VLM2Vec-V2:打破模态壁垒,迈向视频与文档理解的统一Embedding新纪元

VLM2Vec-V2:打破模态壁垒,迈向视频与文档理解的统一Embedding新纪元

唐国梁Tommy
发布于 2026-06-25 20:54:14
发布于 2026-06-25 20:54:14
今天,我们要深入探讨一篇引人注目的新研究——来自Salesforce Research、UC Santa Barbara等机构的《VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents》。这篇论文不仅提出了一个更强大的多模态模型,更重要的是,它为我们描绘了一幅宏伟的蓝图:如何构建一个能够统一理解图像、视频乃至复杂文档的“通用视觉嵌入”模型。

一、 为何我们需要一个“全能型”视觉模型?
在过去的几年里,多模态学习取得了爆炸性的进展。以CLIP为代表的模型,成功地将图像和文本映射到了一个共享的“语义空间”中。你可以给它一张狗的照片,它能理解这与文字“一条在草地上奔跑的金毛犬”高度相关。这项技术已经成为许多应用的基石,从图像搜索到AI绘画,无处不在。
然而,现实世界的信息远比静态图片和简短文字要复杂得多。想一想:
- 视频(Video):包含了时序动态、声音和复杂的场景互动。当你在YouTube上搜索“如何制作提拉米苏”时,你需要的是一个能理解整个视频流程的模型,而不仅仅是识别出“鸡蛋”和“面粉”的图片。
- 视觉文档(Visual Documents):PDF报告、PPT幻灯片、科学论文……这些文档包含了丰富的文本、图表、表格和复杂的排版布局。一个只能“读”纯文本的AI,在面对一份充满数据的财报PDF时,会瞬间“失明”。
现有的主流嵌入模型,如V-VLM、E5-V等,虽然在图文领域表现出色,但它们就像是只会一门“方言”的专家,面对视频和文档这些“新语言”时,就显得力不从心。这种能力的缺失,严重限制了AI在更广阔、更实用的场景中的应用。
因此,这项研究的动机非常明确:打破当前多模态模型在视觉形式上的局限性,创建一个能够统一处理和理解图像、视频和视觉文档的嵌入框架。这不仅是一次模型性能的提升,更是对AI通用理解能力的一次重要探索。
二、 VLM2Vec-V2 的两大“杀手锏”
为了实现上述宏伟目标,论文作者们祭出了两大核心贡献,可以说是一套“组合拳”:先定义一个更难、更全面的“考场”,再训练一个能在这个考场上取得高分的“全能考生”。
1. 贡献一:MMEB-V2——一个更严苛、更全面的多模态“超级考场”
