机器学习中的特征选择技术:过滤方法、包装方法、嵌入方法

机器学习中的特征选择技术:过滤方法、包装方法、嵌入方法

deephub
发布于 2026-06-24 18:24:58
发布于 2026-06-24 18:24:58
机器学习(Machine Learning)模型从数据中学习规律。数据集中并非每个特征(feature,即列)对预测的贡献都相同——有些特征无关紧要、有些彼此冗余、还有些只是噪声反而会拖累模型性能。
特征选择(Feature Selection)就是从数据集中筛选出最重要特征、去除无用特征的过程。其主要价值在于:提升模型准确率、缓解过拟合(overfitting)、缩短训练时间、改善可解释性、降低计算成本。
什么是特征选择?
特征选择是一种预处理技术,用于识别并保留构建机器学习模型时最相关的特征。
以一个银行数据集为例,包含以下字段:年龄、性别、薪资、客户 ID、账户余额、支行编码。其中客户 ID 对预测客户行为几乎没有贡献,特征选择就是要识别并移除这类列。
为什么特征选择很重要
机器学习数据集往往包含数百乃至数千个特征。特征过多会带来一系列问题:维度灾难(Curse of Dimensionality)、训练时间拉长、过拟合风险上升、模型泛化能力下降,以及存储需求膨胀。特征选择让模型聚焦于真正有意义的信息。
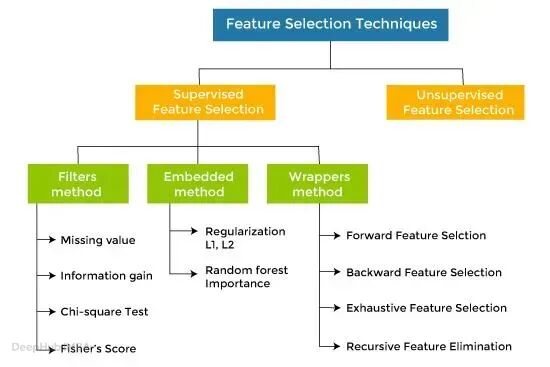
特征选择技术的类型
特征选择技术大致分为三类:过滤方法(Filter Methods)、包装方法(Wrapper Methods)、嵌入方法(Embedded Methods)。
1、 过滤方法
过滤方法独立于机器学习算法对特征逐一评估,不需要反复训练模型,因此速度快、计算开销低,适合大型数据集。代价是忽略了特征之间的交互关系。

基于相关性的特征选择(Correlation-Based Feature Selection)
衡量输入特征与目标变量之间的线性关系。
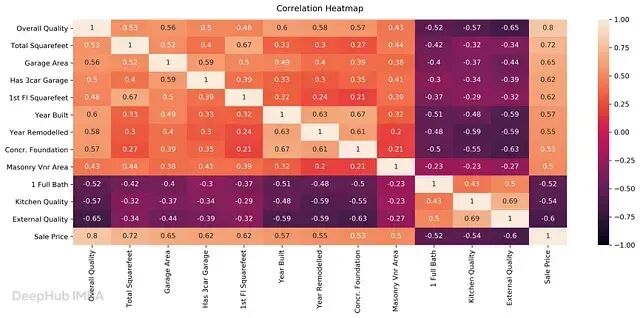
热力图(heat map)
