
Skills 规范、构建与设计模式 —— 从 SKILL.md 到生产落地的完整拆解
--- ## 引言:为什么这一次值得认真对待 每隔几个月,AI 工程圈就会冒出一个"新东西"——新的框架、新的协议、新的概念。大多数最后都被遗忘了,少数沉淀下来变成基础设施。 **Agent Skills 属于后者,但不是因为它"新",而是因为它"小"。** 它的核心规范本质上只有一件事:**用一个叫 `SKILL.md` 的 Markdown 文件,加上一个目录结构,把"AI 该如何完成一类任务"从 prompt 里抽出来,放进文件系统**。 听起来朴素到不像 2025 年的"前沿技术"。但软件工程史上反复出现的规律是——**真正改变格局的,往往是这种"看起来朴素"的小规范**: - HTTP 没什么花哨的,但它定义了 Web; - JSON 比 XML 简陋得多,但它统一了 API; - Markdown 不如 LaTeX 强大,但它统治了文档; - `package.json` 只是个配置文件,但它撑起了整个 npm 生态。 **Skills 想做的是 AI 能力的 `package.json`**。 这篇文章不讲故事,不喊口号,不预测未来。我们只做一件事:**把 Skills 规范、构建方法、设计模式,从协议层到生产落地,一次性拆透**。 读完之后,你应该能回答这些问题: 1. `SKILL.md` 的每个字段为什么这样设计? 2. 渐进披露(Progressive Disclosure)三层加载的工程意义是什么? 3. 怎么从零构建一个生产可用的 Skill?目录怎么分、脚本怎么写、测试怎么做? 4. 现有 Skill 实践中,有哪些反复出现的设计模式?哪些是反模式? 5. 把 Skill 推到生产环境,会遇到哪些工程现实问题? **不绕弯子,直接进入正文。** --- ## 一、规范层:SKILL.md 到底定义了什么 要构建 Skill,先要看懂规范。Anthropic 在 2024 年底公布的 Agent Skills 规范,核心其实只规定了**三件事**: 1. 一个目录的最小布局; 2. 一个 `SKILL.md` 文件的格式; 3. 一套渐进披露的加载机制。 ### 1.1 目录的最小布局 一个 Skill = 一个目录。最小可用形态只需要一个 `SKILL.md`: ``` my-skill/ └── SKILL.md # 唯一必需文件 ``` 完整形态包含四个可选子目录: ``` my-skill/ ├── SKILL.md # 必需 ├── scripts/ # 可执行代码(Python / Bash / Node 等) ├── references/ # 长文档、规范、示例 └── assets/ # 模板、字体、样例文件 ``` **为什么这样设计?** 因为这四个子目录对应了三种不同的"加载时机"——后面讲渐进披露时会回到这一点。 ### 1.2 SKILL.md 的格式 `SKILL.md` 由两部分组成:**YAML frontmatter**(顶部元数据)+ **Markdown 正文**。 最小完整示例: ```markdown --- name: pdf-form-filler description: | Fill interactive PDF forms by mapping a JSON payload to field names. Use when the user provides a PDF file together with structured data that should be injected into form fields. allowed-tools: - Read - Write - Bash --- # PDF Form Filler ## When to use - 用户提供 .pdf 文件 - 用户提供结构化数据(JSON / 表格) - 用户明确要求"填表"、"fill form"、"注入字段" ## Procedure 1. 调用 `scripts/extract_fields.py` 提取表单字段 2. 将 JSON 键映射到字段名(必要时请求用户澄清) 3. 调用 `scripts/fill_form.py --pdf <path> --data <json>` 生成填充版本 4. 输出文件路径并提示用户检查 ## Error Handling - 字段无法映射 → 列出无法映射的字段,请求用户确认 - PDF 受密码保护 → 请求密码或终止 ``` ### 1.3 三个核心字段,每一个都值得拆解 #### `name` —— 全局标识 - 小写 + 连字符; - ≤ 64 字符; - **必须与目录名一致**。 这个字段看起来无聊,但有一个重要约束:**它是 Skill 在 host 内的全局ID**。重名会冲突,host 拒绝加载。这意味着 Skill 一旦发布,改名等于发布新 Skill。 #### `description` —— 召回索引 这是整份规范中**最关键、最容易写坏**的字段。 它不是给人看的文档,而是**给模型看的索引项**。在 Skill 加载阶段,模型扫描所有已安装 Skill 的 `(name, description)`,决定**每一刻要不要激活某个 Skill**。 写得好不好直接决定召回成败: | 写法 | 召回效果 | |------|---------| | `A powerful PDF skill.` | ❌ 模糊,模型不知道何时该用 | | `Handles documents.` | ❌ 范围过宽,会大量误触发 | | `Use whenever user mentions files.