Claude Sonnet 5:平价主力智能体,自动化进入默认席位

Claude Sonnet 5:平价主力智能体,自动化进入默认席位

Henry Zhang
发布于 2026-07-03 20:45:21
发布于 2026-07-03 20:45:21

题图:加州优胜美地国家公园
导读|Anthropic 正把强智能体能力下放到 Sonnet 5。它的价值不只是更低的 Token 单价,而是让工具调用、异常处理和多步骤任务,第一次成为日常工作流中的常规能力。
近期 Anthropic 旗下 Claude Code 客户端曝出地域监控相关争议,隐蔽检测机制引发大量中国用户不满,厂商已承诺下一版本彻底移除相关逻辑。
风波之外,6 月 30 日,Anthropic 发布 Claude Sonnet 5,并将其设为 Claude Free 与 Pro 的默认模型,同时接入 Claude Code 和 API。这一安排很有分量:浏览网页、调用终端、修改代码、推进多步骤任务,不再只是旗舰模型的演示能力,而被直接放进了用户最常触达的入口。
先把产品关系说清楚:Fable 5 和 Mythos 5 并非外部竞品,而是 A 厂能力金字塔更上一层的产品。Fable 是面向一般用户、加装更严格护栏的 Mythos-class 模型;Mythos 与它共享底座,但只通过受信任访问计划提供。Opus 4.8 位于两者与 Sonnet 之间,承担高端复杂推理。
为什么 Sonnet 5 会成为“主力档”
从能力分层看,把它们放进一个工具箱里更容易理解:Haiku 是随身小刀,Sonnet 是每天都用的家用厨刀,Opus 是主厨的专业刀具,Fable 则像实验室里的精密设备。从企业部署的角度看,如果把 Fable、Opus 看作专业级工具,Sonnet 更像一辆日常通勤的家用车:性能足够,成本可控,出问题时也更容易设计备选路线。
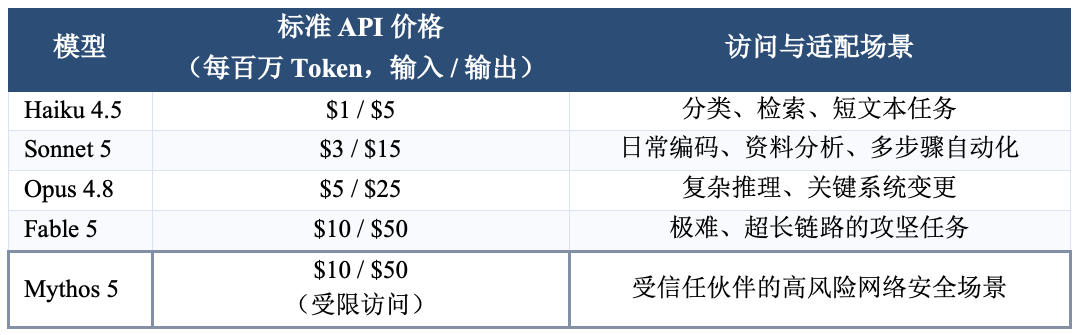
注:Token 是模型处理和计费的最小文本单位。Sonnet 5 在 2026 年 8 月 31 日前的导入价为 $2 / $10;自 9 月 1 日起执行上表标准价。Mythos 的访问仍受限。
按标准价计算,Sonnet 的输入和输出单价约为 Opus 的 60%、Fable 的 30%。因此,“更便宜”是一个很明确的判断:公开 Token 单价是 API 市场里最透明、也最容易横向比较的成本指标。我更看重的是另一件事:这类能够调用工具、反复试错的能力,终于被放进了多数团队可以持续负担的价格带。
“接近 Opus”,到底接近到什么程度?
官方基准显示,Sonnet 5 已明显追近 Opus,但没有抹平差距。其中,GDPval-AA v2 侧重职场知识工作;其余三项分别看智能体编码、终端操作和计算机操作。
官方基准(2026) | Sonnet 5 | Opus 4.8 | Fable 5 |
|---|---|---|---|
SWE-bench Pro(智能体编码) | 63.2% | 69.2% | 80.3% |
Terminal-Bench 2.1(终端任务) | 80.4% | 82.7% | — |
OSWorld-Verified(计算机操作) | 81.2% | 83.4% | — |
GDPval-AA v2(知识工作) | 1618 | 1615 | — |
注:数据源为 Anthropic 公开材料;“—”表示本次资料未在可直接比较的同口径表格中列出,不代表 Fable 不具备该能力。不同测试使用的工具、努力等级和代理框架并不完全一致。
在 SWE-bench Pro 的同一测试设置中,Opus 比 Sonnet 高约 6 个百分点,Fable 又比 Opus 高约 11 个百分点。这种差距会划出真实的工作边界:日常修 Bug、补测试、批量文档处理和常规业务自动化,Sonnet 往往已经够用;核心架构重构或高危生产变更,几个百分点可能就决定了任务能否自动完成,还是必须人工接手。
