AI染色追踪:微服务测试数据“溯源”不再难

AI染色追踪:微服务测试数据“溯源”不再难

AI智享空间
发布于 2026-06-29 14:21:10
发布于 2026-06-29 14:21:10
一、微服务时代,测试数据"丢了"是常态
单体应用时代,排查问题相对简单——一个进程,一份日志,从头读到尾就能定位。
微服务架构把这件事彻底打散了。一笔业务请求,可能要经过网关、用户服务、订单服务、库存服务、支付服务、消息队列、风控服务……每个服务都有自己的日志,自己的数据库,自己的部署节奏。
测试时这个问题尤其突出。你造了一条测试数据,发起一次下单请求,结果在支付服务那一环出了异常。你想知道:这笔数据完整的流转路径是什么?它在哪个服务被处理成了什么样子?是不是和正式流量混在一起,污染了生产数据?
没有追踪机制的情况下,排查这类问题靠的是工程师凭经验,在十几个服务的日志系统里分别搜索一个用户 ID 或订单号,手动拼接出完整链路。慢,而且容易遗漏。
全链路染色追踪,解决的正是这个问题。
二、什么是"染色":给数据贴一张能跟着它走的标签
"染色"这个词,描述的是一种朴素但精确的思路:在测试数据生成的那一刻,给它打上一个独一无二的标记,然后让这个标记在数据流转的每一步都被携带、被记录,最终可以凭这个标记,把分散在各处的痕迹重新拼接成一条完整链路。
这不是新概念。在分布式追踪领域,这套机制有标准化的实现方式,核心是两个要素:
Trace ID(全链路 ID):一次完整业务请求的唯一标识,从请求发起的那一刻生成,贯穿整个调用链路,不会改变。
Span ID(节点 ID):链路中每一个具体调用环节(比如"订单服务调用库存服务"这一次调用)的唯一标识,每经过一个服务节点,生成一个新的 Span,并记录它的"父 Span"是谁——这样就能还原出完整的调用树形结构。
W3C 制定的 Trace Context 标准,定义了这套信息如何在 HTTP 请求头里传递,字段名是 traceparent,格式大致是:
traceparent: 00-{trace-id}-{span-id}-{trace-flags}每个微服务收到请求时,从请求头里读出 traceparent,记录自己的 Span,再把(更新后的)traceparent透传给下一个被调用的服务。只要这条链路上所有服务都遵守这个约定,整条调用路径就能被完整重建。
OpenTelemetry 是目前这个领域最主流的开源标准,提供了跨语言的 SDK,自动给 HTTP 请求、数据库调用、消息队列投递注入和提取 Trace Context,工程师不需要在每个服务里手写传递逻辑。
测试场景下的"染色",在这套标准能力之上,多做了一件事:给测试数据额外打上"这是测试流量"的标识,以便和生产流量彻底区分。
三、测试染色的额外要求:不只是追踪,还要隔离
生产环境的分布式追踪,目标是排查性能问题和故障。测试场景的染色追踪,目标除了排查问题,还有一条更重要的诉求——确保测试数据不会污染生产数据,也不会被生产逻辑误处理。
这通常通过在 Trace Context 之外,额外携带一个"测试标记"实现,典型做法包括:
方式一:专用请求头标记。在请求头里加一个自定义字段,比如 X-Test-Flag: true,所有服务识别到这个标记后,走专门的测试数据处理逻辑——读写"影子表"(Shadow Table,与生产表结构一致但物理隔离的测试专用表),不触发真实的短信/支付等外部副作用。
方式二:数据本身打标。 在订单号、用户 ID 等业务标识里嵌入约定的前缀或后缀(比如测试订单号统一以 T_开头),下游服务通过解析这个约定识别测试数据。这种方式实现简单,但耦合度较高,业务标识规则一旦变化,所有依赖此约定的服务都要同步调整。
