首个语音智能体端到端测评出炉:Grok登顶,真实场景通过率仅一半

首个语音智能体端到端测评出炉:Grok登顶,真实场景通过率仅一半

用户11563501
发布于 2026-06-23 14:06:28
发布于 2026-06-23 14:06:28
Artificial Analysis推出业内首个语音转语音(S2S)智能体端到端性能基准τ-Voice,专门测试语音智能体在真实客服场景下的工具调用和多轮交互能力。
此前语音智能体测评大多停留在转录准确率、单轮响应延迟这些基础指标,很少关注模型能不能真正帮用户完成改机票、处理退货这类完整流程。τ-Voice补上了这个缺口,测试场景完全贴近真实生产环境:给模拟用户加上不同口音、背景噪音,模拟真实网络下的丢包情况,任务覆盖航空、零售、电信三个常见客服领域,共278个真实场景,最终通过任务完成后的数据库状态判断是否成功。
测试结果打破了不少人的认知:哪怕目前最强的S2S模型,端到端完整解决真实客服任务的成功率也刚过一半,和同任务下顶级文本智能体的表现差距明显。
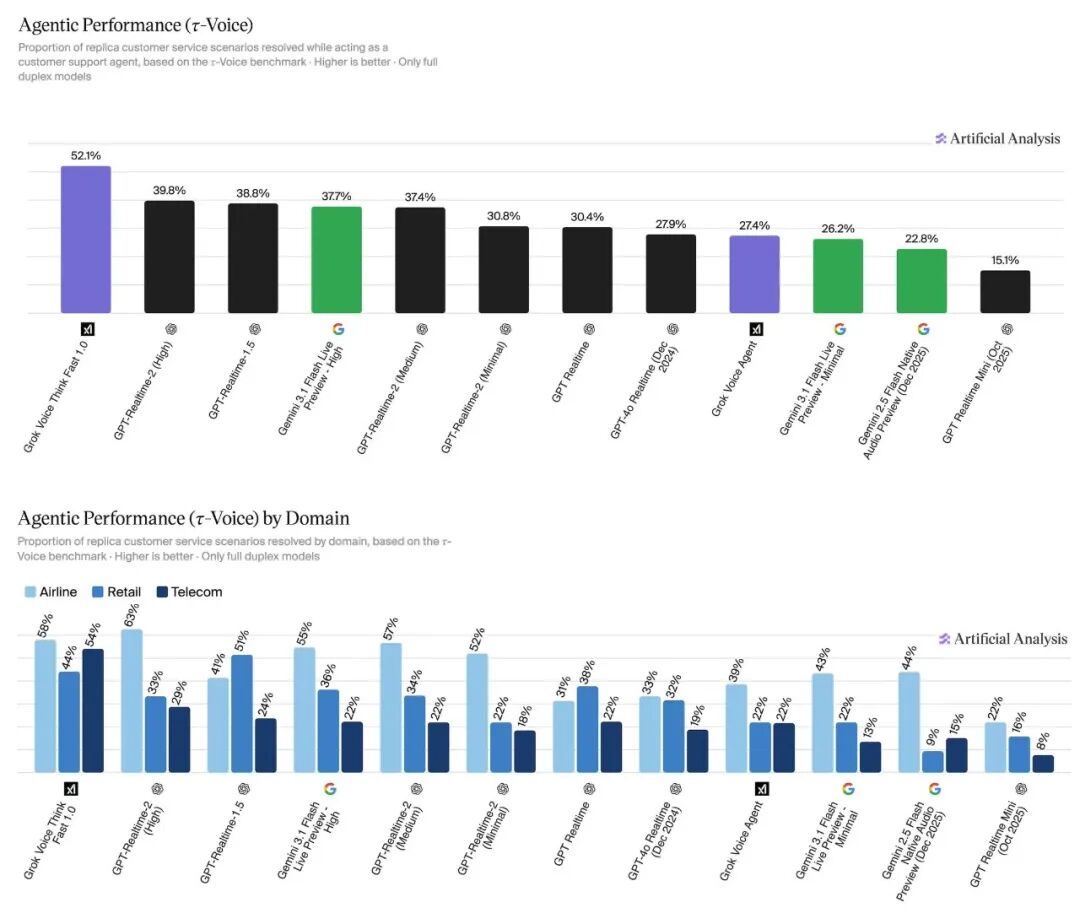
各模型端到端任务成功率对比
各模型端到端任务成功率对比
这份测评结果出来后,马斯克第一时间在X平台转发,时间是2026年5月12日。他旗下xAI的Grok Voice Think Fast 1.0拿下第一,解决率达到52.1%。具体排名里,第二名OpenAI GPT-Realtime-2(High)成功率39.8%,GPT-Realtime-1.5以38.8%排第三,谷歌Gemini 3.1 Flash Live Preview - High以37.7%排第四。Grok成绩比OpenAI几天前刚发布的GPT-Realtime-2 High版本高出12.3个百分点,甩开二三名不少。完整排名如下:
