牛!一款国产AI语音登顶全球第一,首个可编辑语音模型来了!

牛!一款国产AI语音登顶全球第一,首个可编辑语音模型来了!

开源星探
发布于 2026-07-03 12:56:34
发布于 2026-07-03 12:56:34
在当今的内容创作领域,语音合成技术已经成为了不可或缺的生产力工具。
无论是短视频配音、有声书制作,还是游戏角色语音生成,AI语音都在深刻改变着我们的创作方式。
但长期以来,这个领域一直被国外巨头所主导。从早期的Google TTS,到后来的ElevenLabs,再到 OpenAI 的 Whisper 系列。
不过最近,一款名为 ViiTorVoice 的国产模型横空出世,彻底打破了这个局面。
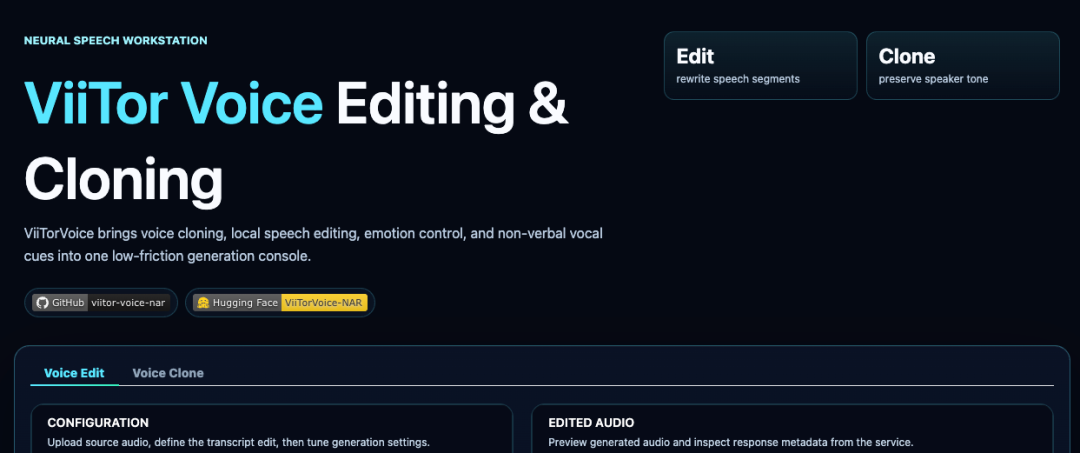
它不仅在全球权威评测榜单 Seed-TTS 上登顶第一,更以首创的"局部编辑"能力,重新定义了语音合成的可能性。
🏆 全球第一的成绩单
在当前业界最严苛、公认度最高的TTS标准评测Seed-TTS中,ViiTorVoice交出了一份惊艳的成绩:
- • 英文词错率(WER):1.32
- • 中文词错率(WER):0.99
特别值得一提的是,ViiTorVoice在中文词错率指标上取得了当前公开评测的最佳成绩,成为全球首个中文词错率突破1.0大关的里程碑模型。
这意味着它在发音准确性和语义还原能力方面,已经达到了行业领先水平。
🎯 核心能力
ViiTorVoice-NAR是一个面向语音克隆与语音局部编辑的非自回归语音生成系统。
它的核心能力远不止简单的语音克隆,而是一套完整的语音创作解决方案。
语音克隆:无参考文本也能克隆
传统的语音克隆需要提供一段说话人的音频,以及对应的准确文字内容。但ViiTorVoice首创了"无参考文本(Zero-Shot)"的跨语种语音克隆能力,你只需要上传一段声音样本,就能直接生成任意文本的语音。
你不需要知道具体说了什么,只需要截取这段音频,就能让AI用这个声音说出任何你想要的内容。
局部编辑:像改Word一样修语音
这是ViiTorVoice最革命性的功能。在真实的生产环境中,更耗费时间的往往不是第一次生成,而是后期修改。
比如:
- • 短剧已经完成配音,上线前发现角色人名需要调整
- • 广告文案临时修改了产品名称
- • 课程内容更新了一个专业术语
重新生成一句新的配音并不难,真正耗时耗力的,是如何让修改后的内容与原有音频保持一致,尤其在音色、情绪衔接、停顿突兀、时间轴同步这些细节上。
ViiTorVoice的片段级编辑能力,完美解决了这个难题。
你可以任意替换某个词、某句话、某个片段,就像在Word里修改文字一样简单。系统会自动定位差异区域,只重新合成局部片段,前后过渡天衣无缝。
情感与副语言控制:让声音更有戏
优秀的配音不仅仅是念对文字,更重要的是传递情感和表达细节。
ViiTorVoice支持在文本条件中插入情感标签和副语言信息,并通过CFG(Classifier-Free Guidance)参数增强控制效果。
你可以这样使用:
<|emotion-happy|>我终于完成了这个项目,感觉真的很开心。
<|emotion-sad|>听到这个消息,我感到非常难过。这种细粒度的情感控制,让AI生成的语音不再是冷冰冰的机械音,而是充满了人情味和表现力。
低延迟推理:实时互动不再是梦
在实时交互场景中,延迟是致命的。ViiTorVoice采用非自回归架构,支持first block推理模式,端到端首帧返回时间可以做到约60ms,5秒音频可以在100ms内生成,推理速度达到40倍实时。
📦 快速上手
下面是完整的安装和使用指南。
环境准备
首先,确保你的系统满足以下要求:
- • Python 3.8+
- • 支持CUDA的GPU(推荐NVIDIA GPU,显存8GB以上)
- • Linux或macOS系统
步骤一:克隆项目并安装依赖
git clone https://github.com/viitor-ai/viitor-voice-nar.git
cd viitor-voice-nar
bash init_env.shinit_env.sh脚本会自动创建虚拟环境并安装所有依赖,非常省心。
步骤二:下载模型
模型文件需要下载到local_models/目录下,不要使用软链接。