在创造新模型之前,作者们首先解决了一个基础问题:我们该如何公平且全面地评判一个模型是否真的“全能”?答案是构建一个新的评测基准——MMEB-V2 (Massive Multimodal Embedding Benchmark V2)。
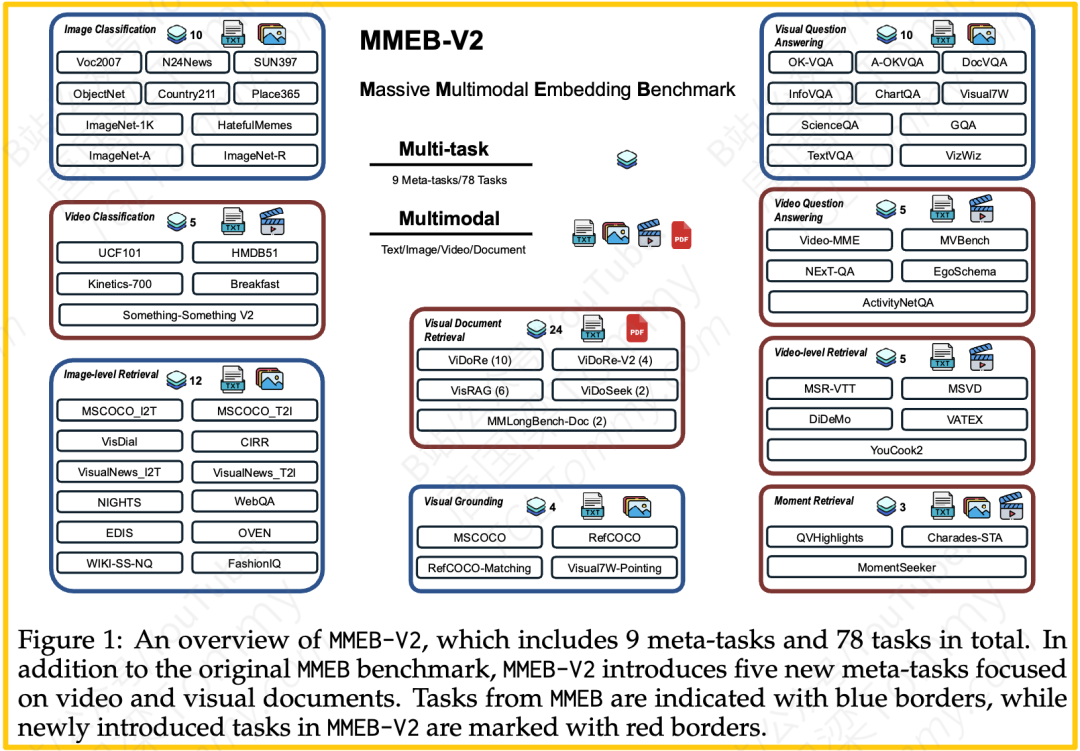
你可以把MMEB-V2想象成AI领域的一场“十项全能”挑战赛。它在原有的图文评测基准MMEB的基础上,新增了五大类极具挑战性的任务,全面覆盖了视频和视觉文档领域:
- 视频检索 (Video Retrieval):给一段文字,从海量视频库中找出最相关的那个。
- 时段检索 (Moment Retrieval):在一段长视频中,根据描述定位到具体的几秒钟片段。
- 视频分类 (Video Classification):判断视频内容属于哪个类别(如“运动”、“烹饪”)。
- 视频问答 (Video QA):观看一段视频后,回答关于视频内容的问题。
- 视觉文档检索 (Visual Document Retrieval):根据一个问题,在成堆的PDF或PPT中找到包含答案的那一页。
通过这套覆盖了9大元任务、78个子数据集的“考卷”,MMEB-V2为多模态模型提供了一个前所未有的、能够同时检验其图像、视频和文档理解能力的公平竞技场。
2. 贡献二:VLM2Vec-V2——为统一嵌入而生的“全能考生”
有了考场,接下来就是训练考生。VLM2Vec-V2正是为此而生。它是一个统一的多模态嵌入模型,其核心目标是将来自文本、图像、视频、视觉文档这四种不同模态的数据,全部编码(Embed)到同一个高维向量空间中。
在这个空间里,语义相近的内容,无论其原始形态是什么,它们的向量表示都会非常接近。这意味着,一段描述“全球气候变化趋势”的文字,一张展示冰川融化的图片,一份关于《巴黎协定》的PDF报告,以及一段记录环保峰会的新闻视频,都可能被映射到这个空间的相似位置。
实验结果也证明了它的强大。在MMEB-V2这个严苛的考场上,VLM2Vec-V2 (2B版本)取得了58.0的总体平均分,全面超越了包括GME、LamRA以及其前身VLM2Vec在内的所有基线模型。这不仅仅是分数的胜利,更是其统一学习框架有效性的有力证明。
三、 VLM2Vec-V2 是如何炼成的?
理解了VLM2Vec-V2“是什么”,我们再来深入探索“它是如何做到的”。其成功的秘诀可以归结为三点:一个强大的模型骨干,一套高效的学习方法,以及一种聪明的数据策略。
1. 坚实的基础:为何选择Qwen2-VL作为模型骨干?
