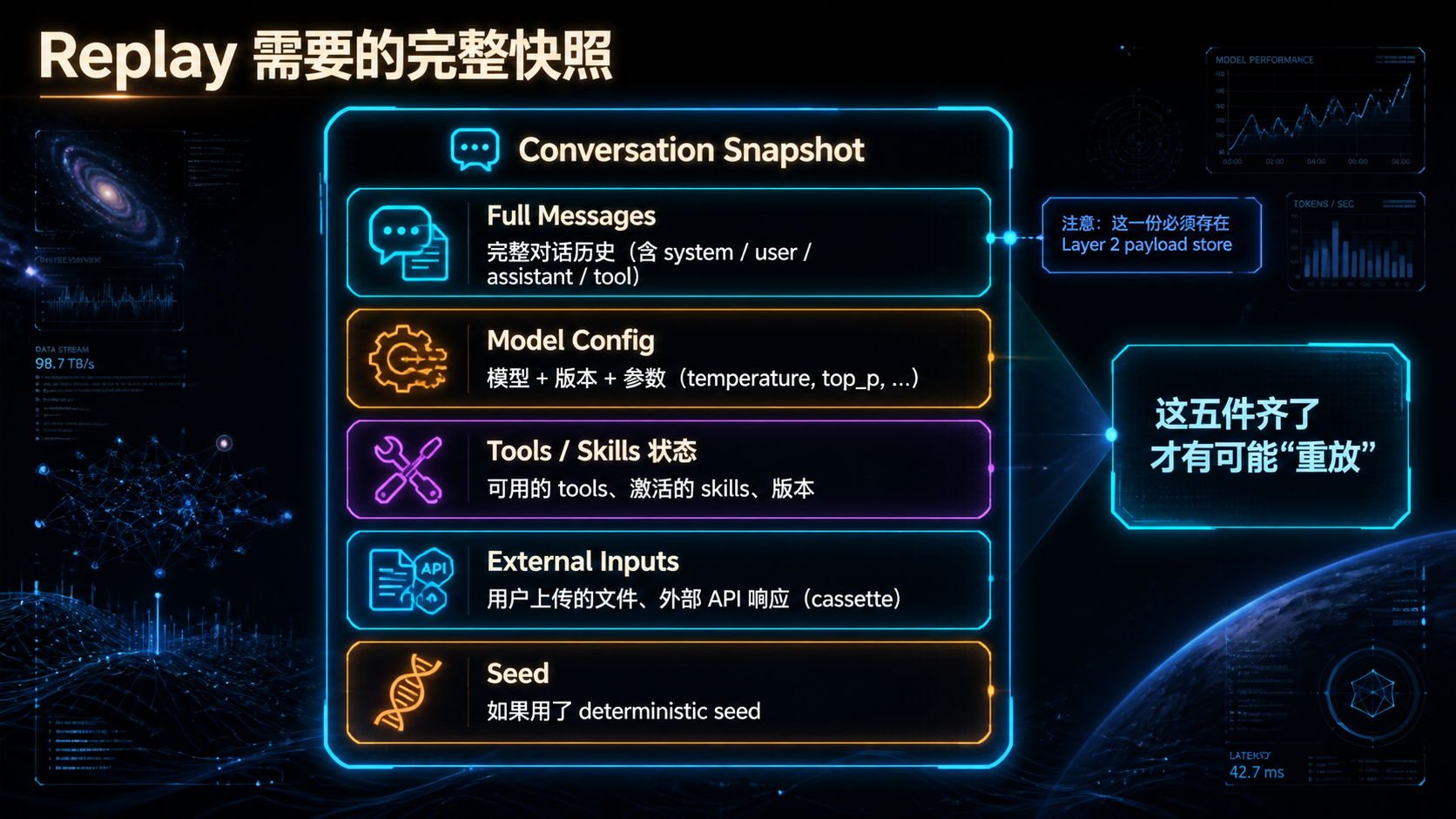 **Replay 不是"用同样的输入再跑一次"**——这个理解太天真。 真正的 Replay 需要: 1. **完整对话历史**(不是简化版); 2. **模型配置**(同一 prompt + 不同 temperature 行为完全不同); 3. **当时可用的 tools / skills**(一个 Skill 的版本变了,召回就变了); 4. **外部输入**(用户上传的文件、当时的 API 响应——需要 cassette 录制); 5. **随机种子**(如果用了 deterministic mode)。 ### 3.3 三种 Replay 模式 不同场景需要不同 Replay 模式: | 模式 | 输入 | 用途 | |------|------|------| | **Exact Replay** | 用 cassette 重放所有外部响应 | bug 复现、回归测试 | | **Live Replay** | 重新调外部 API | 验证当前生产环境行为 | | **Counter-factual Replay** | 改一个变量(如换模型、改 prompt) | 评估改动影响 | 最常用的是 **Counter-factual Replay**——这是 AI 可观测的"杀手级特性"。 ### 3.4 Counter-factual Replay 的真实价值 设想一个场景: > 你把主力模型从 Claude 3.5 Sonnet 换成 Claude 4 Sonnet。 > > 没有 Replay 执行力时:上线灰度,等用户反馈,看几天数据。 > > 有 Replay 能力时:拿上周 1000 个真实 conversation 的 trace,**用新模型全部 replay 一遍**—— > - 同样的输入下,新旧模型分别怎么回答; > - 哪些 case 答得更好,哪些更差; > - 成本变化多少; > - 延迟变化多少。 **这是从"猜测"到"量化"的跨越**。 不止是换模型——换 prompt、加 Skill、调 temperature、改 tool 描述,**任何变更都可以用 Replay 验证**。 ### 3.5 Replay 的工程现实 Replay 听起来很美好,但有几条工程现实必须面对: #### 现实 1:外部状态难以重放 如果 Agent 调用了"创建 GitHub issue"这种**有副作用**的 tool,replay 时怎么办? 两种处理: - **Mock 模式**:tool 调用走 cassette,不真的执行副作用; - **Sandbox 模式**:副作用执行在隔离环境(staging GitHub 仓库)。 Counter-factual Replay 必须避免重复副作用——**不要在 replay 中真的发邮件**。 #### 现实 2:模型不确定性 即使 input 完全一样,模型两次输出也可能不同。 应对: - 评估时**多次 replay**(n_runs),看分布; - 关键指标用**通过率**而非单次结果; - 用 `temperature=0` 减少波动(但不能完全消除)。 #### 现实 3:存储成本 每个 conversation 都存完整快照——存储会爆炸。 应对: - **采样存储**:100% trace + 10% full payload + 1% cassette; - **TTL 分层**:trace 90 天,payload 7 天,cassette 30 天; - **关键 case 永久保存**:bug 复现的、用户投诉的、评测集里的——单独打 tag,永不过期。 --- ## 四、Cost / Latency / Quality:三件事一起盯 回到 §1.3 的核心:AI 可观测必须同时盯三件事。这一章拆开每一件该怎么盯。 ### 4.1 Cost:必须精确到 conversation 很多团队的 cost 监控停留在"看月账单"——这是**最粗糙的方式**。 正确做法:**每个 event 都计算 cost,向上聚合到 step / run / conversation / user**。 ```yaml # 在每个 LLM call event 上计算 event: kind: llm_call model: claude-3-5-sonnet-20241022 input_tokens: 4823 output_tokens: 612 cached_tokens: 3200 cost_usd: 0.0231 # 按当时定价计算 # 拆分(便于归因) cost_breakdown: input_uncached: 0.0049 input_cached: 0.0048 output: 0.0092 total: 0.0231 ``` **有了 event 级 cost 后,能回答的问题**: - 单个 user 的月度成本(trace_id → user); - 单个 conversation 的成本(trace 聚合); - 单个 Skill 激活的平均成本(filter by skill_name); - 哪个 tool 调用最贵; - Prompt caching 命中率(cached_tokens / input_tokens); - 哪些 conversation 异常高成本(top N)。 **Cost 监控的实操要点**: 1. **价格表配置化**——模型价格会变,不要硬编码; 2. **按模型版本计费**——`claude-3-5-sonnet-20241022` 和 `claude-3-5-sonnet-20240620` 价格可能不同; 3. **Cached tokens 单独算**——Prompt caching 是 5-10x 成本差异; 4. **设置预算告警**——单 conversation / 单 user / 日总额都要有阈值。 ### 4.2 Latency:分层测,分层告警 延迟在 AI 系统里**非常容易掩盖问题**。 为什么?因为 LLM 调用本身就 1-10 秒——单一指标 "p95 延迟" 看不出哪一段慢。 正确做法:**按事件类型分层测**。 | 层 | 测什么 | 典型范围 | |----|--------|---------| | End-to-end | 用户感知的总耗时 | 数秒到数十秒 | | Run | 一次 agent.run 总时长 | 同上 | | Step | 一个推理-动作回合 | 1-10 秒 | | LLM call | 单次模型调用 | 500ms-5s | | Tool call | 单次工具调用 | 10ms-1s | | MCP call | 单次 MCP 调用 | 10ms-数百 ms | | Skill load | Tier 2/3 加载 | <100ms | **关键指标**: - 每一层的 p50 / p95 / p99; - **First token latency**(流式输出第一个 token 的时间)——这才是用户感知的"开始响应"; - **Tool call wait ratio**(等工具的时间占比)。 **告警阈值**: - 不要用绝对数字("超过 5 秒就告警")——AI 系统的延迟天然就高; - 用**变化率**告警("p95 比上周同期高 50%")——这才反映真实回退。 ### 4.3 Quality:最难,但最重要 Quality 是三件事里最难量化的——但**不量化就没法优化**。 #### 三种 Quality 信号 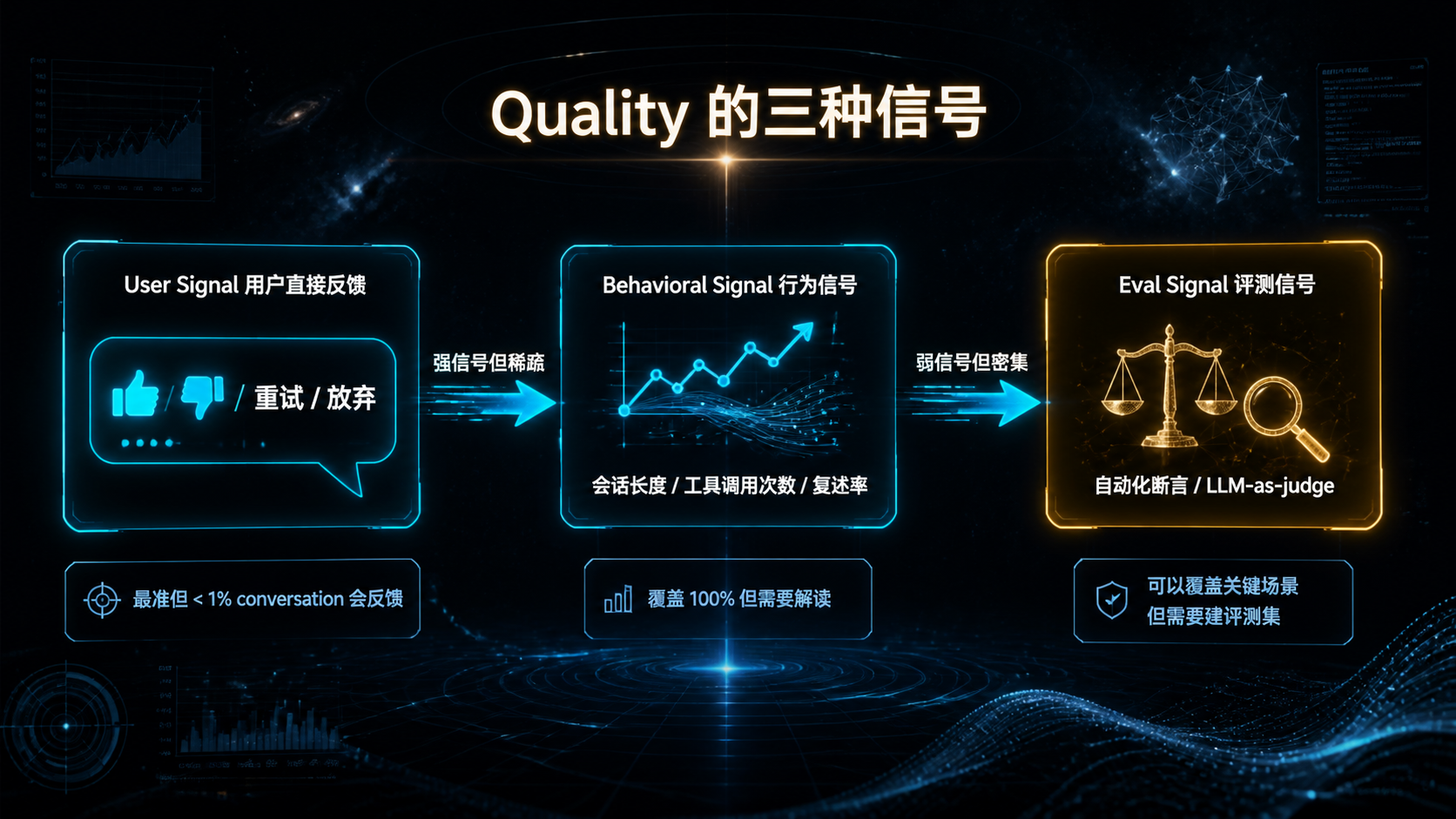 **三种信号的组合使用**: 1. **User Signal**——准确但稀疏; 2. **Behavioral Signal**——密集但模糊; 3. **Eval Signal**——主动出击,针对关键场景。 **单独依赖任何一种都不够**。 #### Behavioral Signal 的典型指标 | 指标 | 含义 | 高表示 | |------|------|-------| | 平均轮次 | 一个 conversation 多少轮 | 任务复杂 / 答得不好 | | Tool 调用次数 | Agent 调了几次工具 | 思路混乱可能调一堆 | | Skill 误激活率 | 测试集中不该激活的激活了 | 描述写不好 | | 用户重述率 | 用户改述同一问题的比例 | 答得不好 | | 任务放弃率 | 用户中途离开 | 答得不好 | 这些指标**单看意义不大**,但**对比看变化趋势**就很有用。 #### Eval Signal:核心是评测集 下一章专门讲。 --- ## 五、评测:从一次性到持续 讲完可观测,进入评测。