mkdir -p local_models
huggingface-cli download ZzWater/ViiTorVoice-NAR \
--local-dir local_models \
--local-dir-use-symlinks False模型地址:https://huggingface.co/ZzWater/ViiTorVoice-NAR
步骤三:启动服务
./run_grpc_v2.sh start all服务启动后,可以通过以下命令查看状态:
./run_grpc_v2.sh status all默认HTTP服务监听在0.0.0.0:7861,本机访问地址为http://127.0.0.1:7861。
API调用示例
健康检查
curl "http://127.0.0.1:7861/health"语音克隆(无参考文本)
curl -X POST "http://127.0.0.1:7861/v1/voice-clone" \
-F 'ref_audio=@prompt.wav' \
-F 'text=今天天气不错,我们下午一起去公园散步吧。' \
-F 'language=zh' \
-F 'allow_missing_ref_text=true' \
--output clone.wav情感控制
curl -X POST "http://127.0.0.1:7861/v1/voice-clone" \
-F 'ref_audio=@prompt.wav' \
-F 'text=<|emotion-happy|>I finally finished the project, and I feel really happy.' \
-F 'language=en' \
-F 'emotion_guidance_scale=6.0' \
-F 'nvv_guidance_scale=2.0' \
--output clone_emotion.wav局部编辑
curl -X POST "http://127.0.0.1:7861/v1/text-local-edit" \
-F 'source_audio=@source.wav' \
-F 'original_text=Please send the meeting notes before Friday.' \
-F 'edited_text=Please send the meeting notes before Monday.' \
-F 'language=en' \
-F 'align_granularity=word' \
-F 'expand_mask_ratio=1.5' \
-F 'output_format=wav' \
--output edited.wav🌟 适用场景
ViiTorVoice的强大能力,让它在多个领域都有广泛的应用前景:
影视娱乐
- • 游戏角色配音:快速生成不同性格的角色语音
- • 动画配音:为卡通角色赋予独特的声音
- • 影视后期:补录台词、修改配音内容
教育培训
- • 有声书制作:快速将文字转换为高质量音频
- • 多语言课程:一键生成多语种教学音频
- • 语言学习:提供标准发音示范
内容创作
- • 短视频配音:快速为视频添加旁白
- • 播客制作:生成主持人语音
- • 虚拟主播:打造个性化的AI主播声音
商业应用
- • 客服语音:定制企业专属客服声音
- • 智能助手:为智能设备提供个性化语音
- • 广告配音:快速生成广告语音
写在最后
ViiTorVoice-NAR 的出现,更以创新的"局部编辑"能力,为语音合成领域带来了革命性的变化。
它让我们看到,中国的 AI 技术正在某些领域实现弯道超车,走在世界前列。
GitHub:https://github.com/viitor-ai/viitor-voice-nar
模型:https://huggingface.co/ZzWater/ViiTorVoice-NAR
Demo:https://huggingface.co/spaces/ZzWater/ViiTorVoice
如果本文对您有帮助,也请帮忙点个 赞👍 哈!❤️
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号