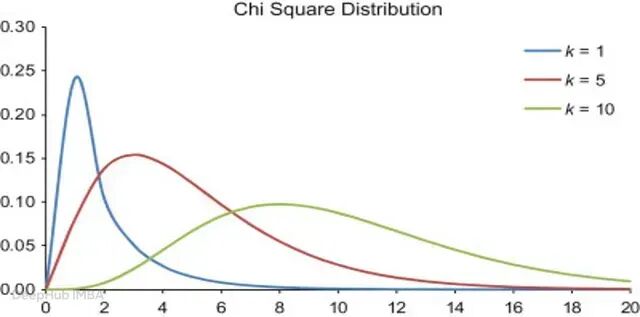
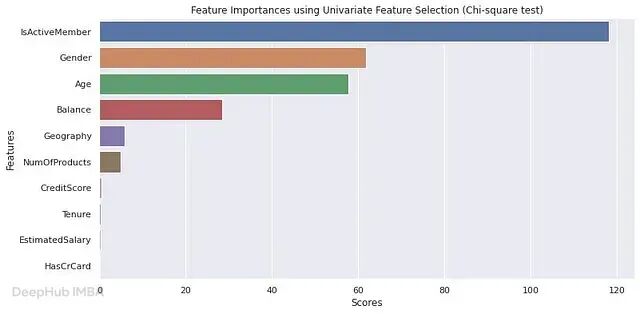
卡方检验(Chi-Square Test)
用于类别型特征,衡量特征与目标变量之间的依赖程度。卡方分数越高,说明该特征携带的判别信息越多。典型应用场景包括客户细分、文本分类和医疗诊断。
互信息(Mutual Information)
衡量一个变量能为另一个变量提供多少信息。与相关性分析相比,互信息能捕捉非线性关系,更适合分类任务。
2、 包装方法
包装方法借助机器学习模型对特征子集进行评估,通过反复训练不同特征组合来寻找最优子集。由于考虑了特征间的交互关系,通常能取得更好的效果,但计算开销也随之上升。
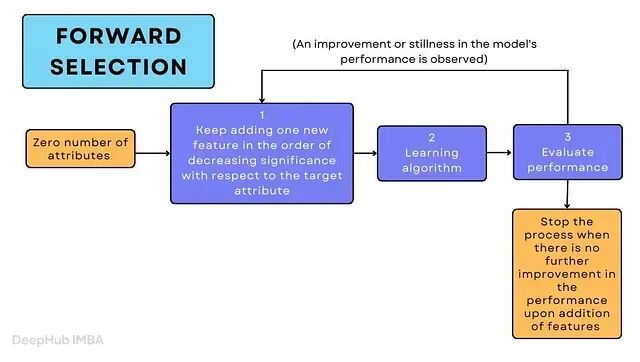
前向选择(Forward Selection)
从零个特征出发,每轮加入一个在当前基础上贡献最大的特征,直到性能不再提升为止。具体步骤如下:
- 分别用每个特征单独训练模型。
- 选出效果最好的特征。
- 在此基础上逐一尝试加入其他特征。
- 重复,直到性能停止改善。
后向消除(Backward Elimination)
与前向选择方向相反,从全量特征出发,每轮移除贡献最小的特征,直到保留下最优子集。步骤如下:
- 用全部特征训练模型。
- 移除最不重要的特征。
- 重新训练。
- 重复,直到特征集合收敛。
方法直观易懂,产出的特征子集质量也较高。
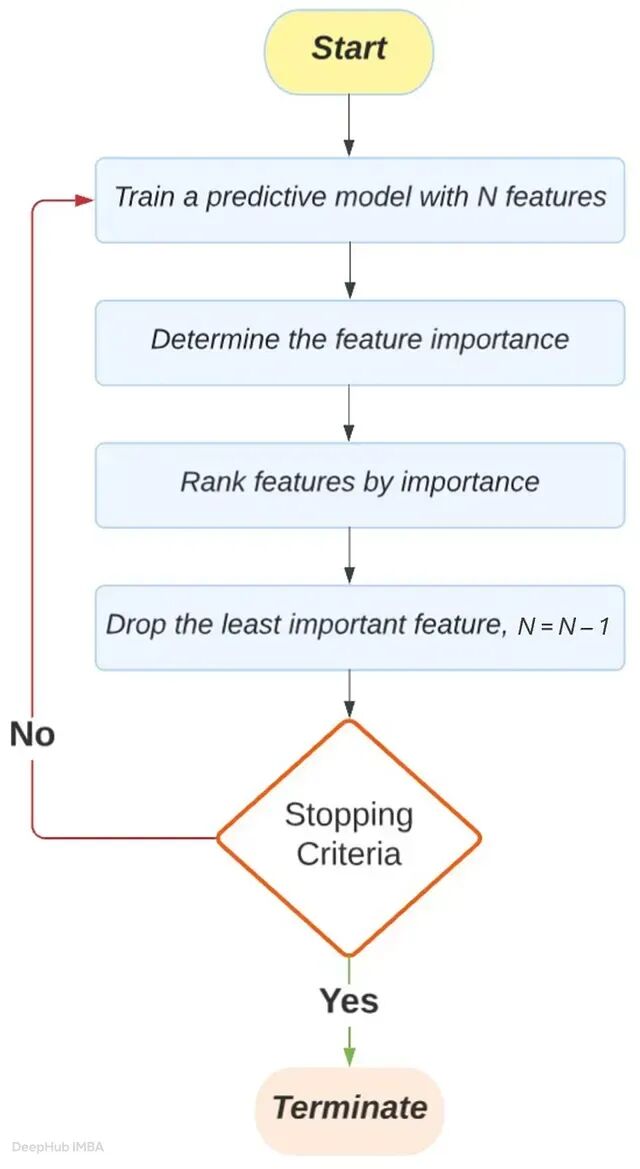
递归特征消除(Recursive Feature Elimination,RFE)
RFE 是使用最广泛的包装方法之一,工作流程如下:
- 训练模型。
- 对所有特征排名。
- 移除排名最低的特征。
- 重新训练。
- 重复,直到保留所需数量的特征。
以一个银行数据集为例,原始特征为:年龄、薪资、余额、信用评分、交易记录。经 RFE 筛选后,最终保留:薪资、余额、信用评分。
3、嵌入方法
嵌入方法在模型训练过程中同步执行特征选择,兼具过滤方法的效率和包装方法对特征交互的感知能力。
