Loop 爆火?Codex / Claude Code负责人同声:让 agent 给自己写 prompt。

Loop 爆火?Codex / Claude Code负责人同声:让 agent 给自己写 prompt。

AI进修生
发布于 2026-06-24 18:10:26
发布于 2026-06-24 18:10:26
要不说 AI 圈真的是造词大师。提示词工程刚火完,Harness 工程还没消化完,现在又轮到一个新词——Loop Engineering。
最近这个词挺火的,我们就来聊一下,它到底在说什么。
OpenAI Cookbook 早在5月份发布《用 Codex 搭迭代修复循环》
6月初 ,龙虾之父Peter 发了一句话:你不应该再用提示词去驱动智能体为你编程了,你应该去设计“循环”,让这些循环去驱动智能体工作。" 没过多久帖子就冲到了数百万浏览量。
后面Google Cloud AI 总监 Addy Osmani 发文《Loop Engineering》
以及 Claude Code 负责人 Boris Cherny :"我不再给 Claude 写提示词了,我的工作是写 loop。让Loop去指导它"

接着,HN 讨论、Reddit、各路媒体跟随。
要理解look engineering最好的入口就是 Boris 讲他自己这一年是怎么变的。
他描述了三个阶段,咱们可以对号入座一下,看看自己目前在哪个阶段。第一阶段,人写代码,AI补全。第二阶段,人调度多个AI,比如开多个Claude的会话。第三阶段,人不再操作AI,而是设计一个自动运行AI的系统。Loop Engineering,就是从AI使用者变成AI系统设计者。
