
MCP Server 治理实战:从健康检查到沙箱执行
## 引言:被低估的"AI 微服务运维" 过去一年,Model Context Protocol(MCP)从 Anthropic 内部协议,变成跨厂商的事实标准。Cursor、Cline、Continue、Zed、VS Code、Claude Code 全部接入,社区贡献的 MCP server 从几十个涨到几百个。 但**热闹是一面,地雷是另一面**。 当你团队开始在生产环境跑 MCP server,会陆续发现这些问题: - 某个 server 进程崩了,agent 看到的是一段莫名其妙的连接错误; - 某个第三方 server 在后台静默调外网,没人知道它在传什么; - 凭据写在 `.env` 文件里,被新人 push 到 GitHub,半小时后被扫到; - 同一个 server 被五个 agent 共用,没人知道谁该负责升级; - server 升了一个版本,下游三个 agent 全挂,回滚的时候才发现没锁版本。 **这些不是 MCP 协议的问题,是治理的问题。** 如果你把 MCP server 当成"一个工具调用"——那它就是个 demo。 如果你把 MCP server 当成"一个微服务"——你就要面对所有微服务运维该有的问题:分类、注册、健康、凭据、隔离、降级、可观测、生命周期。 这篇文章不讲 MCP 是什么(请直接看 modelcontextprotocol.io)。我们只讲一件事:**一旦 MCP server 进了生产,治理要怎么做**。 读完之后,你应该能回答: 1. MCP server 该不该分类?怎么分? 2. 一个内部 Registry 要包含哪些字段?为什么这些字段不能少? 3. 健康检查怎么做?stdio 和 HTTP 形态分别怎么处理? 4. 凭据放哪里?六条强制规则各对应什么风险? 5. 沙箱有几档?什么情况下必须用 container? 6. 故障来了怎么降级?错误信息要不要丢给模型? 7. 生命周期怎么管?什么 server 该被 retire? **不绕弯子,直接进入正文。** --- ## 一、为什么 MCP server 需要"治理",而不是只"接入" 先校准一个被反复忽略的事实:**MCP server 不是函数调用,是独立进程**。 这个差异看起来很小,工程意义却很大。 ### 1.1 MCP server 与 Inline Tool 的本质差异 | 维度 | Inline Tool | MCP Server | |------|-------------|-----------| | 部署形态 | 同进程函数 | 独立进程(stdio / HTTP / SSE) | | 延迟 | 微秒级 | 毫秒级(stdio 1-10ms,HTTP 更高) | | 故障域 | 跟 agent 同生死 | 进程独立,可崩可重启 | | 凭据 | 走 agent 进程 | server 自己管 | | 跨语言 | 受限于 host 语言 | 任何语言 | | 跨 agent 复用 | 不能 | 可以 | | 版本独立性 | 跟 agent 一起发版 | 独立发版 | 注意最后五行——**这五件事每一件都对应着治理工作量**。"独立进程"带来的好处必然伴随着"独立运维"的成本。 ### 1.2 治理的本质:把"工具"当"微服务"管 如果一个 MCP server 只被一个 agent 用、只在本地跑、只调一个内部函数——它确实不需要治理。 但只要它跨越以下任意一条边界,治理就成了刚需: - **跨进程**:需要健康检查、超时、重试; - **跨团队**:需要明确所有权与版本承诺; - **跨网络**:需要凭据管理与流量审计; - **跨人**:需要 Registry,让所有人知道"我们到底在用哪些 server"; - **跨可信边界**:需要沙箱与权限隔离。 **MCP server 的治理本质,是"AI 时代的微服务治理"**。所有传统微服务踩过的坑,MCP server 一个不落地都会踩——只是踩坑的人换成了 AI 工程师。 ### 1.3 一张图看清治理的六件套 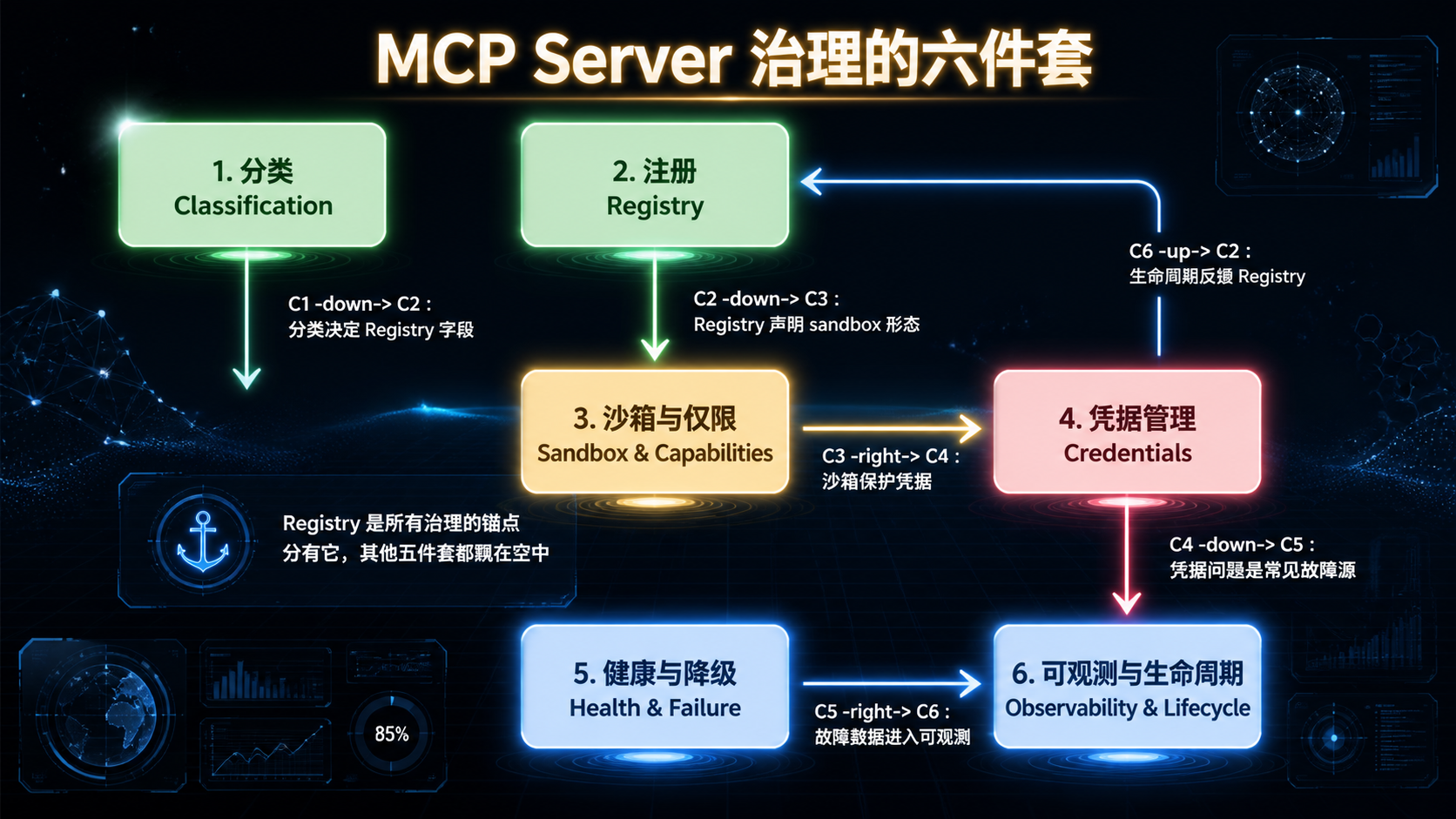 接下来六章,每一章对应一件套。**顺序很重要——后五件套全部依赖第一件套**。 --- ## 二、分类:不是所有 server 都该被一视同仁 ### 2.1 为什么必须分类 新人最容易犯的错误是——对所有 MCP server 用同一套审计强度。 