任何强大的模型都需要一个优秀的底层架构。VLM2Vec-V2选择的是阿里巴巴研发的Qwen2-VL视觉语言模型。这个选择并非偶然,而是看中了它特别适合处理多样化视觉输入的三大特性:
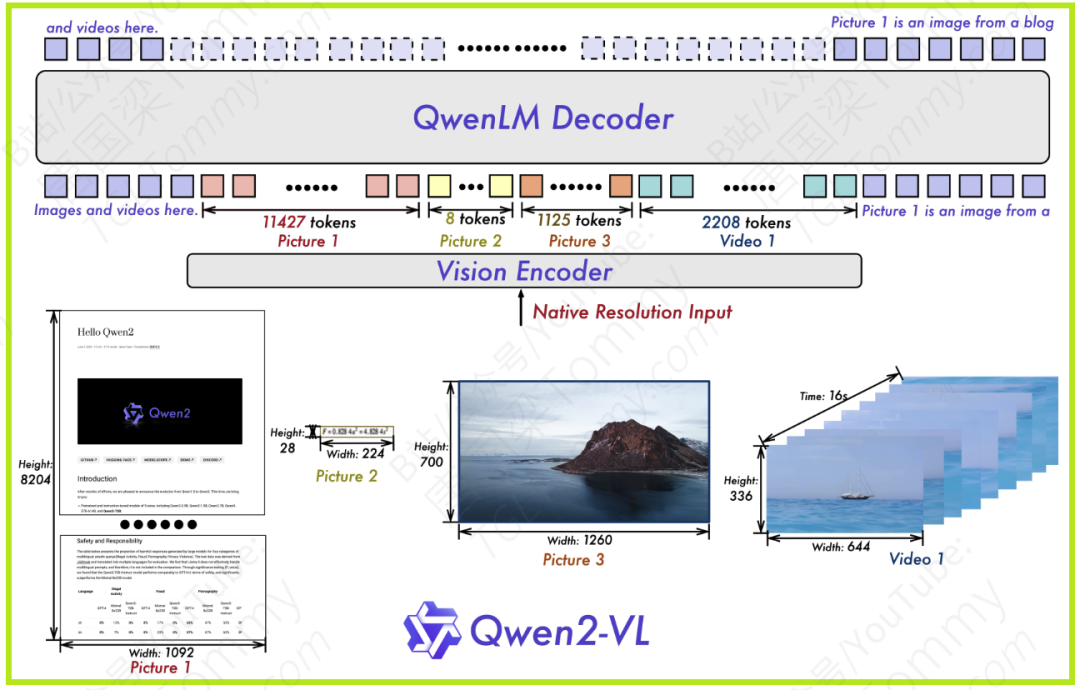
- 灵活的动态分辨率:传统模型通常要求输入图像有固定的尺寸,这既不灵活也浪费计算资源。Qwen2-VL能够高效处理任意分辨率的视觉输入。打个比方,它就像一副能自动变焦的智能眼镜,无论你看的是一张高清大图还是一系列低分辨率的视频帧,它都能快速适应,找到最佳的“焦距”来观察。
- M-RoPE, 多模态旋转位置编码:这个技术听起来很复杂,但它的作用很直观——为模型提供一个内置的“GPS系统”。对于图像,它能帮助模型理解物体在空间中的相对位置(“猫在桌子下面”);对于视频,它还能理解事件在时间上的先后顺序。这个“时空GPS”对于理解视频的动态性和文档的布局至关重要。
- Unified Architecture (统一架构):Qwen2-VL使用一套统一的内部处理机制来理解2D图像和3D视频数据(时间可以看作第三维度)。这确保了模型在处理不同视觉模态时具有一致性,不会因为模态切换而“精神分裂”。
2. 核心的灵魂:指令引导的对比学习
这是VLM2Vec-V2训练过程的精髓,它融合了两种强大的学习范式:对比学习(Contrastive Learning)和指令微调(Instruction Tuning)。
- 对比学习:在“找不同”游戏中学会区分万物
对比学习的理念很简单:拉近相似的,推远不同的。我们可以用一个形象的游戏来理解它:
想象一下,你正在教一个AI认识世界。你给它一个“查询”(Query),比如一段文字“一只猫在沙发上打盹”。然后,你给它一张完全匹配的“正样本”图片(Positive),同时还给它一堆不相关的“负样本”图片(Negative),里面有狗、有汽车、有风景。 AI的任务,就是学习一种“映射”方法,将文字查询和正样本图片映射到高维“语义空间”中的两个非常靠近的点。同时,它要将所有负样本图片映射到离它们很远的地方。
通过亿万次这样的“找不同”游戏,AI逐渐学会了分辨世间万物的细微差别。在VLM2V2中,这个过程由一个叫做InfoNCE Loss的数学公式来指导:
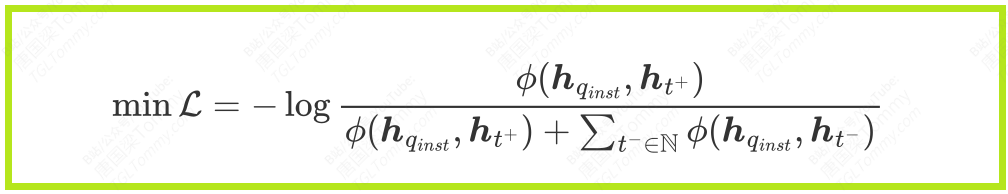
