为什么你的 RAG 检索不到答案?面试官真正想听的是这个

为什么你的 RAG 检索不到答案?面试官真正想听的是这个

王中阳AI编程
发布于 2026-06-23 21:28:44
发布于 2026-06-23 21:28:44
本文是「RAG 面试通关」系列的第 5 篇。 上一篇:第 4 篇《做 RAG 为什么要用向量数据库,我直接上 MySQL 不行吗》 下一篇预告:第 6 篇《RAG 从 Demo 到生产,绕不过 Rerank》
“RAG 里召回是什么意思?”
“就是把用户问题转成向量,然后去向量数据库里搜相似文档。”
“那为什么很多生产级 RAG 不只用向量召回?BM25 有什么价值?Hybrid Search 怎么合并结果?Query Rewrite 和 HyDE 分别解决什么问题?”
这个场景太常见了。
很多人学 RAG,只学会了一个流程:
用户提问,转向量,查向量库,塞给大模型。
但真实项目里,RAG 回答不准,很多时候不是大模型不会答,而是正确材料一开始就没被召回来。
召回,是 RAG 系统的第一道关。
这道关没过,后面的 Rerank、Prompt、LLM 再强,也是在错误材料上努力。
今天这篇,我们就把 RAG 面试里最核心的召回策略讲透。
3个误区:召回不是向量检索
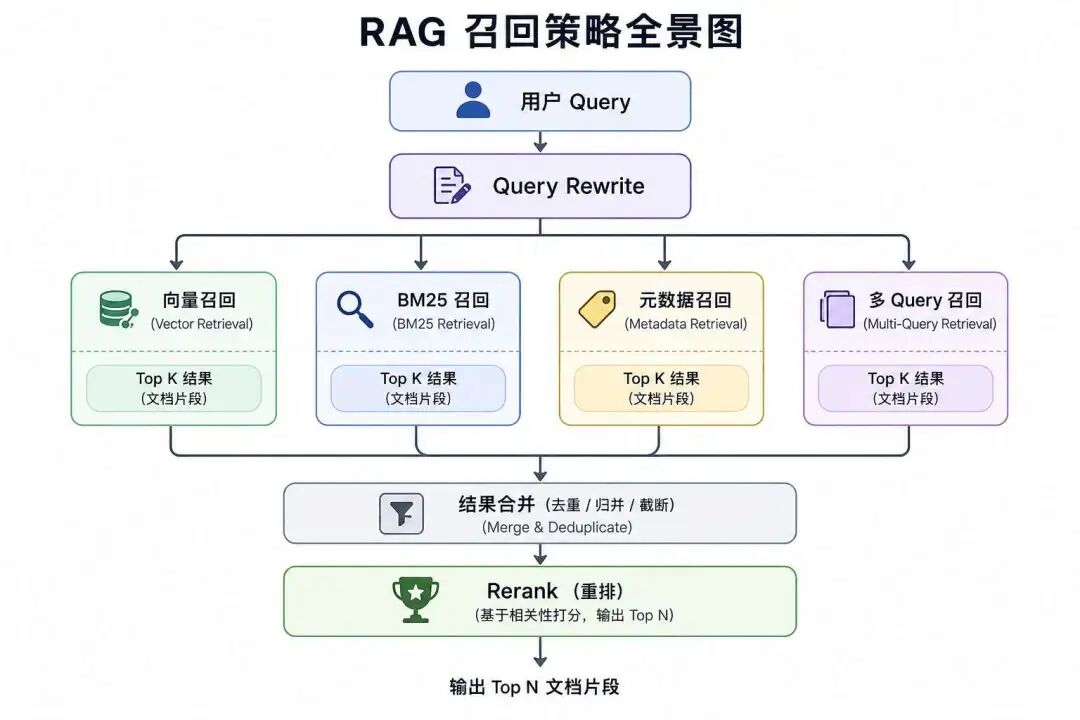
一、面试官问:RAG 中的召回是什么意思?
