【万字长文】LLM 缓存这笔账,藏着多少猫腻?


从 Claude、OpenAI、DeepSeek,到 Coding Agent、中转站和 AI Gateway 的成本黑箱
01|一句"继续",为什么也可能很贵
同样一段 100k token 的上下文,这一轮花几分钱,下一轮花几块钱。
差的不是模型,也不是你打了多少字。差的是这批重复内容有没有命中缓存。
我第一次注意到这件事,是因为 Coding Agent 的账单贵得有点离谱。
明明只是让它"继续改""再跑一下测试""把刚才那个报错修掉",输入框里就几个字,额度却蹭蹭往下掉。
问题不在你打的那几个字。
对 Coding Agent 来说,"继续"只是请求最后追加的一小段。前面往往已经压着一大批上下文:工具定义、项目规则、历史对话、上一轮的工具结果。真正吃 token 的,是这批每轮都重复的内容。
这批内容如果命中缓存,后面几轮会便宜很多。缓存读取的价格,通常只有普通输入的十分之一上下,有的模型还能更低。
没命中,每一轮都按普通输入重新计费,等于全程裸跑。同样是 100k token 的上下文,一轮按缓存读取、一轮按普通输入,账单能差出一个量级。
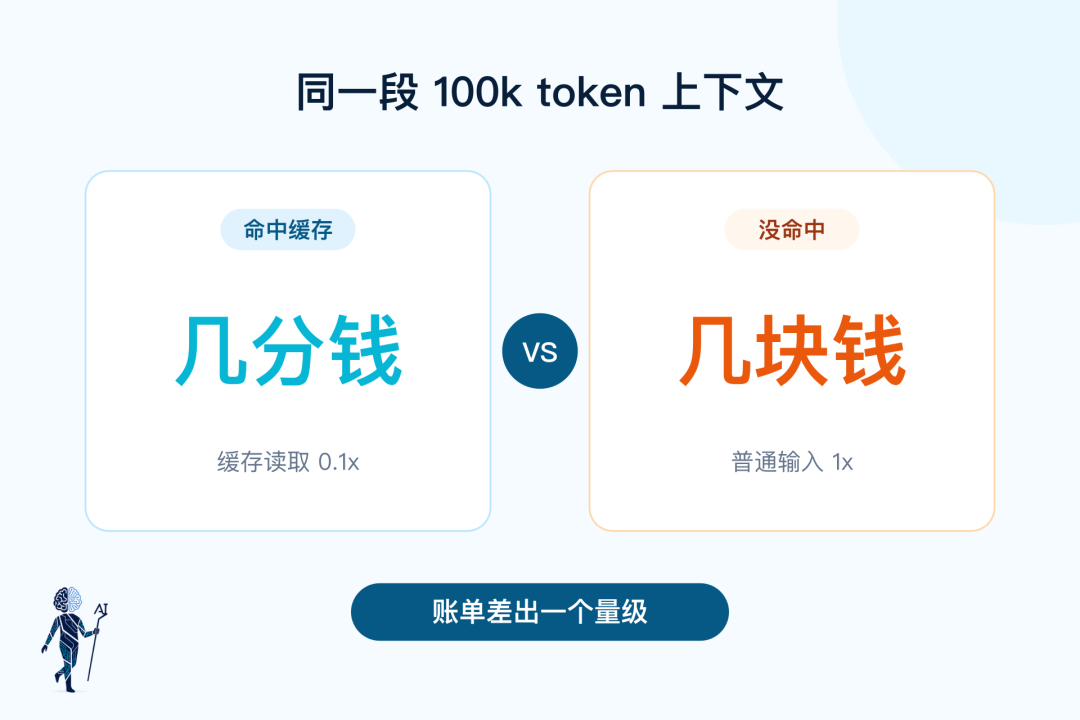
同一段 100k 上下文,命中和没命中,账单差一个量级
同一段 100k 上下文,命中和没命中,账单差一个量级
这件事还很难靠你自己看出来。
模型厂商、Agent 框架、中转站、路由位置,每一层都会动你最后的调用成本。只看模型单价,根本盖不住这些。
真正决定长会话成本的,是另外三个问题:每一轮输入里有多少重复内容,重复内容有没有命中缓存,命中之后有没有算进你的账单。
这篇文章就顺着这笔账往下拆。
先讲缓存到底缓存了什么,再看 Claude、OpenAI、DeepSeek 的规则差异;然后回到 Coding Agent,看它为什么容易命中率不稳;最后落到最敏感的一层——缓存省下来的钱,最后有没有算给你。
02|缓存到底缓存了什么
先把它和几个容易混的概念分开。
Prompt caching 的重点是输入前缀复用,跟模型长期记忆、语义检索是两回事。模型发现这次请求的前半段和之前某次一模一样,已经处理过的那部分就能用更低成本读回来。
关键词是"前缀一致"。
一个 Agent 请求大致长这样:
[tools] 工具定义
[system prompt] 系统提示词
[project rules] 项目规则
[conversation history] 历史对话
[tool results] 上一轮工具结果
[new user message] "继续" ← 真正新增的只有这几个字普通聊天里没人关心这个结构。
到了 Agent,前面的固定内容变得很大,真正新增的常常只是最后那句指令。缓存能省的,就是前面这批重复输入。
tools + system + project rules 连续多轮保持一致,后续请求的前缀就有机会命中。模型不必每轮重新按普通价处理这段,首 token 延迟也会下降。
缓存也很容易被动态内容打断。
当前时间、随机 request id、重排过的工具列表、动态拼出来的 system prompt,只要出现在请求靠前的位置又每轮都变,命中率就会塌。