方式三:中间件层路由。 在网关或服务网格(Service Mesh)层面,根据染色标记把测试流量路由到专门的测试集群或测试命名空间,从基础设施层面实现物理隔离,业务代码无需感知。
这三种方式各有取舍:专用请求头标记最轻量,但要求所有服务都正确透传;影子表隔离最彻底,但维护两套表结构有额外成本;中间件路由侵入性最小,但需要服务网格基础设施支撑。多数团队会结合使用——用 Trace Context 做追踪,用专用标记做隔离判定,用影子表做数据物理隔离。
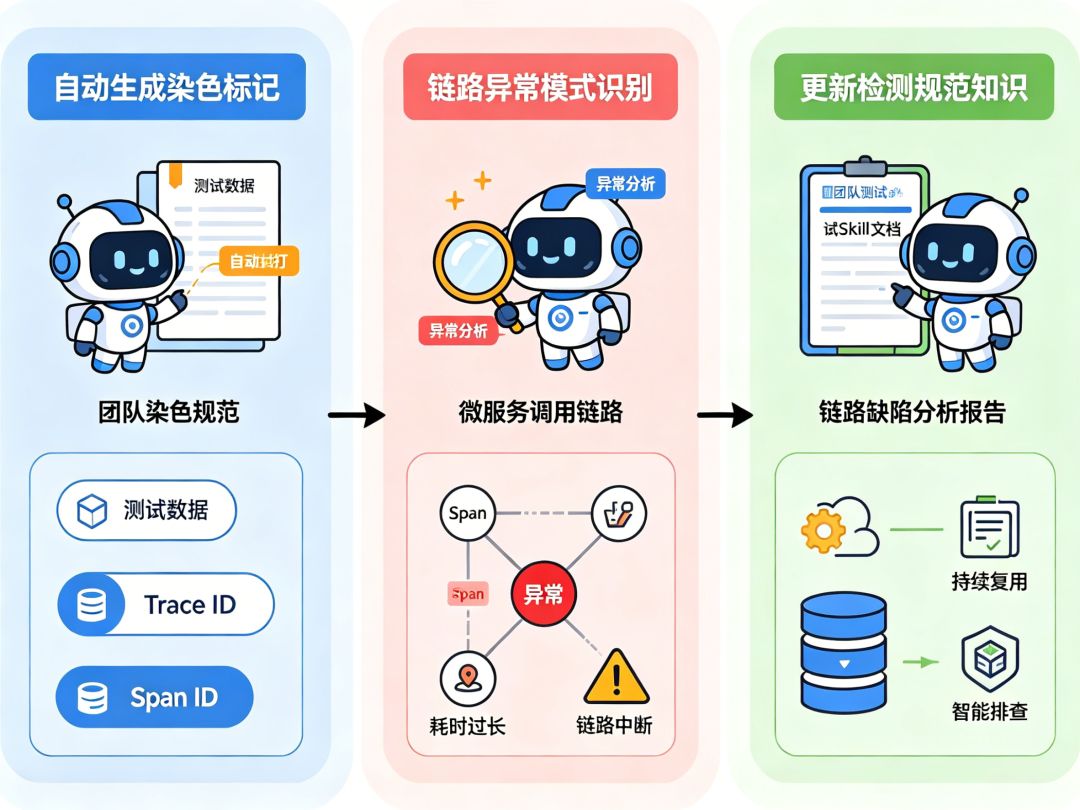
四、AI 在这套机制里,具体做什么
染色追踪的基础设施(Trace Context 传递、影子表、标记透传)本身不依赖 AI,是成熟的分布式系统工程实践。AI 的价值,体现在基础设施之上的三个环节:
第一,自动生成符合规范的染色标记。测试用例数量大、场景多的情况下,人工为每条测试数据手动构造符合规范的染色标记(Trace ID 生成、测试标记注入、影子表路由参数),容易出错且效率低。让 Agent 参照团队的染色规范(写进 Skill 文档,包含标记格式、注入位置、各服务的识别约定),批量生成测试数据并自动注入正确的染色信息,减少人工构造的出错概率。
第二,链路异常的模式识别。一次完整调用链路可能跨越十几个 Span,人工逐条排查效率低。把链路数据交给 Agent 分析,识别异常模式——哪个 Span 的耗时显著偏离历史基线、哪个环节的 Trace 在到达后突然"断链"(说明某个服务没有正确透传 Trace Context)、哪些测试数据的染色标记在中途丢失(说明数据流转过程中可能被某个不合规的服务处理过)。
第三,把发现的链路缺陷,显式化为团队的检测规范。每次发现一个"染色标记丢失"的具体场景——比如某个异步消息队列消费者没有正确透传 Trace Context——这类发现不应该只停留在一次性修复,而应该写进团队的测试 Skill 文档:明确这个服务、这种调用方式,历史上出现过染色丢失,后续测试时要重点关注。这样下次类似场景出现,Agent 能基于历史模式主动排查,而不是每次都从零开始。
五、一个需要正视的局限
全链路染色追踪不是银弹。它解决的是"数据流转路径是否可追溯、测试数据是否被正确隔离"的问题,不解决"业务逻辑是否正确"的问题。
一条染色清晰、链路完整、隔离到位的测试数据,业务结果依然可能是错的——比如优惠券金额算错了,但整条链路追踪和隔离都没有任何异常。染色追踪能告诉你"数据去了哪里、经过了什么",但不能替代对业务结果本身的断言和校验。
把染色追踪当作排查工具和质量基础设施是合适的定位,把它当作测试覆盖率或正确性的保证,是一种误用。
结语:可追溯性,是复杂系统测试的地基
微服务架构带来的复杂度,本质上是"可观测性"的复杂度——系统行为分散在太多节点上,人脑无法直接掌握全貌。
全链路染色追踪,是应对这种复杂度的基础工程实践:给每一笔测试数据一个不会丢失的身份标识,确保它在穿越任意多个服务边界之后,依然可以被重新拼接成一条完整、可读、可分析的链路。
AI 在这套机制里的角色,不是替代分布式追踪的工程基础,而是在基础设施之上,把"批量生成染色标记"和"链路异常分析"这两件原本依赖人工的重复性工作接管过来,并且把每一次发现的链路缺陷,转化为团队可以持续复用的检测知识。
基础设施决定了你能不能追踪到数据,知识资产决定了你能多快发现问题在哪里。两者缺一不可。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号