新手回答
召回就是从向量数据库里找出和用户问题最相似的文档片段。
高手回答
召回是从大规模知识库中,快速筛选出一批可能和用户问题相关的候选文档。
它的目标不是一步到位找到最终答案,而是尽量不要漏掉正确材料。
在 RAG 里,召回阶段更关注 Recall,也就是正确内容有没有被找回来。
至于这些候选内容谁更相关,谁应该排前面,可以交给后面的 Rerank 和生成阶段继续处理。
所以召回的核心原则是:
先把可能有用的内容捞回来,再让后面的模块做精排和筛选。
面试时要强调一点:
召回不等于向量检索。
向量检索只是召回方式之一。
生产级 RAG 往往会同时使用向量召回、关键词召回、元数据过滤、规则召回、Query 改写和多路召回。
二、为什么单纯向量召回不够?
向量召回的优势是语义理解。
用户问法和文档写法不一样,它也可能找得到。
比如用户问:
“员工离职之后还能不能拿年终奖?”
文档写的是:
“劳动关系终止后,奖金发放依据绩效周期和公司制度执行。”
关键词不完全一致,但语义相关。
向量召回有机会命中。
但向量召回也有明显短板。
第一,对精确词不敏感
比如用户问:
“GPT-4o 的上下文窗口是多少?”
这里的 GPT-4o 是精确模型名。
如果向量召回只理解成“大模型上下文窗口”,可能召回一堆 GPT-4、Claude、Gemini 的文档。
但用户要的是 GPT-4o。
第二,对数字、编号、代码、专有名词不稳定
合同编号、订单号、函数名、类名、产品型号、法规条款,这些内容更适合关键词匹配。
Embedding 模型不一定能准确保留这些精确符号。
第三,容易语义漂移
用户问一个很具体的问题,向量召回可能捞回一堆“看起来相关但不能回答问题”的内容。
比如用户问“RAG 里 RRF 怎么实现”,向量召回可能召回“RAG 召回策略介绍”,但里面没有 RRF 的实现细节。
所以只靠向量召回,容易出现“看起来相关,实际没用”的问题。
三、为什么单纯关键词召回也不够?
关键词召回的代表是 BM25。
它的优势是精确匹配、可解释、稳定。
但它不理解语义。
比如用户问:
“怎么让大模型少编答案?”
文档里写的是:
“通过检索增强和引用约束降低幻觉。”
如果没有关键词重合,BM25 可能召回不到。
再比如用户问:
“新人入职多久有年假?”
文档写的是:
“员工连续工作满一年后享有带薪年休假。”
关键词不完全一致,但语义明显相关。
这就是关键词召回的短板。
所以面试时可以这样答:
向量召回擅长语义匹配,但对精确词不稳定。关键词召回擅长字面匹配,但不理解语义。两者互补,所以生产级 RAG 常用混合召回。
四、BM25 是什么?
BM25 可以理解为关键词检索里的经典打分算法。