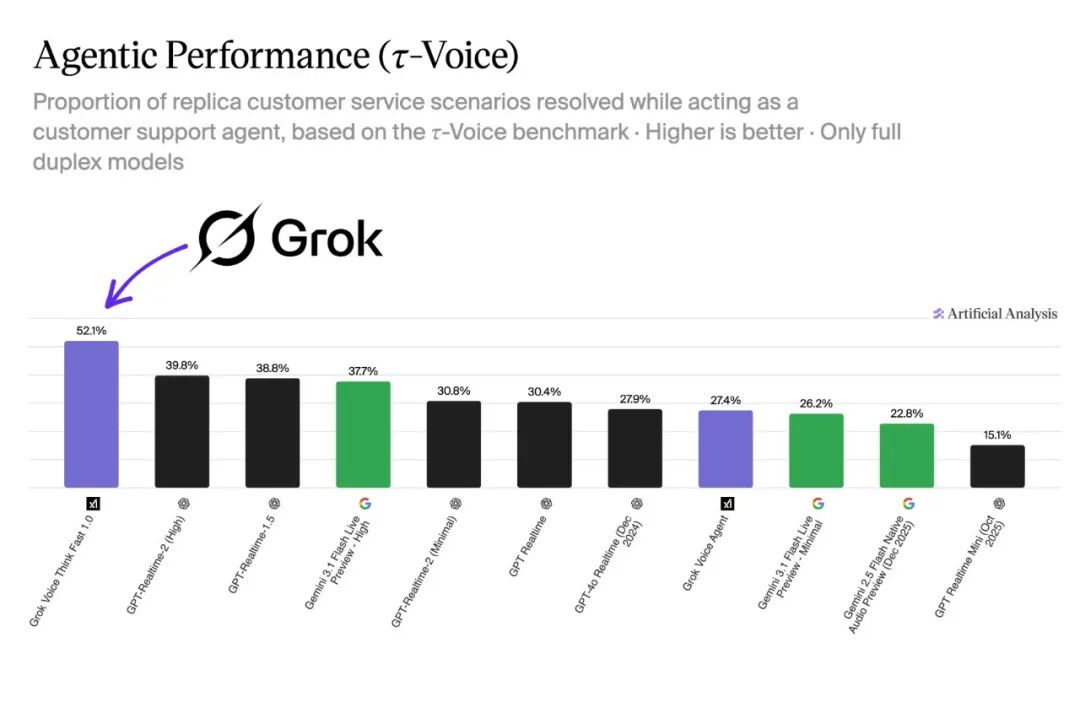
Agentic Performance(τ-Voice)测试结果
Agentic Performance(τ-Voice)测试结果
除了任务成功率,测评还统计了每个模型的平均对话时长,这个指标直接关系用户体验和企业运营成本。所有模型平均对话时长都控制在7分钟以内,最短的是Gemini 2.5 Flash Native Audio Preview,仅2.4分钟;最长的是GPT Realtime Mini,达6.4分钟;排名第一的Grok Voice Think Fast 1.0平均对话时长5.6分钟,排在第二。
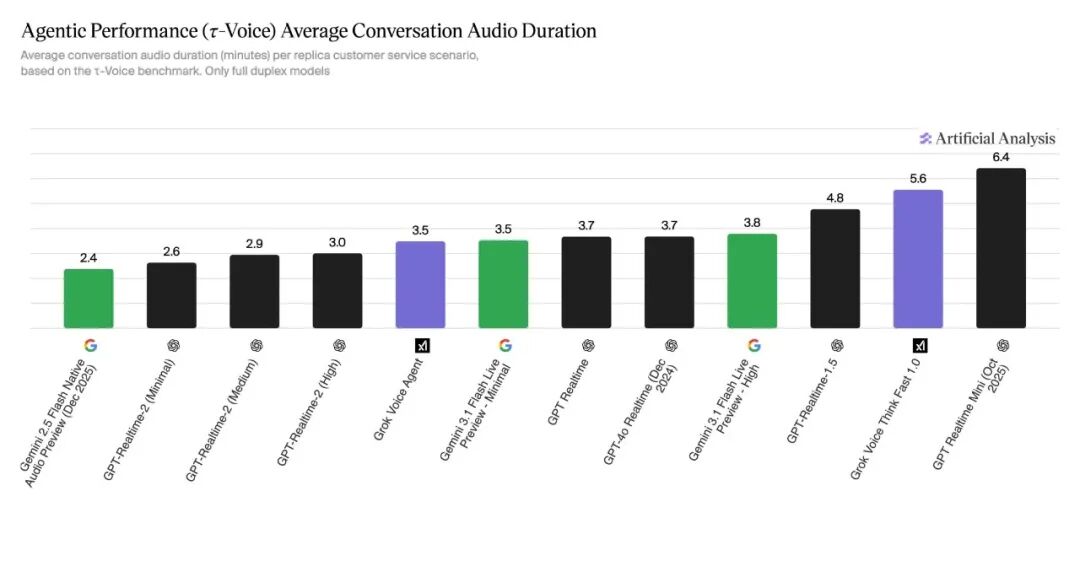
各模型平均对话时长对比
各模型平均对话时长对比
发布测评的X用户XFreeze提到,Grok能实现实时后台推理,同时不带来额外延迟,这也是它已经能规模化自主处理Starlink电话客服的原因。马斯克转发后,直接邀请用户尝试Grok Voice功能。此前马斯克曾提到,Grok用到了和物理学研究同等级别的算力,甚至可以输出物理精度的黑洞模拟,相关视频如下:
推文发出后引来上千条讨论,各方观点差异不小。
有从业者认为,在延迟不增加的前提下实现性能提升,是实打实的技术突破,语音AI竞争已经进入新阶段。也有网友调侃,从性能差距看,Grok已经把OpenAI甩得看不见尾灯,马斯克从卫星到语音客服的全链路整合,已经超出很多公司的布局节奏。业内对这个基准的推出普遍认可,有网友指出,之前大部分测评都停留在转录质量,真实流程里的智能体成功率才是生产环境真正关心的指标。
但质疑的声音也不少。
有普通用户反馈,Grok Voice目前语音选项少,部分语音效果不佳,付费SuperGrok用户已经被限制使用次数,实际使用还会遇到连接问题和速率限制。老用户吐槽,Grok长期缺乏长时记忆,除了闲聊和简单搜索,没法用在工作或学习场景。也有用户反馈,多次试用下来实际体验不如ChatGPT,不推荐使用。