结果两头不讨好: - 对**自研 server** 强制三道审计、签名、SBOM,团队抱怨流程过重; - 对**第三方 server** 只看 README 就装上,结果某天发现它在传公司数据。 正确做法是**按来源与风险分级**。 ### 2.2 四档分类 | 类别 | 来源 | 典型例子 | 风险特征 | |------|------|---------|---------| | **C1: First-party** | 团队自研 | 内部 DB server、内部业务 API | 风险来自代码质量,可控 | | **C2: 官方 / 协议组织** | modelcontextprotocol/servers | filesystem、github、git | 风险来自版本兼容,可控 | | **C3: 厂商官方** | 数据库厂商 / SaaS 官方 server | Postgres 官方、Stripe 官方 | 风险来自厂商策略变化 | | **C4: 第三方 / 社区** | 个人或社区项目 | GitHub 上随手 fork 的 server | 风险来自代码 + 凭据 + 行为 | **核心准入要求差异**: | 类别 | 代码审计 | 强制沙箱 | 版本锁定 | 凭据隔离 | |------|---------|---------|---------|---------| | C1 | review 即可 | 推荐 | 必须 | 必须 | | C2 | 信任官方 | 推荐 | 必须 | 必须 | | C3 | 安全审计 | 推荐 | 必须 | 必须 | | C4 | **强制** | **强制** | **必须** | **必须** | **默认策略**:禁止使用未分类的 server。**新 server 接入的第一步永远是"它属于哪一类"**。 ### 2.3 一个常被忽视的判断题 很多人会问:**"那个看起来很官方的 server,是 C2 还是 C3 还是 C4?"** 判断标准: - 在 `modelcontextprotocol/servers` 仓库下 -> C2; - 在厂商自己的官方 GitHub 组织下(如 `@anthropic-ai`、`@stripe`)-> C3; - 在某个个人 / 不知名组织下,哪怕 star 很多 -> C4。 **Star 数不能让一个 server 升级。一万 star 的 C4 仍然是 C4。** --- ## 三、Registry:所有治理的"真相之源" ### 3.1 Registry 不是文档,是契约 很多团队把 MCP server 信息散落在三个地方: - 每个 agent 的配置文件里; - 内部 wiki 的某个表格里; - 某个工程师的脑子里。 **这是治理失败的开始**。 真正的 Registry 是一个**单一权威源**,所有 agent host 启动时必须校验它——**未登记的 server 一律拒绝加载**。 ### 3.2 Registry 的最小字段集 ```yaml servers: - id: internal-db class: C1 version: 1.4.0 protocol_version: "2024-11-05" transport: stdio # stdio | http | sse owner: data-platform@team stability: stable # experimental | beta | stable | deprecated image: registry.internal/mcp/internal-db:1.4.0 sandbox: container # none | container | wasm | seccomp credentials: source: vault # vault | env | keychain vault_path: secret/mcp/internal-db allowed_capabilities: - net.internal - fs.read:/data/exports health: probe: http://localhost:9090/health interval_s: 30 consumers: - agent-coder - agent-analyst last_audited: 2026-04-15 ``` **每一个字段都不是装饰**。