它会根据几个因素给文档打分。
第一,用户 query 里的词有没有出现在文档里。
第二,出现次数多不多。
第三,这个词是不是稀有词。
第四,文档长度会不会影响判断。
简单说,如果一个词在用户问题里出现,在某篇文档里也出现,而且这个词不是到处都有的普通词,那这篇文档的得分就会更高。
BM25 比普通词频更聪明的一点是:
它不会认为一个词出现 100 次就一定比出现 10 次重要 10 倍。
它会对词频做饱和处理。
同时,它也会考虑文档长度。
同样命中一个关键词,短文档里命中可能比超长文档里命中更有价值。
面试里不用背公式,但要说清楚 BM25 的价值:
它解决的是字面匹配和精确术语召回问题,是向量召回的重要补充。
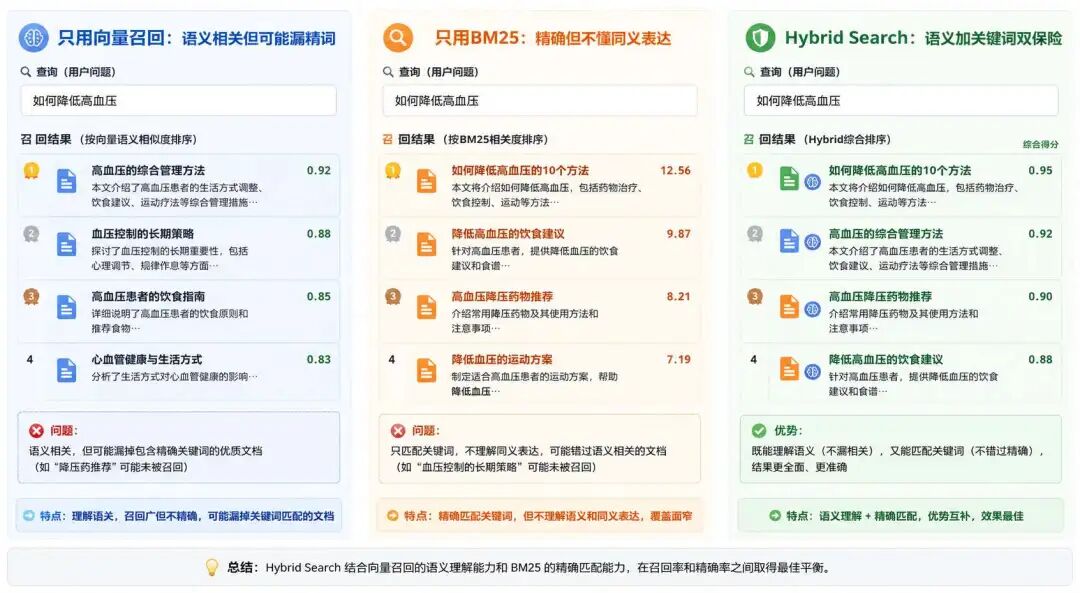
五、什么是混合召回?
混合召回就是同时使用多种召回方式,再把结果合并。
最常见的是:
向量召回 + BM25 关键词召回。
也就是 Hybrid Search。
比如用户问:
“LangChain 里 ConversationBufferMemory 怎么用?”
向量召回可能找到:
“多轮对话记忆机制设计”
“Agent 记忆模块实现”
BM25 可能找到:
“ConversationBufferMemory 使用示例”
“LangChain Memory 源码分析”
这两类结果都有价值。
向量召回负责找语义相关。
BM25 负责抓关键词精确命中。
合在一起,召回质量就更稳。
这也是为什么工业界常用 Hybrid Search。
因为真实用户的问题既有语义表达,也有精确术语。
单一路线很难覆盖所有情况。
3种合并:Hybrid Search怎么稳
六、多路召回后怎么合并结果?
这是面试里很容易被追问的点。
假设向量召回返回 50 条,BM25 返回 50 条。
怎么合并?
不能简单把分数加起来。
因为向量相似度和 BM25 分数不是同一个尺度。
向量相似度可能在 0 到 1 之间。
BM25 分数可能是 3、20、100,没有固定上限。
直接相加会很不公平。
常见做法有几种。
第一,分数归一化后加权
把不同召回通道的分数统一到相近范围,再按权重合并。
比如向量分数占 0.6,BM25 分数占 0.4。
这种方式可解释,但权重需要调。
如果没有标注数据,权重很容易拍脑袋。
第二,RRF 排名融合
RRF 是 Reciprocal Rank Fusion,倒数排名融合。
它不看不同通道的原始分数,只看排名。
一个文档在某路召回里排得越靠前,贡献越大。
如果同一个文档在向量召回和 BM25 里都排得靠前,它最终得分会更高。
RRF 的好处是简单、稳定、不太依赖分数尺度。