从技术视角看,争议主要集中在三点:
第一,不少人提到,现在AI行业基准测试类似F1赛车,测试成绩不代表实际使用体验,测评领先不代表产品更好用。
第二,就算测试成绩好看,真实场景的复杂对话才是试金石。有用户举例,用户凌晨投诉包裹延误、全程情绪激动还频繁改诉求,这种场景下多少顶流模型都会掉链子。更关键的是,目前还没有语音模型能解决长对话中的事实一致性问题——声音自然但全程瞎编,还不如声音机械但说的都对。
第三,已有实际用户反馈,Grok Voice虽然速度快,但经常给出肤浅甚至错误的答案,Grok自己都承认"跑分调优是最大的原因"。

用户反馈Grok Voice存在事实错误问题
用户反馈Grok Voice存在事实错误问题
有网友提出更尖锐的观点:基准里的52%已经是理想测试环境的结果,放到真实呼叫中心的复杂场景里,实际成功率只会更低。还有人补充,现在只测了最终工具调用成功率,中途模型出错后的恢复能力才是真正难点,也是未来基准需要补上的部分。还有网友点出,现在说规模化落地自动语音客服,本质是把人工审核成本转移到了其他部门——速度是功能,可靠才是产品。
目前已经有用户放出Grok Voice实际体验视频,感兴趣可以查看:
可以确定的是,语音AI已经成为当前巨头竞争的核心战场,几乎每隔几周就有性能层面的新突破。语音转语音智能体还是一个快速进化的领域,这次测评只是一个起点,未来随着模型能力提升,排名肯定还会变化。但这个基准已经照出了行业现状:语音智能体还远没到"解决"的阶段,真实复杂环境下的可靠性,才是接下来要啃的硬骨头。跑分只是第一步,真正能在实际场景站稳,还需要解决事实准确、延迟稳定、长对话记忆这些用户真能感知到的问题。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号