我们一个一个拆解: #### `class` —— 决定准入强度 参见上一章。**没有这个字段,你就没法区分"信任级别"**。 #### `version` —— 锁定,禁止 `latest` 不锁版本的运维等于赌博: - server 升级一个 minor,可能改了 tool 的返回结构; - agent 没动,但行为突然变了; - 排查时一脸懵。 **铁律**:版本字段必须是具体值,不允许 `latest`、`*`、`>=x.y`。 #### `protocol_version` —— 锁定 MCP 协议版本 MCP 协议本身在演化。不同协议版本之间的消息格式可能有变化。 **锁定 protocol_version 是为了让"server 升级"和"协议升级"两件事解耦**。否则你升级 server 时,可能意外撞上协议变更,问题排查难度翻倍。 #### `transport` —— stdio / http / sse 不同传输方式的运维差异很大: - **stdio**:进程级隔离,调试简单,部署轻; - **HTTP**:可远程部署,可负载均衡,但延迟更高; - **SSE**:用于长流式响应。 **Registry 显式声明 transport,让 host 知道用什么客户端连**。 #### `owner` —— 必须是人 + 团队 只写人名不够(人会离职),只写团队不够(团队不背责)。 正确格式:`alice@data-platform` 或 `data-platform@team` 配合内部 oncall 表。 **没 owner 的 server 不准登记。这一条永远不能让步**。 #### `stability` —— 决定能否被生产用 - `experimental`:开发期,仅内部用,可以随时崩; - `beta`:内部多 agent 试用,有基本 SLA; - `stable`:生产可用,变更走严格流程; - `deprecated`:待下线,CI 在被引用时告警。 **生产环境的 agent 默认只能引用 stable server**。这条策略可以放进 host 启动校验里强制执行。 #### `sandbox` —— 隔离形态 `none` / `container` / `wasm` / `seccomp`。详见第四章。 #### `credentials.source` —— 凭据从哪来 `vault` / `env` / `keychain`。**这个字段的存在本身就是治理动作**——它强迫你回答"凭据存哪里",而不是默认散落在各处。 #### `allowed_capabilities` —— 权限白名单 详见第四章。**默认 deny-all,未声明的能力 = 拒绝**。 #### `health` —— 健康探针 详见第六章。 #### `consumers` —— 谁在用 这是经常被忽视但**极其重要**的字段。它让你能回答: - 这个 server 升级,影响谁? - 这个 server 30 天没人用了,能下线吗? - 这个 server 出故障了,需要通知哪些团队? **没有 consumers 字段的 Registry,无法做影响分析**。 #### `last_audited` —— 上次审计时间 C3 / C4 的 server 必须周期审计。**不写这个字段,审计就永远不会发生**。 ### 3.3 Registry 即真相:host 启动校验 Registry 不是 wiki 上的表格,是**host 必须读的配置**。 启动校验流程: 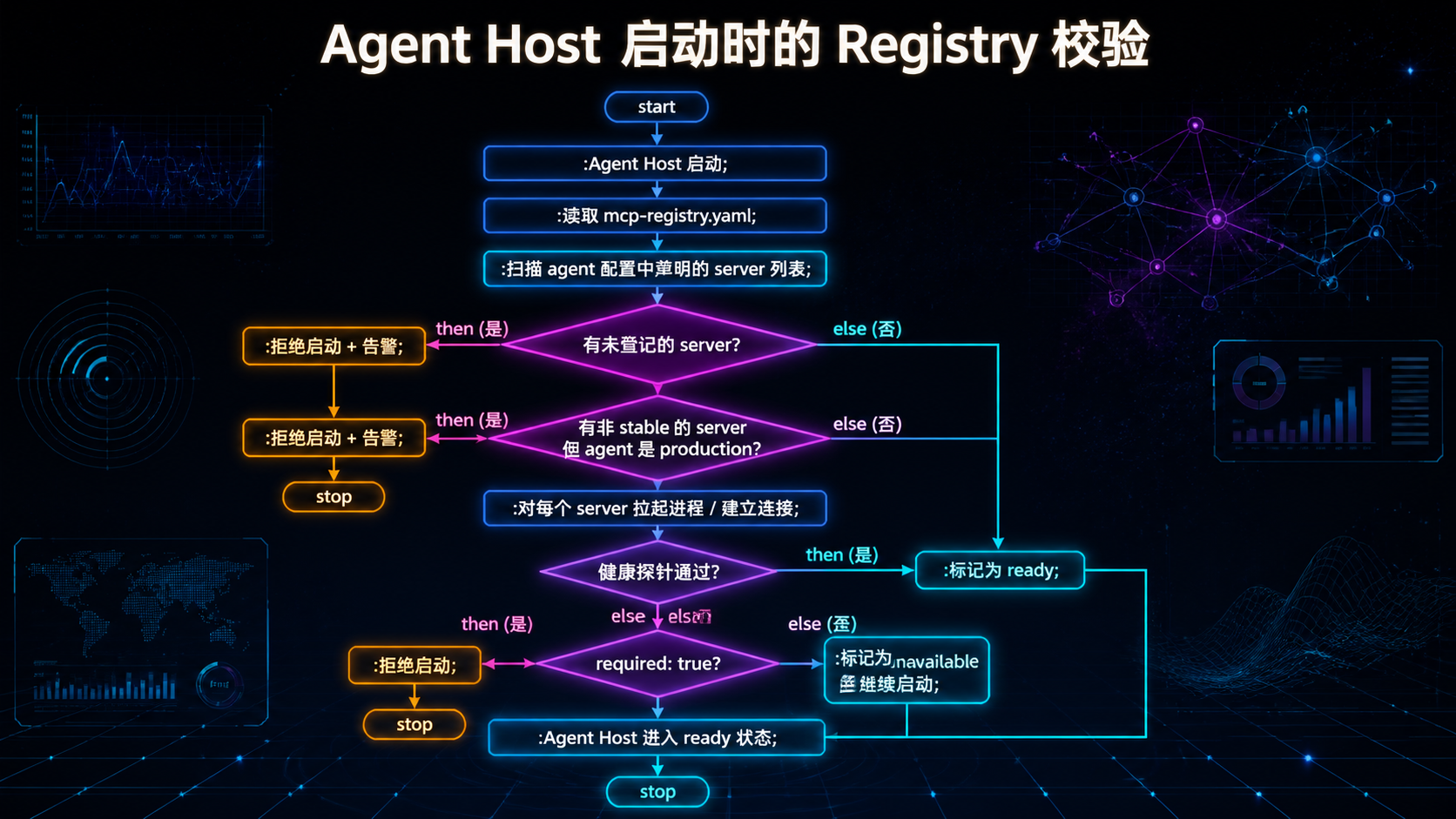 **这一套校验不是 nice-to-have,是治理的底线**。没有它,Registry 就只是一个被人忽视的 YAML 文件。 --- ## 四、沙箱与权限:把第三方 server 关进笼子 ### 4.1 为什么沙箱不能省 回到第一章的事实——**MCP server 是独立进程,会执行代码**。 这意味着一个第三方 server 理论上可以: - 读你的 `~/.ssh`; - 调用 `curl` 把数据传到外网; - 启动子进程跑任意命令; - 写入根目录、修改系统文件; - 在后台开一个反向 shell。 **任何一个 MCP server 都有这种能力,只要你没有沙箱**。 