这个公式的分子部分,是希望查询和正样本的相似度分数尽可能大;而分母则包含了正样本和所有负样本的相似度之和,最小化损失函数就意味着要让负样本的相似度尽可能小。
- 指令微调:让模型“听懂人话”,学会触类旁通
如果说对比学习是让模型学会“看图说话”,那么指令微调就是教模型“理解任务要求”。作者发现,仅仅将原始数据对(如视频和描述)喂给模型是不够的,模型还需要知道“它具体要做什么”。
因此,他们在每个查询前都加上了一段明确的任务指令。例如,在进行视频检索时,输入不再是简单的“一段关于烹饪的视频”,而是被格式化为:[VISUAL_TOKEN] Instruct: "Find a video that contains the following visual content:" \n Query: "一段关于烹饪的视频"
这个小小的改动,效果却十分显著。它就像你给一个助手下达指令,告诉他“去帮我找一份关于XX的报告”和“去帮我总结一下XX报告的第二章”是两个完全不同的任务。通过这种方式,模型学会了根据不同的指令来调整自己的行为,从而能够更好地泛化到各种未知的新任务上。
3. 聪明的策略:交叉子批次,让训练更稳定、更高效
当训练数据来自几十个不同的数据集时,如何高效地“喂”给模型是一个技术活。如果只是简单地随机混合,训练过程可能会很不稳定。为此,VLM2Vec-V2设计了一种巧妙的交叉子批次(Interleaved Sub-batching)策略。
这个策略可以类比为一位健身达人的高效训练计划:
假设一个大的训练批次(Batch)包含1024个样本。
- 传统方法(随机混合):就像这位健身者在一小时内随机做各种器械,练一会儿胸,又跑去练一会儿腿,再练一会儿胳膊。这样虽然全面,但每个部位的刺激都不够深。
- VLM2Vec-V2的方法:这位健身者将一小时的训练分成8个“子批次”,每个子批次持续7-8分钟。在第一个子批次里,他只做和“视频检索”相关的练习,这让负责这项任务的“肌肉群”得到了深度刺激,训练难度也更高。在第二个子批次里,他可能只做“文档问答”的练习。通过将这些高度集中的“子批次”交织在一起,他既保证了每个任务都得到充分、高强度的训练,又通过任务切换维持了整体训练的多样性和稳定性。
这种策略,在提高对比学习难度的同时,又避免了因批次内样本过于同质化而导致的训练崩溃,可谓一举两得。