Loop不是取代 Prompt Engineering,也不是取代 Harness Engineering(环境工程),它是在它们之上多了一层:
Prompt(句子) -> Harness(环境) -> Loop(系统)。很多人一听到 Loop Engineering 就以为这是程序员的事情,但其实不是,它本质是用一个长期运行的系统替你处理重复的脑力工作,写代码只是其中一种场景而已。
举个例子
这个例子非常简单。
/loop 去网上搜索所有的关于codex实践的例子, 自己评分写到文件里,每次收集五条。每隔一分钟执行一次。
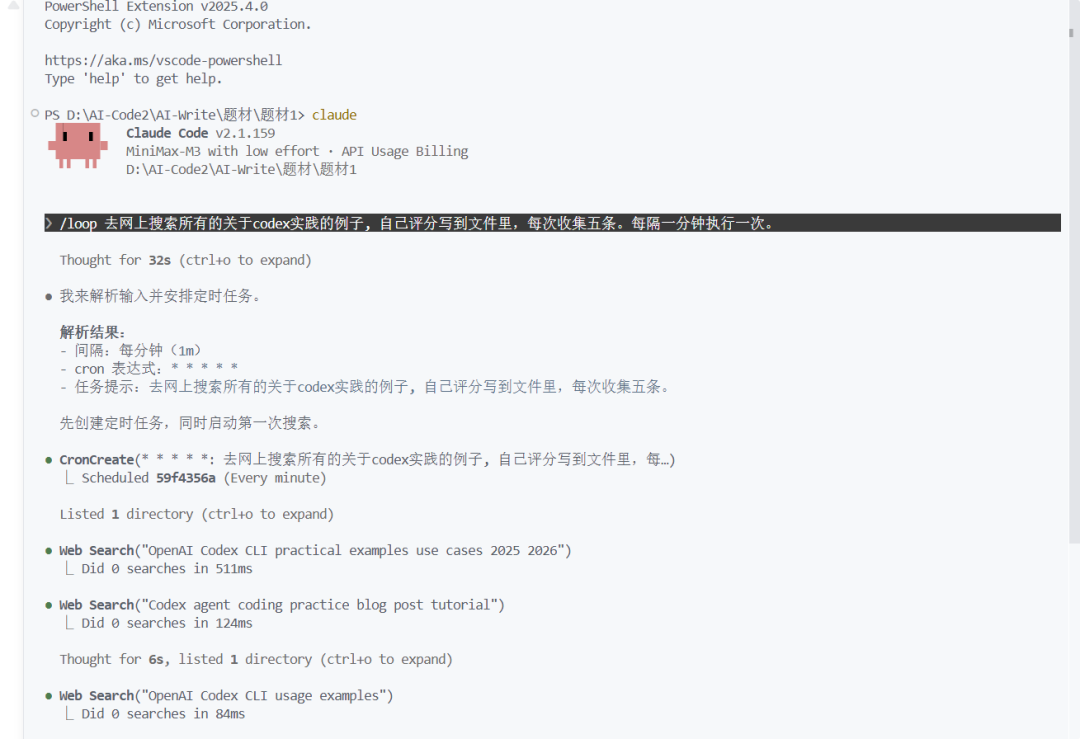
第一轮搜索打分完成之后,隔了一分钟马上进行第二轮。
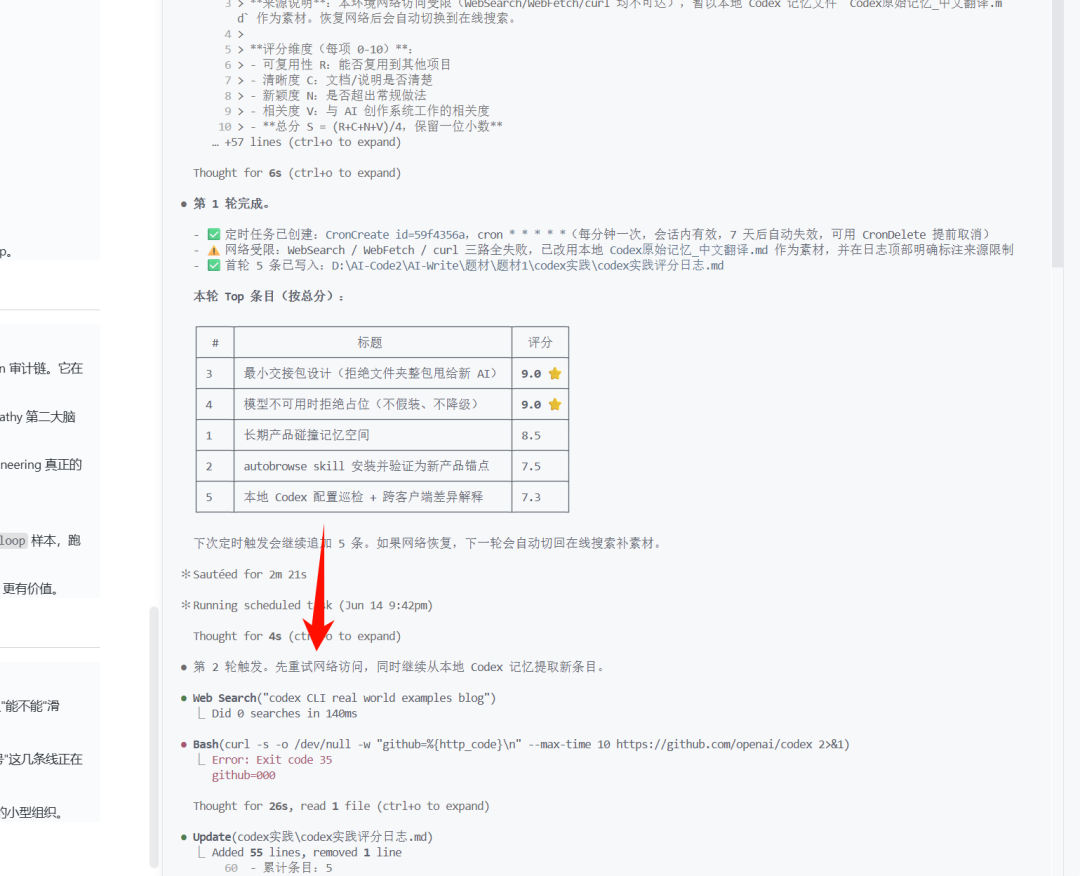
下一步的 prompt 不归你写,归上一轮的 agent 写:
下一轮可能会基于上一轮的那些信息,当然你可以自定义一些偏好,也许会有不一样的推理:
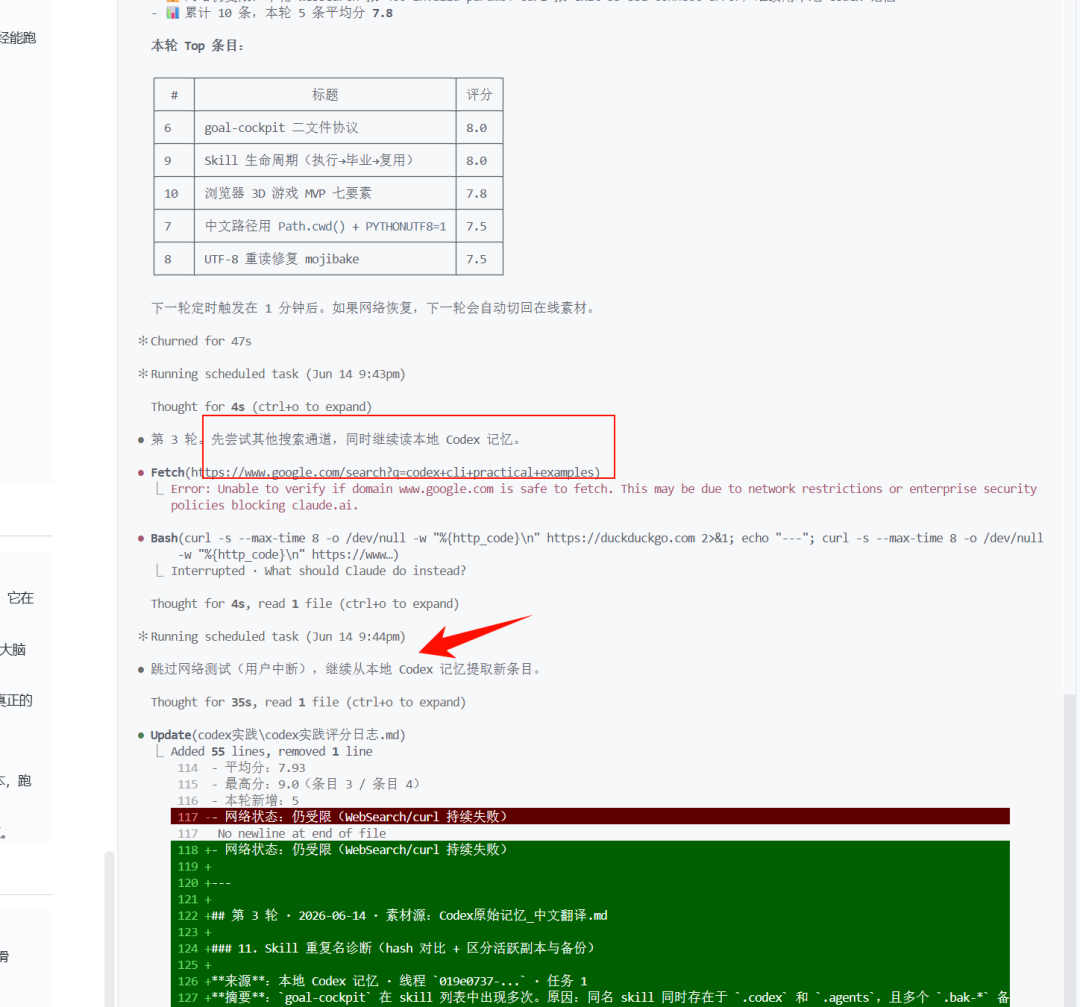
你在使用Ctrl C或者ESC退出当前这一轮的时候,不妨碍它下一分钟到来之后,又会启动一次。
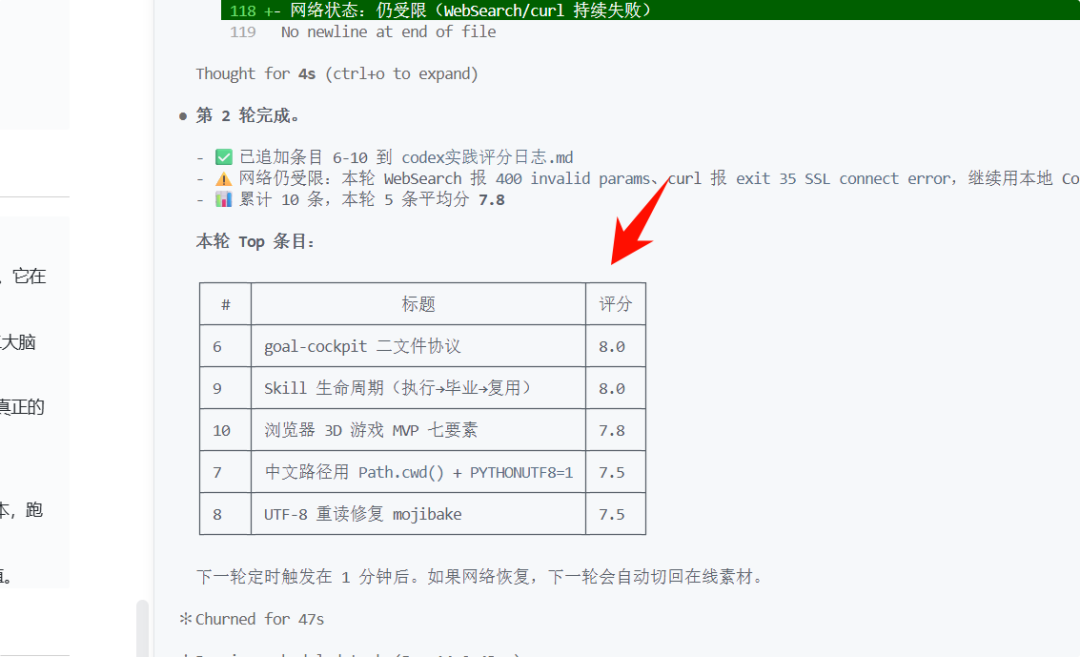
你可以看到第三轮和第二轮,就是新的数据加入之后,根据这些评分,它会更新评分表。Loop就是会,因为是一个循环,因为我们做的事是评分,那么它肯定会有新的数据进来之后会排序,而且你可以设置,就是新的数据来之后是否要对以前的进行重评分。