这类问题在 Agent 框架里特别常见。你没输入多少新东西,框架却每轮往前缀里塞动态字段,本来能复用的上下文被当成新输入处理。

动态字段插在最前面,整条前缀的缓存全部失效
动态字段插在最前面,整条前缀的缓存全部失效
所以稳妥的排法很简单:长期稳定的内容放前面,每轮变化的放后面。越稳定越靠前,缓存越管用;越动态越靠前,缓存越容易废。
还要记住一点,缓存只动输入侧。
输出每轮都要重新生成。缓存省的是重复上下文的读取成本和预填充延迟,不会让输出免费,也不会让回答变好。
所以判断缓存有没有起作用,别只看总 token,要看输入里有多少被缓存读取、多少新写入、多少完全没命中。
各家给这些字段起的名字不一样:
- Claude:cache_creation_input_tokens、cache_read_input_tokens、input_tokens
- OpenAI:cached_tokens
- DeepSeek:prompt_cache_hit_tokens、prompt_cache_miss_tokens
名字不同,要看的是同一个问题:这一轮输入里,重复内容有没有被低价复用。 看不到这个,模型单价就只能解释账单的一小部分。
03|Claude 的缓存,控制最强,也最容易用错
Claude 适合拿来讲 Agent 成本,因为它机制最明确,usage 字段也最细。
Claude 缓存看的是有序前缀,引用顺序是 tools → system → messages。前面一变,会连带影响后面。
tool definition 改了,后面的 system 和 messages 缓存都可能失效。system prompt 改了,后面的 messages 也跟着失效。
偏偏在 Agent 里,最靠前的内容也最容易被框架动态拼接。
Claude 用 cache_control 指定缓存断点,意思是告诉 API:到这里为止的前缀值得缓存。
{
"model": "claude-opus-4-8",
"system": [
{ "type": "text", "text": "You are a coding assistant. Follow the project rules below..." }
],
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Here is the repository context and coding rules...",
"cache_control": { "type": "ephemeral" }
},
{ "type": "text", "text": "Now fix the failing test." }
]
}
]
}重点是位置。
cache_control 放在稳定内容之后,后续用户问题随便变,前面那段稳定前缀都还有机会被复用。
Claude 对命中条件卡得很严:断点之前的内容必须逐字一致。语义差不多没用,文本、结构、顺序一变就可能不命中。
常见的失效来源就那几样:tool schema 变化、工具顺序变化、system prompt 混进动态状态、项目规则挪了位置、工具结果结构变了。
