世界模型四大技术路线深度研究清单


最近突然发现还有个世界模型的比赛,看来语言大模型终究还不是世界模型,那就看看目前这个领域的研究情况和进展。
因为人工智能行业已经开始从"数字世界"进入"物理世界"。
过去两年,大模型主要解决的是写代码、写文案、做PPT、回答问题,本质上AI理解的是语言构建出来的世界。
但是具身智能(就是机器人)和自动驾驶要面对真实世界,需要遵循物理定律,视觉获得信息,通过严谨的推理来指导一步行动,否则一不小心就要造成灾难性的后果。
而语言大模型从底层基础,技术架构上就不支持这点,比如 Sora 生成的视频就发现过不遵守物理规则的现象。
于是,随着具身智能的推进,世界模型开始成为AI行业最新的研究方向。
24年Google DeepMind发布世界模型Genie 2,可通过单张图片生成可交互3D世界;
25年NVIDIA推出Cosmos平台,专门用于训练机器人与自动驾驶世界模型;
"AI教母"李飞飞创办的World Labs,目标就是要研发世界模型。
2026年5月29日,被誉为全球世界模型"终极试金石"的WorldArena榜单公布结果。
在世界模型感知与动作响应赛道:
智元创新 自主研发的世界模型 GenieEnvisioner-Sim2.0(GE 2.0) 位列第一。
考拉悠然 联合码极客和同济大学空间智能团队打造的 "考拉悠然无界世界模型" 位列第二。
GE 2.0仅用 20亿(2B)参数 的模型,效果优于英伟达、微软等超大参数旗舰模型,验证了在人形机器人应用方面,轻量化模型的适配性不逊于超大参数模型。
世界模型的起源与概念框架
"世界模型"并非新词。最早可追溯到 1943年,肯尼斯·克雷克(Kenneth Craik)提出人脑依靠构建现实的"微型模型"完成逻辑思考。
上世纪80年代末至90年代初,这一理念被引入神经网络研究。
现代"世界模型"的技术定义来自强化学习的 POMDP(部分可观测马尔可夫决策过程) 框架:
智能体 → 执行动作 → 改变环境状态 → 获取观测信息 → 指导新动作 → 循环- • 环境状态:对某一时刻客观环境的完整描述(所有物体的位置、速度与属性),理论上信息完整。
- • 观测:智能体对客观世界的局部感知(视网膜光子、传感器读数、视频像素)。
- • 动作:智能体基于感知做出的反馈行为。
如今各类世界模型产品,本质都是这套闭环的不同实现方向,各自只输出闭环中的某一部分信息。
"语言模型学习文本的统计规律,世界模型则学习时空的统计规律: 光线如何落在物体表面、不在相机拍摄视角下的花园是什么模样、物体受外力后如何运动并遵循物理定律。" —— 李飞飞
李飞飞与World Labs团队发布《世界模型的功能分类》,将世界模型归纳为三大功能类别:
类别 | 输出 | 评判标准 | 代表 |
|---|---|---|---|
渲染器(Renderer) | 像素画面(供人观看的观测信息) | 视觉还原度 | Sora、Genie 3、RTFM |
仿真器(Simulator) | 环境状态(几何/物理/动力学层面贴合客观规律的表征) | 结构真实性 | Omniverse、Marble |
规划器(Planner) | 动作指令(依托观测与目标,给出下一步行动方案) | 决策有效性 | VLA模型、WAM、DreamZero |
