大模型 “幻觉” 之谜:本质、成因与防御


导读:近年来,以GPT、LLaMA、DeepSeek为代表的大语言模型席卷全球,展现出惊人的文本生成能力。然而,这些模型常常会“一本正经地胡说八道”——生成看似合理实则错误甚至荒谬的内容,这种现象被称为模型幻觉。幻觉问题严重制约了大模型在医疗、金融、法律等高风险领域的落地应用。本文将从信息论和概率建模的角度,系统剖析幻觉的数学本质、成因机理、潜在风险以及工程化解法,帮助大家建立起对大模型“撒谎”行为的系统性认知。
1
幻觉的本质:事实性与忠实性的双重失配
学术界将大模型幻觉划分为两大经典类别 [2]:
- 事实性幻觉(Factuality Hallucination):生成内容与客观事实不符。示例:错误表述 “中国的首都是上海”。
- 忠实性幻觉(Faithfulness Hallucination):生成内容与用户输入、上下文逻辑自相矛盾。示例:用户询问苹果颜色,模型回答 “苹果是蓝色的”。
1.1 事实性幻觉的数学形式
真实世界的事实分布为P*(y∣x),大模型学习到的分布为Pθ(y∣x),。对于给定输入 x,幻觉发生的概率等价于模型预测与事实之间的KL散度超过某个阈值:
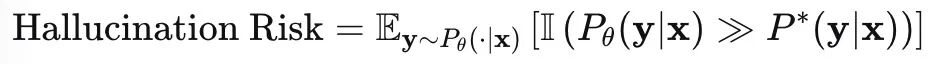
更直观地,对于一个事实性陈述 s,我们可以定义其真值函数Truth(s),那么模型生成的幻觉程度可以表示为:
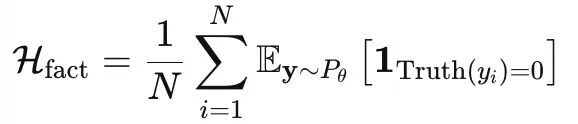
1.2 忠实性幻觉的数学形式
忠实性幻觉更关注条件依赖性。给定输入 x 和已生成的前缀 y<t,模型应该保持内容的一致性。这种不一致性可以用自相矛盾概率来度量:
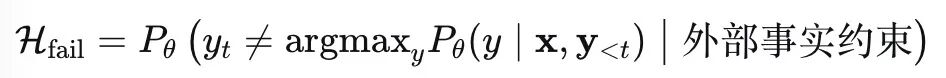
简而言之,幻觉的本质是模型对条件概率分布的过度泛化与记忆错位。
2
幻觉的成因
幻觉并非单一问题导致,而是数据、训练、推理、模型架构全链路因素共同作用的结果。
2.1 数据层面:噪声、偏见与长尾知识缺失
大模型训练语料来源于互联网,天然混杂大量错误信息、过时观点、虚假内容。模型通过最大似然估计 (MLE) 完成训练。若训练数据本身存在错误样本,模型会学习到错误的概率分布。
同时,互联网知识存在长尾分布,低频冷门事实样本极少,模型无法充分学习,只能依靠泛化猜测,进一步加剧幻觉。
2.2 训练层面:最大似然的局限性
MLE目标鼓励模型将概率质量集中在训练集中出现过的输出上,但这种“老师强制教学”的方式有两个缺陷:
- 暴露偏差(Exposure Bias):训练时每一步都基于真实的前缀,而推理时基于自己生成的前缀,累积误差导致幻觉。
- 对数概率的均匀化:对于语义相似的多个正确答案,模型可能将概率分散,而对错误答案也不够低。
2.3 推理层面:解码策略的副作用
生成时的解码策略显著影响幻觉率。以常用的温度采样为例:
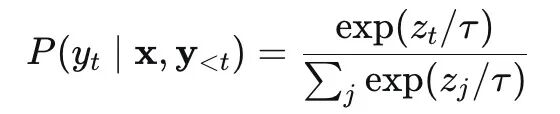
其中zt是logits,τ是温度参数。当τ >1 时,输出分布变得平坦,模型更可能采样到低概率(从而可能错误)的token。Top-k 和 Top-p 采样同样会引入随机性,增加幻觉风险。
而贪心解码(τ→0)虽然确定性更高,但仍可能陷入高概率的幻觉路径。例如模型反复生成“I don’t know”可能被惩罚,于是选择编造一个看似合理的答案。
2.4 架构层面:Transformer的归纳偏置
Transformer的自注意力机制虽然强大,但其位置编码和有限上下文窗口限制了模型对长程事实的精确引用。当所需事实位于上下文窗口之外,或者被注意力机制“忽略”时,模型只能依赖参数化记忆,而参数化记忆是有损压缩的。
这种近似检索不可避免会产生压缩失真,尤其是在需要精确数值、日期、名称的场景。
3
幻觉的系统性风险
模型幻觉不只是体验问题,在落地场景中会引发多类严重风险:
风险类别 | 具体表现 | 典型场景 |
|---|---|---|
安全风险 | 生成虚假医疗建议、错误操作指令 | 医疗咨询、自动驾驶决策 |
法律与合规风险 | 捏造法律条文、伪造合同条款 | 法律文书辅助、审计报告 |
信任侵蚀 | 输出错误内容,降低用户对 AI 的信任 | 智能客服、在线教育问答 |
信息污染 | 幻觉内容被爬虫抓取,回流成为新训练语料,污染下一代模型 | 互联网公开语料循环训练 |
4
防御方案:从算法到工程
目前学术界与工业界已形成多套成熟的幻觉防御体系,以下介绍主流方案及原理。
4.1 检索增强生成(RAG)