这对 Agent 框架就是一句话的要求:稳定内容要真的稳定。
Claude 还能在对话中间插入 role: system 消息。
它的价值正是冲着前缀稳定来的。中途要加新规则、切权限模式、补临时约束,不用去改最前面的 system prompt,新规则作为后续消息进来,前缀不动,已经建好的缓存就能接着复用。
注意 system message 权限很高,网页正文、工具返回、用户上传的内容别往里塞。
读账主要看这三个输入字段:
{
"usage": {
"input_tokens": 842,
"cache_creation_input_tokens": 18640,
"cache_read_input_tokens": 73210,
"output_tokens": 1260
}
}input_tokens 是本轮按普通输入计费的部分。
cache_creation_input_tokens 是本轮新写入缓存的部分,写入有溢价。
cache_read_input_tokens 是本轮从缓存读回来的部分,价格通常远低于普通输入。
只看总 token 很容易误判。
一次请求看起来输入很多,但大半是 cache read,其实很便宜。反过来,写入高、读取低,说明你一直在写缓存却很少读回来。
对 Claude 来说,最该盯的是写入和读取的比例,而不是"有没有开缓存"。
写入高读取低,是前缀不稳或复用次数不够;读取高普通输入低,才说明稳定前缀真被复用了。
04|5 分钟还是 1 小时,TTL 按节奏选
Claude 缓存默认 5 分钟 TTL,也能选 1 小时。这两个选项差的不只是时长,还直接改写入成本:
- 5 分钟 cache write:普通输入价格的 1.25 倍 - 1 小时 cache write:普通输入价格的 2 倍 - cache read:普通输入价格的 0.1 倍
写入本身不免费。1 小时写得更贵,只有后续真能多次读回来才划算。
5 分钟适合高频连续会话。
让 Coding Agent 连续修 bug、跑测试、读文件、改代码,几分钟内反复用同一批稳定上下文,5 分钟基本够。而且 5 分钟缓存命中后会刷新,只要会话不长时间断开,就不一定很快过期。
1 小时适合中间有明显停顿的场景。
读完输出过二三十分钟再继续、side agent 跑长任务、应用预热一段大上下文之后反复用。这些场景 5 分钟会过期,1 小时才保得住前缀。
它也不该无脑开。
内容只用一次,1 小时写入就是打水漂。前缀每轮都在变,1 小时也救不了命中率。
Coding Agent 用户要再多看一层。
Claude Code 在 2.1.108 加了两个环境变量:ENABLE_PROMPT_CACHING_1H 启用 1 小时 TTL,FORCE_PROMPT_CACHING_5M 强制 5 分钟。后续 changelog 还修过"1 小时 TTL 被静默降级成 5 分钟"的问题。
到 2.1.160,它已经不是把整个会话固定成 5m 或 1h,而是按策略给不同缓存块分别生成 cache_control。usage 里能看到 ephemeral_5m_input_tokens 和 ephemeral_1h_input_tokens 这样的拆分。