World Labs世界模型三大功能模块拆解示意图:
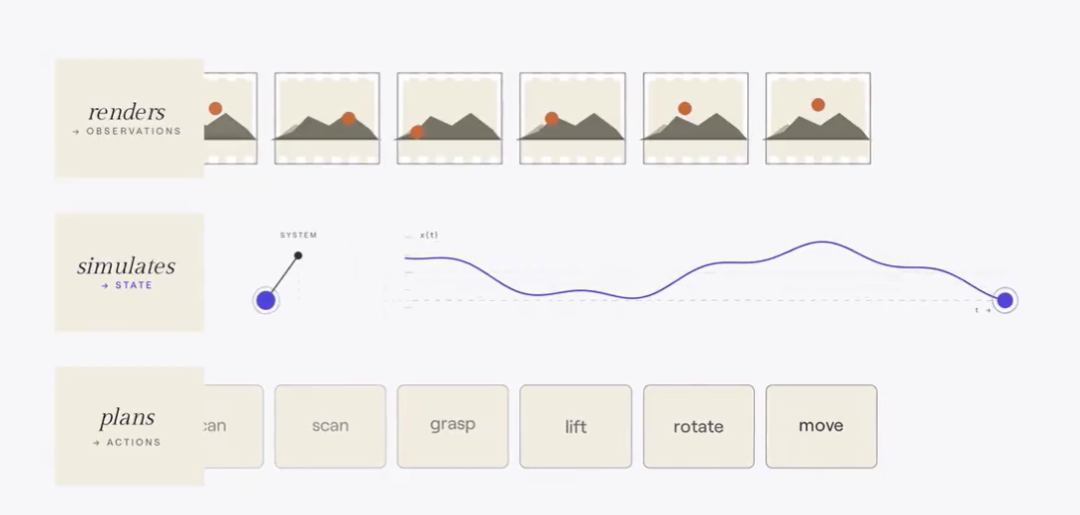
三者关系:渲染器输入动作、输出观测画面;规划器输入观测信息、输出动作指令——互为逆过程。
仿真器是衔接二者的桥梁,底层共用几何、物理、动力学这套描述世界运行逻辑的基础知识。
渲染器商业化最成熟,但能力有上限,视觉逼真≠物理精准,无法用于建筑设计、机器人训练。
规划器前景最受期待,但技术尚处起步阶段,绝大多数演示局限在实验室环境。
仿真器关注度最低,却具备最深远的产业价值,仅NVIDIA Omniverse潜在市场规模超万亿美元。
终极形态:三类模型边界正不断消融,最终走向能够灵活切换输出形式的大一统世界基础模型。单一基座模型既能生成照片级渲染画面、输出符合物理规律的环境结构,又能生成动作序列。
分类与技术路线的关系
分类 | 对应技术路线 | 说明 |
|---|---|---|
渲染器 | 路线二(显式画面重建)+ 路线四(状态-渲染解耦的上层) | Sora/Genie是纯渲染器;Eden的渲染层也是渲染器 |
仿真器 | 路线四(状态-渲染解耦的底层状态层)+ 路线一(JEPA的隐空间表征) | Eden的结构化状态层本质是仿真器;JEPA学习的隐空间也是一种仿真 |
规划器 | 路线三(WAM/VLA) | DreamZero等WAM直接输出动作指令 |
跨类别 | 路线一(JEPA)的V-JEPA 2 → 规划器 | JEPA从纯特征预测走向机器人零样本规划,正在跨越仿真→规划的边界 |
李飞飞的观点:真正掌握杯子在桌面的几何形态、材质、受力规律的模型,既能从任意角度渲染杯子画面,也能仿真杯子被碰倒的全过程,还能规划机械手抓取动作。 三类应用只是同一套底层世界认知的三种落地形式。
以李飞飞的分类框架分析,WorldArena榜单中出现的各模型所走的技术路线:
智源创新的GenieEnvi-sioner-Sim2.0 属于仿真器+规划器组合。
考拉悠然无界世界模型属于仿真器 + 渲染器组合。
清华+斯坦福团队的Ctrl-World属于仿真器主导,研究侧重环境状态的理解与控制,在感知赛道强调对物理世界的结构化表征能力。
英伟达GEAR 的 DreamZero 模型以规划器为主导,WAM路线代表,140亿参数直接输出动作指令,同时通过视频动态先验隐式学习物理规律,也具备仿真器特征。
OpenAI的 Sora 属于纯渲染类,生成像素画面供人观看,不追求物理精准性,被认为不算真正的世界模型。
谷歌DeepMind 的 Genie 3属于渲染器 → 渲染器+仿真器演进中, 从纯画面生成(渲染器)逐步加入物理涌现和可编程规则(仿真器特征)。
World Labs(李飞飞)的 Marble 属于融合版的渲染器 + 仿真器已,单模型同时输出高斯泼溅画面(渲染器)与碰撞网格(仿真器)。
基于当前进展判断:
- 1. 纯单一类别已不存在 — WorldArena榜单上的参赛模型几乎全部是多类别组合,印证了李飞飞"三类边界正在消融"的判断。
- 2. 仿真器是必选项 — 所有面向物理世界的模型(机器人、自动驾驶)都必须包含仿真器能力,因为不理解物理规律就无法在真实环境中可靠运行。
