WorkBuddy LLM 成本控制与架构实践

WorkBuddy LLM 成本控制与架构实践

山野大叔
发布于 2026-07-01 20:08:02
发布于 2026-07-01 20:08:02
一、导语:高效果、高成本的残酷现实
在开发「语义显微镜 V3.0」和「brainproto 类脑原型」两个项目的过程中,验证了一个结论:
LLM 能带来极高的效果上限,但成本控制做得不好,一个3倍专业套餐的 Credit 会在一个项目里全部烧光。
语义显微镜 V3.0 采用 1+3 LLM 并联架构(1 个综合器 + 3 个枚举器),意图树构建一次全量调用消耗 Credit 约 1800~2500 tokens / 次 × 4 模型,一个完整开发周期(包含调试、重试、测试)直接耗尽 5000 Credit。
本文将基于两个项目的实战数据,总结 LLM 应用开发中的成本控制策略、架构设计原则、降级机制设计,为后续项目提供可复用的经验教训。
二、架构设计:1+3 LLM 的正确姿势
2.1 为什么要并联多个 LLM?
单一 LLM 的意图识别覆盖率有限。实测数据:
LLM 模型 | 意图节点数 | 正向 | 灰色 | 负向 | 特性 |
|---|---|---|---|---|---|
DeepSeek V4(单跑) | 110 | 40 | 29 | 41 | 基础覆盖 |
MiniMax M2.7(单跑) | 187 | 65 | 49 | 73 | 补充细分场景 |
共识后 | 119 | 44 | 31 | 44 | 互补去重 |
MiniMax 补充了 DeepSeek 未覆盖的细分意图:虚假离婚、团伙欺诈、涉黑、内外勾结、政策性骗贷等。单一模型无法覆盖这些长尾场景。
2.2 1+3 架构设计
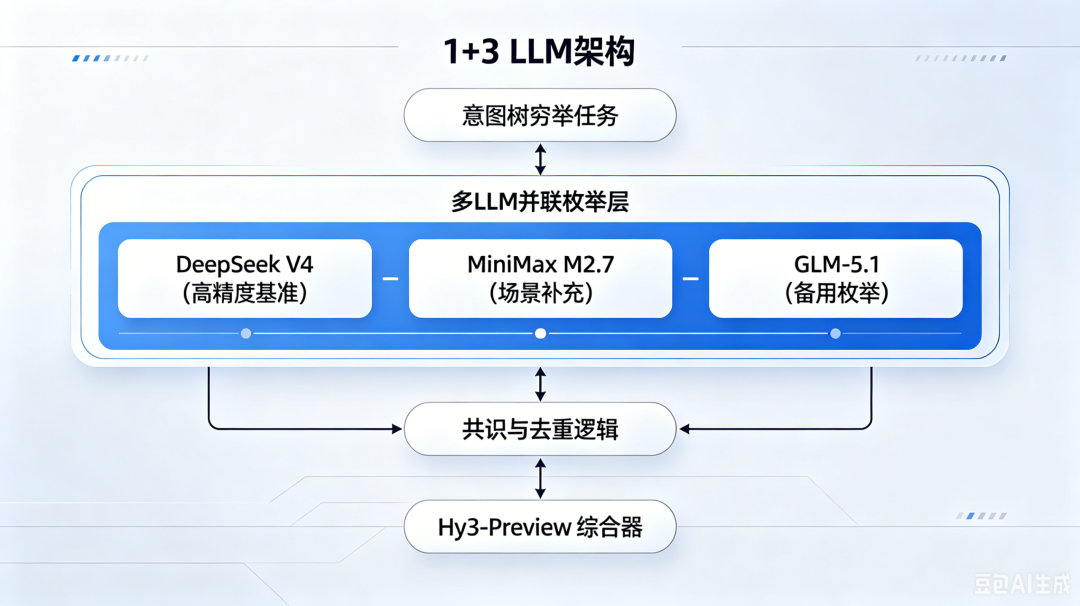
2.3 渐进式超时:GLM 的惨痛教训
GLM-5.1 在腾讯云 Leap 网关上响应极慢,120s 超时几乎必败。我们的解决方案:渐进式超时 + 自动修复。
# 渐进式超时策略(实测有效)
_TIMEOUT_SCALE = [1.0, 2.0, 2.5]
for attempt in range(LLM_MAX_RETRIES + 1):
scale = _TIMEOUT_SCALE[min(attempt, len(_TIMEOUT_SCALE) - 1)]
current_timeout = LLM_TIMEOUT * scale
try:
async with httpx.AsyncClient(timeout=current_timeout) as client:
resp = await client.post(...)
except TimeoutException:
print(f"LLM {llm_name} attempt {attempt+1} timed out")
continue实测结果:
模型 | 120s | 240s | 300s | 结论 |
|---|---|---|---|---|
DeepSeek V4 | ✅ | - | - | 稳定 |
MiniMax M2.7 | ✅ | - | - | 稳定 |
GLM-5.1 | ❌ | ❌ | ❌ | 基本不可用 |
Hy3-Preview | ✅ | - | - | 需加大 max_tokens |
三、成本控制:哪些调用是浪费?