这里有个容易漏的成本边界:用很小的保活请求去维持 5 分钟缓存,本身也要算钱。
粗算一下。一小时 12 次保活,每次读一遍缓存前缀按 0.1x,是 1.2x;加上第一次 5 分钟写入的 1.25x,合计约 2.45x。反而比直接写 1 小时的 2x 更贵。
这只是敏感性估算。实际还要看保活是否真读了完整前缀、是否产出输出、是否被中转站按原价计费。
Claude 也支持混用 TTL,但有顺序:长 TTL 内容放在短 TTL 之前。道理还是前缀,越稳定越靠前。
工具定义 / 系统规则 / 项目规范 → 1h cache
近期对话 / 本轮任务上下文 → 5m cache
当前用户输入 → no cache
5 分钟和 1 小时的写入成本与适用节奏
5 分钟和 1 小时的写入成本与适用节奏
TTL 不能只看时长,要看写入成本、复用次数和会话节奏。
05|OpenAI 与 DeepSeek,一个自动省心,一个价差极端
Claude 是显式控制,另外两家走的是别的路。
OpenAI 不要你手动加 cache_control,对支持的模型,只要前缀够长就自动尝试缓存。
这对产品化请求很友好。固定系统提示、产品说明、长文档开头这类稳定长前缀,系统会自动复用,命中信息出现在 usage 的 cached_tokens。
它强调 exact prefix match,前缀要完全一致才命中,缓存从 1024 token 起生效。原则和 Claude 一致,只是不用你手动标断点。
OpenAI 还给了 prompt_cache_key。
它的作用不是强制缓存某段,而是帮平台把有相同长前缀的请求路由到更可能命中的位置。同一个文档、同一个客服知识库、同一个应用模板,用稳定的 cache key 能提高复用机会。
代价是控制感弱:不能精确指定断点,也不能给不同片段单独设 TTL。
还有两个边界要记住。缓存 token 仍然计入 TPM 等速率限制。缓存也有保留时间,文档提到通常 5 到 10 分钟不活跃后失效,最长约 1 小时,部分模型有 extended retention。
所以它适合省心,别当成无限期记忆。
DeepSeek 默认开启,叫上下文硬盘缓存,不用改代码。但它的命中逻辑和前两家体感差别最大。
前缀要先被持久化成一个完整的 cache prefix unit,后续请求只有完整匹配某个已持久化的 unit 才命中。
第一次:A + B → 结束后 A + B 成为一个 cache prefix unit
第二次:A + B + C → 命中 A + B如果第二次是 A + C,未必命中。持久化的是 A + B,A + C 没完整匹配。
不过 DeepSeek 会检测多次请求之间的 common prefix。前两次都带 A,系统可能把 A 单独持久化,等第三次变成 A + D,就有机会命中 A。
这也解释了一个看着挺玄学的现象:DeepSeek 有时第一、二轮没命中,第三轮才开始命中。不是抽风,是缓存构建要几秒,后台还在整理 prefix unit。
它的 usage 很直观。
prompt_cache_hit_tokens 是命中的部分,prompt_cache_miss_tokens 是没命中的部分。
