DeepSeek 太快了!


6月份快要过完了,居然没有等到 DeepSeek 新模型发布。
不过昨天在官网对话,发现 DeepSeek 回答速度极快,几乎是刚按下回车键,马上开始输出。

原来是 DeepSeek 发布了一个叫 DSpark 的框架,推理生成速度提升了 60% 到 85%。
什么是DSpark 框架?
它是一个推测性解码模块。
假设你是一位总工程师,每写一行代码都要亲自审批。
推测性解码的思路是:雇一个实习生先写几行草稿,总工程师看一眼,对的直接批准,不对的自己重写。
这样一来,审批次数从 100 次降到了 20 次。
这就是推测性解码的本质:找一个"草稿模型"快速生成候选 token,大模型批量验证。
DSpark 的两个创新
投机解码本身不是新概念。
但把它做到生产环境里、并且大规模部署,DSpark 做了两件以前没人做好的事。
第一件:半自回归生成架构。
传统的草稿模型分两派。
并行派:一次猜一排字,快,但后面的容易猜错。
串行派:一个字一个字猜,准,但慢。
DSpark 的策略是:我都要。
主体上还是并行生成,但每个 block 内部,让 token 之间互相看一眼再出结果。
这样既保留了并行的速度,又把猜错率压下去了。
第二件:置信度调度验证。
原来的投机解码有个问题:草稿猜出来的字,不管好坏,全送去大模型验证。
但在高并发时段,GPU 算力是最贵的资源。
把一堆大概率被"退货"的字也排队送去验证,就是算力浪费。
DSpark 加了一个"置信度头",让草稿在猜字的同时,也给每个字打个分:这个字活下来的概率是多少?
还有一个实时调度器,监控当前 GPU 的负载状态,动态决定到底验证几个字。
高负载时少验,保住整体吞吐。
低负载时多验,榨干单请求性能。
根据当时那几毫秒的硬件状态,给每个请求量身定做最优方案。
架构解析
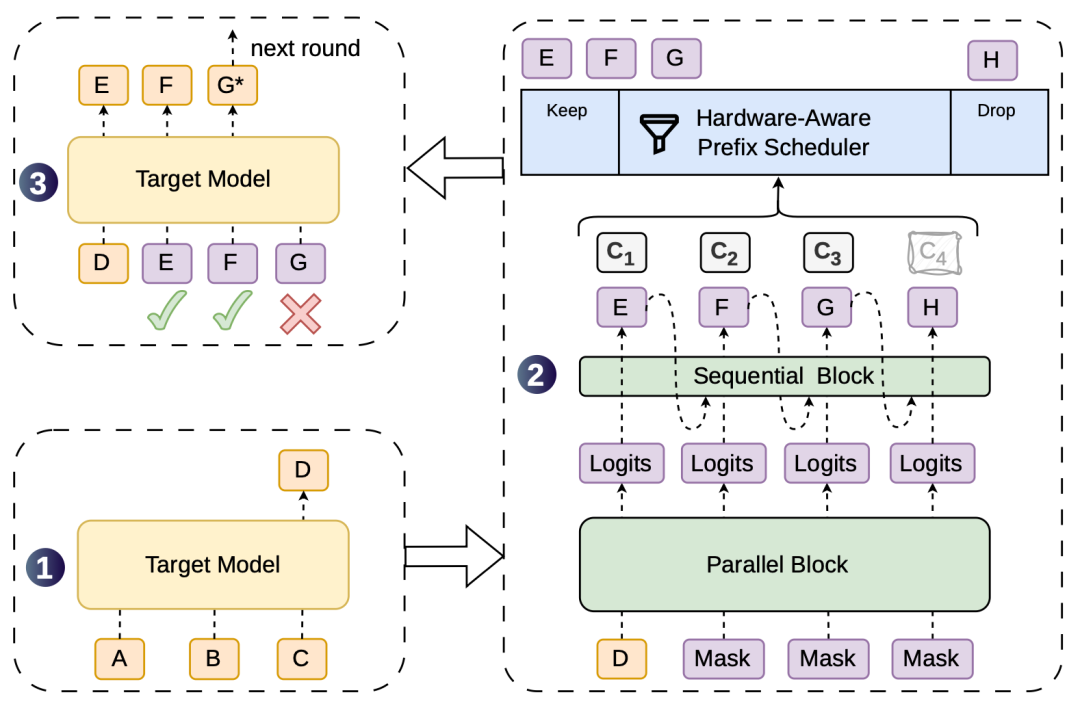
DSpark 架构图
步骤 1:目标模型先执行一步,生成第一个 token D,草稿阶段的"锚点"。
步骤 2:以 D 为输入,DSpark 启动并行主干网络生成草稿 token EFGH,同时通过轻量级的串行头计算每个 token 的置信度 c1-c4。
步骤 3:Hardware-Aware Prefix Scheduler 评估这些置信度,决定保留哪些、丢弃哪些。
图上可以看到:EF 被保留,G 被拒绝,H 直接被丢弃。
最后目标模型并行验证被调度的前缀,E 和 F 通过,G 被拒后模型生成修正版 G* 来完成这一轮。
