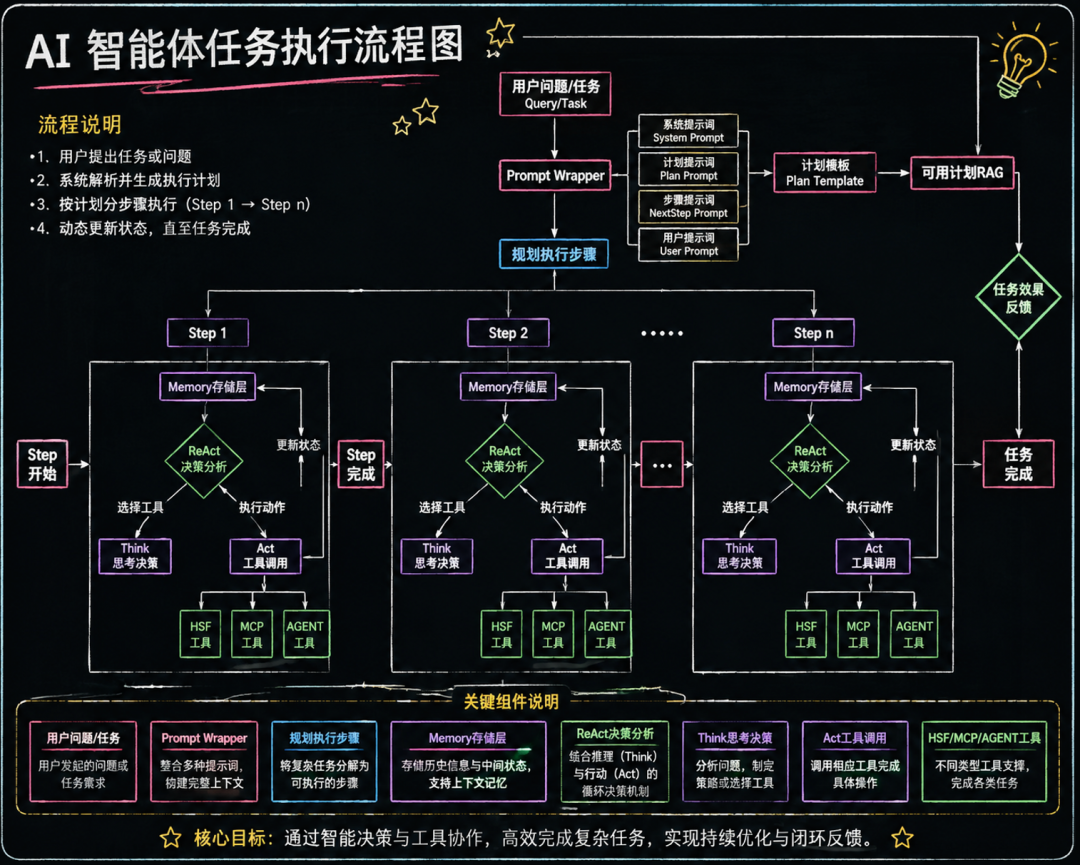
Agent是一个大loop


Claude Code作者说过一句话:我不再给Claude写prompt了,我有一堆loop在跑,我的工作是写loop。
Claude Code的动态工作流,让Claude能够按任务即时编写自己的Harness,用JavaScript编排subAgents/模型路由/worktree隔离/验证循环和可恢复执行,从而更适合长任务/并行任务/对抗验证和非编码类复杂任务。
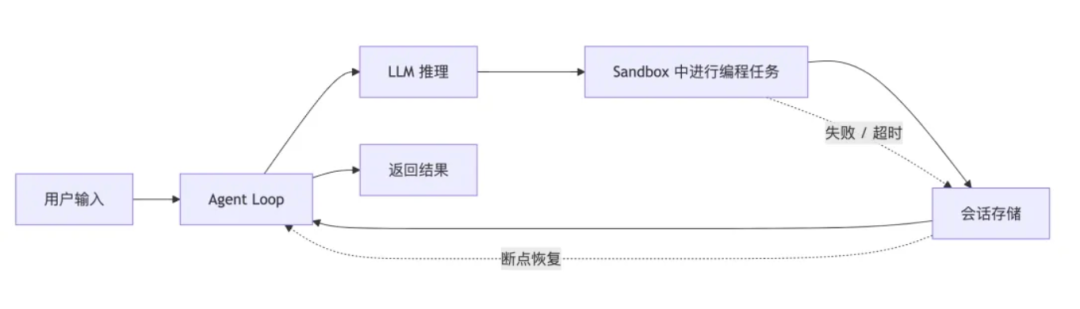
Agent是一个大loop,组装上下文,调用LLM,运行Bash,读写文件,回填上下文,继续推理。
这个循环可能要跑几十轮,跨越十几分钟到几十分钟,这个过程需要记录完整会话事件,在模型出错时/工具失败时/容器崩溃时继续工作。
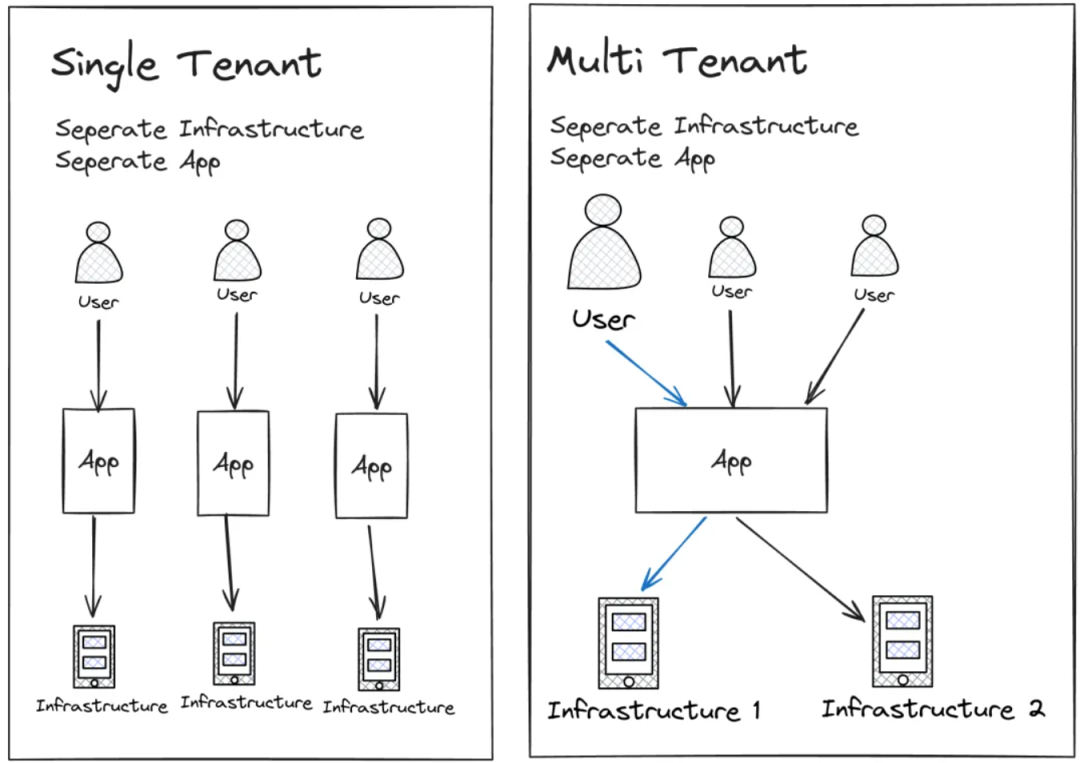
如果是一个多租户的Agent平台,每个Agent都是一个独立的项目,数据要隔离/计算要隔离/计费也要隔离/出问题了不能互相影响。
