告别微调!DINOv3如何成为冻结即可用的通用视觉之王

告别微调!DINOv3如何成为冻结即可用的通用视觉之王

OpenCV学堂
发布于 2026-07-03 19:40:56
发布于 2026-07-03 19:40:56
DINO系列模型概述
在深入探讨 DINOv3 的创新之前,让我们先快速梳理一下 DINO 系列的演进历程:
- DINO (2021):提出了革命性的理念,即视觉 Transformer (ViT) 可以通过自蒸馏(self-distillation)方式,在无需标签的情况下学习到有意义的表征。
- DINOv2 (2023):进一步扩大了这一方法的规模,并提升了训练的稳定性。它证明了自监督模型能够产生跨领域通用的特征,且无需微调即可直接应用。
- DINOv3 (2025):将一切推向了前所未有的规模——拥有 70亿 参数,并在 17亿 张训练图像上进行学习。同时,它引入了突破性技术,解决了长期存在的密集特征退化(dense feature degradation)难题。
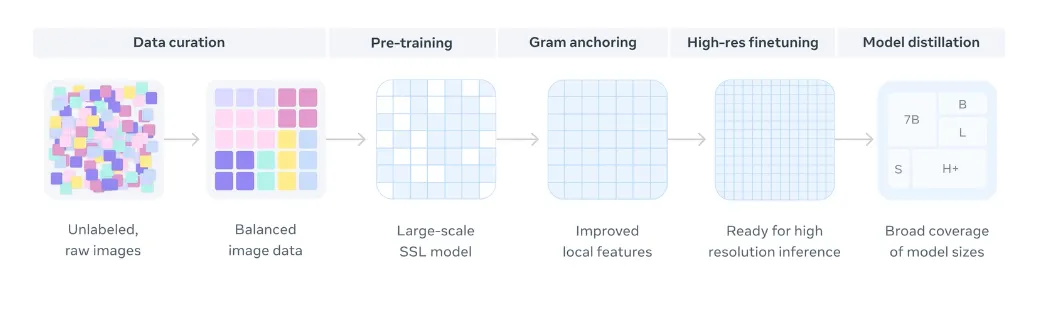
每一代模型不仅仅是性能的提升,更是从根本上改变了我们对“利用无标签数据能实现什么”的认知
DINOv3的不同之处
DINOv3的论文指出,DINOv3 能够生成丰富、密集的特征,且只需保持骨干网络冻结(即不进行参数更新),便可直接用于微调多种复杂的下游任务。这一点非常出色——通常,我们需要对模型进行一定程度的微调,才能使其适应特定下游任务并提升性能。但 DINOv3 凭借其训练策略和架构上的改进,彻底颠覆了这一局面。它已经学会生成高质量的密集特征,这些特征可以轻松适配并应用于任何特定场景。这意味着,它真正实现了论文中所说的——“一个单一的、冻结的 SSL(自监督学习)骨干网络,即可作为通用的视觉编码器”。
DINOv2到DINOv3的架构演化
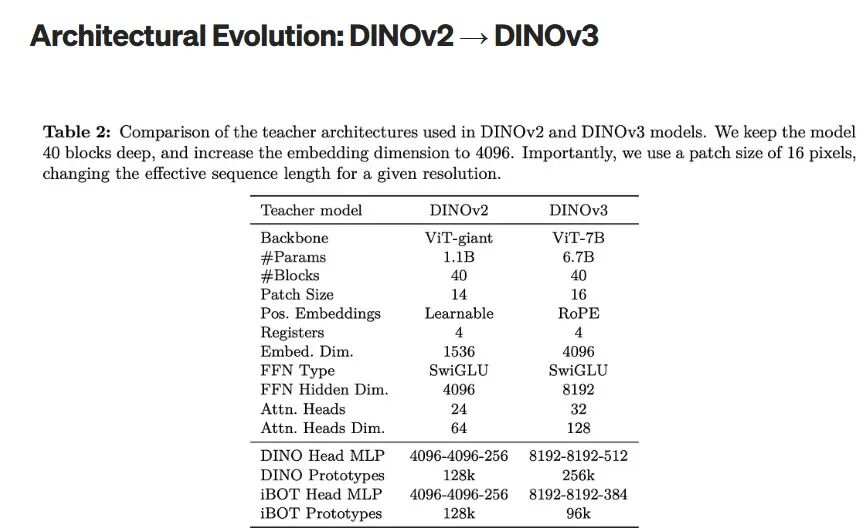
模型参数规模扩大
DINOv3 的规模是其前身的 6 倍,参数量从 11 亿跃升至 67 亿——这一跨越在保持同样 40 层深度的同时,实现了更丰富的表征学习能力。
位置编码方式改变
将可学习位置编码(learnable positional embeddings)替换为 RoPE(旋转位置嵌入,Rotary Position Embeddings)——这种现代化方法使得模型无需重新训练即可处理可变输入分辨率,支持从 256×256 到 4096×4096 像素的图像。
Patch大小变化
采用更大的图像块尺寸(从 14×14 增至 16×16 像素),通过缩短序列长度来提升计算效率;同时扩展嵌入维度(从 1536 增至 4096),以捕获更丰富的特征表征。
增强的注意力架构
- 更多的注意力头(从 24 个增至 32 个),且每个头的维度更大(从 64 增至 128)
- 前馈网络神经元节点翻倍(隐藏维度从 4096 增至 8192)