所以很多混合召回系统会优先用 RRF 做结果融合。
第三,学习排序
如果你有足够标注数据,可以训练一个融合模型,综合向量分数、BM25 分数、标题命中、点击率、文档热度、更新时间等特征。
这种方式效果上限更高,但实现成本也更高。
面试时可以这样答:
冷启动阶段我会优先用 RRF,因为它不依赖不同召回通道的分数可比性。有标注数据之后,可以再考虑分数加权或学习排序。
4类改写:让Query更好检索
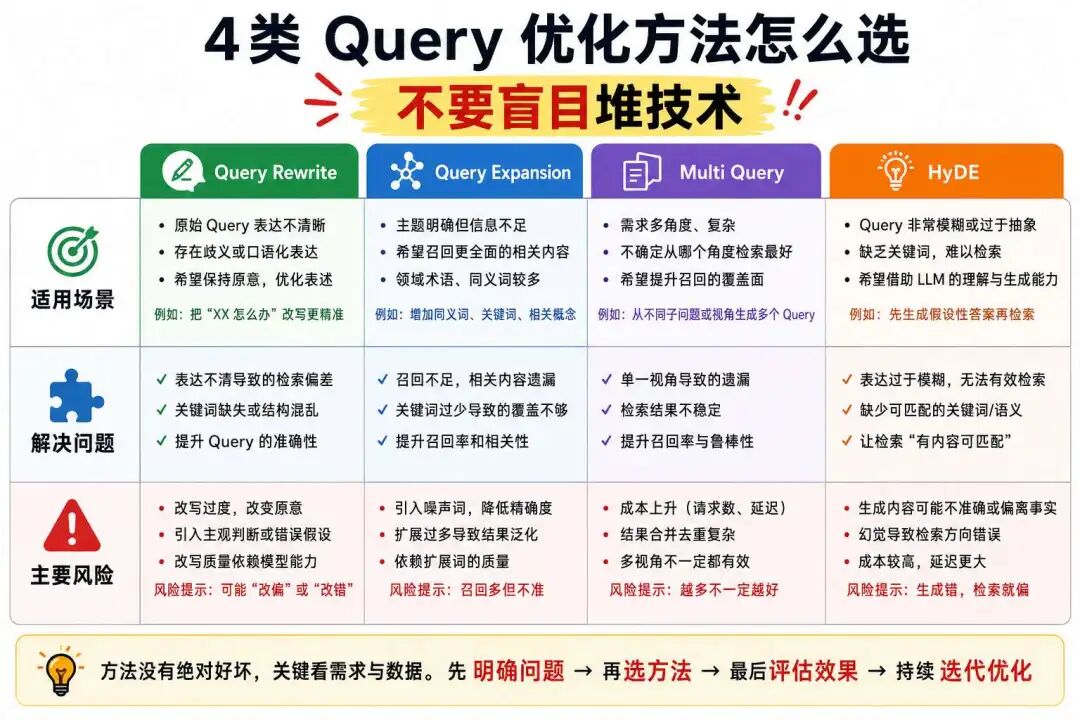
七、Query Rewrite 是什么?
用户原始问题经常不适合直接检索。
比如用户问:
“那这个怎么配?”
如果没有上下文,系统根本不知道“这个”指什么。
Query Rewrite 就是把用户问题改写成更适合检索的问题。
常见改写包括:
- 补全上下文
- 去掉口语化表达
- 修正错别字
- 提取核心术语
- 把模糊问题改成明确问题
比如在多轮对话里:
用户上一轮问:“Rerank 是什么?”
这一轮问:“那它什么时候用?”
系统可以改写成:
“RAG 系统中 Rerank 适合在什么场景使用?”
这样再去召回,效果会好很多。
Query Rewrite 的风险是:
改写错了会带偏检索。
所以生产里通常要保留原始 Query 和改写 Query,有时会一起召回,再合并结果。
八、Query Expansion 是什么?
Query Expansion 是查询扩展。
它不是改写原问题,而是在原问题基础上补充相关词。
比如用户问:
“怎么优化 RAG 检索效果?”
扩展后可以加入:
“召回、BM25、向量检索、混合搜索、Rerank、Query Rewrite、Recall@K”。
这样可以提高召回覆盖面。
但扩展也有风险。
如果扩展太多无关词,会引入噪声,导致召回变散。
所以 Query Expansion 要控制范围,最好结合业务词表、同义词表或大模型生成后做过滤。
九、Multi Query Retrieval 是什么?
Multi Query Retrieval 是让系统从多个角度生成多个查询,再分别检索。
比如用户问:
“RAG 和微调怎么选?”
系统可以生成几个子查询:
- RAG 适合什么场景?
- 微调适合什么场景?
- RAG 和微调的成本对比
- RAG 和微调能不能结合使用
然后分别召回,再合并结果。
它适合复杂问题、开放问题、多角度问题。
但缺点是成本和延迟更高。
因为每个子查询都要跑一次检索,有时还要调用大模型生成子查询。
所以 Multi Query 不一定每次都开。
可以只在复杂问题、召回结果置信度低、或者用户问题包含多个意图时使用。
十、HyDE 是什么?
