9|我以为RAG就是接个知识库,结果连踩7个坑。

9|我以为RAG就是接个知识库,结果连踩7个坑。

靖扬
发布于 2026-06-29 14:12:36
发布于 2026-06-29 14:12:36
我叫张小米,AI产品经理。
上一个项目做完,我以为自己多少算懂AI了。
然后老板把我叫进会议室,说要给销售团队做一个AI助手。
“销售每天都在回答差不多的问题,能不能让AI来答?对了,下个月季度汇报,我想在会上展示这个,你来搞。”
我点头点得很用力,像是真的知道该怎么搞。
出了会议室,我在走廊站了三分钟。
我不知道从哪儿开始。
时间只剩1个月。
01 AI为什么连公司规则都敢编
时间紧,我没想太多,直接接了一个大模型API,搭了个对话框,扔给销售试用。
当时我想得挺简单:现在的大模型什么都能聊,回答几个产品问题,应该不难吧。
我折腾了两天搭好,又让销售试用了两天。第四天,销售总监老李发来一张截图,下面跟着一句话:
“它跟客户说可以免费试用90天。我们明明只有14天,谁答应的?”
我盯着那条消息看了一会儿。
它答得很完整,语气也很专业。唯一的问题是,整句话都是编的。
我搭的那个东西,连我们怎么卖都不知道,就敢替公司答应客户。
距离汇报还有26天。
我拿着截图去找技术同事老王。
他看了一眼:“它又没看过我们的试用规则,当然不知道是14天。只能根据以前见过的同类产品,猜一个听起来最像答案的答案。”
“那怎么办?”
“给它接一个知识库。回答之前先查公司资料,这个方案叫RAG。”
“要多久?”
“你先把产品文档、FAQ、报价规则整理出来。我来搭,三天。”
📌 什么情况下需要RAG? 大模型默认看不到你公司的最新资料和内部信息。问它产品参数、报价规则,它有时会给出一个“听起来很合理”,实际却是编出来的答案——这就是常说的“幻觉”。 AI不知道公司的事,但资料又多到不能每次全部塞给它——这时候就该RAG出场了。
02 RAG到底怎么工作
三天后,老王把我叫到白板前,画了三个框。
用户提问、知识库、大模型。
“平时直接问AI,它只能根据自己原来学过的内容生成答案,里面没有我们公司的最新资料。RAG就是在中间多加一步:先去知识库里找,找到相关内容以后,再把资料和问题一起交给大模型。”