C4 server 必须强制沙箱化——这不是建议,是底线。 ### 4.2 四档沙箱形态 | 形态 | 适用 | 工程成本 | 隔离强度 | |------|------|---------|---------| | `none` | 仅 C1 / C2 且只读 + 非敏感 | 零 | 无 | | `container` | 默认推荐(C3 / C4) | 中 | 强 | | `seccomp + namespace` | 性能敏感场景 | 高 | 强 | | `wasm` | 实验性,强隔离 | 高 | 极强 | **实务建议**: - 90% 的团队,**默认上 container 就够了**; - 性能敏感、不能接受容器开销时,要考虑 seccomp; - WASM 还在演化,生态不成熟,不推荐生产用。 ### 4.3 Container 沙箱的最小实践 ```bash # 推荐的容器化运行方式 docker run \ --read-only \ # 容器文件系统只读 --tmpfs /tmp:size=64M \ # 临时空间限制 --network mcp-internal \ # 自定义网络,可控出口 --cap-drop ALL \ # 丢弃所有 capability --security-opt no-new-privileges \ # 禁止权限提升 --memory 256m --cpus 0.5 \ # 资源限制 --user 1000:1000 \ # 非 root 运行 -v /data/exports:/data/exports:ro \ # 显式挂载,只读 --env-file <(vault read -format=json ...) \# 凭据通过 vault 注入 registry.internal/mcp/internal-db:1.4.0 ``` **几个关键点**: 1. `--read-only` + `--tmpfs`:根文件系统只读,临时空间独立; 2. `--cap-drop ALL`:默认 deny-all Linux capability; 3. `--network mcp-internal`:自定义网络,可以在网络层做出口控制; 4. 资源限制:防止 server 进程消耗过多资源拖垮 host; 5. 非 root 运行:即使容器被攻破,攻击者也不是 root; 6. 显式挂载:只挂载它真正需要的目录。 ### 4.4 Capability 声明:默认 deny-all 光有容器还不够。还需要在 Registry 里**显式声明这个 server 允许做什么**: ```yaml allowed_capabilities: - fs.read:/data/exports # 文件系统读,限定路径 - fs.write:/tmp/mcp-internal-db # 文件系统写,限定路径 - net.internal # 仅内网 - net.external:api.github.com # 仅指定外网域名 - exec:none # 禁止子进程 ``` 未声明的能力 = 拒绝。**Host 在启动 server 时根据声明配置沙箱参数**——比如 `net.external:api.github.com` 会被翻译成防火墙规则。 ### 4.5 危险能力清单:需要二级审批 某些能力**威力过大**,不应轻易授予: - `exec:any`:可启动任意子进程; - `net.external:*`:任意外网(数据外传风险); - `fs.write:/`:根目录写入; - 任何涉及凭据导出的能力(`secrets.read:*`)。 **这些能力即使是 C1 server 也需要二级审批**。Registry 的 PR 需要 owner + 安全团队双签。 --- ## 五、凭据:永远不要让它进入 agent context ### 5.1 凭据泄漏的真实路径 回顾一下凭据可能泄漏的真实路径: 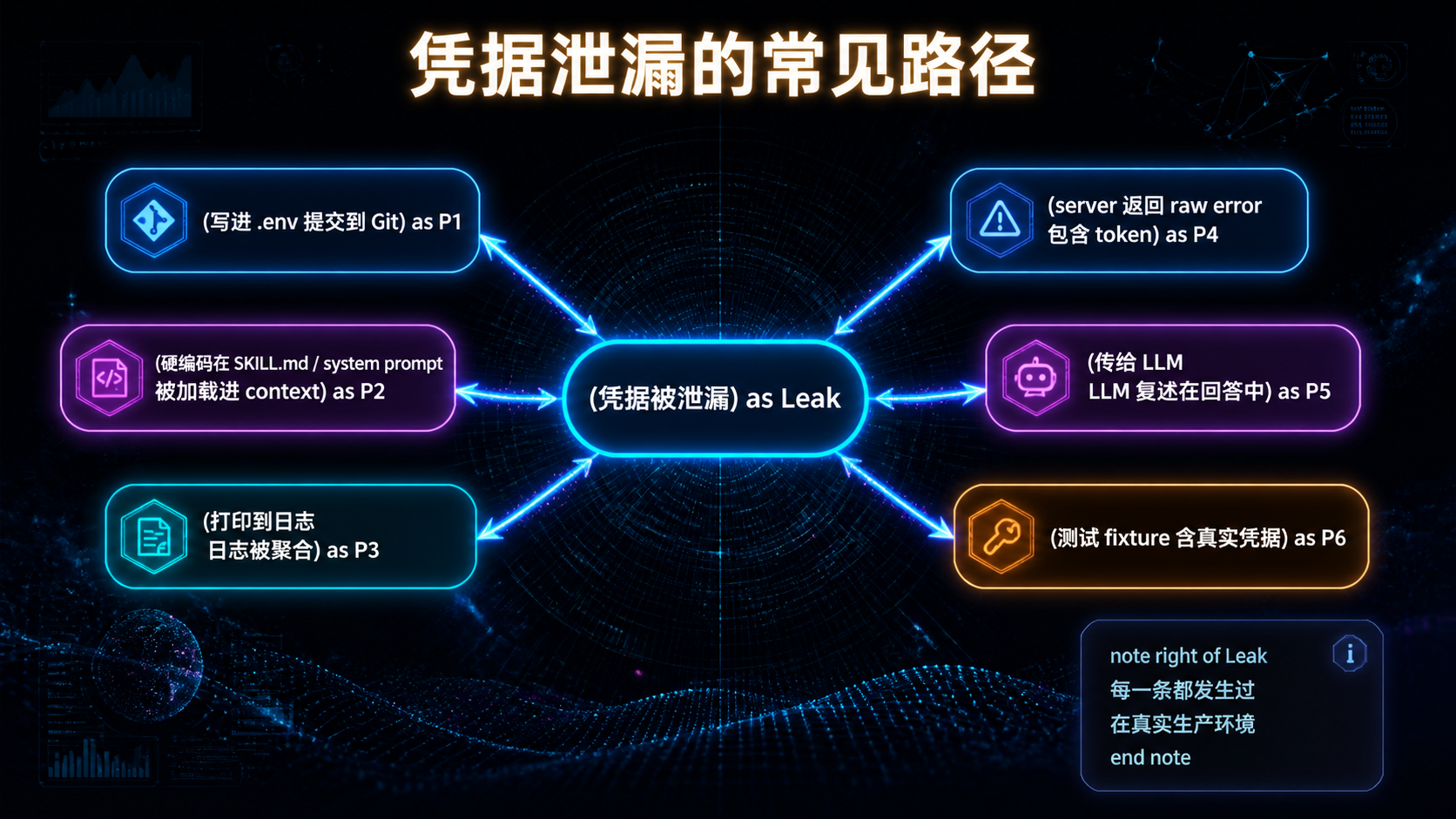 每一条路径都有真实案例。**凭据治理的目标,是把所有路径堵死**。 ### 5.2 六条强制规则 | # | 规则 | 防住哪条路径 | |---|------|------------| | CR1 | 凭据绝不进入 SKILL.md / system prompt / agent context | 防 P2 | | CR2 | 凭据绝不进入仓库(即使加密) | 防 P1、P6 | | CR3 | 凭据由 server 进程自己从 vault / keychain / 受控 env 读取 | 防 P1、P2 | | CR4 | 日志中凭据必须自动 redact | 防 P3、P4 | | CR5 | 凭据按 server 维度隔离(一 server 一凭据,最小作用域) | 限制泄漏影响 | | CR6 | 凭据轮换可在不重启 agent host 的前提下完成 | 应急响应时间 | 每一条规则都不是教条——**它们对应的是真实事故的复盘结论**。 ### 5.3 凭据存放:三档推荐 | 环境 | 推荐方案 | 备注 | |------|---------|------| | 生产 | HashiCorp Vault / Cloud KMS + 短期 token | token 自动轮换 | | 开发 | OS keychain(macOS Keychain / Windows Credential Manager) + 本地受限文件 | 与生产凭据隔离 | | CI | CI 自带 secret manager + 临时 token | 禁止用 production 凭据 | **关键纪律**:**生产凭据永远不进入开发 / CI 环境**。开发环境用的是 staging 凭据。 ### 5.4 凭据泄漏的应急流程 万一发生泄漏(GitHub secret scanning / log scan 报警): 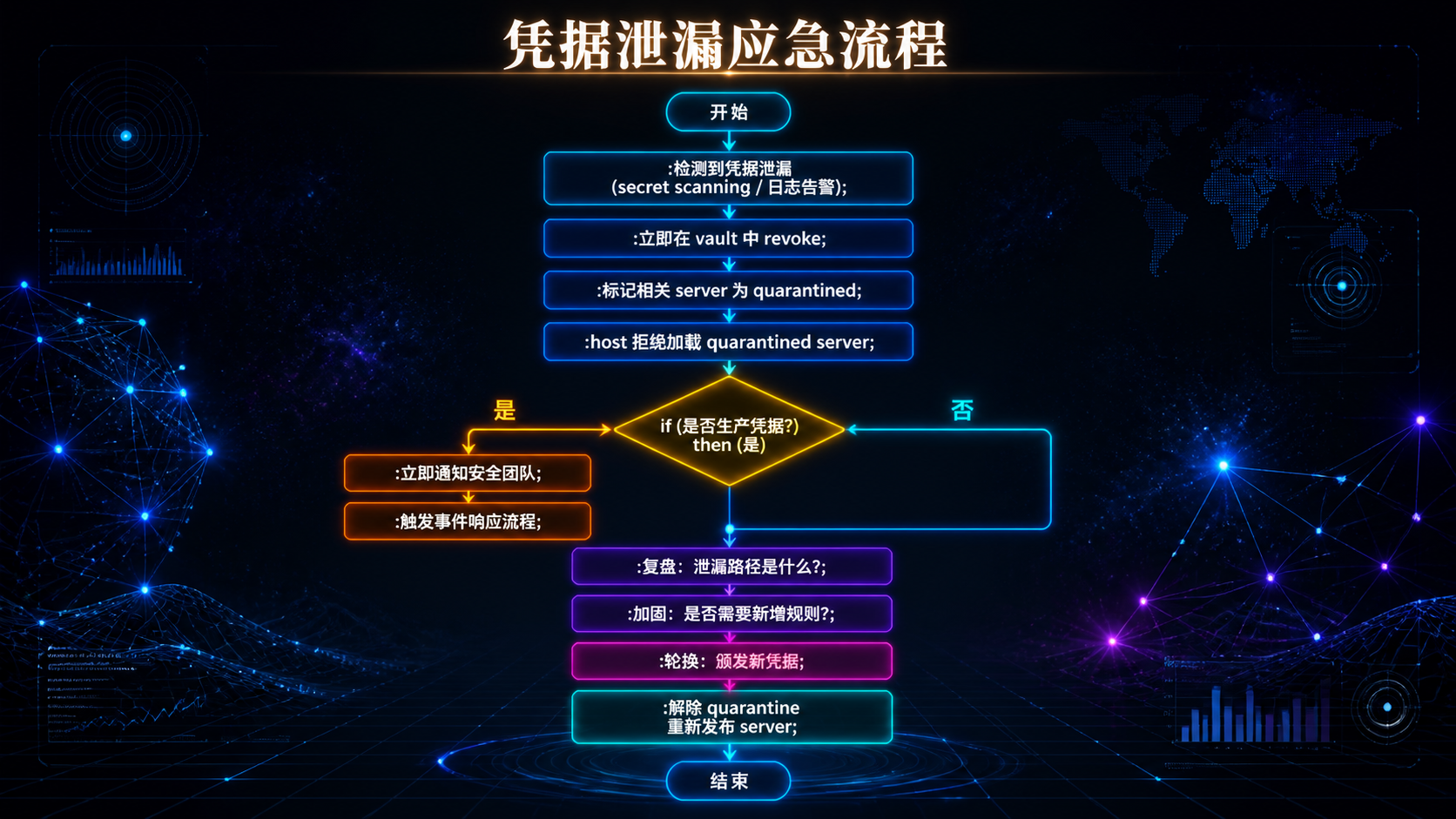 **关键时间窗口**:从检测到 revoke 应当在分钟级——这要求自动化。**任何"等下班再处理"的凭据问题都是事故扩大**。 --- ## 六、健康检查与故障处理 ### 6.1 健康检查不是 "ping" 很多团队把健康检查理解成"能不能连上"——这是远远不够的。 一个 MCP server 的健康检查至少要回答: 1. 进程是否存活; 2. MCP handshake 是否成功; 3. 它依赖的下游(DB、API)是否可用; 4. 协议版本是否兼容; 5. server 内部状态是否正常(如连接池是否耗尽)。 ### 6.2 stdio 与 HTTP 的不同探活方式 #### stdio server stdio server 没有 HTTP 端点,探活靠**协议层面的 handshake**: - 启动后 N 秒内必须发送 `initialize` 响应; - 周期发送 `ping` 请求,server 必须响应 `pong`; - 任何协议错误(无效 JSON、message id 错乱)视为不健康。 #### HTTP / SSE server HTTP server 应当暴露 `/health` 端点: ```json GET /health { "status": "ok", "version": "1.4.0", "protocol_version": "2024-11-05", "uptime_s": 12483, "dependencies": { "database": "ok", "external_api": "degraded" } } ``` **关键**:dependencies 字段让 host 能区分"server 自己挂了"和"server 依赖挂了"——前者重启可能有用,后者重启没用。 ### 6.3 故障处理矩阵 | 故障类型 | Host 行为 | |---------|----------| | server 启动失败 | 标记为 `unavailable`;若 `required: true` 则 host 启动失败 | | 单次调用超时 | 指数退避重试不超过 N 次,全失败则返回结构化错误给模型 | | 连续 M 次调用失败 | 触发 circuit breaker,临时禁用该 server | | server 进程崩溃 | 自动重启不超过 K 次;超出则告警 + 标记 `quarantined` | | 健康检查持续失败 | 转入降级模式,agent 接收"该能力暂不可用"信号 | | 协议版本不兼容 | 拒绝建立连接,告警 | **N、M、K 的具体值由团队根据 SLA 自填**——不要照抄网上的数字。 ### 6.4 错误必须结构化,不能 raw 这是被严重低估的设计点。 **反模式**:把 server 的 raw exception 塞进 tool result 返回给模型: ``` ConnectionError: [Errno 111] Connection refused File "/app/server.py", line 142, in handle_request ... Traceback... ``` **为什么致命**: 1. 模型可能在回答中复述这段错误,**包含路径、版本号、凭据片段**; 2. 模型不知道这是"工具故障"还是"用户请求错误",可能误导用户; 3. 多次失败时模型会陷入"反复重试"循环。 **正确做法**:返回结构化错误给模型: ```json { "error": { "kind": "tool_unavailable", "retryable": false, "user_message": "数据库查询暂时不可用,请稍后再试。", "internal_id": "err-2026-05-12-a3f" } } ``` `internal_id` 留给运维做日志关联,`user_message` 留给模型展示给用户。**raw exception 永远只进日志,不进 context**。 ### 6.5 降级与回退 每个关键 server 应在 Registry 中声明降级方案: ```yaml fallback: mode: degrade # degrade | reject | alt-server user_message: "数据库查询暂不可用,请稍后再试。" alt_server: internal-db-readonly ``` 三档降级: - `reject`:直接拒绝调用,告诉模型该能力不可用; - `degrade`:返回降级结果(如缓存、空结果),并标注; - `alt-server`:切到备用 server(如主写 server 挂了切到只读 server)。 **没有 fallback 声明的关键 server,不准上生产**。 --- ## 七、可观测性:你需要回答"上周谁调了什么" ### 7.1 必发事件清单 最低事件集: | Event | 触发时机 | |-------|---------| | `mcp.server.startup` | server 启动并完成 handshake | | `mcp.server.health` | 每次健康探针结果 | | `mcp.tool.invoked` | 模型发起一次 tool call | | `mcp.tool.completed` | tool call 结束 | | `mcp.server.error` | 协议错误 / 崩溃 / circuit break | | `mcp.server.shutdown` | server 退出 | ### 7.2 必含字段 ``` trace_id, server_id, server_version, protocol_version, tool_name, latency_ms, input_size, output_size, outcome, error_class ``` **特别提醒:不要把 tool 的 input/output payload 默认落日志**。 很多 server 会接触 PII、凭据、业务敏感数据。**默认日志只记 size 和 outcome,按需采样 + 显式 allowlist 才采 payload**。 ### 7.3 最低 Dashboard 运维 MCP 体系的人必须能看到: 1. **Top-N 被调用 server / tool**:哪些被频繁用; 2. **每 server 的 p50 / p95 / p99 延迟**:性能基线; 3. **错误分类分布**:timeout / protocol / auth / app; 4. **circuit breaker 触发历史**:哪些 server 不稳; 5. **登记但 30 天未被调用的 server**:候选下线; 6. **凭据轮换状态**:哪些 server 凭据过期临近。 **没有这些数据,你不知道该砍谁、该升谁、该救谁**。 --- ## 八、生命周期:MCP server 也会"老去" ### 8.1 server 不是一次性资产 很多团队的 server 一旦上线就"被遗忘"。