这些改进使模型能够捕获更复杂的视觉关系。
DINOv3的不同之处
DINOv3 将图像自监督学习推向新高度,打造出通用的视觉骨干网络,在多个不同领域均取得了绝对的当前最佳性能(state-of-the-art),涵盖目标检测、深度估计、图像分割、视频分类等任务。具体规模如下:
70 亿参数(相比之下,DINOv2 为 10 亿)
17 亿张训练图像(相比之下,DINOv2 为 1.42 亿)
无需微调即可跨视觉任务工作的通用骨干网络然而,仅靠规模并不能完全解释 DINOv3 的突破性表现。真正的精髓在于其技术创新。
自监督面临的密集特征退化问题
先前的自监督模型面临一个令人困扰的问题:在训练过程中,虽然全局图像特征持续改善,但密集的图像块级(patch-level)特征实际上却随着时间推移而逐渐变差。
DINOv3 的研究人员通过仔细分析图像块特征相似度图,定位了核心问题。
其演变过程如下:
在 20 万次迭代时(训练早期):
图像块特征干净、定位精准且具有语义意义
代表“花瓣”的图像块仅与其他花瓣图像块具有高相似度
密集预测任务可以表现优异
在 60 万次以上迭代时(训练后期):
图像块特征变得嘈杂,并失去其局部性
原本代表“花瓣”的图像块,现在与随机的、不相关的图像块(如草地)也表现出高相似度CLS 标记与图像块特征之间的余弦相似度增加,意味着图像块失去了其局部特异性。CLS 标记应当代表全局上下文,而图像块特征则应保持其细粒度的、位置特定的特征。当图像块特征与全局表征过于相似时,它们就失去了密集预测任务所需的空间区分性。
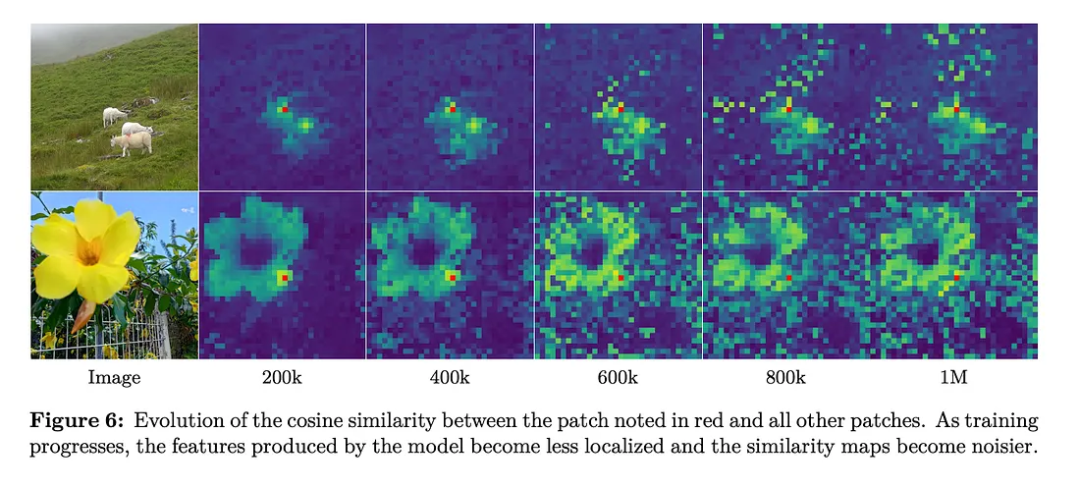
密集预测性能急剧下降
Gram 锚定- 解决密集特征退化
Meta 提出了一种名为 Gram 锚定(Gram Anchoring) 的方法。这是一种新型的损失函数,旨在强制要求图像块特征之间的相似性结构在长期训练过程中保持稳定。你可以把它想象成一种记忆机制,即使在特征本身不断演变的情况下,也能保持模型对图像块之间相互关系的理解保持一致。

该机制包含以下三个关键部分:
- Gram 教师(Gram Teacher) 保存模型在训练早期(约 20 万次迭代时)的一个“干净”版本,此时密集特征的质量仍然很高。
2. Gram 矩阵损失(Gram Matrix Loss) 对当前模型的图像块特征进行正则化,强制其与 Gram 教师中的特征相关性保持一致。
3. 高分辨率增强(High-Resolution Enhancement) 在 Gram 教师中使用 2 倍分辨率的特征,然后通过下采样来获得更好的图像块一致性。
关键策略
- DINOv3模型训练早期模型关系表现健康的时刻(即 20 万次迭代时)对其拍一张快照(take a snapshot)
- 将其保存为“Gram 教师”(Gram Teacher)——即那个“睿智的旧版本”
- 在后续的训练过程中,持续不断地反问自己:“我当前的关系状态,还和当初一样好吗?”