核心思路:生成前从外部知识库检索相关资料,将检索结果并入上下文,弱化模型参数记忆的依赖。
注意:检索环节本身会引入噪声,工程落地需搭配结果重排序、相关性阈值过滤。
4.2 事实性采样解码(对比解码)
通过强弱双模型 logits 差值抑制幻觉,弱模型幻觉倾向更强,抵消其干扰项。该方案无需重新训练模型,属于推理阶段优化,落地成本低。
4.3 自我反思与验证
让模型对自身输出做二次校验,典型实现为思维链验证:
- 模型生成初始回答y;
- 下发校验指令,要求模型逐条核查内容事实;
- 根据校验结果修正最终输出。
数学形式等价于引入后验修正因子:
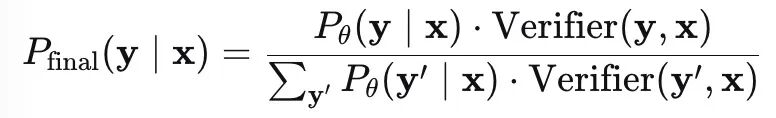
Verifier(y,x) 为事实校验模型输出的忠实性得分。
4.4 基于不确定性的主动拒绝
模型判断自身置信度不足时,主动拒绝作答。行业常用预测熵衡量不确定性:
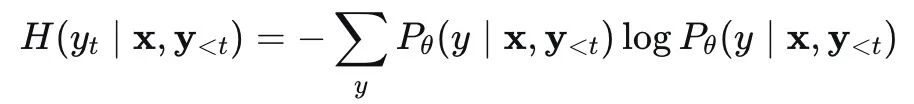
当熵值超过预设阈值 τH,模型输出 “信息不足,无法回答”。进阶方案可使用语义熵,消除词表噪声,结果更稳健。
4.5 示例代码:温度参数与幻觉量化实验
下方代码模拟温度参数对输出分布熵的影响,直观证明:温度越高、不确定性越强,幻觉概率越高。依赖库:torch、transformers,可直接运行。
import torch
import torch.nn.functional as F
def compute_entropy(logits, temperature=1.0):
"""计算给定logits和温度下的预测熵"""
scaled_logits = logits / temperature
probs = F.softmax(scaled_logits, dim=-1)
entropy = -torch.sum(probs * torch.log(probs + 1e-8), dim=-1)
return entropy.mean().item()
# 模拟高不确定性logits:多个Token置信度接近
logits_uncertain = torch.tensor([[2.0, 2.1, 1.9, 1.8, 2.2]])
print(f"T=0.5 熵: {compute_entropy(logits_uncertain, 0.5):.4f}")
print(f"T=1.0 熵: {compute_entropy(logits_uncertain, 1.0):.4f}")
print(f"T=1.5 熵: {compute_entropy(logits_uncertain, 1.5):.4f}")运行输出参考:
T=0.5 熵: 0.0532
T=1.0 熵: 1.6094
T=1.5 熵: 1.8576结果可见:温度参数越大,分布熵越高,模型随机性越强,越容易产生幻觉。
5
结论与展望
大模型幻觉是概率生成本质、训练数据缺陷、模型架构限制共同造成的必然现象。
单一方案无法彻底根除幻觉,工业落地最优实践为组合策略:RAG 检索增强 + 对比解码 + 模型自我校验叠加使用;高风险场景必须配套人工审核闭环。
未来随着模型可解释性技术、事实性奖励模型不断成熟,有望在训练阶段从根源降低幻觉倾向。理解幻觉背后的数学与原理,是搭建可靠大模型应用的基础。
参考文献
[1] Zhang, Y., et al. (2023). Siren’s Song: Understanding and Mitigating Hallucination in Large Language Models. arXiv preprint arXiv:2309.01234.
[2] Ji, Z., et al. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), 1-38.
[3] Li, K., et al. (2024). Contrastive Decoding: A Training-free Approach to Reduce Hallucination. ICLR 2024.
[4] Shuster, K., et al. (2022). Retrieval Augmentation Reduces Hallucination in Conversation. EMNLP 2022.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号