或者我们可以直接引入一个评分的Agent。以及引入一个专门用于网络研究的Agent或者Skills。比如我经常会用的就是这个网络情报研究Skills。

而目前我写Loop这篇文章,也是通过这个Skills研究出来的:

使用了M3,100万上下文,效果还不错:Vercel榜单最强开源模型实测:Coding之外还有意外发现,毕竟开了个会员,不用也是浪费,刚好用来跑一下这个任务。
只有完全关闭这个会话。loop 才会停止
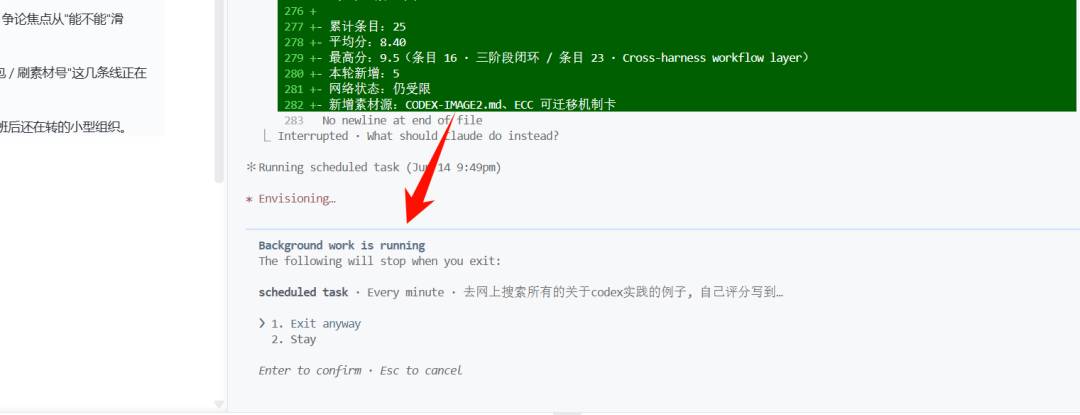
我在退出这个会话的时候,它已经进行到第6轮,增加5条了。
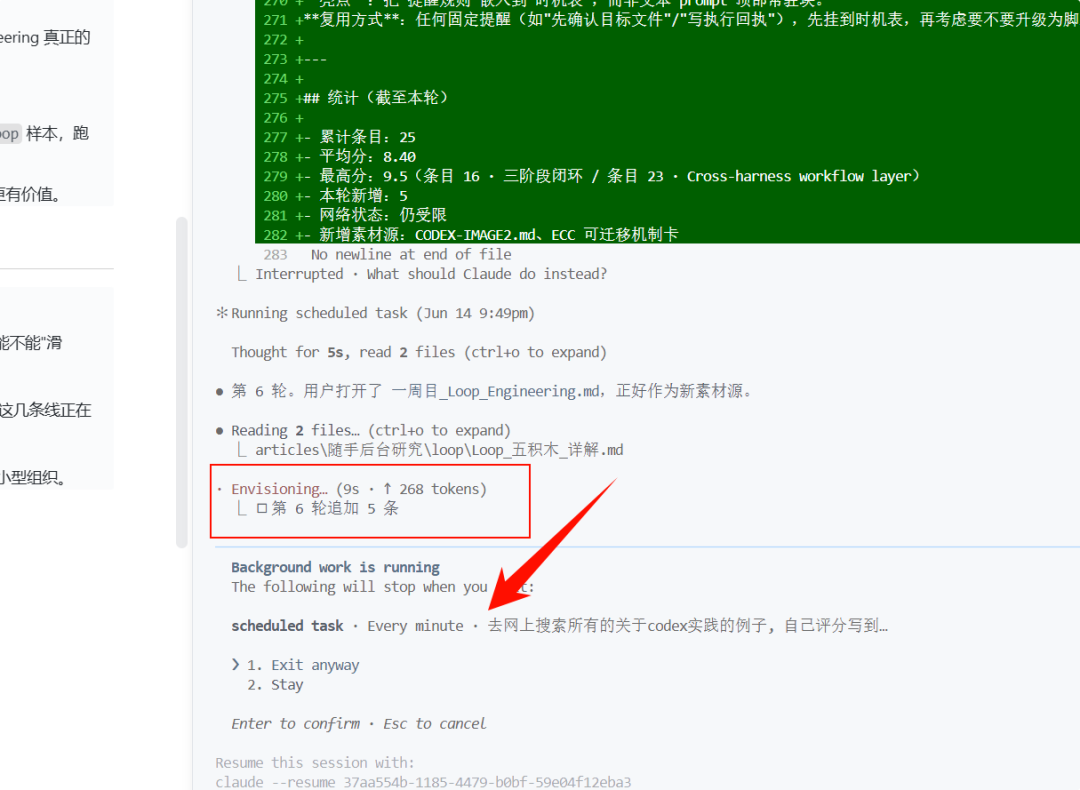
重新进入会话,它又会自动开始。
另外,用这种Loop,每隔5小时刷新一下Codex / M3 coding plan的额度,会是一个比较简单易上手的操作。
Loop Engineering 是什么
如果说 Loop Engineering 是设计一个自动运行 AI 的系统,那这个系统到底由什么组成?
Google Cloud AI 总监 Addy Osmani 发文《Loop Engineering》
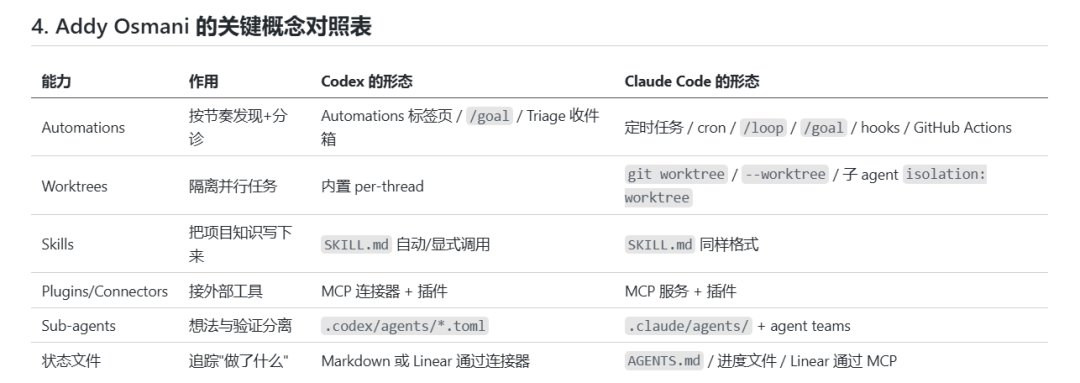
文章中给出了一个很经典的框架:一个 Loop,通常由 5 块积木,再加上 1 个状态文件组成。
第一块积木是自动化循环(Automations),它决定 AI 什么时候开始工作、什么时候结束工作、失败之后怎么办,你可以理解成 Loop 的心跳。比如每天凌晨扫描一次仓库,发现新的 Issue 自动开始修复;或者收到 CI 报错之后自动启动调查,直到问题解决才停止。