评测和可观测**不是一回事**,但**密不可分**。 ### 5.1 一次性 eval vs 持续 eval 绝大多数团队的评测演进路径: ``` Phase 1: 不评测,靠 vibes Phase 2: 上线前手动跑几个 case Phase 3: 写个 eval 脚本,每次发版跑 Phase 4: CI 接入,PR 自动跑 Phase 5: 持续 eval(线上数据进评测集,每天跑) ``` **很多团队停在 Phase 3**——这是不够的。 为什么?因为 AI 系统的**性能会漂移**: - 模型版本变了(即使你没主动升); - Prompt 改了某句话,影响了别的场景; - 外部 API 行为变了; - 用户输入分布变了。 **没有持续 eval,你只能事后知道质量下降了**。 ### 5.2 评测集的分层设计 评测集不能是"一堆 case 怼一起"——必须分层。 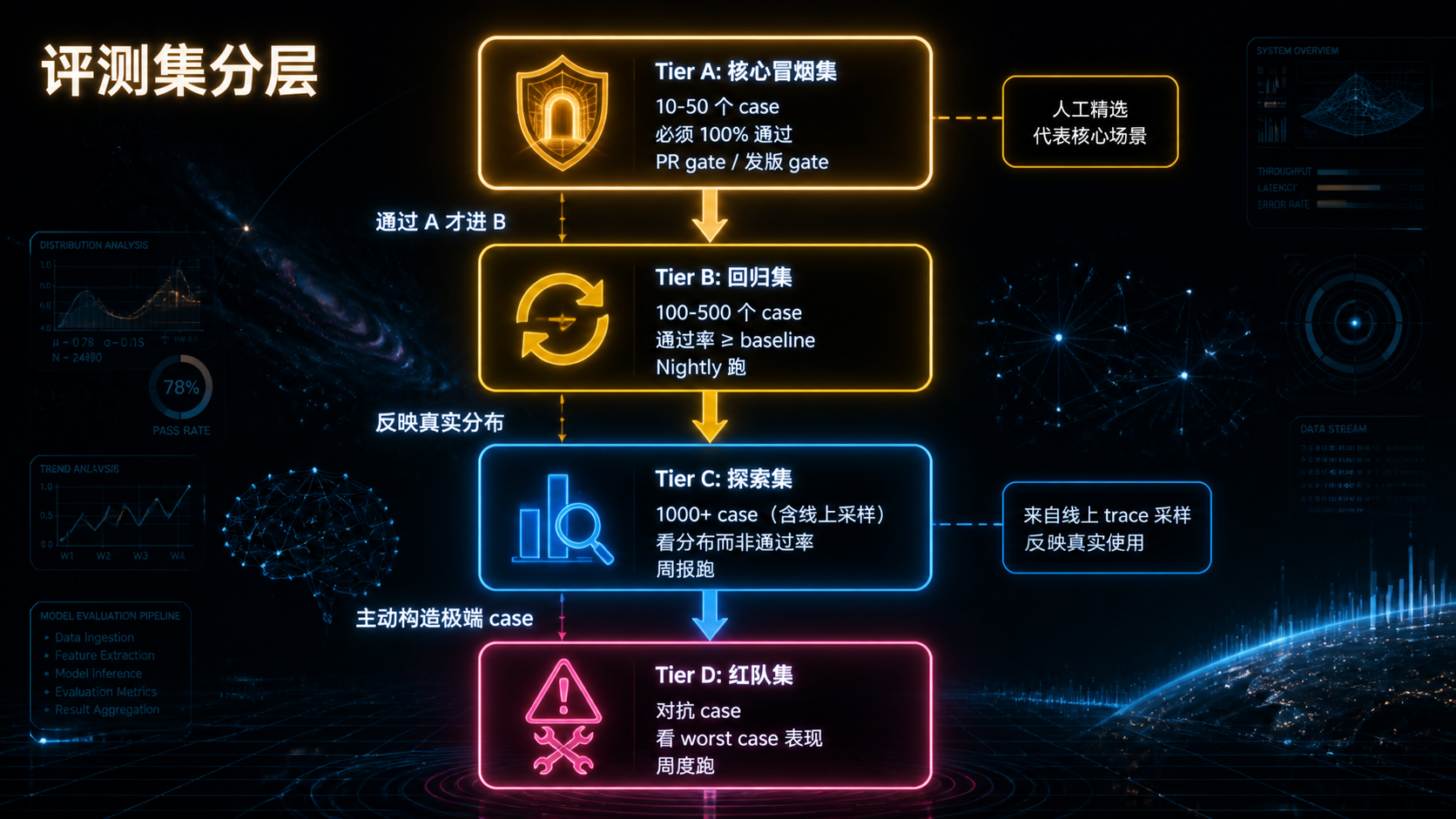 每一层有不同的频率、阈值、用途: | Tier | 大小 | 频率 | 阈值 | 用途 | |------|------|------|------|------| | A. 冒烟 | 10-50 | PR | 100% | 阻塞发版 | | B. 回归 | 100-500 | Nightly | ≥ baseline | 检测回归 | | C. 探索 | 1000+ | 周 | 看分布 | 发现新问题 | | D. 红队 | 50-200 | 月 | 看 worst | 找边界 | ### 5.3 评测的三种判定方式 每个 case 怎么判通过?三种方式: | 方式 | 适用 | 优点 | 缺点 | |------|------|------|------| | **确定性断言** | 输出结构化(文件、JSON、code) | 100% 可靠 | 覆盖不了开放回答 | | **关键词检查** | 必须 / 不能出现某些词 | 简单 | 容易绕过 | | **LLM-as-judge** | 开放回答 | 灵活 | 自身有不确定性 | **实操原则**: 1. **能用确定性断言就用**——它最可靠; 2. **关键词检查作为补充**——尤其用于"必须不出现"的约束; 3. **LLM-as-judge 是兜底**——必须固定 judge 模型版本,多次重复看通过率。 ### 5.4 Skill 激活的评测特殊性 回顾 Skills 那一篇——评测 Skill 激活有特殊性。 **反模式**:通过输出字符串匹配判定激活。 > "如果输出里有 'PDF',那 pdf-skill 应该激活了。" **为什么不行**: - 模型可能口头提到 "PDF" 但没真激活 Skill; - 模型也可能激活了 Skill 但输出没出现 "PDF"; - 措辞变化会让判定失效。 **正确做法**:**通过 trace 中的 Skill activation event 判定**。 ```python def is_skill_activated(trace, skill_name): for event in trace.events: if (event.kind == "skill_tier2_activated" and event.skill_name == skill_name): return True return False ``` **这是 trace schema 设计的回报**——只要 schema 设计得好,评测判定就能精准。 ### 5.5 持续 eval:让线上反哺评测 最后一步:**让线上 trace 持续给评测集供血**。 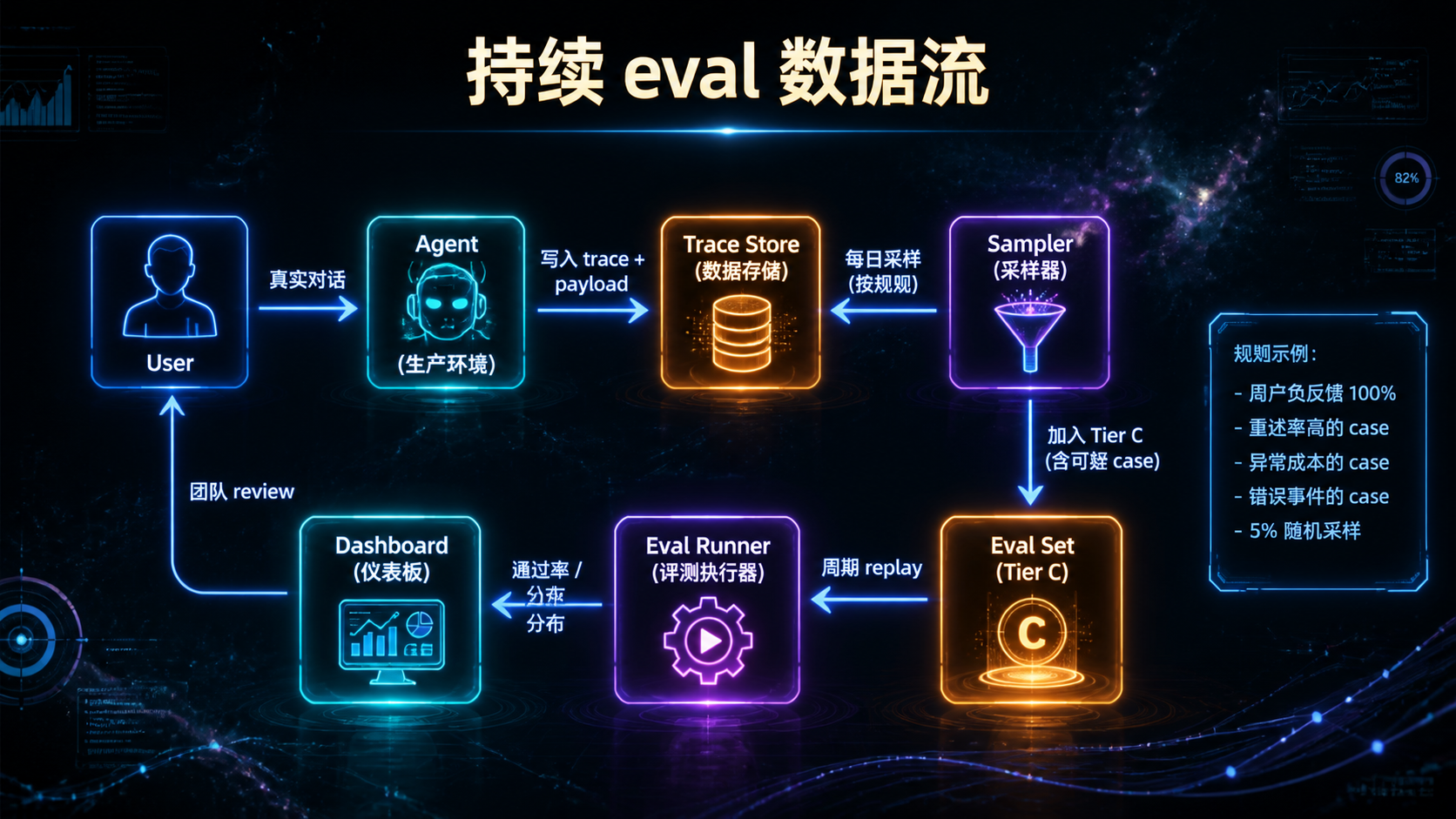 **这一闭环的关键**: 1. **采样规则**——不要 100% 都进评测集(噪声太多)。优先采用户负反馈、异常 case、错误 case; 2. **PII 处理**——进评测集前必须脱敏; 3. **人工标注**——Tier C 的"期望输出"需要人工标,工作量不小; 4. **关键 case 升级**——发现重要的 Tier C case,手动升级到 Tier B 或 Tier A。 **这是 AI 工程"飞轮"的核心**:线上数据 → 评测集 → 持续优化 → 线上数据。**没有这个飞轮,AI 系统会留在初版**。 --- ## 六、工程现实:那些落地时一定会撞的坑 讲完原则与设计,必须讲工程现实——**很多事是"听起来美好做起来痛苦"的**。 ### 6.1 成本爆炸:可观测自己也很贵 可观测系统本身有成本: - **Trace 存储**:百万级 event/day,存储费不便宜; - **Eval 调用**:n_runs × case 数 × 频率,token 费可观; - **Replay 调用**:counter-factual replay 每次都是真实 LLM 调用。 **控制手段**: 1. **采样**:Trace 100%,Payload 10%,Cassette 1%; 2. **TTL 分层**:见 §2.6; 3. **PR 只跑变更**:CI 评测只跑相关 Tier A,nightly 跑 Tier B; 4. **Cassette 重放**:Eval 用录制的 cassette 而不是真实 LLM; 5. **预算上限**:评测系统本身设月度预算,超了告警。 ### 6.2 隐私与合规 PII 已经在 §2.6 讲了。再补充几点: - **存储位置合规**:欧盟用户数据可能不能存美国; - **保留期合规**:GDPR 有"被遗忘权"——用户要求删除时,trace 也要删; - **审计访问**:Layer 3 的访问必须留审计日志; - **跨境传输**:把数据发给 third-party SaaS 可观测产品时要审核。 **建议**:把这些当**架构约束**而非"事后补救",从 schema 设计就考虑。 ### 6.3 LLM-as-judge 的陷阱 LLM-as-judge 是评测的常用工具,但有几个**反模式**: | 反模式 | 后果 | |--------|------| | Judge 和被评测用同一个模型 | 系统性偏差,模型偏好自己 | | Judge 模型版本不固定 | 评测结果不可对比 | | Judge prompt 不固定 | 评测结果不可对比 | | 只用 LLM-as-judge | 评测自身不确定,无法定位回归 | | Judge 输出自由文本 | 无法聚合 | **正确做法**: - **Judge 模型与被评测模型不同**(如用 GPT-4 评测 Claude); - **Judge 模型版本固定**(如锁定到具体 snapshot); - **Judge prompt 版本化**(进 Git); - **Judge 输出结构化**(如 `{score: 1-5, reason: str}`); - **Judge 与确定性断言混用**——能确定的用确定的。 ### 6.4 别建 silo:可观测要打通能力栈 可观测系统**最大的失败模式**是建成 silo: - LLM 监控用一个工具; - Tool / MCP 监控用另一个工具; - 业务监控又是另一个; - **没有任何工具能贯穿一次 conversation**。 **正确做法**:所有事件**共享 trace_id**,无论是 LLM call、Skill 激活、MCP 调用,还是业务侧的 user_id、conversation_id。 任何一次查询都能从用户的一句话**贯穿到底层的 token 消耗**——这才叫可观测。 --- ## 七、十大反模式:可观测与评测的常见坑 ### AP1:默认存全部 payload 错误:所有 LLM 输入输出都进数据库。 正确:默认只存 size + hash,按 allowlist 采样存 payload。 **为什么致命**:PII 泄漏 + 合规风险 + 存储爆炸。 ### AP2:错误用自由文本 错误:`error: "Something went wrong"`。 正确:预定义 `error_class` 枚举。 **为什么致命**:无法聚合统计,无法定位。 ### AP3:通过字符串匹配判定 Skill 激活 错误:输出里有"PDF"就算 pdf-skill 激活。 正确:通过 trace 中的 activation event 判定。 **为什么致命**:召回率与精度都不可靠。 ### AP4:用同模型做 judge 错误:Claude 评测 Claude 输出。 正确:Judge 用不同模型,且版本固定。 **为什么致命**:系统性偏差,看不到真实问题。 ### AP5:评测集不分层 错误:1000 个 case 混在一起。 