HyDE 是 Hypothetical Document Embeddings,假设文档嵌入。
它的思路很有意思。
不是直接把用户问题转成向量去检索。
而是先让大模型根据用户问题生成一段“假设答案”或“理想文档”。
再把这段假设文档转成向量,去知识库里搜相似内容。
为什么这样可能有效?
因为用户问题往往很短,信息量少。
而一段假设答案包含更多背景词、专业术语和表达方式,更接近知识库里的文档形态。
比如用户问:
“怎么让检索更准?”
直接检索可能太泛。
HyDE 先生成一段关于“RAG 检索优化、混合召回、Rerank、Query Rewrite”的假设内容,再用这段内容检索,可能更容易命中相关文档。
但 HyDE 不是万能的。
如果问题是精确事实类,比如“某个政策的具体数值是多少”,大模型生成的假设答案可能编错。
用错误假设去检索,反而会误导系统。
所以 HyDE 更适合开放式、解释型、方法型问题,不适合高精确事实查询。
6步落地:项目排查有路径
十一、项目里怎么设计召回策略?
可以按这个顺序落地。
第一步,先做好基础向量召回。
选择合适的 Embedding 模型,调好 Chunk Size,确保最基础的语义检索可用。
第二步,加入 BM25。
解决专有名词、精确词、编号、产品名、代码名召回不稳的问题。
第三步,做混合召回合并。
冷启动阶段可以用 RRF。
有数据后再尝试加权融合或学习排序。
第四步,加入 Query Rewrite。
重点解决多轮对话、口语化表达和模糊问题。
第五步,按需加入 Multi Query 或 HyDE。
不要一上来就堆满所有技术。
复杂策略会增加延迟、成本和排查难度。
第六步,建立评估集。
用真实问题评估 Recall@K、MRR、NDCG,并抽样分析 bad case。
召回优化不是靠感觉,而是靠问题集和指标。
十二、如何判断是召回问题?
RAG 回答错了,不一定都是召回问题。
可以分三步排查。
第一,看正确文档有没有被召回。
如果正确 Chunk 没出现在 TopK 里,就是召回问题。
第二,看正确文档排第几。
如果在 TopK 里,但排得很靠后,可能是排序或 Rerank 问题。
第三,看正确文档是否进入 LLM 上下文。
如果进了上下文但模型没用好,才是 Prompt 或生成问题。
这个排查思路非常适合面试。
因为它体现了你能定位问题,而不是只会说“调 Prompt”。
十三、面试官追问清单
- 召回和排序有什么区别?
- 为什么 RAG 不能只用向量召回?
- BM25 的核心思想是什么?
- Hybrid Search 怎么实现?
- 向量召回和 BM25 的分数怎么合并?
- RRF 为什么适合多路召回融合?
- Query Rewrite 和 Query Expansion 有什么区别?
- Multi Query Retrieval 适合什么场景?
- HyDE 为什么有效?有什么风险?
- 召回 TopK 应该怎么设置?
- 召回效果怎么评估?
- RAG 回答错了,怎么判断是不是召回问题?
总结
最后总结一下。
召回是 RAG 的第一道关。
它决定正确材料有没有机会进入后面的流程。
面试时记住五句话。
第一,召回不是向量检索,向量检索只是召回方式之一。
第二,向量召回擅长语义匹配,但对精确词、编号、专有名词不稳定。
第三,BM25 擅长关键词精确匹配,但不理解语义。
第四,生产级 RAG 常用 Hybrid Search 和多路召回,再通过 RRF 或排序模型合并结果。
第五,Query Rewrite、Query Expansion、Multi Query 和 HyDE 都是在优化用户 Query,但要根据场景使用,不要盲目堆技术。
下一篇我们讲 RAG 面经系列第 6 篇:Rerank 重排。
如果说召回负责“尽量别漏”,那 Rerank 就负责“把真正相关的排到前面”。
本文是「RAG 面试通关」系列的第 5 篇。下一篇预告:RAG 从 Demo 到生产,绕不过 Rerank,记得星标不走丢。
最近我把大家公认最容易翻车的 Agent 开发面试考点 整理成了一份 PDF,我自己面了不少人,也被面了不少次,这些东西说实话,外面那些面经基本看不到。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号