四、 实验结果与分析
VLM2Vec-V2在MMEB-V2这个严苛的基准上,与众多强手进行了正面交锋,结果令人信服。
1. 总体性能:全面的领先
表2的性能对比是整个实验的核心。我们可以从中解读出几个关键信息:
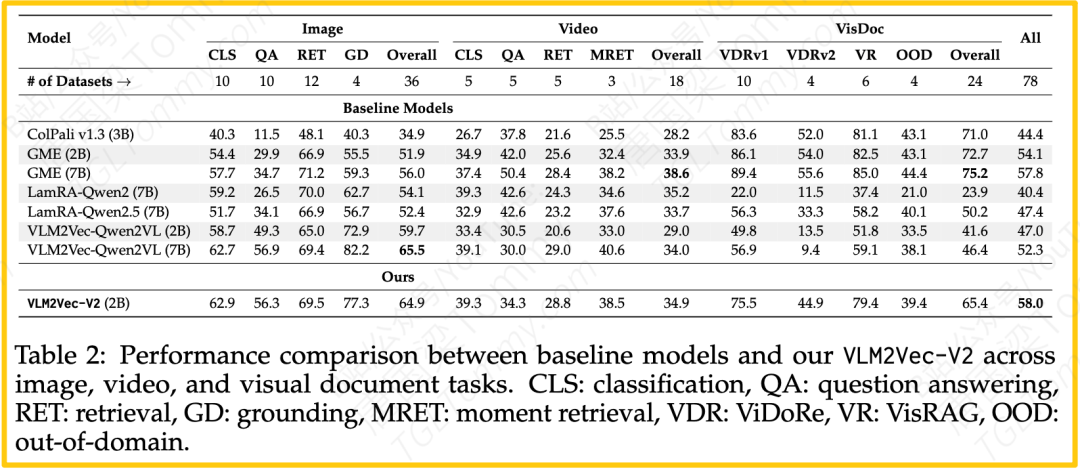
- VLM2Vec-V2 (2B) 登顶:它以58.0的总体平均分位列第一,超越了所有基线模型,包括参数量更大的7B模型。这证明了其训练框架的优越性,实现了“以小博大”。
- 征服新模态:在新增的视觉文档 (VisDoc)任务上,VLM2Vec-V2取得了65.4分,远超其前身(仅40-50分水准)。在视频 (Video)任务上也取得了34.9分,展现了强大的竞争力。
- 诚实的比较:论文坦诚地指出,尽管VLM2Vec-V2在文档任务上很强,但仍略低于专门为文档检索优化的“偏科生”模型ColPali(得分71.0)。这提醒我们,在追求“全能”的同时,专用模型在特定领域的深度优化仍然具有不可替代的价值。
2. 消融研究:探究成功的秘密成分
为了搞清楚到底是哪些因素造就了VLM2Vec-V2的成功,作者进行了一系列“控制变量”实验(Ablation Studies)。
- 多模态联合训练真的有效吗?(见表3)
- 实验设计:作者分别用单一模态数据(仅图像、仅视频、仅文档)、两种模态组合数据,以及全部三种模态数据来训练模型。
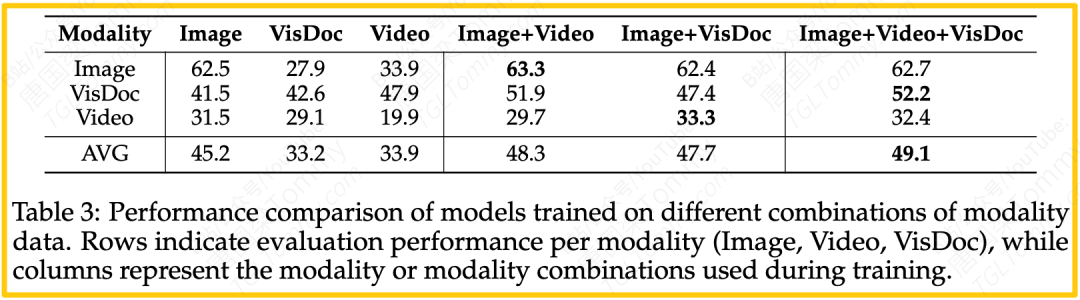
- 惊人发现:结果显示,“大杂烩”的效果最好。当模型用全部三种模态的数据进行联合训练时,它在几乎所有单个模态上的表现都是最好的,最终取得了49.1的最高平均分。这就像一个运动员,通过交叉训练(游泳、跑步、力量)反而能提升自己的专项成绩。这有力地证明了,不同模态的知识可以相互促进,从而提升模型的整体泛化能力。
- 训练设置的影响
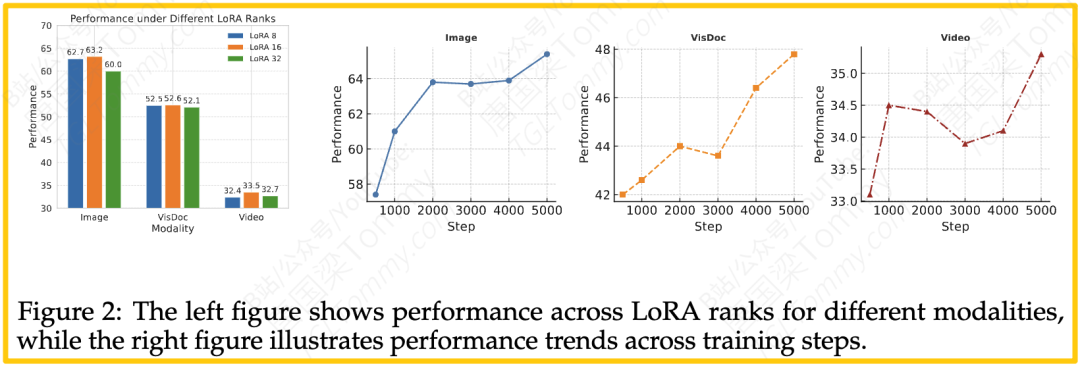
- LoRA秩的选择:实验发现,LoRA(一种参数高效微调技术)的秩设置为16时,模型性能达到最佳,过高或过低都会导致性能下降。这为后续研究提供了宝贵的工程经验。