这两个字段比总 input token 有用得多,因为 DeepSeek 的 hit / miss 价差极端。4 月底一轮降价后,限时折扣价直接转正成了挂牌价。按当前中文价格页,100 万 input token:
- deepseek-v4-flash:cache hit 0.02 元,cache miss 1 元
- deepseek-v4-pro:cache hit 0.025 元,cache miss 3 元
Flash 的 hit / miss 差 50 倍,Pro 差 120 倍。
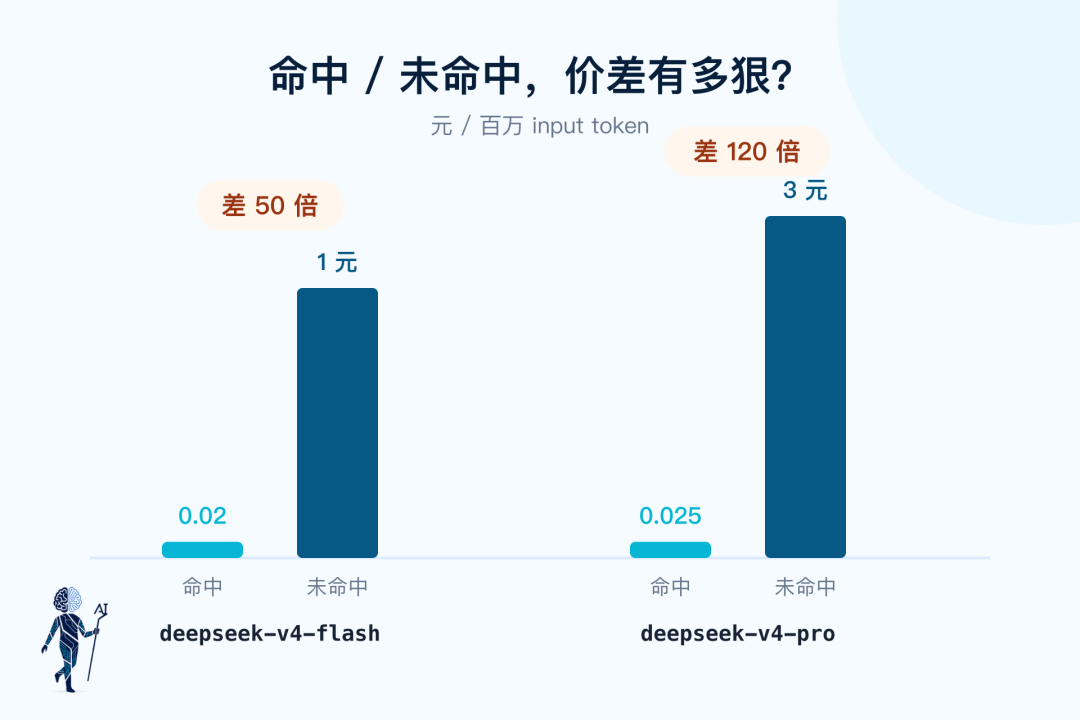
DeepSeek 命中与未命中的输入价差,50 倍到 120 倍
DeepSeek 命中与未命中的输入价差,50 倍到 120 倍
对 DeepSeek 来说,命中与否直接决定这一轮长输入是几分钱,还是几块钱。
我自己五一期间跑过一批 DeepSeek 调用,总量约 15 亿 token,最后花了不到 50 块钱,平均约 0.033 元 / 100 万 token,基本是把 cache hit 薅满的效果。真正决定总成本的,已经从标价表上的 miss 单价,转向大量重复上下文有没有落到 hit 档位。
这也是为什么 DeepSeek 最能照出中转站的问题。
网关只给你总 input token、不分 hit 和 miss,上游大量命中、却按普通输入给你计费,你根本看不出来。
它的缓存只匹配输入前缀,输出仍然每次生成,也不承诺 100% 命中(官方说 best-effort),缓存不用后几小时到几天自动清理。
06|Coding Agent 为什么缓存难稳
把 Claude Code 拎出来看,不是因为它做得差,而是因为它把这类问题暴露得最清楚。换到 OpenCode、OpenClaw、Hermes,细节不同,压力来源一样。
编程客户端早就不是单个 agent。它会调度工具、压缩上下文、切换模式、拉起子任务。
一个请求前缀里塞了很多东西:工具定义、项目规则、CLAUDE.md、权限模式、MCP schema、git 状态、历史消息、工具结果。有些该长期稳定,有些每轮都变。
系统越复杂,动态上下文越多;动态上下文越多,缓存越难稳。
这就是它们比直连 API 更难命中的根本原因。
直连 API 的缓存很干净,前缀一致就好解释。Agent 框架多了一层上下文组织逻辑,每轮到底塞了哪些工具、状态、摘要、历史片段,你通常看不全。
最近一批 Coding Agent 的缓存优化,核心都是同一件事:把稳定内容和动态内容分开。几个反复出问题的地方,正好串起这条线。
第一个是动态 system prompt。
当前时间、cwd、git 状态、权限模式、token budget,这些对 Agent 有用但每轮都变。一旦混进很靠前的 system prompt,就把原本稳定的前缀拖成了动态前缀。
Claude Code 后来加了 --exclude-dynamic-system-prompt-sections,就是把这类内容从稳定前缀里摘出去,改善跨用户缓存。
第二个是 tool schema。