` | ❌ 触发条件过泛 | | `Fill PDF forms by mapping JSON to field names. Use when user provides a PDF and structured data.` | ✅ What + When 双句结构 | **规范虽然只要求 ≤ 1024 字符,但有效的 description 几乎都遵循同一种结构**: ``` <WHAT 句>: 动词开头,说明能做什么 <WHEN 句>: "Use when ..." 开头,给出激活信号 ``` 这个双句结构不是规范强制,但它是社区在实践中收敛出来的事实标准。**后面构建实战章节会反复强调这一点**。 #### `allowed-tools` —— 权限闸门 声明这个 Skill 在执行过程中**允许调用哪些工具**。 关键性质:**是强制约束,不是建议**。Host 会拒绝 Skill 调用未声明的工具——这等于给每个 Skill 加了一道权限边界。 举例:一个只读分析 Skill 不应声明 `Write`;一个本地处理 Skill 不应声明任何网络工具。**最小权限原则在这里有具体落点**。 ### 1.4 渐进披露:规范中最重要的设计 如果说 `SKILL.md` 是骨架,**渐进披露(Progressive Disclosure)** 就是这套规范的心脏。 要理解它解决什么问题,先看一个数字: > 一个 Skill 的完整 `SKILL.md` 平均 ~3000 token。如果你装 200 个 Skill 全量加载,就是 **60 万 token——超过任何主流模型的上下文窗口**。 规范的解法是**把加载切成三层**: 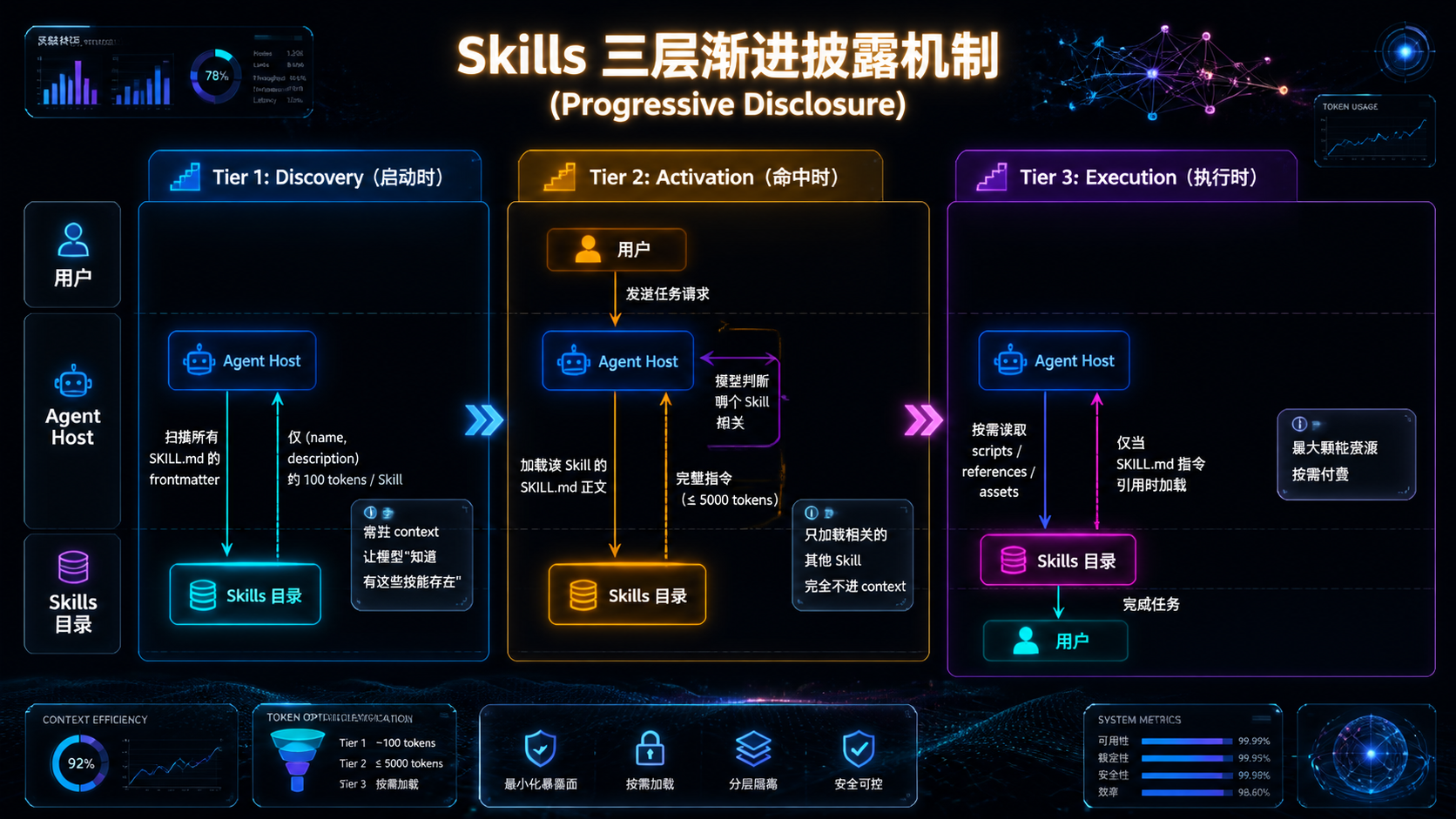 **每一层的具体加载内容**: | Tier | 加载时机 | 加载内容 | 单 Skill 成本 | |------|---------|---------|--------------| | Tier 1 | host 启动 | (name, description) | ~100 tokens | | Tier 2 | 模型决定激活 | SKILL.md 正文 | ~3000 tokens | | Tier 3 | 指令引用资源 | scripts / references / assets | 按需 | **这个分层不是"性能优化",而是"使规范可扩展"**。没有渐进披露,Skill 数量超过 20 个就会撞墙——有了渐进披露,理论上数百个 Skill 共存才成为可能。 **但是,魔法有前提**:Tier 1 召回失败,整套机制崩溃。这就是为什么我们要花那么多篇幅强调 `description` 的写法——**它是渐进披露能否成立的命门**。 ### 1.5 SKILL.md 同时是四种东西 把规范层的理解凝练一下,`SKILL.md` 这个文件,**同时承担四种身份**: | 身份 | 服务对象 | 关键字段 | |------|---------|---------| | **召回索引项** | LLM(Tier 1 阶段) | `description` | | **操作指令书** | LLM(Tier 2 阶段) | Markdown 正文 | | **权限声明** | Agent Host | `allowed-tools` | | **工程资产** | 工程师 / Git | `name` + 自定义 metadata | **理解了这四重身份,你才算读懂了 SKILL.md。** 接下来进入构建层——**怎么从零写一个能上生产的 Skill**。 --- ## 二、构建层:从零构建一个生产可用的 Skill 光看规范不够。我们走一遍完整工程流程,目标场景:**"Excel 报表自动化生成"** Skill。 为什么选这个?因为它**同时涉及**结构化数据、模板、确定性逻辑、用户意图判断——是 Skill 的典型场景。 ### 2.1 第一步:先写 description,再写其他 **这是最容易被跳过、但最不应该跳过的一步**。 不要急着开 IDE 写代码。先打开一个空文件,**只写 description**,反复推敲。 第一稿(典型新手版本): ```yaml description: | Generate Excel reports. Use when user asks to make a report. ``` **为什么差?** - "reports" 范围太宽,会被所有"报表"请求误触发; - "asks to make a report" 没有具体输入信号; - 模型几乎没有线索决定何时激活。 第二稿(修订后): ```yaml description: | Generate multi-sheet Excel reports from structured data (CSV, JSON, or database query results). Supports formula injection, conditional formatting, and chart embedding. Use when the user provides tabular data AND explicitly requests an .xlsx output, or asks for "Excel report", "spreadsheet", or "财务报表 / 月报 / 数据汇总" in Chinese. ``` **为什么好?** - **WHAT**:清晰说明能做什么(多 sheet、公式、格式、图表); - **WHEN**:给出激活的"AND"条件(有数据 + 要 .xlsx); - **关键词**:列出英文+中文的触发词,避免语言切换失效; - **隐性边界**:通过"explicitly requests an .xlsx output" 排除了"导出 CSV"等相似但不同的请求。 **写 description 的工程纪律**: 1. 永远用双句结构(What + When); 2. 永远包含至少 2–3 个具体触发词; 3. 永远显性排除最容易混淆的相邻场景; 4. 中英文场景,永远双语关键词。 ### 2.2 第二步:设计目录与切分边界 不要直接开始写代码。先想清楚一个问题——**哪些是脚本、哪些是 Markdown 指令?** 切分原则: | 应该是代码(`scripts/`) | 应该是 Markdown 指令(`SKILL.md`) | |----------------------|--------------------------------| | 读写 Excel 文件 | 何时使用哪个模板 | | 公式注入与计算 | 如何与用户确认歧义 | | 数据校验 | 异常情况如何回退 | | 图表渲染 | 如何决定 sheet 结构 | | 任何确定性算法 | 任何涉及判断与对话的部分 | **核心铁律**:**不要让 LLM 重新发明 `openpyxl.load_workbook`**。能写代码的地方就写代码,模型负责"何时调",代码负责"怎么做"。 最终目录结构: ``` excel-report-builder/ ├── SKILL.md ├── scripts/ │ ├── validate_data.py # 数据形状校验 │ ├── build_workbook.py # 接收配置 JSON → 生成 .xlsx │ ├── inject_charts.py # 图表注入 │ └── apply_style.py # 公司样式应用 ├── assets/ │ └── templates/ │ ├── monthly.xlsx # 月报模板 │ ├── financial.xlsx # 财报模板 │ └── blank.xlsx # 空白模板 ├── references/ │ └── style-guide.md # 公司报表风格规范(≤ 2000 字) ├── tests/ │ ├── positive/ # 应激活的 case │ ├── negative/ # 不应激活的 case │ └── fixtures/ # 共享测试数据 └── CHANGELOG.md ``` ### 2.3 第三步:写 SKILL.md 正文(用强结构) 正文用**强结构 H2 章节**——这不是审美问题,而是为了**让模型扫描时不迷路**。 推荐的章节骨架: ```markdown # Excel Report Builder ## When to use (明确触发条件 + 明确"不要使用"条件) ## When NOT to use (列出最容易混淆的相邻场景) ## Inputs (期望的输入形式与必需资源) ## Procedure (编号步骤,每步引用具体脚本或资源) ## Outputs (交付物的格式、命名、位置约定) ## Error Handling (已知失败模式与回退策略) ## Examples (至少 1 个完整 input → output 范例) ``` 实际填充后的样子: ```markdown # Excel Report Builder ## When to use - 用户提供结构化数据(JSON / CSV / SQL 结果) - 用户明确要 .xlsx 输出 - 关键词命中:"Excel 报表"、"月报"、"财报"、"spreadsheet" ## When NOT to use - 用户只要纯 CSV 导出 → 使用通用导出工具 - 用户要 PDF 报表 → 使用 pdf-report-builder skill - 用户只是聊到 Excel,没有具体生成意图 ## Inputs - 数据格式:JSON / CSV 文件路径,或对话中的结构化文本 - 模板偏好:用户可指定 monthly / financial / blank - 风格偏好:默认遵循 references/style-guide.md ## Procedure 1. 调用 `scripts/validate_data.py --input <path>` 校验数据形状。 - 若失败:报告缺哪一列,请求用户确认。 2. 根据用户意图选模板: - 月度运营数据 → `assets/templates/monthly.xlsx` - 财务数据 → `assets/templates/financial.xlsx` - 其他 → `assets/templates/blank.xlsx` 3. 调用 `scripts/build_workbook.py --template <path> --data <json>`。 4. 若用户要求图表:调用 `scripts/inject_charts.py`。 5. 调用 `scripts/apply_style.py` 应用公司样式。 6. 输出文件路径 + 内容摘要给用户。 ## Error Handling - 数据缺列 → 报告缺哪一列,请求用户确认 - 模板加载失败 → 回退到 blank.xlsx,并告知用户 - 公式语法错误 → 跳过该列公式,记录 warning,继续生成 - 数据量 > 10 万行 → 提示用户考虑数据库导出方案 ## Examples ### Example 1: 月报 Input: 用户上传 `oct-ops.json`,说"生成 10 月运营月报" Steps: validate → 选 monthly 模板 → build → style → 输出 Output: `outputs/oct-ops-monthly.xlsx` ``` **这里有几个工程细节值得注意**: 1. **每个 Procedure 步骤都引用具体脚本**——这是渐进披露 Tier 3 的"触发器"。 