Nat. Comput. Sci. | 改造大型语言模型以实现定向化学空间探索

Nat. Comput. Sci. | 改造大型语言模型以实现定向化学空间探索

DrugOne
发布于 2026-06-05 20:48:41
发布于 2026-06-05 20:48:41
2026年5月11日,加州大学伯克利分校、Promontory Labs与赫伯特·韦特海姆UF Scripps生物医学创新与技术研究所等机构的研究人员在《Nature Computational Science》发表题为“SmileyLlama: modifying large language models for directed chemical space exploration”的论文。

本文提出的SmileyLlama是一种把通用开源大语言模型Meta-Llama-3.1-8B-Instruct改造成化学语言模型的方法。作者使用约200万个来自ChEMBL v33的SMILES分子字符串,结合分子性质计算和工程化提示,对Llama进行监督微调(SFT),使其能够直接输出符合药物化学需求的分子SMILES。与仅把LLM当作“会聊天的化学助手”不同,用户可以用自然语言指定分子量、logP、氢键供体/受体、TPSA、可旋转键、是否含大环、是否含特定子结构或共价弹头等性质,SmileyLlama据此生成满足条件的候选分子。
代码仓库:
https://github.com/THGLab/SmileyLlama
背景
化学语言模型(CLM)通常以SMILES或SELFIES等字符串表示为训练对象,已经成为从头生成分子的常用工具,尤其适用于药物发现。过去的分子生成模型多数从ChEMBL、ZINC等大型化学数据库出发,从头训练变分自编码器、循环神经网络、GPT 或结构化状态空间模型等架构,并通过下游优化提高生成性能。