- 3. 中国团队在仿真+规划的融合路径上领先 — GE 2.0以2B参数击败超大参数模型,说明在具身智能场景中,仿真精度和规划效率比参数规模更重要。
- 4. "轻量化"是产业化的关键 — GE 2.0的2B参数设计意味着可以部署在机器人端侧,而不需要依赖云端算力,这是从实验室走向量产的必要条件。
路线一:抽象空间模拟(LeCun / JEPA路线)
核心思想
彻底抛弃像素级重建,在抽象特征空间中预测未来状态。
引入隐变量建模不确定性,通过调整隐变量推演多种可能的未来。
代表人物 Yann LeCun 认为这是通往AGI的正确路径。
技术演进(14篇关键论文,5个阶段)
阶段 | 模型 | 关键突破 |
|---|---|---|
理论→图像 | JEPA → H-JEPA → I-JEPA | 概念起点;I-JEPA首次工程落地,多块掩码策略在隐空间学习语义表征 |
动态与跨模态 | MC-JEPA → V-JEPA → Audio-JEPA | V-JEPA证明特征预测可作为独立目标,训练速度比像素重建快2倍;跨模态通用性验证 |
三维几何 | Point-JEPA → 3D-JEPA | 点云和三维特征学习,为复杂世界模型扫清模态障碍 |
动作与规划 | ACT-JEPA → V-JEPA 2 | V-JEPA 2展现零样本机器人规划能力,未微调即可在未知环境多步推演 |
底层重构 | LeJEPA → Causal-JEPA → V-JEPA 2.1 → LeWorldModel → ThinkJEPA | LeJEPA引入SIGReg正则化,移除EMA等启发式技巧;LeWorldModel首次实现从原始像素端到端训练;ThinkJEPA融合视觉语言模型进行长周期逻辑推演 |
JEPA vs 自回归模型
维度 | JEPA | 自回归模型 |
|---|---|---|
核心机制 | 隐空间特征预测 | 逐token预测 |
训练目标 | 特征空间预测一致性 | 像素/文本重建误差 |
计算效率 | 高(V-JEPA快2倍) | 低 |
世界理解 | 物理常识+因果推理 | 文本模式,缺物理常识 |
规划能力 | 多步推演+零样本规划 | 有限 |
数据依赖 | 5%-10%标注即稳定 | 需大量标注 |
LeJEPA数学证明要点
- • 引入各向同性高斯正则化(SIGReg):约束隐空间分布,确保表征稳定可预测
- • 仅依赖特征预测损失+高斯正则化损失两个目标
- • 移除EMA、停止梯度等启发式技巧,训练流程简化
- • 为端到端架构(LeWorldModel)奠定数学基础
路线二:显式画面重建(视频生成)
核心思想
逐帧重建/生成视觉画面,通过像素序列预测来模拟物理动态。
更直观但侧重视觉外观,物理规律的理解是"涌现"出来的而非显式建模。
代表模型
Sora(OpenAI)
- • 核心技术:时空潜变量Patch(Spacetime Latent Patches),支持任意分辨率/方向输入
- • 规模定律:大幅增加参数和算力,涌现出3D一致性和物体持久性
- • 数据策略:DALL-E 3式高质量视频重标注
- • 已展现能力:3D一致性、长程连贯性、与世界互动(笔触、咬痕)的雏形
- • 核心局限:本质是预测像素序列,非显式理解物理规律;缺乏实时交互;存在大量反常规场景
- • 争议:LeCun等人认为Sora不算真正的世界模型