2. **Error Handling 不是"模型自由发挥"**——明确写出哪种错误怎么处理。 3. **Examples 不是装饰**——它给模型提供了 in-context learning 的样本。 ### 2.4 第四步:脚本的工程纪律 `scripts/` 里的代码也有几条不能违反的纪律: #### 1. 接口要稳定 脚本暴露的命令行接口(CLI)应当**像公共 API 一样稳定**。一旦 SKILL.md 引用了 `--template <path>`,就不要随意改成 `--tpl <path>`——这会让所有引用它的指令失效。 #### 2. 错误码要明确 不要让脚本只用 `exit(1)` 草草报错。区分错误类型: ```python EXIT_OK = 0 EXIT_VALIDATION_FAILED = 10 EXIT_TEMPLATE_NOT_FOUND = 20 EXIT_DATA_TOO_LARGE = 30 EXIT_UNKNOWN = 99 ``` SKILL.md 的 Error Handling 章节就可以基于这些错误码精准回退。 #### 3. 输出要结构化 脚本输出应优先用 JSON,而不是自由文本: ```json { "status": "success", "output_path": "outputs/oct-monthly.xlsx", "warnings": ["Column 'revenue_q4' contained 3 null values"], "stats": {"rows": 1284, "sheets": 4} } ``` 这让模型更容易解析结果,也让自动化测试更稳定。 #### 4. 不要硬编码任何凭据 `scripts/` 是会被加载、被审计、被分享的——**任何密钥/Token 出现在脚本里都是事故**。需要凭据走环境变量或 vault,绝不写进文件。 ### 2.5 第五步:测试是必修,不是选修 这一条值得单独成段:**没有 `tests/` 的 Skill,不是工程资产,是技术债**。 最简测试格式(YAML): 正例: ```yaml id: case-001 description: 用户提供 JSON + 要求月报 input: user_message: "把这份数据生成 Excel 月报" attachments: - path: fixtures/oct-data.json expected: activated: true outputs: - type: file pattern: "*.xlsx" assertions: - kind: file_exists path: outputs/oct-data-monthly.xlsx - kind: workbook_sheet_count min: 2 ``` 反例(同样重要): ```yaml id: case-101 description: 用户只是聊到 Excel input: user_message: "我以前用 Excel 写过很复杂的公式,吐了" expected: activated: false ``` **为什么必须有反例?** - 只有正例 → 你只能确认"该激活时激活"; - 加上反例 → 才能确认"不该激活时不激活"; - 误激活的破坏性 ≥ 漏激活——你不希望用户随便提一句"Excel"就跑了一个生成流程。 **测试的最低要求**: | Skill 阶段 | 最低测试要求 | |-----------|-------------| | experimental | ≥ 3 条正例 | | beta | + ≥ 3 条反例 + 激活率 telemetry | | stable | + 误激活/漏激活率基线 + 多次重复(n-runs) | | deprecated | 保留测试用于回归 | ### 2.6 第六步:版本与所有权 Skill 是工程资产,必须有清晰的版本与所有权。在 frontmatter 加上团队扩展字段: ```yaml metadata: version: 0.1.0 # semver stability: experimental # experimental | beta | stable | deprecated owner: data-platform@team created: 2026-05-12 last-reviewed: 2026-05-12 tags: [excel, report, automation] ``` **stability 字段是被严重低估的设计**——它告诉团队"这个 Skill 还在试,别在重要场景用"。当 Skill 数量增长后,没有这个字段,治理几乎不可能。 至此,**一个 Skill 从零到生产可用的全流程**走完了。 接下来进入设计模式层——**当你写第 10 个、第 50 个 Skill 时,你会发现自己在反复重复某些结构**。 --- ## 三、设计模式:六类反复出现的 Skill 结构 把现有公开 Skill 仓库、社区讨论和实战经验综合起来,可以归纳出**六类反复出现的设计模式**。这些模式有点像 Skill 工程的"设计模式"雏形——理解它们,能让你在写新 Skill 时少走 80% 的弯路。 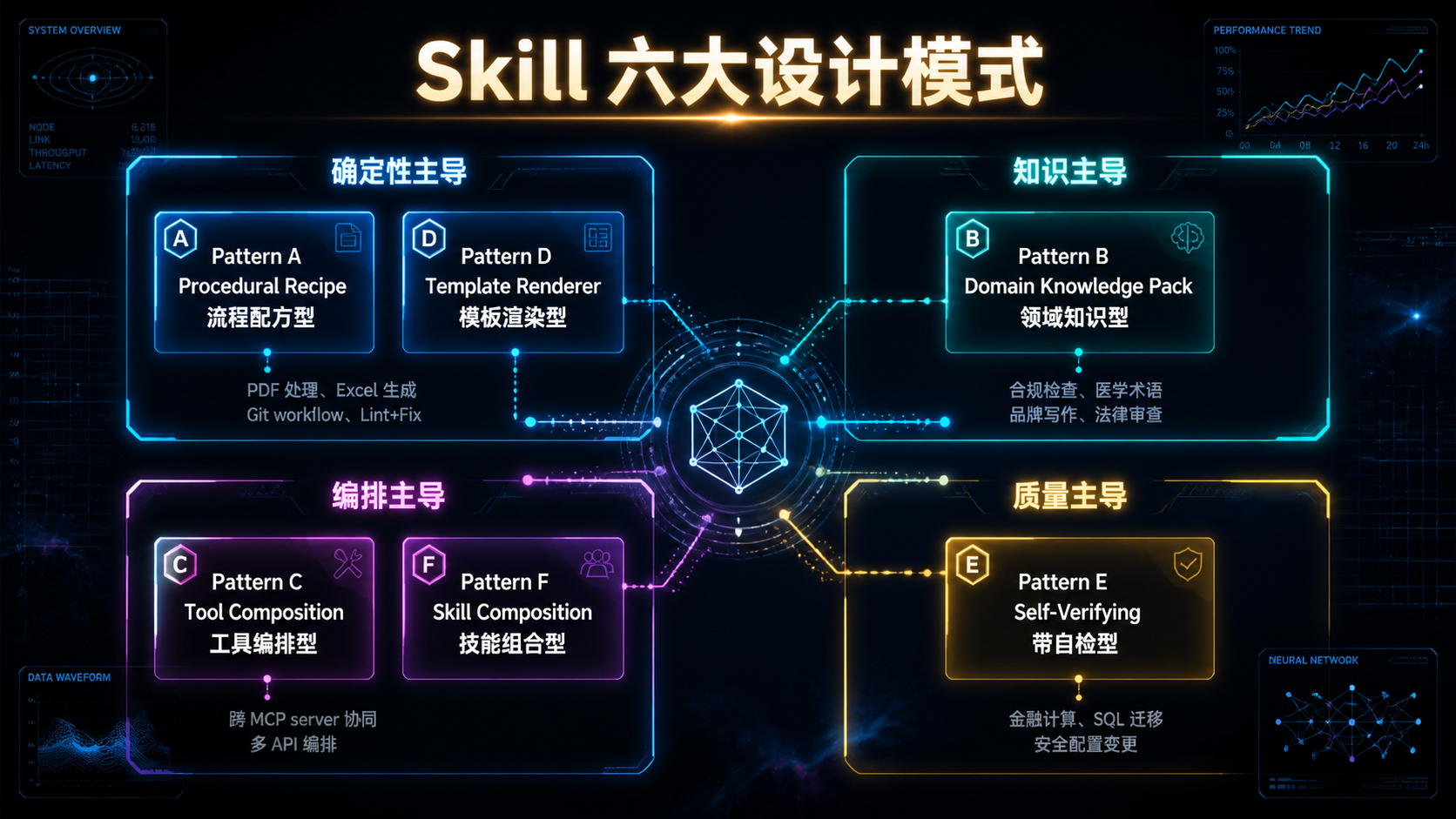 ### 3.1 Pattern A — Procedural Recipe(流程配方型) **适用场景**:步骤明确、决策点清晰、可被脚本化的任务。 **典型例子**:PDF 处理、Excel 生成、Git 操作、代码 lint+fix。前面拆解的 Excel Skill 就是这个模式的典型。 **结构特征**: - `SKILL.md` 写**步骤 + 决策点**; - `scripts/` 放**确定性代码**; - `assets/` 放模板与样例。 **核心反模式**:把所有逻辑都写进 Markdown 让 LLM 自由发挥。**确定性逻辑应该是代码**——不要让模型重新发明 `pandas.read_excel`。 **判断标准**:如果你能给一个实习生写一份"操作手册",那它就适合 Recipe 模式。 ### 3.2 Pattern B — Domain Knowledge Pack(领域知识型) **适用场景**:知识密集、流程不可写死的领域。 **典型例子**:法律条款审查、医学术语翻译、品牌文案规范、ISO 标准合规检查。 **结构特征**: - `SKILL.md` 给**触发条件 + 核心准则 + 决策树**; - `references/` 放**完整规范文档**; - 必要时配 `assets/` 给样例。 **关键技巧**:**用 Tier 3 控制成本**。不要把整本 ISO 标准塞进 SKILL.md 正文——那会被 Tier 2 全量加载。把规范放 `references/`,SKILL.md 里只写"何时去读哪一节"。 **经典反模式**:把 RAG 知识库的内容塞进 `references/`。**事实查询走 RAG / MCP retrieval server,Skill 描述的是 how,不是 what**。 ### 3.3 Pattern C — Tool Composition(工具编排型) **适用场景**:需要多个工具 / MCP server / API 协同的任务。 **典型例子**:从 Slack 拉消息 → 调用 GitHub API 创建 issue → 写回数据库 → 通知相关人。 **结构特征**: - `SKILL.md` 描述**编排逻辑**(先 A,再 B,条件分支去 C); - `allowed-tools` 显式声明所有依赖; - 不一定需要 `scripts/`——主要靠工具调用串起来。 **与 MCP 的关系**:这是 Skill 与 MCP 的**强耦合点**。Skill 可以"约束"调用哪些 MCP tool,但 MCP server 本身的注册仍在 agent host 配置层。**Skill 不能"安装"MCP server,只能"使用"已注册的 MCP server**。 ### 3.4 Pattern D — Template Renderer(模板渲染型) **适用场景**:生成结构化输出文档。 **典型例子**:根据数据生成季度报告 PPT、根据描述生成简历 Word、根据 issue 生成 release notes、根据日程生成会议纪要。 **结构特征**: - `SKILL.md` 描述**何时使用 + 模板选择规则**; - `assets/` 放**模板文件**(.docx / .pptx / .html / .tex); - `scripts/` 做**模板渲染**(jinja / python-pptx / docxtpl)。 **为什么这个模式特别重要**:它把"长尾输出格式"从**调 prompt** 变成了**做工程**。一份 PPT 模板的好坏不靠 prompt 调参,而靠把 .pptx 文件做好——**从玄学回到工程**。 ### 3.5 Pattern E — Self-Verifying Skill(带自检型) **适用场景**:高风险、错误代价大的任务。 **典型例子**:金融计算、SQL 迁移、安全配置变更、代码重构、密钥轮换。 **结构特征**: - 步骤中**强制**包含 verification step; - `scripts/` 包含校验脚本(如 dry-run / diff / 单元测试触发); - 验证失败时**显式回退或请求人工确认**。 **典型 SKILL.md 片段**: ```markdown ## Procedure 1. 生成迁移 SQL(不执行) 2. **必须**运行 `scripts/dry_run.py` 在 staging 数据库上验证 3. 若 dry-run 通过:呈现 diff 给用户,请求确认 4. 用户确认后执行 5. 执行后再次运行 `scripts/verify_schema.py` 验证结果 6. 任何步骤失败 → 立即回滚 + 通知 owner ``` **这是当前社区还在快速演化的模式**——把"评估"前置进 Skill 本身。未来一年这个模式可能形成更标准的子规范。 ### 3.6 Pattern F — Skill Composition(技能组合型) **适用场景**:复杂任务由多个简单 Skill 拼装。 **典型例子**:写一份产品 launch 报告 = 数据 Skill 拉数据 + Excel Skill 做图 + Slides Skill 生成 PPT。 **结构特征**: - 在 SKILL.md 的描述里**显式说明**"先调用 X-skill,再调用 Y-skill"; - 组合 Skill 自己应当**很薄**——主要做编排,不做实际工作。 **陷阱(必须知道)**: - 当前规范**没有正式的 skill-to-skill dependency 字段**; - 组合靠 LLM 推断,**容易脆**; - 一个被依赖的 Skill 改了 description,可能让组合 Skill 突然不工作。 **实践建议**: 1. 优先**让一个 Skill 直接调用工具**完成任务; 2. 只有任务真的可以正交切分时才用 Composition; 3. 