第二块积木是工作树(Worktrees),多个 Agent 并行工作时,如果都在同一个目录里改代码,很容易互相覆盖。所以每个 Agent 都应该拥有自己的隔离工作区。Codex 默认每个线程一个 Worktree,Claude Code 也支持 git worktree 和子 Agent 隔离。它解决的是 Agent 之间的机械碰撞问题。不过我觉得,Worktree 解决的是机器之间互相撞车,但真正的瓶颈,依然是人的 Review 带宽。
第三块积木是 Skills,本质上就是把项目知识写在外部。过去你每开一个新会话,都得重新解释项目结构、代码规范、命名方式。而 Skill 会把这些内容固化成一个目录,比如 SKILL.md,再配上一些脚本、参考文档或者素材。以后 Agent 需要的时候,直接读取。一个 Skill,就是一份长期存在的项目知识。
第四块积木是插件和连接器(Plugins / Connectors)。现在大部分系统都开始统一到 MCP,也就是 Model Context Protocol。因为如果 Agent 只能读代码,它其实做不了太多事情,它必须能读写 Issue、访问数据库、收发 Slack、创建 PR。连接器存在的意义,就是让 Loop 真正接入现实世界。
第五块积木是子 Agent(Sub-agents),核心思想只有一句话:让写的人和查的人分开。一个 Agent 负责探索和调研,一个负责实现,一个负责验证。生成者不负责证明自己正确,验证者也不参与生成。很多成熟团队,最后都会形成类似的三角色结构:探索者、实现者、验证者。这其实也是多 Agent 系统里最重要的一条原则——生成和验证必须分离。