三年后某天你发现: - 它在用三年前的 SDK; - 它依赖的某个 Python 库已经停止维护; - 它的 owner 早就离职; - 没人敢动它,因为不知道改了会不会出事。 **这就是缺乏生命周期管理的结局**。 ### 8.2 五阶段生命周期 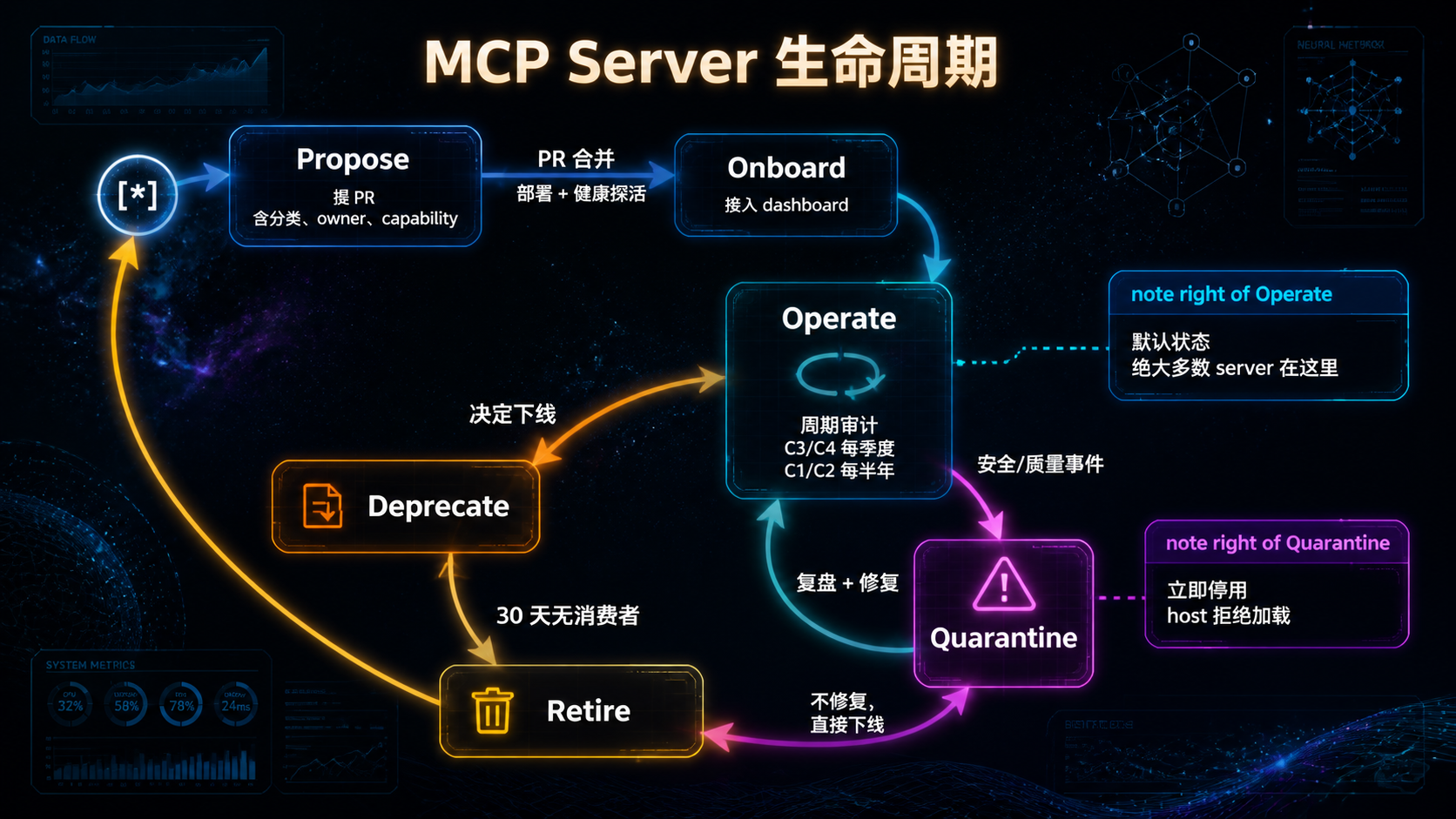 每个阶段对应不同的约束: | 阶段 | 准入要求 | host 行为 | |------|---------|----------| | Propose | PR + classification + owner | 不可用 | | Onboard | 健康通过 + dashboard 接入 | 可用(受限) | | Operate | 周期审计 | 可用 | | Deprecate | 标记 `replaced-by` | 仍可用,但 CI 告警 | | Retire | 30 天无 consumers | 从 Registry 移除 | | Quarantine | 立即触发 | host 拒绝加载 | ### 8.3 审计周期 | 类别 | 审计周期 | |------|---------| | C1 / C2 | 每半年 | | C3 | 每季度 | | C4 | **每季度 + 每次版本升级** | 审计内容: - 代码 review(diff since last audit); - 凭据是否仍然最小化; - capability 声明是否仍然合理; - 是否有未修补的 CVE; - consumers 列表是否仍然准确。 **审计不是仪式,是控制风险的最便宜手段**。 ### 8.4 Retire 的纪律 server 一旦 30 天没有 consumer,host 自动发出 retire 候选告警。 retire 的步骤: 1. 通知 owner 与历史 consumers; 2. 给 14 天迁移窗口; 3. 14 天后从 Registry 移除; 4. server 进程停止; 5. 凭据从 vault 删除; 6. 文档归档。 **Retire 不是"删除"**——它是"有序下线"。**保留凭据、保留 image、不更新 Registry,是技术债复利的开始**。 --- ## 九、十大反模式:MCP server 治理一定会踩的坑 把工程现实凝练成反模式清单。 ### AP1:把内部一次性函数包成 MCP server 错误:把单 agent 内部用的函数包成 server。 正确:单 agent 私有用 inline tool,跨 agent 复用才 MCP 化。 **为什么致命**:延迟翻倍 + 调试地狱 + 无复用收益。 ### AP2:用 `latest` 标签拉 server 错误:`image: registry.internal/mcp/internal-db:latest`。 正确:必须锁定具体版本号。 **为什么致命**:升级不可控,事故无法回滚。 ### AP3:server 把凭据写到 stdout / log 错误:server 在错误信息里打印 raw token。 正确:日志强制 redact + vault 管理。 **为什么致命**:日志聚合后凭据被无数人能看到。 ### AP4:C4 server 不沙箱直接跑 错误:从 GitHub 拉个 server 直接 npm install + node run。 正确:强制 container + capability 白名单。 **为什么致命**:等于给陌生人 root 权限。 ### AP5:把原始异常作为结果返回模型 错误:raw `Traceback` 塞进 tool result。 正确:结构化错误 + user_message + internal_id。 **为什么致命**:信息泄漏 + 模型行为不可控。 ### AP6:把超长结果原样塞进 context 错误:server 返回 10MB JSON,全进 context。 正确:host 端截断 + 提供 resource id 让模型按需读。 **为什么致命**:context 爆炸 + 后续推理质量崩塌。 ### AP7:默认 `net.external:*` 错误:图省事给 server 开了任意外网访问。 正确:域名 allowlist + 防火墙规则。 **为什么致命**:数据外传无法检测。 ### AP8:一个 server 一把万能凭据 错误:一个 GitHub token,所有 GitHub MCP server 共用。 