严格控制组合深度,**不超过两层**; 4. 在依赖的子 Skill 上锁定版本(在 metadata 里记录)。 ### 3.7 模式选择速查表 | 任务特征 | 推荐模式 | |---------|---------| | 步骤清晰、可脚本化 | A. Procedural Recipe | | 知识密集、决策树为主 | B. Domain Knowledge Pack | | 需要多个外部能力 | C. Tool Composition | | 输出是结构化文档 | D. Template Renderer | | 错误代价大 | E. Self-Verifying | | 子任务正交、可拆 | F. Skill Composition | **这些模式不互斥**——一个真实 Skill 可能是 A + E 的组合(流程配方 + 带自检),或 B + D(领域知识 + 模板渲染)。**模式是抽象,工程是组合**。 --- ## 四、Skills 在能力栈中的位置:与 MCP、Tool Calling 的关系 构建 Skill 时绕不开一个问题——**它和 MCP、Tool Calling 是什么关系?** 简短答案:**不是替代,是分层。** ### 4.1 三层架构 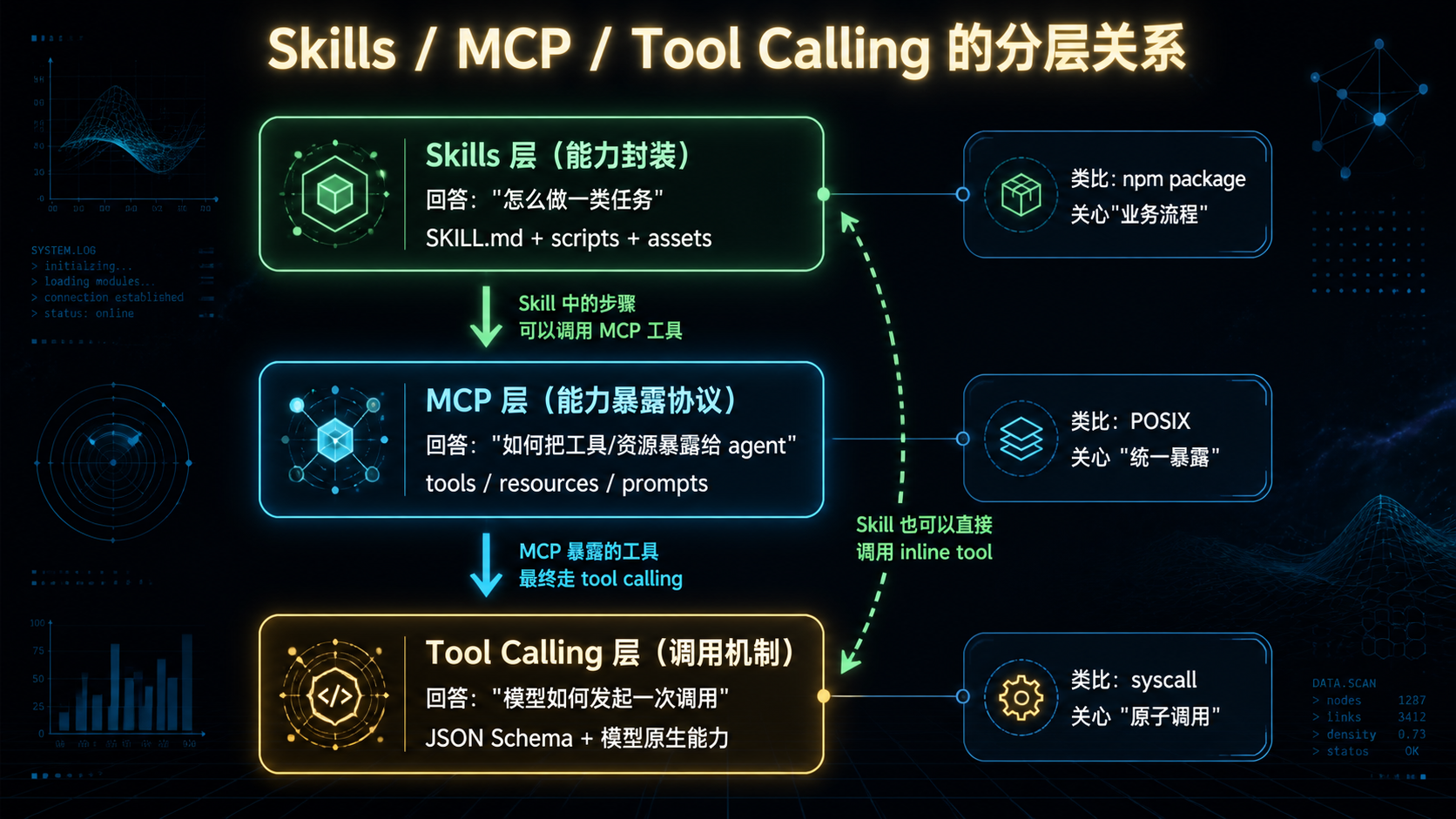 类比来理解: - **Tool Calling ≈ syscall**——底层调用机制,逃不掉; - **MCP ≈ POSIX**——统一协议,让能力可以跨进程暴露; - **Skill ≈ npm package**——业务封装,把流程性知识打包分发。 ### 4.2 三者的真实分工 | 维度 | Tool Calling | MCP | Skill | |------|--------------|-----|-------| | 解决的问题 | 如何调一个函数 | 如何跨进程暴露能力 | 如何打包一类流程 | | 抽象层 | 调用机制 | 协议 | 封装 | | 颗粒度 | 单个函数 | 一组相关工具 | 一类任务的完整流程 | | 是否包含"流程知识" | 否 | 否 | 是 | | 是否可独立版本化 | 否 | 是 | 是 | | 是否可文件系统管理 | 否 | 部分 | 是 | **关键认知**: - 写 Skill 不能跳过 Tool Calling——**Skill 步骤里调脚本、调 MCP,都走 tool calling**; - Skill 经常调用 MCP tool——比如 `db-migration-skill` 的 SKILL.md 会写"用 postgres MCP server 执行 schema diff"; - **三者正交**,组合使用是常态。 ### 4.3 真实工程组合参考 | 场景 | Skill | MCP | Tool Calling | |------|-------|-----|--------------| | 单 agent 内部小工具 | ❌ | ❌ | ✅ inline | | 跨 IDE 数据库查询 | ❌ | ✅ DB server | ✅ | | PDF 处理工作流 | ✅ pdf-skill | ❌ | ✅ Bash/Python | | 企业合规审查 | ✅ compliance-skill | ✅ policy-RAG-server | ✅ | | Coding agent(如 Claude Code) | ✅ test-gen, refactor 等 | ✅ filesystem, git, github | ✅ | **核心规律**:Skill 描述流程,MCP 提供能力,Tool Calling 完成调用。**三者协作,各司其职**。 --- ## 五、生产落地:构建之后还要做什么 把 Skill 写完不是终点。把它真的跑到生产,会撞到一堆"教程不告诉你"的问题。这一节专门讲这些**让人难受但必须解决的工程现实**。 ### 5.1 可观测性:你能回答"上周哪些 Skill 被激活了几次"吗? 如果不能回答,**你的 Skill 体系就在裸奔**。 最低必发事件清单: | 事件 | 触发时机 | |------|---------| | `skill.tier1.loaded` | metadata 进入 context | | `skill.tier2.activated` | 模型决定使用该 skill | | `skill.tier3.resource_read` | 加载 scripts / references / assets | | `skill.step.tool_call` | Skill 步骤中触发 tool call | | `skill.completed` | 流程结束(success / failure / aborted) | 最低 dashboard 必须能看到: - **Top-N 激活 Skill**:哪些被频繁用; - **每个 Skill 的成功率与错误分类**:哪些不稳; - **"30 天未激活"列表**:候选下线; - **"高激活但低成功率"列表**:优先修复。 **没有这些数据,你不知道哪些 Skill 该砍、该改、该升级**——只能凭感觉。 ### 5.2 评测:CI 跑不起来的 Skill 不是工程资产 Skill 改动必须有 CI 回归。