- 训练步数的影响(见图2):性能曲线图显示,即使在训练了5000步之后,模型在视频和文档任务上的性能仍在持续上升,没有出现明显的“瓶颈”。这暗示了一个重要的信息:VLM2Vec-V2的潜力可能还远未被完全挖掘出来。
五、 启示:通往“万物皆可嵌入”的未来之路
VLM2Vec-V2无疑是多模态嵌入领域的一个重要里程碑。它不仅提供了一个强大的新模型,更重要的是,它验证了一条通往更通用、更强大AI的可行路径。基于这篇论文,我们可以预见几个激动人心的未来方向:
- 更丰富的模态融合:当前的视频表示还相对初级(均匀采样8帧)。未来,可以探索更智能的帧选择策略,甚至将音频作为第四种关键模态融入进来,实现真正的“视听一体”理解。
- 挖掘更深的潜力:既然训练尚未饱和,那么投入更多的计算资源,进行更长时间、更大规模的训练,几乎肯定能进一步解锁模型的潜力,冲击更高的性能上限。
- 通用与专业的结合:如何将VLM2Vec-V2这样的“通才”模型与ColPali这样的“专才”模型进行有效结合?或许未来的AI系统会采用一种“混合专家”的模式,根据任务类型动态调用最合适的模型。
- 迈向更多模态:这套统一学习的框架极具扩展性。我们可以想象,未来它还可能被扩展到3D点云、医学影像、甚至金融时间序列等更多样化的数据形式,最终实现“万物皆可嵌入”的终极愿景。
总而言之,VLM2Vec-V2的工作,让我们离那个能够无缝理解并关联世间万物的通用AI,又近了一步。这不仅仅是技术上的突破,更是对未来智能交互形式的一次深刻预演。让我们拭目以待,看它将如何继续演进,并赋能下一代的AI应用。
参考文献
论文名称: VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents
第一作者: Salesforce Research
论文链接: https://arxiv.org/pdf/2507.04590
发表日期: 2025年7月7日
GitHub:https://github.com/TIGER-AI-Lab/VLM2Vec.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#多模态大模型 #AI视频理解 #人工智能 #AIGC #唐国梁Tommy #大模型原理 #AI前沿技术 #AI论文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号