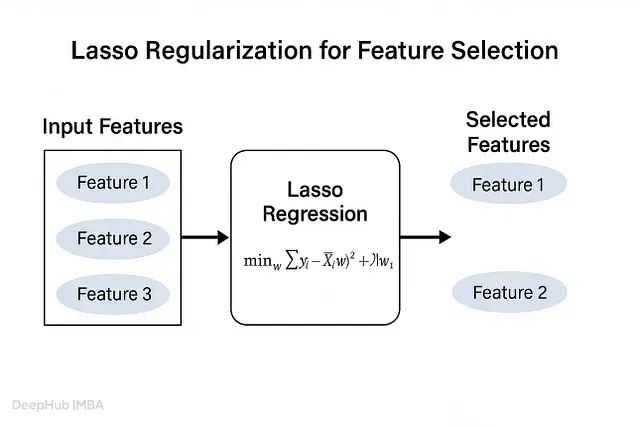
Lasso 回归(L1 正则化)
Lasso 在损失函数中加入 L1 惩罚项,自动将不重要特征的系数压缩至零,从而实现特征剔除。公式如下:
Loss=RSS+λ∑∣βi∣Loss=RSS+\lambda\sum|\beta_i|Loss=RSS+λ∑∣βi∣
其中 RSS 为残差平方和(Residual Sum of Squares),λ 为正则化参数,β 为系数。随着 λ 增大,越来越多的系数归零,对应特征被自动移除。
Lasso 回归(L1 正则化)
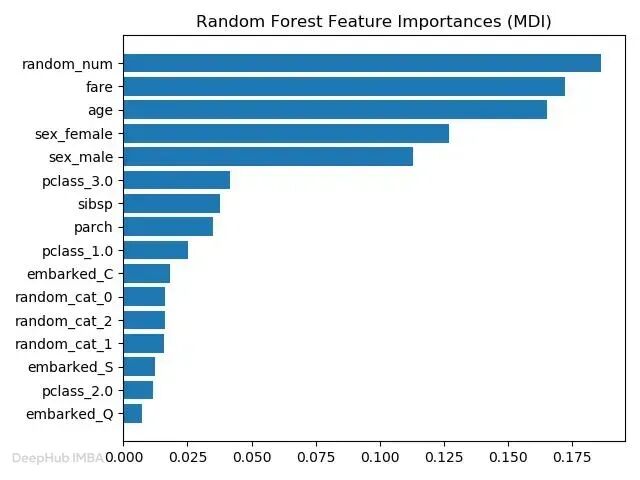
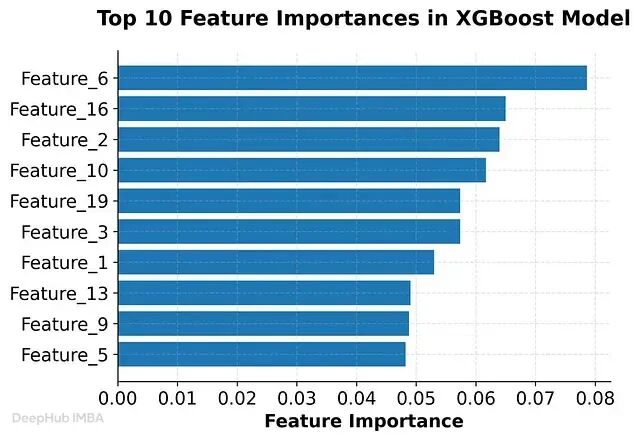
基于树的特征重要性(Tree-Based Feature Importance)
决策树(Decision Tree)、随机森林(Random Forest)、XGBoost 等树模型在训练过程中天然计算特征重要性——根据特征在各分裂节点上的贡献累计得分,重要性越高说明该特征对预测的影响越大。
总结
不同场景下的方法选择有一定规律:相关性分析适合快速清理高度共线的特征;RFE 在中等规模数据集上表现稳定;Lasso 回归适用于特征数量多的线性模型;随机森林特征重要性对分类和回归任务都适用。多数情况下,组合使用几种方法能得到比单一方法更可靠的结果。
特征选择是机器学习 Pipeline 中不可忽视的环节。去掉无关和冗余特征,模型在性能、计算效率和可解释性上都会有所改善。相关性分析、卡方检验、互信息、RFE、Lasso 回归、基于树的特征重要性——这些方法各有侧重,选哪种取决于数据集规模、特征类型和所用算法。
作者:Palavalasamounika
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-19,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号