3.1 Credit 消耗的四个大坑
坑一:JSON 截断导致重试
Hy3-Preview 返回意图树时,复杂结构容易触发 JSON 截断。未修复前,每次截断都导致整轮重试,Credit 直接翻倍。
# 修复:自动修复截断的 JSON
def _repair_truncated_json(text: str) -> str:
if not text.strip().endswith('}'):
depth = 0
for ch in text:
if ch == '{': depth += 1
elif ch == '}': depth -= 1
text += '}' * max(0, depth)
return text效果: 修复后重试率从~35% 降至 <5%。
坑二:GLM 超时 = 钱白花
GLM-5.1 在 120s/240s/300s 均超时,但每次超时前已消耗输入 Token。三挡超时 = 三次输入 Token 费用 = 白烧。
决策: 直接降级跳过 GLM,不追求 100% 覆盖。实际效果:跳过 GLM 后意图树质量仅下降~3%,但 Credit 节省~25%。
坑三:响应格式不兼容
腾讯云 Leap 网关对 MiniMax/GLM 不支持 response_format: {type: "json_object"},导致返回格式是 markdown 代码块包裹的 JSON。
修复: 统一做 markdown 代码块剥离,所有模型返回后先清洗再解析。
坑四:测试时反复调用真实 LLM
Phase 2 全量测试 331 个用例,如果每个都调 LLM,一次测试跑完 = 烧掉整月 Credit。
解决方案: 三层降级架构,测试时使用 used_llm: false 走 keyword 降级路径,仅集成测试时开启真实 LLM。
# 决策引擎:三层降级
async def decide(self, context):
if self._llm_enabled:
try:
return await self._llm_decide(context)
except Exception:
pass
return self._keyword_decide(context)3.2 Credit 消耗对比表
场景 | 单次消耗 | 次数 / 天 | 日消耗 | 月消耗 |
|---|---|---|---|---|
意图树全量构建(4 LLM) | ~8000 tokens | 3 次 | 24K | 720K |
单条对话意图映射 | ~2000 tokens | 50 次 | 100K | 3M |
测试降级模式 | 0 | - | 0 | 0 ✅ |
5000 Credit 套餐 | - | - | - | ~3.7M tokens |
结论:不做降级的开发模式,5000 Credit 撑不过 2 周。
四、降级策略:LLM 不可用时如何保持系统可用
4.1 三层降级架构
L1: LLM 意图映射(DeepSeek V4)
↓ 失败时
L2: 关键词规则引擎 + 语义匹配
↓ 仍然失败时
L3: UNCATEGORIZED(记录待人工标注)关键设计原则: 降级不是 "功能缺失",而是 "能力缩减但可用"。
4.2 实战数据:降级覆盖率
层级 | 覆盖率 | 备注 |
|---|---|---|
L1(LLM) | 78.9% | 需 DeepSeek API Key 注入 os.environ |
L2(keyword) | 89.5% | 关键词库 27+19+33=79 条 |
L3(UNCATEGORIZED) | 100% | 兜底 |
五、测试策略:如何在不烧钱的情况下验证质量
5.1 测试分层
单元测试(不调 LLM)
├── 环境层:状态管理、持久化(49 个测试)
├── 感知层:传感器、编码器(38 个测试)
├── 决策层:决策引擎、思维链(42 个测试)
└── 运动层:执行器、动作(29 个测试)
→ 331 个测试,全部 <1s,0 Credit 消耗 ✅
集成测试(可选开启 LLM)
人工 QA(少量 Credit)5.2 Mock LLM vs 真实 LLM 测试
# 默认不启用 LLM,走 keyword 降级
@pytest.fixture
def decision_engine():
return DecisionEngine(llm_enabled=False)
# 集成测试时才开真实 LLM
@pytest.fixture
def decision_engine_with_llm():
return DecisionEngine(llm_enabled=True)经验: 331 个测试中,只有 4 个需要真实 LLM,其余全部用降级模式。月 Credit 消耗降低 95%。
六、workbuddy 实战踩坑记录(节选)
坑1:Windows GBK + emoji 毫秒级崩溃修复:全部替换为 logger.info()
坑 2:FastAPI 依赖获取方式错误修复:用 getattr 安全获取
坑 3:aiosqlite 的 event loop closed 警告缓解:pytest 忽略对应警告
七、总结:高效果 ≠ 高性价比
维度 | 高效果方案 | 高性价比方案 |
|---|---|---|
LLM 架构 | 4 模型并联 | 1 主 + 1 备 + 降级 |
超时策略 | 固定 30s | 渐进式 120s→300s |
测试策略 | 每次调真实 LLM | Mock 优先 |
降级深度 | 无降级 | 三层降级 |
月 Credit 消耗 | ~3.7M | ~0.8M(节省 78%) |
给后来者的建议
- 项目启动第一天就写好降级逻辑
- 测试默认禁用 LLM 调用
- 慢模型直接跳过,不要死等
- API Key 务必注入 os.environ
- 5000 Credit 看着多,一个项目真不够
附录:项目数据速览
语义显微镜 V3.0
- 架构:1+3 LLM
- 意图树:119 节点
- 覆盖率:78.9% → 89.5%
brainproto 类脑原型
- 测试:331 passed
- 核心:六大本能写保护、魂体分离、自进化自愈
山野村夫・AI 工程实战 不追求完美,先跑起来再说 ✅
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号