MCP server 一多,tool definitions 又长又容易变。Claude Code 提过 MCP tool definitions deferred,延迟加载工具定义。这不只是少塞 token,更是减少工具 schema 对前缀的扰动。任何接 MCP 的客户端都躲不开。
第三个是切换模型。
Claude Code 会提醒你:中途切模型,下一轮会重新读完整历史,且没有缓存。切模型不只是换了推理能力,也可能让缓存链路整个断掉,下一轮输入成本突然变高。任何支持多模型切换的 Agent 都要面对。
第四个是 auto-compaction 和 subagent。
compaction 把历史压成摘要,能降总 token,但会改写 messages 前缀,可能打断原有缓存链。它不天然省钱,是在"缩短上下文"和"保持缓存连续"之间做取舍。
subagent 和 ultracode 这类自动多 agent 编排,对大型重构、深度 review 有价值。但每个子 agent 都有自己的 prompt、工具、规则和执行结果,不一定共享主会话的缓存,token 烧得更快,缓存也更不稳。小修小改硬拆,反而把缓存和 token 都打散。
还有一类是统计本身的 bug,同样会误导你:cache_creation_input_tokens 显示异常会让你看错写入成本,sub-agent 摘要缺少缓存会在多 agent 场景放大 cache creation。
合理的方向就一句:稳定内容固定住,动态内容往后放,用不到的工具别提前暴露,compaction 和 subagent 要有明确边界。
provider-agnostic 框架还有个先天难处:Claude 的 breakpoint、OpenAI 的自动前缀和 cache key、DeepSeek 的 hit / miss 账本,各走各的路。框架要兼容多家,就很难把哪一家用到极致。
到这一层,缓存已经不是某个客户端的附属优化,而是上下文工程的一部分。
07|中转站,缓存省下的钱到底给了谁
前面讲的是模型和框架。到中转站这里,问题变得最现实。
模型有没有缓存是一回事,你有没有拿到缓存收益是另一回事。
三家都会在 usage 里返回缓存信息,作用一样:让你知道这轮输入哪些按普通算、哪些走了缓存优惠。
这些信息一旦过中转站,就可能消失。
很多 OpenAI-compatible API 会把各家 usage 统一成一套简单格式。接入是方便了,缓存账本也被压平了,你最后只看到一个总 input token。
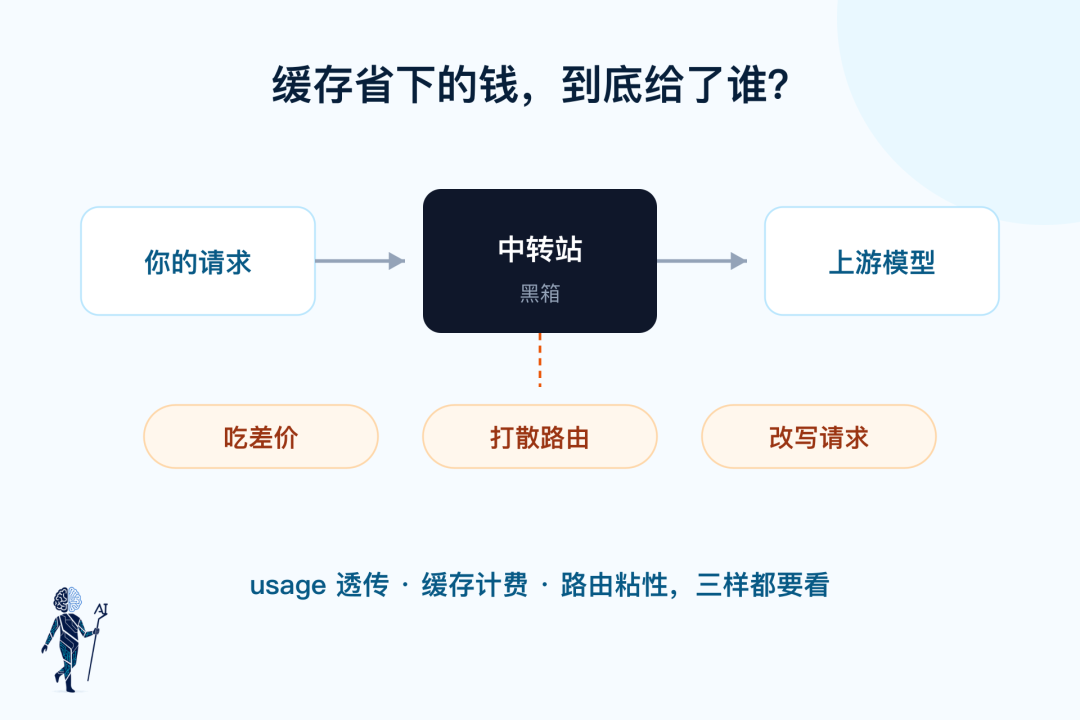
请求经过中转站这层黑箱,有三层猫腻:吃差价、打散路由、改写请求
请求经过中转站这层黑箱,有三层猫腻:吃差价、打散路由、改写请求
由此引出三层问题。
第一层是计费。
上游已经按缓存读取结算了便宜价,中转站转手按普通输入卖给你,中间的差价就被它吃了。它不用改请求,只要账单不分普通输入和缓存输入,你就很难发现。DeepSeek 这种价差巨大的模型尤其明显。
第二层是路由。
Prompt caching 既靠前缀一致,也靠请求落到能复用缓存的位置。中转站如果在多个 key、workspace、region、上游账号之间轮询,同一会话的请求就被打散了。