我问:“那直接把所有文档都扔给AI,不行吗?”
“几百份文档,每问一个问题就全部塞进去?又慢又贵,它还不一定找得准。RAG只取和这个问题有关的几段。”
我看着白板,大概明白了。
原来AI不是突然变懂了,只是回答之前,终于知道先翻资料了。
我们把几百份产品文档导进知识库,重新上线。
老李测了一轮,反馈只有三个字:“好多了。”
产品参数、交付周期,基本都能答对。
还有23天,进度比我预想得快。我甚至开始觉得,接下来应该能顺一点了。
📌 RAG是什么? RAG = 检索增强生成(Retrieval-Augmented Generation) 核心流程只有三步:用户提问 → 去知识库检索相关内容 → 把检索结果和问题一起交给大模型生成答案。 一句话概括:给AI装一双眼睛,让它先查公司自己的资料,再开口回答。 这里最关键的不是“存了多少文档”,而是用户提问时,系统能不能从一堆资料里找出真正相关的那几段。
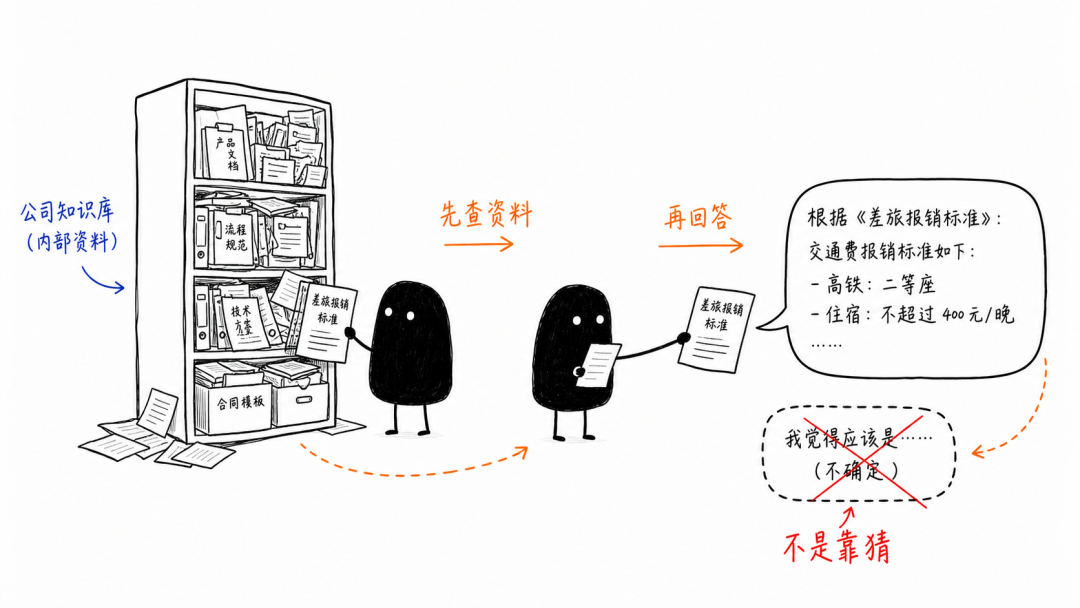
RAG先查资料再回答
03 搜出来的东西不对
上线第二天,我正在整理测试用例,销售小周来找我。
“我问它‘我们产品支持哪些对接方式’,它给我答了一堆售后流程。”
我去后台翻记录。
知识库里有一份售后文档,刚好出现过“对接”两个字,系统就把它搜了出来。
字对上了,意思完全没对上。
我有点烦。这种问题,我自己测试的时候根本没想到。
还有22天。
我把截图发给老王,他回了四个字:“换向量检索。”
“这又是什么?”
“现在这版主要看关键词。向量检索不只看字面,还会看意思。你搜‘对接方式’,它也能找到写着‘集成方法’的文档,因为两句话表达的是同一件事。”
“今天能好吗?”
“能。”
当天切换,小周重新测了一遍,终于答对了。
📌 关键词检索、向量检索和混合检索 关键词检索:看字面,像在文档里按`Ctrl+F`。优点是精确,缺点是死板。搜“集成方式”,不一定能找到写着“对接方法”的文档。 向量检索:先把文字转成一组数字,这个过程叫`Embedding`。意思越接近的内容,在数学空间里的位置也越近。 所以,向量检索找的不是“字一不一样”,而是“意思像不像”。 两种方式各有盲区。实际项目里,经常会让关键词检索和向量检索同时工作,再把两边的结果合在一起,这就是混合检索:一个负责认字,一个负责认意思。