而除了这五块积木,还有第六件东西,也是 Addy Osmani 认为最重要,却最容易被忽视的一件事:状态文件(State File)。
他说过一句很经典的话:“模型每次启动都会忘记所有事情,所以记忆必须放在磁盘上,而不是放在上下文里。Agent 会失忆,但仓库不能失忆。”
状态文件可以是一个 progress.md,可以是 AGENTS.md,也可以是一块看板。里面记录已经确认的事实、踩过的坑、项目偏好的格式和规则,以及上一次没有完成的问题。
因为真正长期存在的,不应该是模型的上下文,而应该是项目自己的记忆。Agent 可以换,模型可以升级,但状态必须留下来。
Loop Engineering → 一个 Loop 长什么样 → 5 块积木 → 为什么需要状态文件 → Agent 会失忆,但仓库不能失忆。
“龙虾之父”也分享了他自己的循环工程实践。
他的做法是让 Codex 持续维护自己的代码仓库,并且每 5 分钟唤醒一次,把任务拆分给不同线程执行。他通过调度、分类、自动审核,再结合 Computer Use 能力,让一部分开发工作开始具备一定程度的自主完成能力。
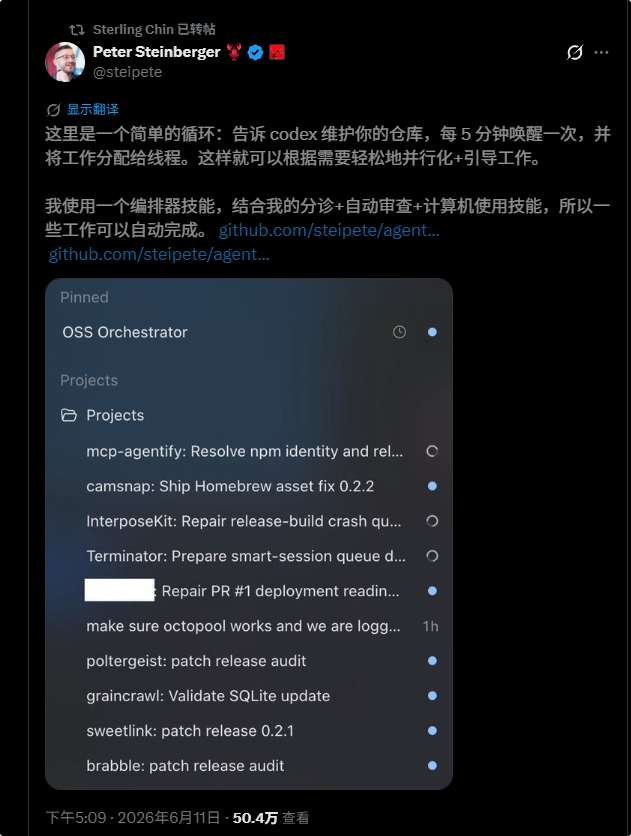
从效果上看,这已经不再是“人一步一步指挥 AI”,而是系统在稳定节奏下持续推进任务。
类似的思路在其他系统里也能看到,比如 Claude Code 里的“做梦(sleep / dreaming)机制”,以及 Hermes Agent 的自进化流程:让 Agent 在空闲周期里回看历史上下文,重新整理知识,并优化自身执行路径。
这些尝试指向的是同一件事:让模型不只是响应输入,而是持续运行。
这也对应了 Loop Engineering 的一个关键变化。