真正拉开差距的,往往是“收尾”
Anthropic 的合作伙伴展示过两类任务:更新 Salesforce 客户分级后,向企业联系人发送通知;以及在遗留代码中复现 Bug、写测试、修改并验证。这些案例当然带有选择性,不能替代独立评测,但它们把问题抓得很准。
异常发生之后,才是智能体开始见真章的时候。比如 API 返回 429 限流错误,或测试失败:模型是直接报错退出,还是读取日志、调整策略、重试并留下可核验结果?在企业里,智能体最值钱的地方,通常不是写出第一段代码,而是少让工程师中途接手一次。
拆解 Sonnet 5 成本:别只盯着 Token 单价
第一层,Token 单价。 Sonnet 的公开单价优势明确,批量调用和日常自动化最容易受益。
第二层,单任务消耗。单价低,不等于每项任务都一定更省。上下文长度、工具调用、重试与努力等级都会改变账单。新版分词器会让同等文本的 Token 数量增加 0% 至 35%;从 Sonnet 4.6 及更早模型迁移时,成本、延迟和输出上限都应重新实测。
第三层,人机总成本。 少一次人工排错、少一轮沟通、少一次复核,往往比省几美元 Token 更重要。企业真正该比较的是完成一件工作的人机总成本。
第四层,可用性与合规。 6 月 12 日,美国出口管制指令曾导致 Fable 5 与 Mythos 5 暂停访问;Fable 在 7 月 1 日才恢复全球访问,Mythos 仍主要面向受信任伙伴。更现实的一点是,Fable 需要至少 30 天的数据留存;所谓零数据留存,就是不允许服务方保留业务数据,因此这类场景不能直接使用 Fable。越靠近能力前沿,越可能受到访问资格、数据治理和政策变化影响。
安全与选型:别把模型当成整个系统
Sonnet 5 默认提供网络安全防护;Fable 的安全分类器更严格。按 Reuters 报道,部分被拦截的高风险请求会自动转由 Opus 4.8 处理,而不是直接报错退出。这里需要说清:安全不是模型自己能完成的事。权限上要遵循最小授权;流程上要给外发、删除、支付和生产变更设置人工确认;事后要能审计并回滚;运行时则要预先设计超时、拒绝或不可用时的降级路径。
选型没有万能答案,但有一条很实用的原则:用满足质量与安全阈值的最低成本模型。日常任务先从 Sonnet 开始灰度测试,达不到成功率或时延要求再升 Opus;Fable 与 Mythos 则只在预算、数据留存和合规条件同时满足时考虑。更稳妥的架构是分层路由:默认 Sonnet,高复杂度任务升级 Opus,极少数攻坚任务再调用 Fable,别让任何单一模型成为业务单点。
Sonnet 5 未必是智能体的终局,却很可能是一个分水岭。接下来的竞争,不只看谁拥有最强模型,也看谁能把足够强的模型放进默认工作流,并且让它稳定、合规、负担得起。真正会普及的,不是一台少数人开得起的超级跑车,而是一台每天都能上路、出了问题还有刹车和备胎的主力车型。
资料来源
[1]Anthropic:Introducing Claude Sonnet 5(2026 年 6 月 30 日)
[2]Anthropic Claude Platform:Pricing(访问日期:2026 年 7 月 1 日)
[3]Anthropic:Claude Fable 5 and Claude Mythos 5(2026 年 6 月 9 日)
[4]Anthropic:Redeploying Claude Fable 5(2026 年 6 月 30 日)
[5]Reuters:US removes curbs on Anthropic’s latest Fable and Mythos AI models(2026 年 6 月 30 日)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号