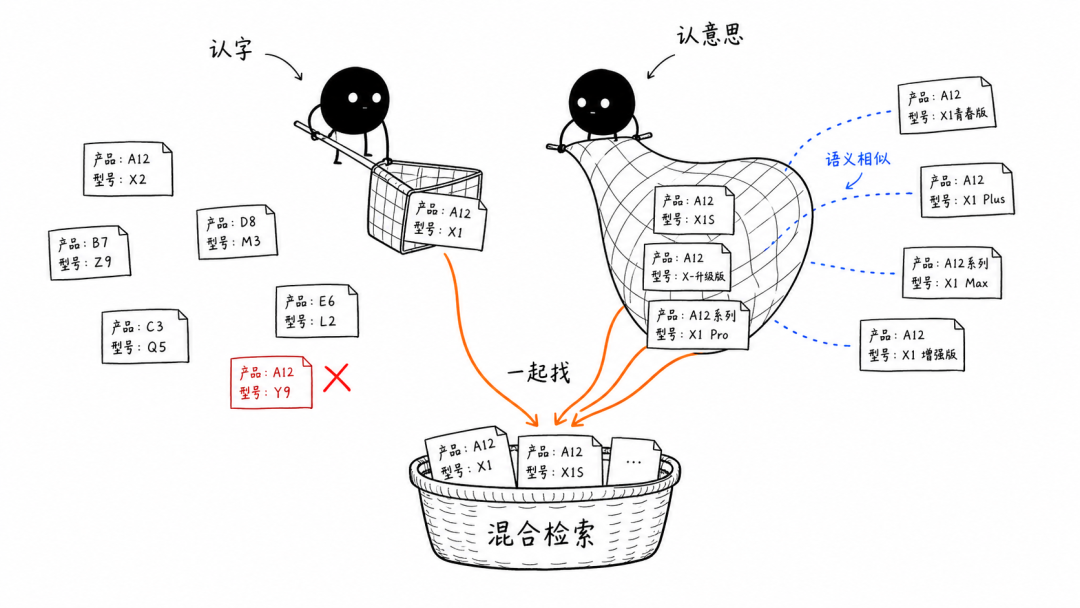
关键词检索和向量检索一起工作
04 型号对了,版本却答错了
向量检索上线第三天,销售小张又来了。
“我问‘XX-Pro版本支持多少并发’,它给我答的是标准版参数。”
我翻了一遍记录。
“XX-Pro”和“XX标准版”的资料都被搜了出来。两份文档写的又都是并发参数,系统根本不知道该把哪一份挡在外面。
但产品版本这种东西,差一个词,就是两套参数。
还有19天,老板下周就要看进度。
我把截图发给老王,只说了一句:“又出问题了。”
老王看完说:“这次不是没搜到,是检索之前没有先划范围。Pro版和标准版的资料都在一个池子里,它当然可能拿错。”
“那怎么分?”
“给文档加标签。产品型号、套餐类型、所属业务线,都提前标清楚。用户问XX-Pro,就先把标准版过滤掉,再去剩下的资料里检索。”
“这个也有名字?”
“元数据过滤。”
“还能赶上吗?”
“我来改。”
补完元数据以后,小张又问了一遍。系统先锁定XX-Pro,再从这个版本的资料里找并发参数,这次终于答对了。
老板那周看进度,我把数据发过去。他回了一个“好”。
虽然只有一个字,我还是松了口气。
📌 元数据:先划范围,再检索 元数据,可以简单理解成贴在文档外面的标签。它不负责回答问题,而是告诉系统:这份资料属于哪个产品、哪个套餐、哪条业务线。 元数据过滤:正式检索之前,先按照这些标签缩小范围,再到符合条件的资料里找答案。 例如用户问“XX-Pro支持多少并发”,系统先用元数据排除标准版,再到XX-Pro的资料里检索。这样不是让AI“猜得更准”,而是从一开始就不让它去错误的范围里找。
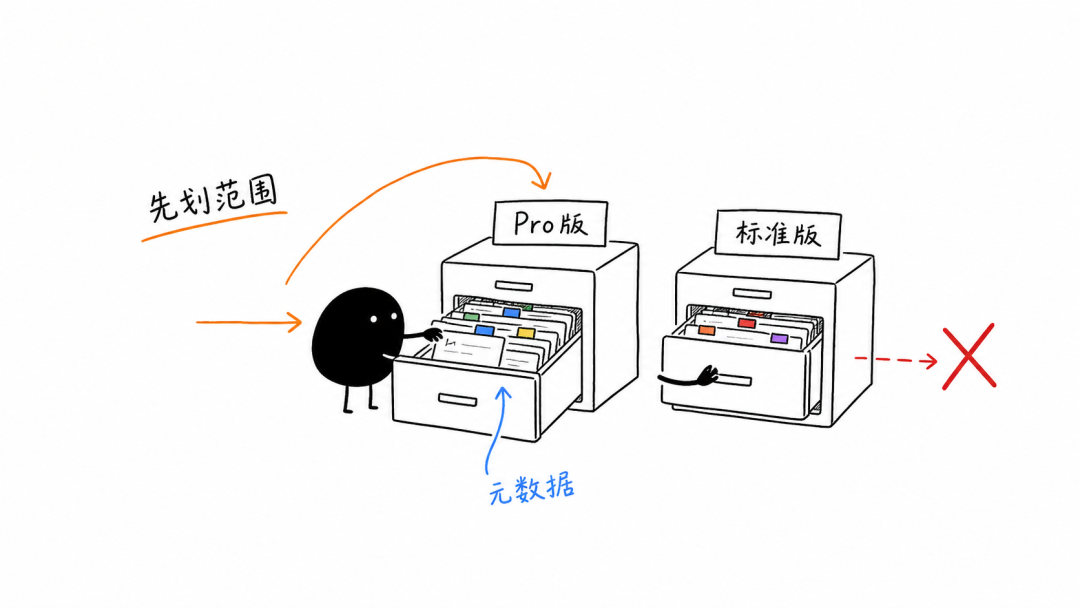
用元数据先划定检索范围
05 销售问问题太随意了
版本混淆的问题解决后,我跟老板汇报了进度。他点点头,说:“继续。”
还有14天,我开始觉得这事有点稳了。
然后销售那边开始放飞自我。
“上次那个方案里的那个功能,客户问能不能定制?”