你看到的模型名一直是 claude-opus-4-8、gpt-5.5、deepseek-v4-pro,但背后走哪个渠道你不知道。有时中转站自己也未必清楚完整链路,它上面可能还接了别的聚合层、云入口、备用渠道。模型名一致,不代表缓存位置一致。
第三层是改写。
有些中转站会插自己的 system prompt、改 tool schema,或者为兼容格式重排 messages。你以为发出去的是原始请求,到上游时前缀已经变了。
更麻烦的是,这类改写通常不出现在你这侧的日志里。你只看得到发给中转站的请求,看不到它转给上游的最终请求。
所以判断中转站,别只看标价。便宜单价没意义,关键看它怎么处理缓存账本。
至少看三件事:
- usage 字段有没有透传,最好能看到供应商原始字段 - 缓存输入怎么计费,上游低价读取的部分有没有按低价算给你 - 同一会话有没有路由粘性,连续任务最好固定在同一组上游资源
三样都没有,就基本没法对账。这已经是成本解释权的问题了。
08|怎么判断自己有没有被缓存坑到
落到使用上,别一上来就问"它有没有缓存",这个问题太粗。
更准的问法分三层:接口有没有返回缓存信息,账单有没有保留这些信息,计费有没有按缓存价格算。
先看接口返回。
关键是它有没有把普通输入、缓存写入、缓存读取分开。只返回一个总 input token,这条链路就少了一半信息——可能真没缓存,也可能缓存了没透传,光看总 token 判断不出来。
再看账单口径。
接口里有缓存字段,不代表账单按缓存算。很多平台 API 返回里保留 usage,后台计费却还是按总输入乘单价。账单只写"输入多少 token、单价多少",缓存收益给了谁,你还是看不出来。
然后看连续会话里的比例。
别拿完全不同的请求去比。要在同一项目、同一任务、同一会话里测:前面大段上下文基本稳定,只在最后追加新问题。
正常情况下,后续几轮会逐渐出现更多缓存读取,普通输入占比下降。每轮都是大量普通输入、几乎没有缓存读取,就该怀疑前缀被打断了。
一次测试说明不了全部。
各家 TTL、最小 token 门槛、写入时机都不同,DeepSeek 还有构建延迟,中转站也可能有账单刷新延迟。一次没命中不等于有问题,连续多轮都看不到缓存痕迹,才值得追。
用 Agent 工具的,还要看动态内容有没有打断前缀:当前时间、git 状态、任务进度、tool schema、MCP 工具列表、测试日志、网页正文,都可能。
中转站也得排查。同一个 base url、key、模型名,不代表上游缓存位置稳定。
最后别只看总价。
总价便宜,可能是模型本来便宜;总价贵,可能是输出 token 多。缓存主要影响输入侧的重复长前缀,判断缓存问题,要看输入里的普通部分和缓存部分。
更靠谱的做法,是把每一轮请求当成一条账本记录: 用了哪个模型,走了哪条链路,输入里多少普通、多少缓存,账单按什么口径收钱。
个人用户重点留意接口 usage、平台账单和请求间隔。团队还要记录 key、项目、用户、模型、base url、workspace、region。这条账本一断,你就只能看平台给的总价——钱到底花哪了,心里永远没数。
09|选型与判断框架
讲到这里,模型选型就不能只看标价了。
长上下文和 Agent 场景里,真实成本由三件事决定:模型基础价、缓存命中率、链路有没有把缓存优惠传给你。
举个粗算。设普通输入价为 1,缓存读取按 0.1。