大语言模型(LLM)是对语言单元概率分布进行建模的统计模型。近年来,规模化Transformer在海量数据上的训练产生了GPT-4和Llama等模型。科研人员已经尝试将前沿LLM用作虚拟实验室成员、自然语言与化学语言之间的翻译器,甚至用于自动化科研;也有人把LLM用在化学空间搜索的突变与交叉步骤,或修改SMILES字符串以改变分子性质。
然而,尚未有从预训练通用LLM派生出的CLM达到现代从头训练CLM的性能。本文证明,开源权重的Meta-Llama-3.1-8B-Instruct可以通过SFT和DPO被转换为药物发现中的分子生成模型。开源权重的优势包括:可以共享适配器;推理时无需把潜在高价值数据上传远程服务器;可以控制微调超参数和算法;也便于解释模型权重。
结果
SFT和DPO改造Llama
为使预训练Llama的输出转向药物分子生成,作者首先使用监督微调。训练数据为ChEMBL v33中约200万个分子的SMILES字符串。对每个分子,作者用RDKit计算药物化学相关性质,包括氢键供体与受体数、分子量、logP、TPSA、sp3碳比例、可旋转键、大环、结构警示、特定子结构和共价弹头相关 SMARTS 等。
训练提示由系统指令和用户指令组成。系统指令赋予模型“擅长生成类药分子SMILES”的角色;用户指令在未指定性质时要求输出类药分子的SMILES,在指定性质时列出具体要求。每个性质以50%概率被放入提示,使模型在推理时无论用户是否给出性质要求都能工作。DPO用于进一步强化模型对特定任务目标的遵循。作者让SFT模型针对某一性质提示生成多个SMILES,用RDKit判断其是否满足提示;再用一轮DPO更新权重。
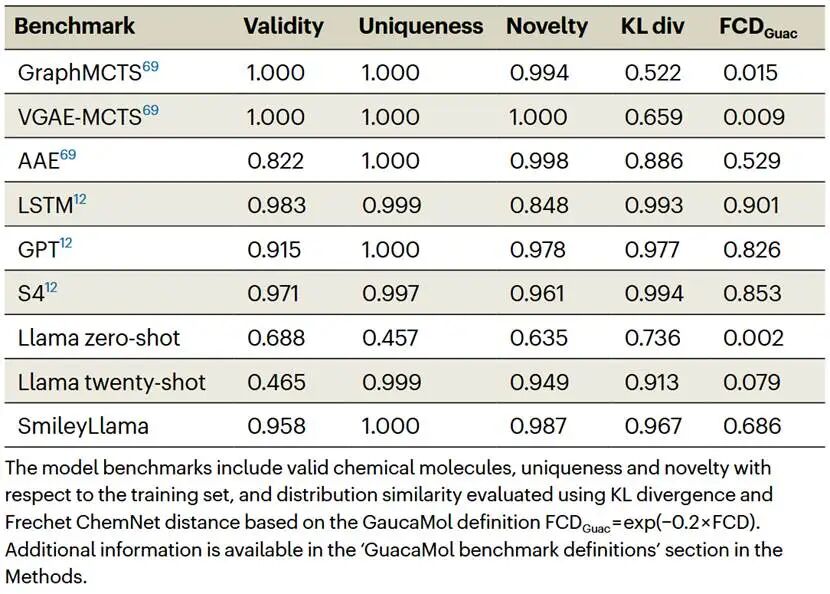
SmileyLlama与其他LLM/CLM的基准比较