“跟XX竞品比,我们强在哪?”
“客户问标准交付周期是多久,有没有现成说法?”
我去后台看记录,这几条要么搜不到,要么搜出来的内容跟问题没什么关系。
老王看完,说:“问得太口语了,检索不知道该抓哪个重点。可以先加一步查询重写,让AI把问题整理清楚,再去搜。”
“那三个‘那个’也能整理清楚?”
“信息本来就缺了,整理不出来。这个得让它追问用户。查询重写只能把已有的信息说清楚,不能凭空猜。”
加完这一步,竞品对比和交付周期问题都能正常检索了。至于“上次那个方案”,系统会先反问一句:你说的是哪份方案?
至少它不再硬猜了。
📌 搜不到结果怎么办——查询重写 用户说话往往比较口语,表达不完整,检索系统不一定知道该搜什么。 查询重写:在检索之前,先用大模型把用户的问题整理成更完整、更适合搜索的说法,再去知识库里查。 例如:“跟XX竞品比我们强在哪?”可以改写成:“我方产品与XX产品的主要差异和优势是什么?” 但如果用户说的是“那个方案里的那个功能”,缺少的信息仍然需要追问。查询重写能把话说明白,不能把不知道的事实编出来。
06 搜出来十条,有八条是旧的
还有10天,我打算这周做完最后一轮测试,下周收尾。
汇报提纲刚写完第一页,老李又来了。
“它回答竞品对比的时候,把三年前的老资料翻出来了。那个产品线早升级了。”
我去后台一看,新版、旧版都在知识库里。系统确实找到了“相关资料”,但它不知道哪份已经不能用了。
老王说:“先用前面加的元数据,把旧版本标记成失效,不让它继续参与检索。剩下的结果也不能直接全塞给大模型,还得重新排一次,只留下最相关的几条。”
“这个又叫什么?”
“重排序。”
我看了眼倒计时,已经懒得吐槽这些不断冒出来的新名词了。
旧资料过滤掉,剩下的内容重新排序。老李又测了一遍,这次终于用上了新版资料。
还剩7天。
我第一次觉得,这事真能成。
📌 结果太多怎么办——重排序 旧资料可以用前面讲过的元数据过滤掉。但检索剩下的结果里,仍然可能混着很多“沾边但不够相关”的内容。 重排序:对检索结果重新评分,把相关性更高的排在前面,只取最相关的几条交给大模型回答。 元数据过滤解决“这份资料还能不能用”,重排序解决“能用的资料里,哪几段最相关”。
07 老板在汇报前5天加了需求
剩5天,我已经开始准备汇报材料了。
功能截图、数据对比、演示脚本,我列了一张清单,准备一项项收尾。
老板又找我谈话。
“销售反馈这个AI挺好用。我在想,汇报的时候能不能再加一个亮点?把合同模板、招标文件、法律条款也导进去,让销售问合同问题的时候也能查。”
我看着他,没有马上说话。
5天。合同文件。一份一万字起步。
我在心里算了一遍,没算出来。
老板还在等我回答。
“我先确认一下可行性,今天给你答复。”
出了办公室,我直接去找老王。
他问:“最大的文档多长?”
