CNN算法:从公式到现实应用的深度解析

CNN算法:从公式到现实应用的深度解析

FPGA技术江湖
发布于 2026-07-03 17:00:48
发布于 2026-07-03 17:00:48
卷积神经网络(Convolutional Neural Network,简称CNN)是深度学习中最具代表性的算法之一,尤其在图像识别、计算机视觉领域取得了巨大成功。CNN的设计灵感来源于生物视觉系统,通过模拟人脑处理视觉信息的方式,实现了对图像的高效理解和识别。

CNN概念插画
CNN的核心公式
卷积运算
CNN的核心操作是卷积运算,其数学表达式为:
S(i,j) = (I * K)(i,j) = Σₘ Σₙ I(m,n) · K(i-m, j-n)
其中:
- I 表示输入图像
- K 表示卷积核(滤波器)
- S 表示输出特征图
- i,j 表示输出位置
- m,n 表示卷积核的移动范围
激活函数
常用的ReLU激活函数:
f(x) = max(0, x)
池化操作
最大池化的数学表达:
P(i,j) = max{I(i·s + m, j·s + n) | 0 ≤ m,n < k}
其中s为步长,k为池化窗口大小。
CNN在现实工程中的应用
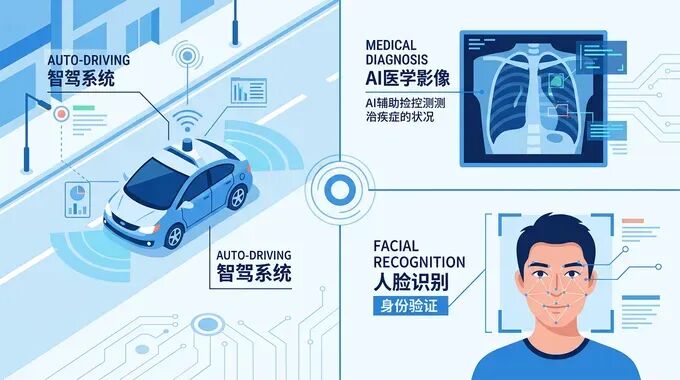
CNN应用场景
- 1自动驾驶
CNN在自动驾驶系统中扮演着关键角色:
特斯拉的Autopilot系统就大量使用了CNN技术来处理摄像头数据,实现环境感知。
- 物体检测:识别行人、车辆、交通标志
- 车道线检测:实时识别道路边界
- 语义分割:理解场景中的每个像素属于什么类别
- 2医疗影像诊断
CNN在医疗领域的应用正在改变疾病诊断方式:
研究表明,某些CNN模型在皮肤癌诊断上的准确率已经超过了专业医生。
- X光片分析:自动检测肺炎、骨折等病变
- CT/MRI扫描:识别肿瘤、器官异常
- 病理切片分析:辅助癌症诊断
- 3人脸识别
从手机解锁到安防监控,CNN驱动的人脸识别技术已无处不在:
- Face ID:苹果手机的 facial recognition
- 门禁系统:企业、小区的身份验证
- 支付验证:支付宝、微信的人脸支付
- 4工业质检
制造业中,CNN被用于:
- 缺陷检测:识别产品表面瑕疵
- 质量分级:自动对产品进行分类
- 尺寸测量:精确测量零件尺寸
- 5农业应用
- 病虫害识别:通过叶片图像判断作物健康状况
- 果实成熟度检测:自动化采摘决策
- 杂草识别:精准除草,减少农药使用
CNN数字识别具体示例
让我们通过经典的MNIST手写数字识别案例,深入了解CNN的工作原理。
MNIST数据集
MNIST包含60,000张训练图片和10,000张测试图片,每张图片是28×28像素的手写数字(0-9)。
CNN架构设计
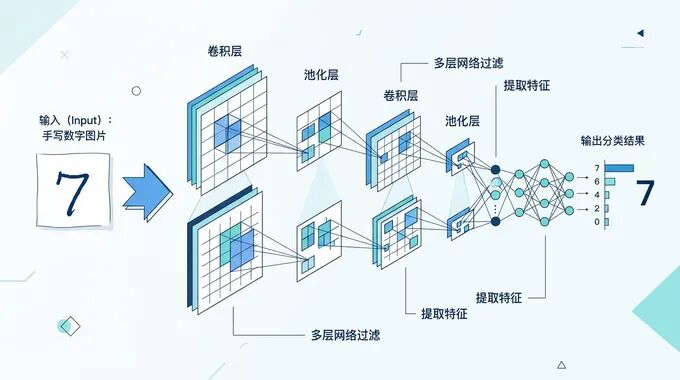
CNN架构图解
一个典型的MNIST识别CNN包含以下层:
第一层:卷积层
输入:28×28×1(灰度图) | 卷积核:32个5×5的滤波器 | 输出:24×24×32 | 激活函数:ReLU
第二层:池化层
池化窗口:2×2 | 步长:2 | 输出:12×12×32
第三层:卷积层
卷积核:64个5×5的滤波器 | 输出:8×8×64 | 激活函数:ReLU
第四层:池化层