作者使用GuacaMol评估有效性、唯一性、新颖性、KL散度和Fréchet ChemNet距离。未经微调的Llama zero-shot只依赖预训练知识,能生成一部分有效SMILES,但唯一性较低;提供20个示例时,唯一性升高但有效性下降。作者推测,zero-shot Llama曾在训练数据中接触过SMILES语法,但缺乏泛化能力;而few-shot示例把模型带离其记忆的SMILES,却不足以让其掌握可变语法结构。
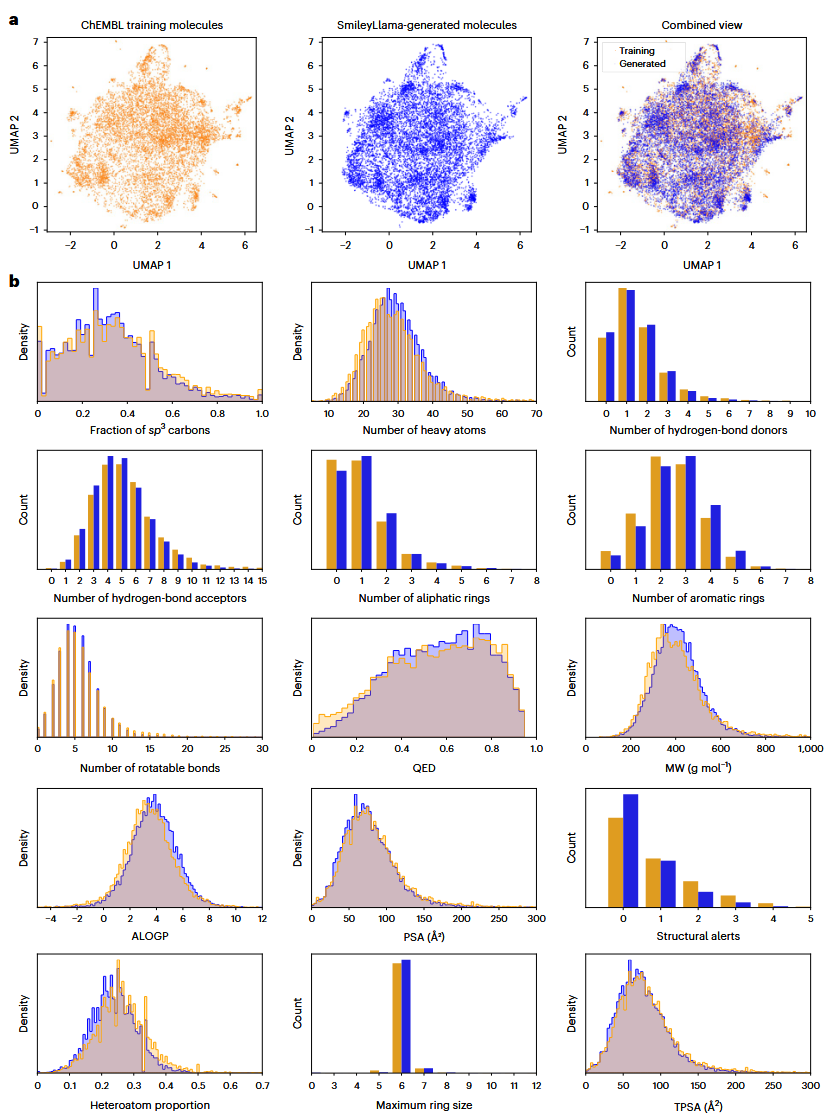
图1 生成分子与ChEMBL的分布比较
SFT显著提升了SmileyLlama的类药分子生成能力。不同提示格式的消融实验显示,提示格式本身对GuacaMol指标影响不大;更小的Llama-3.2-1B/3B和Qwen2.5-7B也可用相同流程微调,说明LLM-SFT思路具有一定通用性。随着参数量增加,有效性提高,而新颖性、唯一性和分布匹配度变化较小。
表1 GuacaMol基准
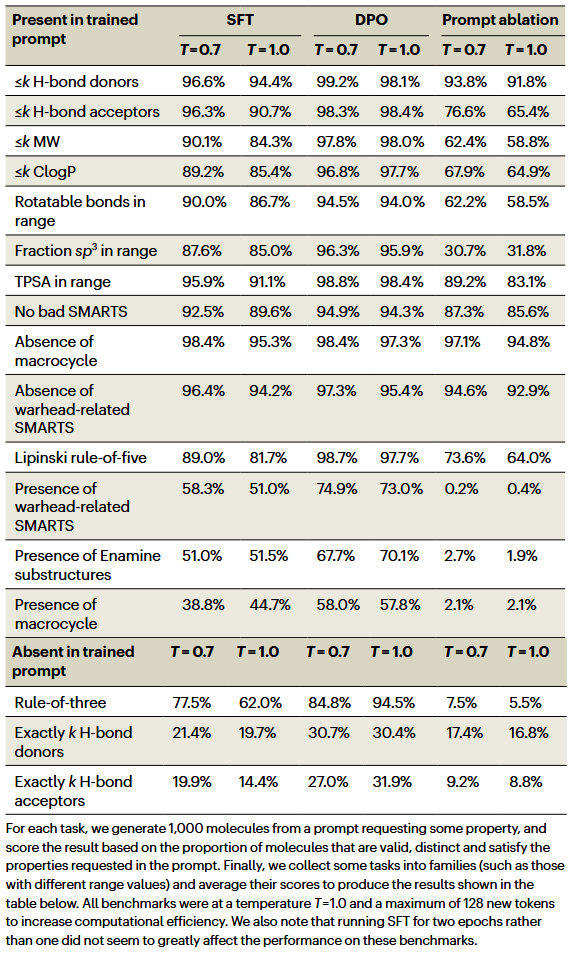
SFT下的性质指定生成
作者评估了SmileyLlama按范围生成目标分子性质的能力。这与要求精确数值的条件生成不同,更接近药物化学实践,因为研究人员通常使用性质区间筛选候选分子。总体上,模型在训练提示中出现过的任务上表现良好,尤其在氢键供体/受体、分子量、logP、TPSA、Lipinski五规则和避免不良SMARTS等任务上达到较高比例。
表现较弱的任务往往在训练数据中稀少,例如生成大环、带共价弹头的分子或含某些Enamine子结构的分子。对精确数量(如恰好 k 个氢键供体/受体)的任务,模型表现较差,因为训练时并未以高精度数值形式表达这些要求。相比之下,提示消融模型在多数性质指定任务上显著落后,说明工程化提示是关键,而不能仅依赖基础模型的化学知识。
表2 性质指定任务的有效不同生成分子比例
DPO下的性质指定生成
DPO可进一步优化模型。对表2中多数任务,DPO后的SmileyLlama明显提高了遵循提示的比例。与此同时,DPO也会使性质分布变窄,并相对不敏感于温度变化。作者因此把SFT与DPO的作用区分为:SFT更适合早期探索广阔化学空间;DPO更像约束优化,适合把生成限制到用户指定的子类。