一个中转站打 3 折,但实际命中率只有 50%。有效输入成本是 0.5×1 + 0.5×0.1 = 0.55,再乘 3 折,是 0.165。
另一个打 6 折,但命中率到 95%。有效成本是 0.05×1 + 0.95×0.1 = 0.145,再乘 6 折,是 0.087。
看起来 6 折更贵,算完反而只有前者一半。

3 折低命中和 6 折高命中,有效成本反过来
3 折低命中和 6 折高命中,有效成本反过来
"几折中转"很容易误导人。折扣只作用在明面单价上,缓存命中率会改变计费基数。 长上下文任务里,命中率差一点,价格排序就可能反过来。
选型按场景看。
重度 Agent、长会话、代码任务,Claude 仍然合适。优势是可控,breakpoint、TTL、usage 都明确;代价是工程要求高,上下文放错位置、TTL 选错,账单就难看。
产品化调用选 OpenAI 更省心。稳定前缀够长,系统自动复用,适合调用规模大、不想手动管缓存点的团队。
价格敏感的长输入复用看 DeepSeek。hit / miss 价差大,长文档、多轮问答很受益,前提是链路能看到缓存账本。字段不透传,优势就被中转站抹平。
Agent 框架的选型,别只看"支持多少工具"。
更要看它怎么组织上下文:稳定规则会不会每轮重写,tool schema 能不能按需加载,MCP 工具会不会一次全塞,compaction 和 subagent 有没有边界。工具越多能力越强,请求也越容易变,命中率最后看的是前缀稳不稳。
中转站同理。便宜折扣只是入口,重点还是那三件事:usage 透传、缓存输入计费、路由粘性。
企业团队再多看一层治理。至少能按项目、用户、key、模型看到输入、输出和缓存统计,否则账单涨上来,只能看到"某个模型花了很多钱",看不到钱花在普通输入、重复上下文、工具结果,还是路由打散上。
一个简单框架收尾:
- 短输入、低频调用,看模型单价就够 - 长上下文、多轮会话,要看缓存命中率 - Agent 和中转站场景,要看上下文组织和账单透明度
这也是为什么这篇文章把模型、Agent 框架、中转站放在一起讲。
Coding 和 Agent 场景常常是输入远大于输出。模型每轮处理大量已有上下文,最后只产出几行修改或一次命令结果。输入侧占比一高,缓存命中率就直接决定总成本。
以后窗口更大、工具更多、Agent 读的东西更多。上下文变长本身不可怕,可怕的是每一轮都把长上下文按普通输入重新付费。
10|下次看账单,先看这三个数
下次再觉得 Agent 贵得离谱,先别急着换模型。
打开 usage,看三个数:普通输入、缓存写入、缓存读取。同一个任务连续跑几轮,缓存读取一直起不来,就该查前缀了——是动态字段插得太靠前,还是中转站在中间动了手脚。
再对一眼账单。usage 里大半是缓存读取,账单却按普通输入收钱,省下来的钱就没到你手里。
这本账看得懂,你花的是模型能力的钱;看不懂,就是一直在为重复上下文、不透明路由和无效工具调用交冤枉钱。
如果你也在搞 AI Coding、AI 研发协作、AI Gateway、AI Eval,想一起聊实际用法、效能提升和踩过的坑,
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号