同时平台运营成本还要尽量的低。
一个Agent执行过程,可能要跑几十轮LLM调用,启动多个Sandbox,产生大量临时文件和日志。
如果Sandbox长期保活,会话和运行所产生的文件在存储层面没有冷热分层,一次任务的运行成本就容易失控。
所以从成本可控角度来说,agent平台需要在几个维度上做到按需付费:
1.计算按需付费:Sandbox和应用运行时都要能秒级冷启动,空闲时归零,而不是7x24小时占着资源;
2.存储分层:高频的绘画,记忆都放在在线数据库中,低频的运行期文件产物数据放在对象存储;
3.生命周期管理:会话日志,Sandbox快找,构建产物这类临时数据要能自动过期归档,否则存量会随着用户量线性膨胀,最终被存储和宽带费用反噬;
这便是一套Agent基础设施能力:

云平台非常容易切换到Agent基础设施,比如云平台已经具备了完整的Serverless资源管理能力,包括身份认证/数据库/云函数与容器/文件存储/web应用托管等能力,云平台把已有的Serverless/Baas/托管/多租户/权限重新组织便可成为新的Agent基础设施。
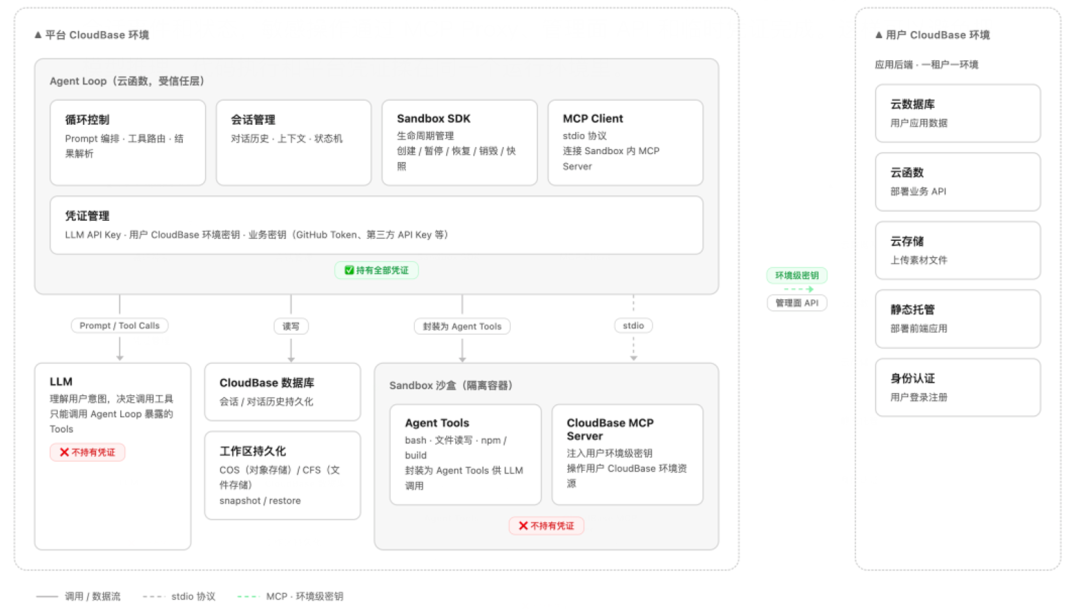
Agent Loop负责编排模型与工具;
Sandbox执行不可信代码;
Session记录会话事件和状态;
敏感操作通过MCP Proxy/控制面API/临时凭证完成;
将Agent执行所需的数据库/身份认证/云存储/云函数/静态托管/容器托管/https访问能力进行封装,让Agent通过MCP调用工具的方式调用。
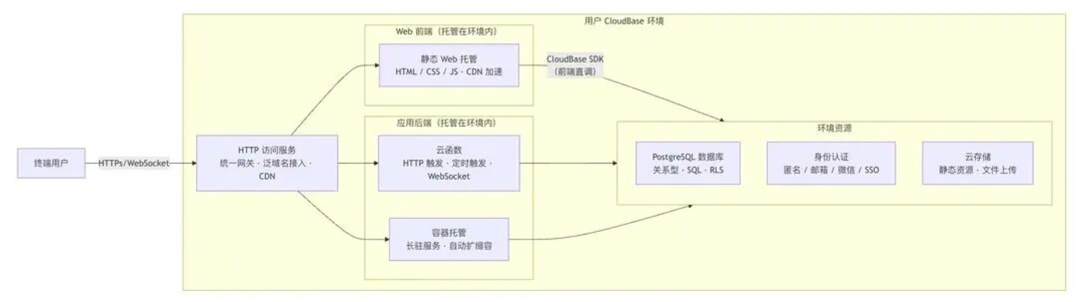
这样边界相互独立,避免将模型推理和Agent执行,平台能力杂糅在一起。
最终Agent平台是一套平台承载多个上层Agent应用,一套平台包含了Agent Loop/Sandbox/模型推理,多个上层Agent应用则有自己的环境/独立的数据/计算/存储/可访问边界/按量计费的集成平台。
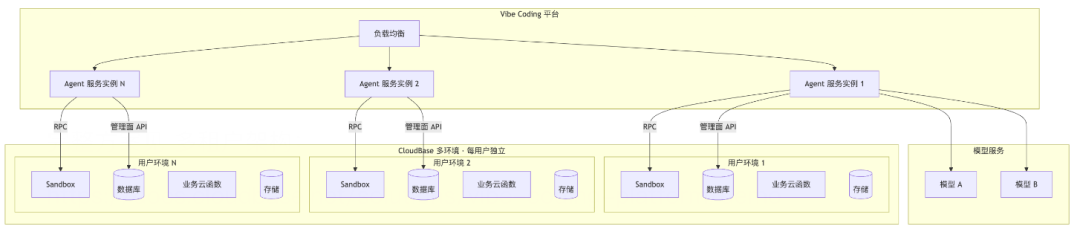
比如在平台上可以通过提示词完成Agent的开发与部署上线。