池化窗口:2×2 | 步长:2 | 输出:4×4×64
第五层:全连接层
输入:4×4×64 = 1024个神经元 | 输出:128个神经元 | 激活函数:ReLU | Dropout:0.5(防止过拟合)
第六层:输出层
输入:128个神经元 | 输出:10个神经元(对应0-9十个数字) | 激活函数:Softmax
训练过程
- 前向传播:输入图片经过各层计算,得到预测结果
- 损失计算:使用交叉熵损失函数衡量预测与真实标签的差距
- 反向传播:计算梯度,更新网络参数
- 迭代优化:重复上述过程,直到模型收敛
实际效果
经过训练,这个简单的CNN模型在MNIST测试集上可以达到99%以上的准确率。这意味着在10,000张测试图片中,只有不到100张会被错误识别。
代码示例(Python + TensorFlow)
import tensorflow as tf from tensorflow.keras import layers, models # 构建CNN模型 model = models.Sequential([ layers.Conv2D(32, (5, 5), activation='relu', input_shape=(28, 28, 1)), layers.MaxPooling2D((2, 2)), layers.Conv2D(64, (5, 5), activation='relu'), layers.MaxPooling2D((2, 2)), layers.Flatten(), layers.Dense(128, activation='relu'), layers.Dropout(0.5), layers.Dense(10, activation='softmax') ]) # 编译模型 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 训练模型 model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels))
CNN的优势与挑战
优势
- 自动特征提取:无需人工设计特征,网络自动学习
- 平移不变性:无论物体在图像中哪个位置,都能被识别
- 参数共享:大幅减少参数量,提高训练效率
- 层次化表示:从低级边缘到高级语义,逐层抽象
挑战
- 需要大量数据:训练高质量CNN通常需要海量标注数据
- 计算资源密集:GPU/TPU加速几乎是必需的
- 黑盒问题:难以解释网络为何做出某个决策
- 对抗攻击脆弱:微小的扰动可能导致错误分类
未来展望
CNN技术仍在快速发展:
- 更高效的架构:MobileNet、EfficientNet等轻量级模型
- 自监督学习:减少对标注数据的依赖
- 可解释性研究:让CNN的决策过程更加透明
- 多模态融合:结合文本、音频等多种信息源
结语
从理论公式到实际应用,CNN已经成为人工智能领域最重要的技术之一。无论是自动驾驶汽车、医疗诊断系统,还是我们每天使用的手机面部解锁,背后都有CNN的身影。随着技术的不断进步,CNN将在更多领域发挥重要作用,推动智能化时代的到来。
理解CNN不仅有助于我们更好地使用这项技术,更能启发我们思考如何让机器像人类一样"看"懂这个世界。
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号