DINOv3的应用场景
图像分类:对图像进行准确类别判断;目标检测与实例分割:为检测和分割模型提供高质量的基础特征;语义分割:实现像素级的精细类别划分;图像检索与特征匹配:用于相似图像查找或内容匹配系统;多模态学习:可作为视觉编码器,与文本模型结合,用于图像描述、视觉问答等任务。
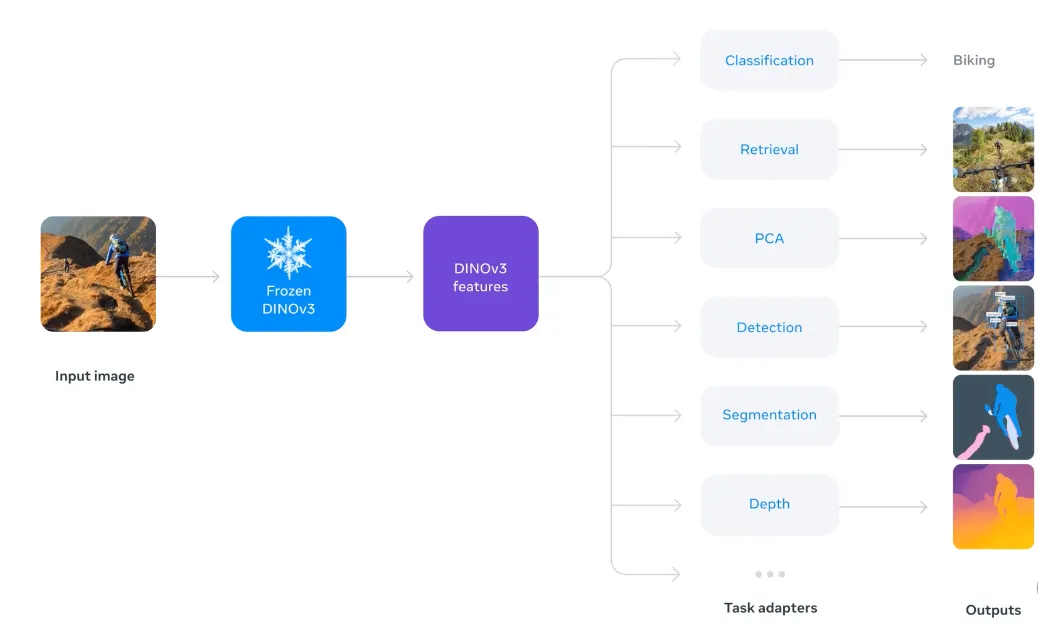
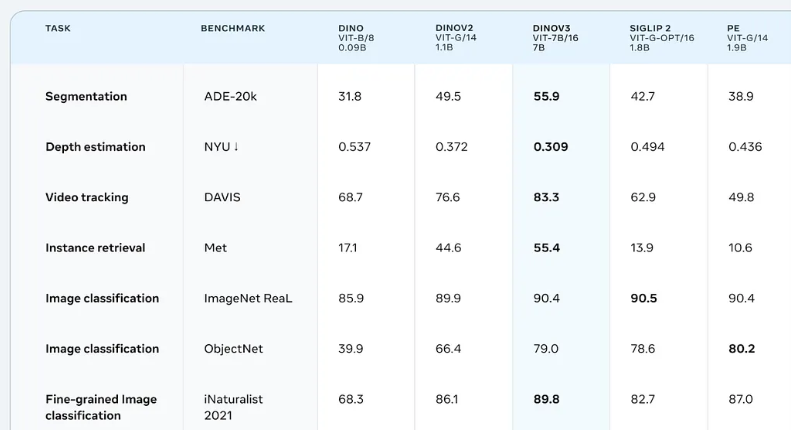
完全冻结DINOv3骨干网络,添加头部分,在各个视觉任务上表现如下:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号