Genie系列(DeepMind)
版本 | 关键能力 | 架构 |
|---|---|---|
Genie 1 | 从无标签视频学习可交互性,推断"潜在动作" | 时空视频分词器 + 潜动作模型 + 110亿参数动力学模型 |
Genie 2 | 2D→3D跃升,键盘鼠标控制,长效记忆,涌现物理规律(重力、碰撞、光影) | 自回归潜在扩散模型 |
Genie 3 | 电影级画质+游戏级实时交互,24FPS/720p,数分钟场景持久,可编程世界事件 | 实时渲染+自然语言规则修改 |
其他代表
- • Dreamer系列(DeepMind):在潜在空间模拟学习,"在梦中试错"
- • World Labs(李飞飞):空间智能,单张图片生成可交互3D持久化环境
能力边界对比
维度 | Sora | Genie 3 | World Labs |
|---|---|---|---|
核心定位 | 视频生成→世界模拟器 | 可交互环境生成 | 3D空间理解与生成 |
交互性 | 单向生成,无实时反馈 | 双向交互,键盘鼠标控制 | 双向空间交互,可导航编辑 |
物理理解 | 涌现式,不显式 | 涌现式+可编程规则 | 3D几何+空间关系 |
持久性 | 有限(视频片段级) | 数分钟场景持久 | 持久化3D环境 |
主要用途 | 内容创作、物理模拟 | 具身智能训练沙盒 | 空间理解、3D内容、具身预训练 |
路线三:动作驱动
核心思想
跳过像素生成,直接理解物理交互并生成最优动作。
将世界预测与动作预测合并为一个闭环学习目标,联合预测未来世界状态与动作序列。
WAM定义
- • 数学形式:
p(o_{t+1:t+H}, a_{t:t+H} | o_{≤t}, language, robot_state) - • 不是传统"只预测未来视频"的世界模型
- • 不是传统"当前观测→动作"的VLA政策
- • 核心:同时输出未来视频/视觉特征与动作,两者互相正则化
WAM vs VLA vs 传统世界模型
维度 | VLA(如π0) | WAM(如DreamZero) | 传统世界模型 |
|---|---|---|---|
核心目标 | 观测→动作 | 联合预测未来状态+动作 | 仅预测未来状态 |
监督信号 | 稀疏动作标签 | 密集视频帧+动作 | 视频/状态转移 |
泛化能力 | 语义强,物理弱 | 跨场景/任务/具身 | 侧重预测精度 |
推理成本 | 低,适合高频控制 | 高(视频扩散),需优化 | 中等 |
失败模式 | 动作合理但后果不可见 | 视频可能美化失败 | 预测偏差累积 |
WAM四类技术架构
架构类型 | 核心 | 代表 | 输出 |
|---|---|---|---|
Joint Video-Action Policy | 视频生成模型直接做机器人策略 | DreamZero、MV-VDP、SAW | 未来视频+动作chunk |
Autoregressive Action World Model | VLA+世界模型放入同一AR序列 | WorldVLA | 动作token+future image |
Action-Conditioned Simulator | 生成可控可交互可反事实的未来世界 | GAIA-2、UniSim、Genie系列 | 可控未来视频 |