这个流程不断循环,每轮都有新的 token 被确认。
实测数据
相比于前一代部署的单 Token 基准(MTP-1),在维持相同总体吞吐量的情况下:
- • Flash 模型:生成速度提升 60%-85%
- • Pro 模型:生成速度提升 57%-78%
跟其他投机解码方案比,在 Qwen3 系列(4B、8B、14B)上的测试中:
- • 比 Eagle3 提升 26.7%-30.9%
- • 比 DFlash 提升 16.3%-18.4%
"平均接受长度",是指草稿模型生成的 token 里,有多少被目标模型接受的比例。
接受率越高,无效计算越少,速度就越快。
DSpark 已经在官网上线,怪不得昨天我跟它对话时,回答的速度惊到了我,感觉是不假思索就开始回答。
为了实现这一点,DSpark 的调度器采用了异步机制,兼容零开销调度(ZOS)和连续 CUDA 图回放。
它利用前两步的历史预测来决定当前的动态截断长度,从而隐藏了调度延迟,避免了 GPU 流水线停顿,同时保证了目标模型输出分布的完全无损还原。
在涵盖数学推理、代码生成和日常对话等多个领域的测试中,DSpark 大幅超越了目前最先进的自回归模型(Eagle3)和并行草稿模型(DFlash)。
例如,在 Qwen3 系列(4B、8B、14B)目标模型上,其平均接受长度比 Eagle3 提升了 26.7% 到 30.9%,比 DFlash 提升了 16.3% 到 18.4%。
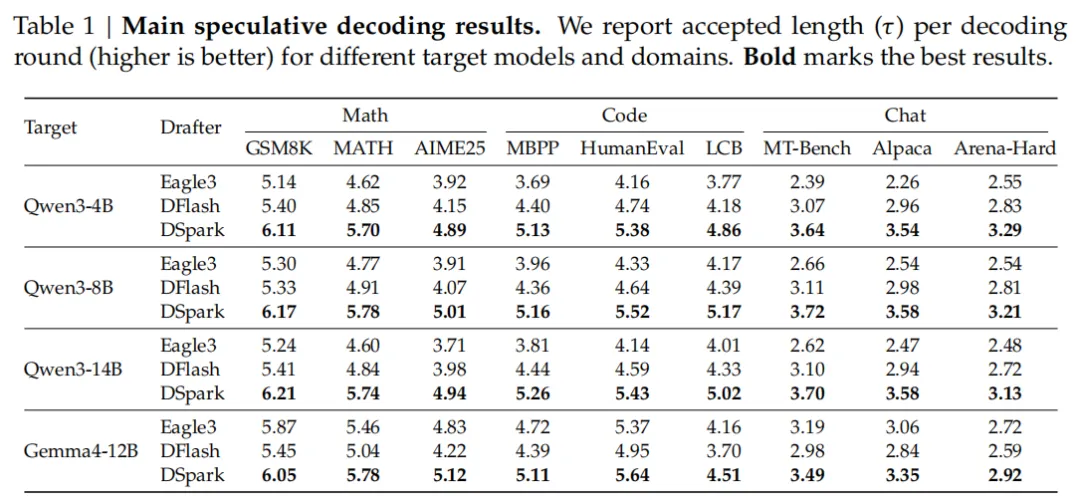
图片
相比于前一代部署的单 Token 生产基准(MTP-1),在维持相同总体吞吐量的情况下,DSpark 将用户的生成速度分别提升了 60%-85%(Flash 模型)和 57%-78%(Pro 模型)。
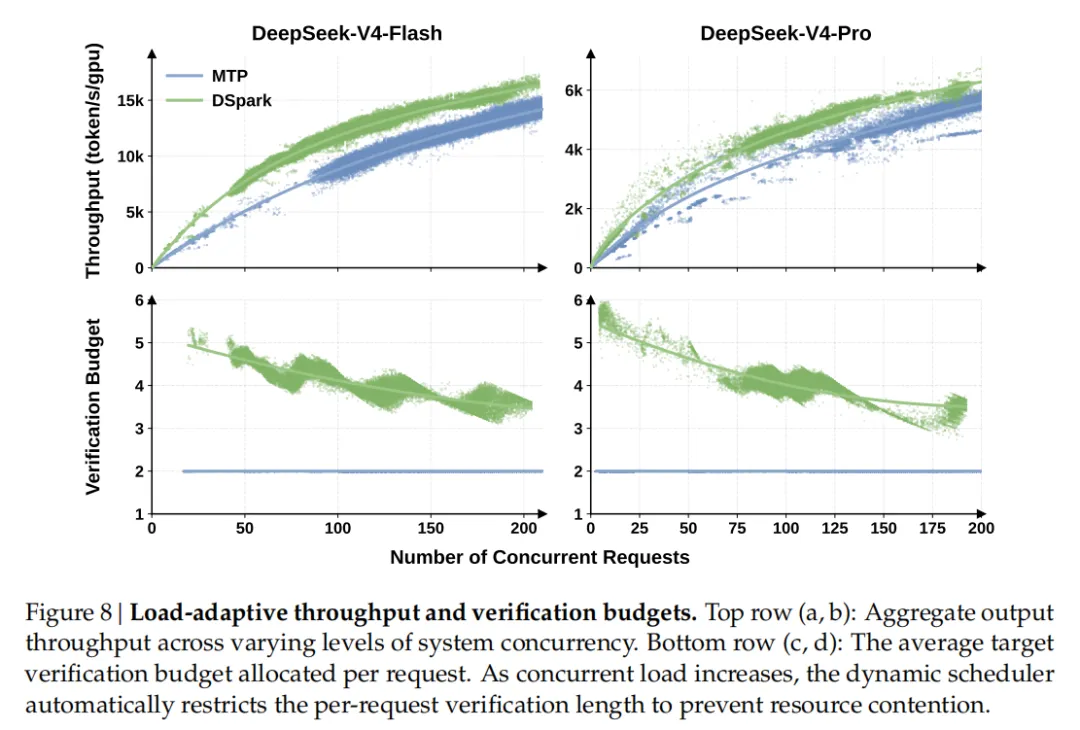
图片
图8|负载自适应吞吐量和验证预算。
顶行(a,b):跨不同级别的系统并发性聚合输出吞吐量。
底行(c,d):每个请求分配的平均目标验证预算。
随着并发负载的增加,动态调度器会自动限制每个请求的验证长度,以防止资源争用。
DeepSpec:基础设施
随 DSpark 一起开源的还有 DeepSpec。
这是一个训练和评估推测性解码草稿模型的全栈代码库。
把整体流程拆成三个阶段:数据准备、训练、评估。
数据准备阶段,需下载提示词数据、使用推理引擎对目标模型重新生成答案,并构建目标缓存(target cache)。
训练阶段可通过 bash scripts/train/train.sh 启动。