“将近三万字。”
“要做分块。整份直接放进去,检索一个条款,可能连前言、付款方式、保密条款一起捞出来。”
他停了一下。
“五天够,但得现在开始。”
📌 文档太长怎么办——分块 长文档整份入库,检索时很容易带出大量无关内容,所以通常要先把它切成更小的内容块。 语义分块:按照内容的自然边界切,比如一个合同条款、一个问答对为一块。每一块的意思相对完整,通常优先使用。 长度分块:按照固定字数切,操作简单,但可能从一句话中间切断。一般会设置重叠区,让前后两块重复一小段,避免关键信息刚好掉在切口上。 块太大,搜出来全是噪音;块太小,前后意思又容易断掉。
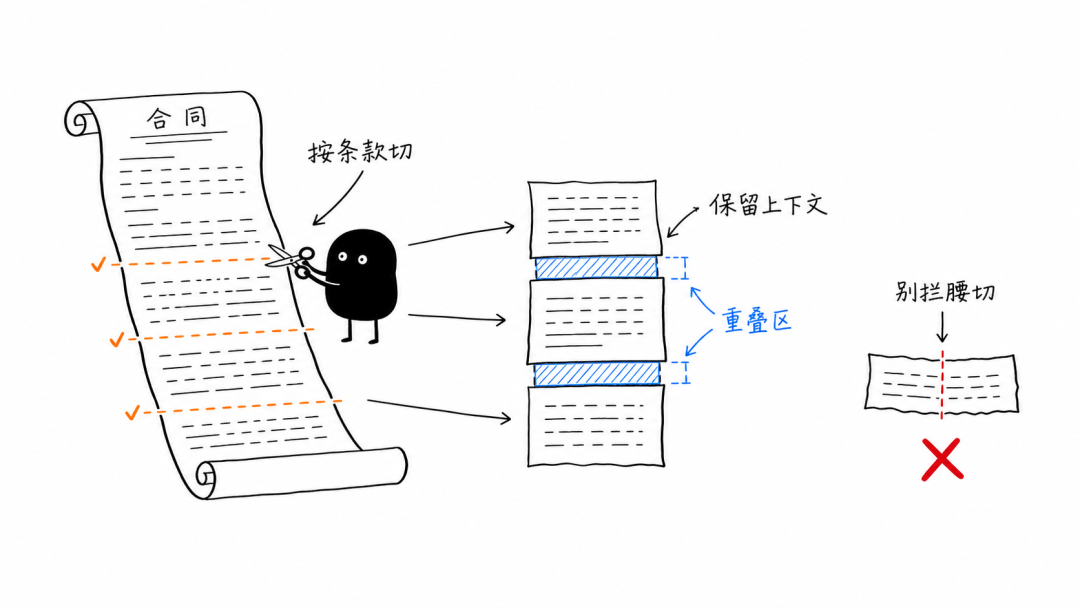
长文档需要按语义分块
汇报当天上午,合同知识库上线。
我们提前定了一条边界:它只负责找到相关条款、展示原文和出处,不做法律判断,也不替销售向客户承诺。
销售问:“违约金怎么算?”
系统准确找到了违约条款,给出答案,还带着原文出处。
下午汇报,老板现场演示了这个功能。销售总监临时追问了两个问题,也都答对了。
散会后,老板发来四个字:“干得不错。”
我看了一眼日历,今天是第30天。
手机放下去,我才发现手心全是汗。
写在最后
七关,30天。
做这个项目之前,我以为RAG就是给AI接一个知识库。
做完以后才知道,知识库接上只是开始。
先让它找到资料,再决定按字找还是按意思找;用户的问题说不清,要先改写或者追问;资料搜多了,要过滤、排序;文档太长,还要切成合适的块。
每一关,都是上一关解决以后,才冒出来的新问题。
如果你也在做一个需要AI查资料、回答问题的项目,这几关大概率都会碰到。
张小米已经替你踩过一遍。
希望你再听到RAG的时候,想到的不只是一串英文,而是这件很具体的事:
先让AI找到对的资料,再让它开口。
这是「普通人 AI 转型 30 问」第 9 问。
下一问,我们讲:Agent 到底是什么?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号