正确:Tier A/B/C/D 分层,对应不同频率与阈值。 **为什么致命**:CI 跑不动 + 阈值不合理 + 无法定位回归。 ### AP6:单次跑 eval 就下结论 错误:跑一次通过就合并。 正确:n_runs ≥ 3 看通过率。 **为什么致命**:LLM 不确定性会让"碰巧通过"看起来像"真通过"。 ### AP7:可观测建成 silo 错误:LLM 用工具 A,Tool 用工具 B,业务用工具 C。 正确:所有事件共享 trace_id,端到端贯穿。 **为什么致命**:无法做根因分析,每次事故都靠人肉对齐。 ### AP8:不锁定 judge / 评测脚本版本 错误:评测脚本随手改。 正确:所有评测组件版本化,进 Git。 **为什么致命**:评测结果不可对比,趋势分析失效。 ### AP9:Replay 时真的发副作用 错误:counter-factual replay 真的调用了"发邮件"工具。 正确:副作用工具 mock 化 / sandbox 化。 **为什么致命**:评测把生产搞坏了。 ### AP10:cost 监控只看月账单 错误:等月底看账单震惊。 正确:event 级 cost,conversation 级聚合,预算告警。 **为什么致命**:成本失控数周才能发现。 --- ## 八、收尾:把"能跑"变成"敢上" 这篇文章拆得很细,但所有内容可以凝练成几条核心判断: **1. AI 可观测不是传统可观测的延伸——它是新基础设施。** 传统三剑客(log / metric / trace)回答 "系统跑没跑";AI 可观测还要回答"做得怎么样"。这是质变。 **2. Trace Schema 是基础设施级决策。** 一旦定下来三个月内无法重构。**事件分层(Conversation / Run / Step / Event)+ 错误枚举 + PII 分层存储**——这三件事必须前置想清楚。 **3. Replay 是 AI 时代的杀手级能力。** 特别是 counter-factual replay——它把"猜测影响"变成"量化影响"。**任何严肃的 AI 团队都该有这个能力**。 **4. Cost / Latency / Quality 必须同时盯。** 任何决策都要看三件一起变了多少。没有同时盯三件的能力,优化就是盲人摸象。 **5. 评测必须分层 + 持续。** Tier A/B/C/D 分层,对应不同频率与阈值。**让线上 trace 持续供血给评测集**——这是 AI 工程的飞轮。 **6. LLM-as-judge 必须谨慎使用。** 不同模型、固定版本、结构化输出、与确定性断言混用——四条都要。 **7. 可观测自己也很贵。** 采样 + TTL 分层 + 预算上限。**不要让监控成本失控,那是另一种事故**。 --- ### 三个可操作的下一步 **如果你还没建 trace 体系**: **第一件事是定 schema**。