该脚本会调用 train.py,并为每张可见 GPU 启动一个 worker。
用户可以通过指定 config_path,在 config/ 目录下选择不同算法和目标模型配置。
项目也支持通过覆盖 config_path、target_cache_dir,以及使用 --opts 修改单个配置字段来调整训练设置。
硬件方面,DeepSpec 默认配置和脚本面向单节点 8 卡环境。
如果 GPU 数量较少,用户需要相应减少 CUDA_VISIBLE_DEVICES 中的可见 GPU 数量。
评估阶段则通过 bash scripts/eval/eval.sh 启动。
评估脚本会使用训练好的草稿模型 checkpoint,在多个 speculative decoding 基准任务上衡量接受情况。
项目当前列出的评估数据集包括 GSM8K、MATH500、AIME25、HumanEval、MBPP、LiveCodeBench、MT-Bench、Alpaca 和 Arena-Hard-v2,覆盖数学推理、代码生成、对话能力和综合问答等不同任务类型。
当前内置三种草稿模型:DSpark、DFlash、Eagle3。
支持的目标模型系列:Qwen3 和 Gemma。
以 Qwen3-4B 配置为例,目标缓存体积大约 38TB,准备跑之前先评估存储资源。
DeepSpec 的价值在于,它把推测性解码这个此前散落在各家团队内部的工程经验,收拢成了一套标准化工具链。
对于想给自己的模型加速推理的队伍,这意味着可以直接在成熟框架上训练定制草稿模型,跳过大量重复的基础设施搭建。
最后
看最近各家大模型的更新,感觉Deepseek 在围绕大模型的技术底座在优化改进。
其他厂家模型都在往应用下游的做后训练,为了让用户的Agent能做更多现实世界的任务。
比如阿里推出的语言世界模型,智谱让大模型能持续的长时间运行完成复杂的任务。
这样国内各家在不同的方向上投入资源,而且都保持开源。
每个模型团队在训练时可以采集各家之长,每一家的技术突破都会迅速变成全行业的“公共养料”,合全体之力追赶国外开源模型的能力,默契地打一场分布式攻坚战。
你也在等 DeepSeek 的新模型发布吗?
欢迎评论区留言。
参考资料
技术报告:《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》
GitHub:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号