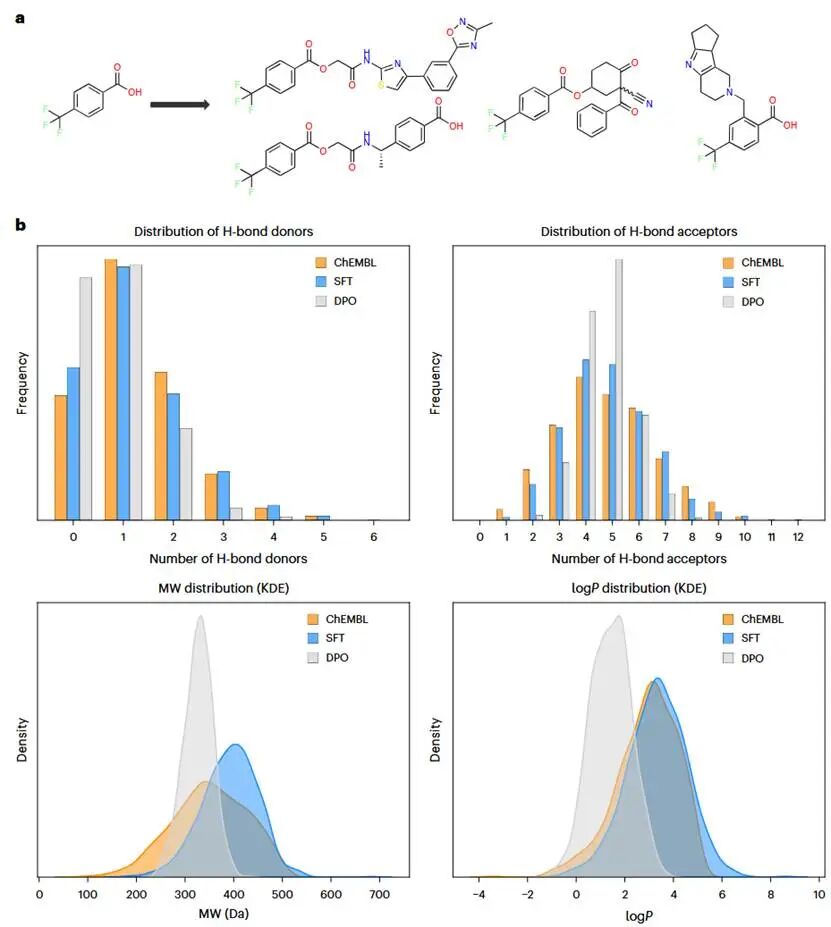
图2 片段增长与DPO前后分布
SmileyLlama/iMiner对蛋白活性位点结合亲和力的优化
前述测试主要关注二维字符串与类药性质,没有显式使用候选药物的三维结构、形状和靶蛋白活性位点相容性。作者把DPO增强的SmileyLlama嵌入iMiner框架,用于生成可与特定蛋白结合的有效新配体。iMiner将深度强化学习与AutoDock Vina实时三维分子对接结合,既追求化学新颖性,也约束分子与靶点活性位点的形状和相互作用兼容性。
在SARS-CoV-2主蛋白酶MPro示例中,SmileyLlama学习提示“High SARS2PRO”,目标是最小化AutoDock Vina docking分数并最大化类药评分。与原iMiner相比,SmileyLlama 约用25%的迭代轮数即可达到类似的docking改善,而且在优化过程中保持更高分子多样性。单纯优化High SARS2PRO会导致部分性质偏离类药范围,例如分子量和logP过高。SmileyLlama的优势在于可通过提示而非重新训练调节性质:把High SARS2PRO与“≤5氢键供体、≤10氢键受体、≤500分子量、≤5 logP”等Lipinski约束合并,可显著改善分子量、logP与类药评分,但高docking分数会有所牺牲,因为较小分子通常形成较少相互作用。
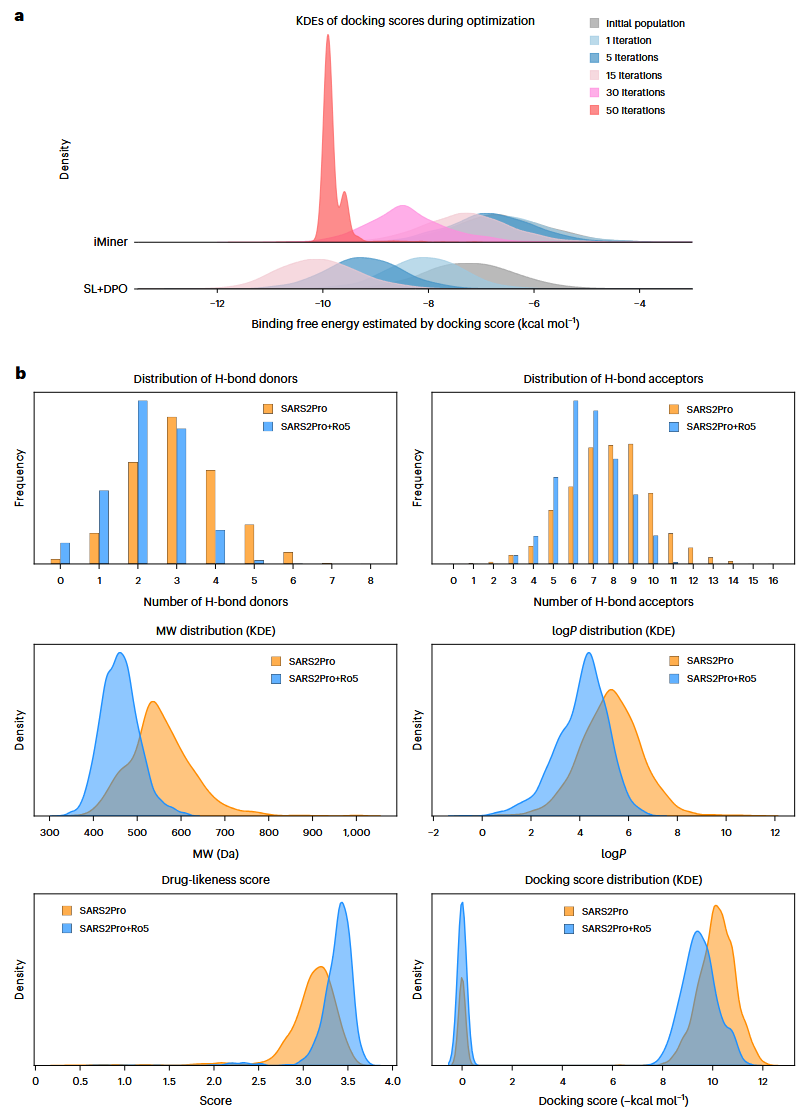
图3 iMiner与SmileyLlama优化过程中对接分布比较
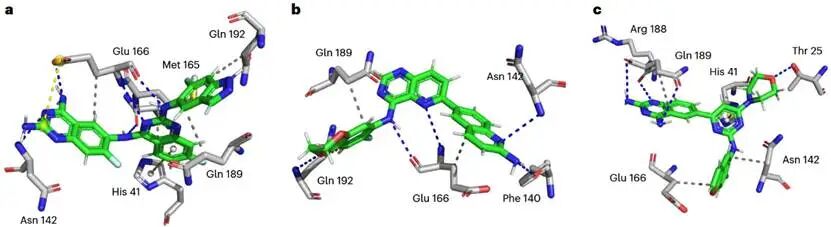
图4 SmileyLlama从头生成分子在SARS2 MPro活性位点中的姿态
SmileyLlama在化学语言建模之外的能力