别先选工具——schema 定错了,换工具也没用。先按 §2.3 画出你的 schema,跑通一个最小闭环,再考虑接 Langfuse / LangSmith / 自建。 **如果你已经有 trace 但没 replay**: 本月内建一个**最小 replay**——能拿一个真实 trace,用同样的 input + tools + model 跑一次。这个能力建起来后,团队的 debug 效率会立刻提升一档。 **如果你已经有 replay 但没持续 eval**: 本季度建一个**最小评测飞轮**——线上采 10 个负反馈 case → 人工标注 → 加入 Tier B → 每周 replay。**这是 AI 团队拉开差距的关键能力**。 --- ## 延伸阅读 / 验证路径 > 提示:AI 可观测工具生态演化极快,以下链接请以**官方域名当前内容**为准。 - OpenTelemetry GenAI 语义约定:`opentelemetry.io`(搜 "GenAI semantic conventions") - LangSmith:`smith.langchain.com` - Langfuse:`langfuse.com` - Anthropic 工程博客(observability / eval 相关):`anthropic.com/engineering` - OpenAI Evals:`github.com/openai/evals` - 社区讨论:r/ClaudeAI、r/LocalLLaMA 搜 "agent observability"、"LLM eval" **Knowledge Boundary**:本文涉及的具体工具与规范都在快速演进期。Schema 字段名、工具能力、最佳实践可能在数月内变化。本文的**设计原则与分层方法**预计相对稳定;具体技术细节请以引用链接的当前版本为准。 --- > **写在最后** > AI 系统的"能跑"和"敢上"之间,隔着一整套可观测与评测基础设施。 > 这套基础设施不性感、不上热搜,但它决定了你的 AI 系统**能不能从 demo 进化成产品**。 > **看见,才能优化;衡量,才能改进**——这是这篇文章想留下的唯一一句话。 --- *如果这篇文章让你重新审视了团队的 AI 可观测实践,欢迎转发给身边那些"用户反馈坏了我也不知道为什么"的工程师。* *这是「AI 能力工程系列」的第四篇。前三篇分别拆了 Skills 规范与构建、MCP server 治理、编排框架选型。四篇配合,构成 AI 工程的完整决策框架——从能力封装、能力暴露、能力编排,到能力的可观测与持续优化。下一篇我们会拆「AI 工程的 CI/CD:从模型发版到 Skill 灰度的完整流水线」,把"敢上"变成"敢改"。*
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号