World-Model-Augmented Agent | 用世界模型评估动作后果 | Dreamer系列、Driving WMs | 风险评估+轨迹评分 |
代表性模型
工作 | 时间 | 关键贡献 |
|---|---|---|
DreamZero(NVIDIA GEAR) | 2026-02 | 140亿参数WAM,基于视频扩散骨干,零样本泛化超SOTA VLA 2倍,7Hz实时闭环控制 |
WorldVLA | 2025-06 | VLA+世界模型统一到单一AR框架,attention mask缓解误差传播 |
MV-VDP | 2026-04 | 3D状态投影为多视角视频,仅10条示教完成复杂真机任务 |
SAW | 2026-03 | 手术场景WAM,语言+参考帧+组织affordance条件生成手术动作 |
GAIA-2(Wayve) | 2025-03 | 自动驾驶多视角可控视频生成 |
自变量 WALL-WM | 2026 | 事件级预测,已开源WALL-OSS |
路线四:状态-渲染解耦
核心思想
底层状态推演与视觉呈现原生解耦。先推演世界下一刻的状态,再从该状态渲染画面。
解决传统视频生成模型在环境持久化、多视角一致性上的根本缺陷。
三层架构
层级 | 功能 | 特点 |
|---|---|---|
结构化状态层(底层) | 维护跨时间持续存在、可动作更新、可视角查询的全局世界状态 | 隐式表征,独立于观察者,回答"世界里有什么、发生了什么" |
条件接口层(中间) | 根据相机位置和观察视角,将全局状态转化为局部条件约束 | 语义信息+几何线索+局部事件变化,保证多视角一致性 |
生成式渲染层(上层) | 在状态+约束双重指引下生成精细化视觉画面 | 只需专注纹理、光照、材质、高频动态细节 |
与Sora/Genie的本质区别
特性 | Sora类视频预测器 | Project Eden世界模拟器 |
|---|---|---|
核心模式 | 根据历史像素预测下一帧像素 | 先推演世界状态,再从状态渲染画面 |
世界状态 | 无独立状态,信息压缩在帧历史中 | 拥有独立、持久、结构化的底层状态 |
物体持续性 | 离开视野即"消失",回来需"重新幻想" | 离开视野仍存在于底层状态 |
视角一致性 | 切换视角需重新生成,难保证一致 | 天然保证,不同玩家看到同一世界的不同窗口 |
交互本质 | 一次性单线程视频片段 | 可长期存在、多人同时进入、持续改变的交互环境 |
解锁的系统级能力
- 1. 环境长程持久化 — 物体离开视野不消失,转身回来查询同一底层状态
- 2. 场景自由复用与确定性控制 — 破坏/建造/改变被写入底层状态,其他用户看到一致世界
- 3. 原生多人与多智能体并发 — 1个底层状态 + N路渲染,计算成本从指数级降为线性级
路线综合对比
维度 | 抽象空间模拟(JEPA) | 显式画面重建(Sora/Genie) | 动作驱动(WAM) | 状态-渲染解耦(Eden) |
|---|---|---|---|---|
世界表征 | 隐空间特征向量 | 像素序列(视频帧) | 视频latent+动作token | 结构化底层状态 |
物理理解 | 显式学习因果+规划 | 涌现式,不显式 | 通过视频动态先验学习 | 状态推演保证物理一致性 |