SFT和DPO改变了Llama,但SmileyLlama仍保留部分英文对话能力。作者用Language Model Evaluation Harness在MMLU、GPQA、Math-Hard和MMLU-Pro上评估模型,发现SmileyLlama在道德场景和部分化学相关科目上低于原Llama。原因之一是模型倾向于用SMILES字符串补全化学相关提示;此外,部分MMLU化学测试本身也存在准确性问题。总体上,这一结果仍有积极意义:从LLM派生的CLM可以继承基础模型的自然语言能力,并用自然语言提示控制化学空间探索。
总结
从通用LLM派生化学语言模型不一定需要在大量化学专用文本上预训练。用数百万分子数据构造prompt-following训练集,再对LLM做资源消耗较低的SFT,就足以达到强分子生成性能。DPO则提供了另一种低成本优化方式,无需单独训练奖励模型,也无需in-context示例,而是由模型自身产生好坏样本进行偏好学习。一个重要发现是,SmileyLlama能把单目标优化学到的知识组合起来处理多目标提示。例如,不必专门训练同时满足SARS2PRO和Ro5的模型,只需把提示合并即可获得相应性质迁移。这对药物发现很有价值,因为真实候选药物往往要同时满足活性、ADME、合成可及性、选择性、抗突变和低脱靶风险等多种约束。
局限也很明确。DPO提高提示遵循度的代价是收窄性质分布和多样性;在早期发现阶段,过强约束可能反而不利于探索。SmileyLlama在数据稀缺场景中仍表现有限,例如大环分子生成。未来可把该框架扩展到药物发现之外,例如SMILES表示的过渡金属配合物设计、化学合成规划、材料与生物体系设计。
参考链接:
https://doi.org/10.1038/s43588-026-00986-y
--------- End ---------
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号