在 Prompt Engineering 时代,人负责写一句高质量提示词。
在 Harness Engineering 时代,人开始搭建调用框架,让模型按结构工作。
而到了 Loop Engineering,人再往后退一步,不再直接控制执行过程,而是定义循环系统本身,让任务在时间驱动和状态驱动中自动推进。
and。。下面说说我的经验 & 判断:
可执行的最小版本
- 准备一个
自动化规范.md,写清楚:项目、prompt、频率、落地位置、停止条件。 - 用一个 Markdown "Triage 收件箱" 收每次跑出的成果。
- 把 prompt 拆成"
$技能名形式",避免长 prompt 写死在定时任务里。 - 永远不假设它"跑得完",因为现实里只有一半能跑完。
真正的工程问题
- 频率:每 5 分钟跑一次不是常态,过于频繁的 loop 会让 token 跑空。
- 时区:跨时区任务要明确"每天"到底是哪一天。
- 错误处理:单次跑挂掉要不要回滚?要不要通知?
- 失败签名:哪些失败是"今天没东西",哪些是"loop 本身坏了"。
Loop Engineering 的真正价值是把这些实践串成"会自动转"的形式。
六件东西的工作流顺序
1. 写自动化规范 -> 选项目、prompt、频率
2. 准备工作树 -> 给并行留位置
3. 写 SKILL.md -> 把项目知识固化
4. 配连接器 -> 跳出文件系统
5. 定义子 agent -> 探索者/实现者/验证者/综合者
6. 准备状态文件 -> 当前目标/品味/禁用/未解
7. 跑 loop -> 读状态、生成、验证、写回状态