交互性 | 隐空间推演 | Sora无/Genie有 | 联合预测状态+动作 | 原生多人持久交互 |
计算效率 | 高(不重建像素) | 低(像素级生成) | 中高(需视频扩散) | 高(1状态+N渲染) |
主要瓶颈 | 工程化落地慢 | 物理规律违反 | 推理成本高 | 架构复杂度高 |
代表机构 | LeCun/AMI Labs | OpenAI/DeepMind/World Labs | NVIDIA GEAR/自变量 | VAST |
商业化阶段 | 学术为主 | 内容创作已落地 | 机器人/自动驾驶验证中 | 游戏/空间计算探索中 |
融资规模 | AMI Labs 10.3亿美元 | — | NVIDIA自研 | VAST近2亿美元 |
融合趋势
业界正在走向融合,不再严格区分路线:
- 1. WAM = VLA + 世界模型:将世界预测的物理先验注入动作策略学习
- 2. JEPA → V-JEPA 2 → 动作规划:从纯特征预测走向机器人零样本规划
- 3. Sora/Genie → 具身训练沙盒:视频生成能力转化为机器人训练环境
- 4. Eden → 游戏+空间计算+具身:持久化世界状态服务多个下游场景
李飞飞论证了融合趋势的底层逻辑:
底层知识同源:几何、物理、动力学这套描述客观世界运行逻辑的基础知识,是渲染器、仿真器、规划器三者共用的底层原理。
能够从任意视角渲染杯子的模型,也可以仿真杯子被推倒后的状态、规划机械手抓取杯子的动作。
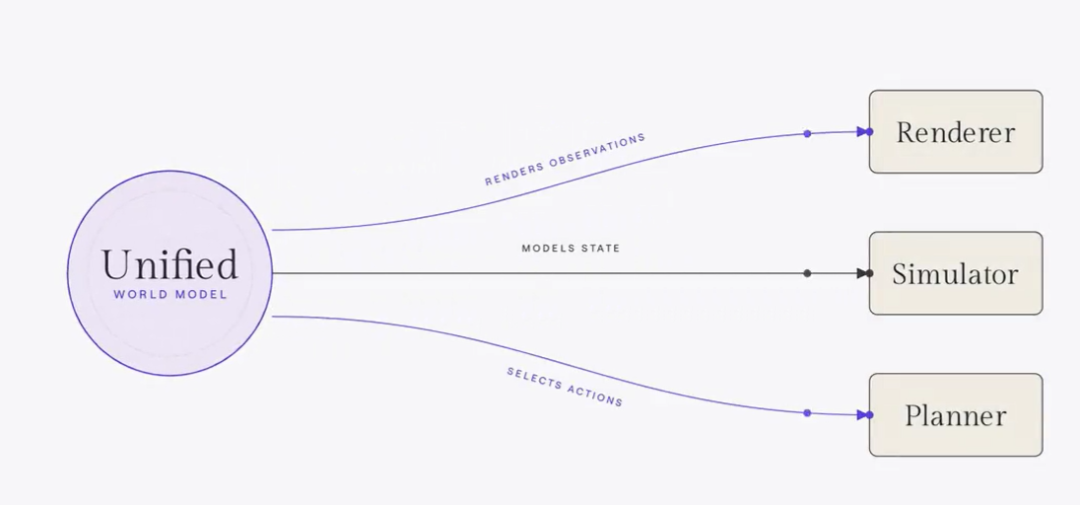
大一统世界模型架构图
融合的现实证据:
- • 多家机器人实验室证实:预训练视频渲染模型可作为环境与动作联合预测的底层基座,用单一模型预判环境变化与对应动作,打通渲染器和规划器的技术壁垒。
- • World Labs的Marble已实现单模型同时输出高斯泼溅画面与碰撞网格,打破渲染器和仿真器的界限。
- • 全品类产品都在从被动生成输出转向交互式系统:渲染器支持根据动作指令生成画面,仿真器产出的环境可调控可修改,规划器从被动应激式决策升级为自主推演式决策。
核心挑战:各类模型数据储备不均衡——渲染模型坐拥海量互联网视频素材,仿真与规划模型却紧缺三维资源与机器人实操数据。
在同一套模型架构中平衡各项需求,是当前世界模型领域最核心的攻关课题。
核心共识:未来的通用世界模型可能需要同时具备抽象理解(JEPA)、视觉生成(Sora/Genie)、动作输出(WAM)和状态持久化(Eden)四种能力。用李飞飞的话说,终极形态是能根据下游需求灵活切换输出形式的大一统世界基础模型。
推荐阅读:
比 Superpowers 更贴近AI编程工程实践的51 个 Agent 和 35 个技能
Hermes Agent 桌面端v0.5.0发布:从界面到功能体验的全面升级
Lazyweb 免费的 25.7 万截图库|让 AI 写出好看的前端页面
不用一个违禁词 让 Claude 说出炸药配方|红队攻击实录
大模型黑箱揭秘:GPT、Claude、Gemini、Grok、Hermes 系统提示词全公开
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号