正确:最小作用域,一 server 一凭据。 **为什么致命**:泄漏一处,全军覆没。 ### AP9:Registry 与实际部署漂移 错误:Registry 写的是 v1.4,生产实际跑 v1.6。 正确:host 启动校验 + nightly diff 报警。 **为什么致命**:所有治理基于错误事实,所有决策都错。 ### AP10:没有 owner 的 server 留在生产 错误:owner 离职后无人接手,server 默默运行。 正确:owner 必填,离职必须转移,无人接手必须 retire。 **为什么致命**:技术债复利。 --- ## 十、收尾:把 MCP server 当微服务管 这篇文章拆得很细,但所有内容可以凝练成几条核心判断: **1. MCP server 是独立进程,不是函数调用。** 凡是独立进程,都有微服务运维的全部问题——分类、注册、健康、凭据、隔离、降级、可观测、生命周期。 **2. Registry 是治理的锚点。** 没有 Registry,其他所有治理动作都是空中楼阁。**Registry 即真相**,host 启动必须校验。 **3. 分类决定治理强度。** C1 / C2 / C3 / C4 不同准入。**Star 数不能让一个 server 升级**。 **4. 沙箱是底线,不是高级特性。** C4 server 强制 container,默认 deny-all capability。**任何"我们先不沙箱"的决定都会变成"我们没沙箱"的事实**。 **5. 凭据永远不能进入 agent context。** 六条强制规则,一条都不能让步。**凭据泄漏的代价远高于治理成本**。 **6. 错误必须结构化,不能 raw。** raw exception 进 context = 信息泄漏 + 行为不可控。**结构化错误是治理的微观最佳实践**。 **7. 生命周期管理决定长期健康。** "上线即遗忘"的 server 是技术债复利的源头。**Retire 是治理的一部分**。 --- ### 三个可操作的下一步 **如果你刚开始接入 MCP**: 先不要急着接十个 server。**先建 Registry**,哪怕只有两条记录。Registry 是第一件事,不是最后一件事。 **如果你已经有几个 server 在跑**: 本周做一件事——**给每个 server 补全 owner 和 sandbox 字段**。这两个字段决定了你能否在事故时快速响应。 **如果你在评估第三方 server**: 打开它的源码,看它声明的 `allowed_capabilities`,对照它**实际**做了什么。如果不一致,**这个 server 不能进生产**。 --- ## 延伸阅读 / 验证路径 > 提示:MCP 生态演化极快,以下链接请以**官方域名当前内容**为准。 - MCP 规范:`modelcontextprotocol.io` - MCP 官方 servers:`github.com/modelcontextprotocol/servers` - Anthropic 工程博客(MCP / Agent 相关):`anthropic.com/engineering` - 社区讨论:r/ClaudeAI、r/LocalLLaMA 搜 "MCP server"、"MCP sandbox" **Knowledge Boundary**:MCP 协议(含传输层、消息格式、authorization 草案)仍在演化。本文的**治理原则**层面预计稳定;涉及具体协议字段时请以引用链接的当前规范为准。 --- > **写在最后** > MCP 让 AI 能力可以像微服务一样跨进程暴露——这是好事。 > 但跨进程的代价,是所有微服务运维问题都会到你头上。 > 治理不是过度工程,是把"能跑的 demo"变成"敢上的系统"的唯一路径。 --- *如果这篇文章让你重新审视了团队的 MCP 实践,欢迎转发给身边那些"先把 server 跑起来再说"的工程师。* *下一篇我们会拆「Agent 编排框架选型:LangGraph、Claude Agent SDK、自研,到底怎么选」——配合 Skills 与 MCP,构成 AI 工程的完整决策框架。*
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号