最小 CI 工作流: ```yaml name: skill-eval on: pull_request: paths: - "skills/**" jobs: eval: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Detect changed skills id: changed run: ./scripts/changed-skills.sh - name: Run skill eval run: | skill-eval suite \ --skills "${{ steps.changed.outputs.skills }}" \ --n-runs 3 \ --report report.json - name: Enforce stability gates run: skill-eval gate --report report.json --policy .skill-policy.yaml ``` **关键技术细节**: 1. **激活判定靠 trace**——通过 trace 中是否出现 Tier 2 加载事件来判定,**不靠输出字符串匹配**。后者容易被措辞变化干扰。 2. **必须多次重复**——LLM 不确定性意味着单次跑测试不可靠。harness 必须支持 `--n-runs`,按通过率而非单次结果判定。 3. **PR 只跑变更**,nightly 跑全量——成本必须可控。 4. **录制 + 重放**减少 API 成本,但**至少每周一次真实重跑**,防止录制漂移。 ### 5.3 安全:第三方 Skill 是新的攻击面 Skill 的一个隐藏特性是——**它包含可执行脚本,会被自动加载并运行**。 这意味着第三方 Skill 必须像 npm 依赖一样审计: - 谁写的?签名了吗? - 脚本里有什么?是否读敏感目录? - `allowed-tools` 声明了什么?是否过度授权? - 是否会向外部网络发请求? **目前生态层面的治理几乎是空白**: - 没有 Skill marketplace 的签名机制; - 没有 supply chain SBOM; - 没有强制沙箱执行规范; - 没有 CVE 报告通道。 **短期内的应对**: | 风险来源 | 应对策略 | |---------|---------| | 第三方 Skill | 仅装 allowlist;强制 code review | | 脚本执行 | 容器化 / seccomp 沙箱 | | 凭据泄漏 | **绝不**写进 SKILL.md / 脚本 | | 过度权限 | `allowed-tools` 最小化原则 | | 误执行 | 高风险 Skill 增加 user confirmation | ### 5.4 成本:Tier 1 是隐藏的"税" 最容易被忽视的成本——**Tier 1 是常驻的**。 每个 Skill ~100 token,装 500 个 Skill 就是 **~50K token 常驻**——直接蚕食有效上下文窗口。 应对策略: 1. 设定 Skill 数量上限(按 host context window 反推); 2. 定期审计未激活 Skill; 3. 通过 `stability: deprecated` 标记并自动下线; 4. 极端场景下,可以考虑**向量检索预过滤 Tier 1**(仍在探索阶段)。 ### 5.5 版本管理:semver 不是可选项 Skill 是工程资产。每一次修改: - 必须 bump 版本号(建议 semver); - 必须更新 CHANGELOG; - 必须走 PR + review(stable 级别强制); - 必须跑测试(CI gate)。 **"我先改一下试试"会毁掉整个 Skill 体系**——尤其是当其他 Skill / 系统已经依赖了某个 description 触发关键词时。 ### 5.6 生命周期:Skill 不是"写完就忘" 每个 Skill 都应该有清晰的生命周期: 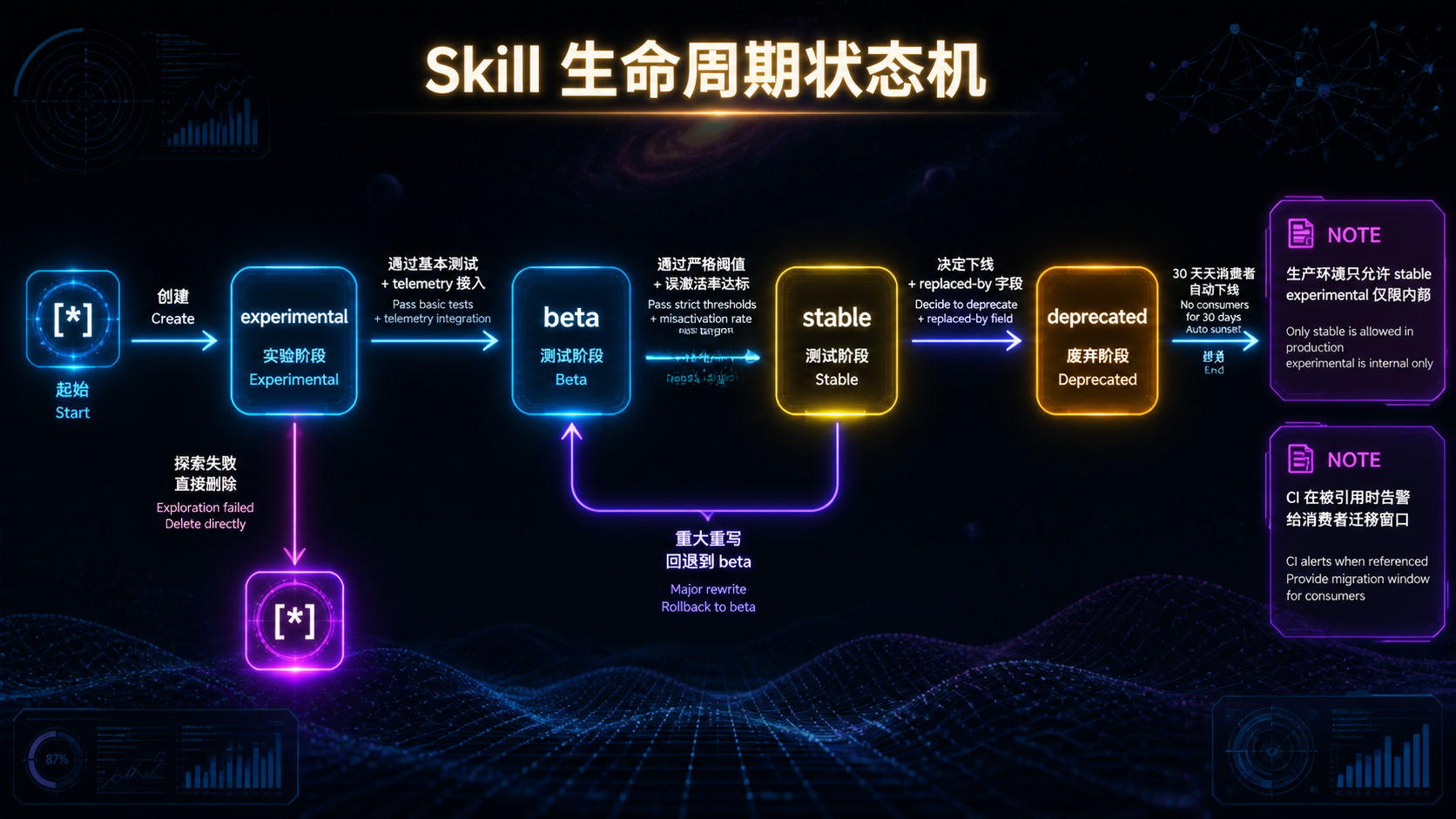 每个状态对应不同的约束(测试要求、审计周期、变更门槛)。**没有生命周期管理,Skill 数量永远只增不减——这是失控的开始**。 --- ## 六、十大反模式:那些一定会踩的坑 写到这里,正向的构建路径已经讲完。最后用一组**反模式清单**收尾——这些都是在工程实战中反复出现的错误,**记住它们,比记住设计模式更重要**。 ### AP1:description 写成营销文案 ❌ `A powerful and intelligent helper skill.` ✅ 双句结构,明确 What + When。 **为什么致命**:Tier 1 召回会失效,Skill 等于不存在。 ### AP2:用自然语言描述确定性逻辑 ❌ 在 SKILL.md 里写"然后把数据按列汇总求和……" ✅ 写成 `scripts/aggregate.py`,让代码做代码的事。 **为什么致命**:模型会重新发明逻辑,结果不稳定且不可测试。 ### AP3:把 RAG 知识库塞进 references/ ❌ 把公司知识库的 5 万篇文章放进 `references/`。 ✅ 事实性知识走 RAG / MCP retrieval server。 **为什么致命**:Skill 描述的是 how,不是 what。塞进去会让 Tier 3 加载爆炸。 ### AP4:把密钥写进 SKILL.md 或脚本 ❌ 在 SKILL.md / scripts 里写 `API_KEY: sk-xxx`。 ✅ 走环境变量 / MCP server 自管 / OS keychain。 **为什么致命**:SKILL.md 会被加载进 context,等价于打印到日志。 ### AP5:声明的工具与实际使用不符 ❌ SKILL.md 说"调用 GitHub API",但 `allowed-tools` 没声明。 ✅ CI 强制校验声明一致性。 **为什么致命**:要么运行时失败,要么权限边界形同虚设。 ### AP6:Skill 之间循环依赖 ❌ A 调 B,B 调 C,C 又调 A。 ✅ 保持原子、单向、组合深度 ≤ 2。 **为什么致命**:组合靠 LLM 推断,循环依赖直接死循环。 ### AP7:单次跑测试就下结论 ❌ `skill-eval run case-001` 通过了,合并。 ✅ `--n-runs 5` 看通过率。 **为什么致命**:LLM 不确定性会让"碰巧通过"看起来像"真通过"。 ### AP8:把超长结果原样塞进 context ❌ MCP tool 返回 10MB JSON,全塞进模型。 ✅ host 端截断,提供 resource ID 让模型按需读取。 **为什么致命**:context 爆炸 + 后续推理质量崩塌。 ### AP9:所有能力一律 MCP 化 ❌ 把单 agent 内部的一次性函数包成 MCP server。 ✅ 单 agent 私有用 inline tool,跨 agent 复用才 MCP 化。 **为什么致命**:过度工程化,没享受收益先付出成本。 ### AP10:跳过基础建设直奔 marketplace ❌ 还没建评测体系、没有 telemetry 就先搞 Skill 分享平台。 ✅ 先 telemetry → 再评测 → 再治理 → 最后 marketplace。 **为什么致命**:治理债务前移,规模化后无法挽回。 --- ## 七、收尾:把 Skill 当工程,不当 demo 这篇文章拆得很细,但所有内容可以凝练成几条核心判断: **1. Skills 的本质是一个规范,不是一个框架。** 规范的生命力远长于框架。`SKILL.md` 这种"一个文件 + 一个目录"的极简设计,比任何花哨的封装都更耐用。 **2. Skills 解决的核心问题是"程序性知识的工程化"。** 我们终于可以把"模型该怎么做某类任务"从 prompt 里抽出来,放进 Git、跑 CI、做 review、版本化。**这是工程化的拐点,不是花哨的概念**。 **3. 渐进披露是规范中最重要的设计。** 没有它,Skills 撑不过 20 个的规模。有了它,数百个 Skill 才有共存的可能。但它的前提是 `description` 写得够好——**这是工程纪律,不是文采**。 **4. Skill、MCP、Tool Calling 是分层的,不是替代的。** 三者协作是常态。"Skills 取代 MCP"、"MCP 取代 Tool Calling"这类叙事都是误读。 **5. 六类设计模式是抽象,工程是组合。** 真实 Skill 往往跨模式组合(A + E、B + D 等)。先记模式,再灵活组合。 **6. 反模式比模式更重要。** 十条反模式里任意踩中两条,Skill 体系都会迅速变成技术债。**先记反模式,再学模式**。 **7. 把 Skill 推到生产,需要 telemetry、评测、安全、版本、生命周期五件套**。 缺一件都会让 Skill 从工程资产退化成技术债。 --- ### 三个可操作的下一步 **如果你是工程师**: 本周把你最近写的最长那段 system prompt 拿出来,看看里面有多少内容**本质上是程序性知识**——能不能抽成一个 Skill?哪怕只抽出一个,你都会瞬间理解 Skills 的价值。 **如果你是技术负责人**: 本月评估团队当前 agent 项目的能力封装现状。**还在用 prompt 堆叠吗?是时候规划迁移路径**。顺序:先 telemetry → 再评测 → 再 Skill 化 → 再治理。 **如果你正在写第一个 Skill**: 不要急。先写 `description`,写到自己满意为止,再开 IDE。**description 是 Skill 的灵魂**——它决定召回、决定边界、决定能否被发现。**前面一切讲解都为了这一点**。 --- ## 📚 延伸阅读 / 验证路径 > ⚠️ AI 领域演化极快,以下链接请以**官方域名当前内容**为准,不要从二手博客转载。 - **Anthropic Skills 官方仓库**:`github.com/anthropics/skills` - **Agent Skills 规范站点**:`agentskills.io/specification` - **Anthropic 工程博客**:`anthropic.com/engineering`(搜 "Agent Skills"、"Building Effective Agents") - **MCP 规范**:`modelcontextprotocol.io` - **MCP 官方 server 列表**:`github.com/modelcontextprotocol/servers` - **社区讨论**:r/ClaudeAI、r/LocalLLaMA 搜 "SKILL.md"、"MCP vs Skills" **Knowledge Boundary**:本文涉及的规范、字段、host 支持矩阵都处于活跃演化期(2024—2026)。具体字段名、最佳实践可能在数月内变化。本文的**判断与设计原则**预计相对稳定;具体技术细节请以引用链接的当前版本为准。 --- > **写在最后** > Skills 不会让 AI 一夜变强,但它会让 AI 工程从"调玄学"回到"做工程"。 > 把 Skill 当工程,不当 demo——这是这篇文章想留下的唯一一句话。 --- *如果这篇文章帮你重新审视了手上的 AI 项目,欢迎转发给身边正在踩 prompt 堆叠坑的朋友。* *下一篇我们会拆「MCP Server 治理实战:从健康检查到沙箱执行」——配合 Skills 一起,构成 AI 能力工程的完整工具箱。*
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号