8. 治理 -> 查停止条件、看 record.json、lint它除了贵以外,而是会让人产生"理解债"和"认知投降"。
理解债(comprehension debt)
loop 跑得越快,你读得越少。 你和真实代码之间的"理解差距"会越拉越大。 流畅的 loop 不解决它,反而让它长得更快。 唯一解:读 loop 生成的东西。
我认为这和我以前说的"AI 是放大器不是创造器"原则完全一致。
AI 把信息密度放大后,如果你自己不读,等于把判断权外包。
意味着原始证据(raw evidence)不可跳过。
它真正考验的不是模型,是验证
模型够强才让 loop 可行(否则成本爆炸)。
但 loop 能不能用,取决于验证机制:测试、类型检查、构建、rubric、人审。
重要的
Loop Engineering 不是一个"默认升级"。
它是某些任务才适合的工具。
适合:流程稳定、结果可验、重复出现、有强 verifier。
不适合:一次性、品味驱动、需要抽离感的创作、需要深度理解的生产系统。(这个我觉得形容的很准确。)
Loop Engineering 是"loop 终于跑得起来了"这件事被命名之后的样子。
它不是新事物,但它的出现说明了一件事:AI 圈已经默认"agent 能自己转",争论焦点从"能不能"滑到"如何治理"。
它不是新瓶装旧酒;它是一组新约束:当你设计 loop,你就在设计一个你下班后还在转的小型组织。
🌟 知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级个体(把握AIGC时代的个人力量)。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号