每个Agent应用都会生成所需的后端代码,创建一份独立的云数据库实例,数据在租户维度天然隔离,平台无需在应用层写一遍多租户逻辑。Agent应用可以通过MCP直接声明数据模型并写入测试数据。
平台内部内置了多种鉴权方式,用户不需要自己重新做一套登陆/鉴权/身份认证系统,应用从第一行代码就自带账户体系。
平台将数据库/云函数/云存储/静态托管/容器托管等后端资源全部包成MCP工具,并沉淀了一批可复用的Skill,这可以让Agent应用开发效率与工程质量极大提升。

用Agent的视角重新设计云平台,Brain/Hands分离运行时,声明式的MCP工具,一租户一环境的多租户模型,为长尾应用而生的Serverless计费都是需要的。
以下为关键的Agent基础设施体系,multi-Agent,mcp/rag/cache/模式/可观测性/评测提示/安全体系。
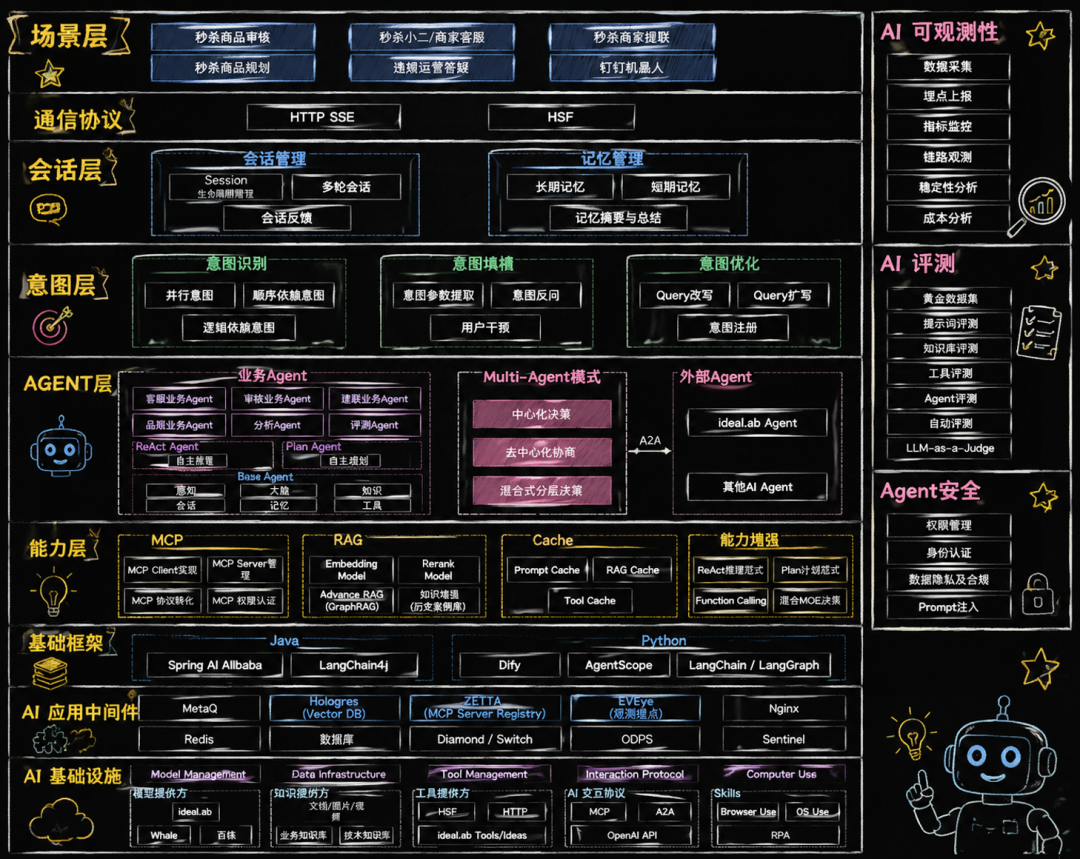
基础依赖层:关注模型/知识/工具/skill底层能力的支持,结合MCP协议将接口转化为MCP。
Agent层/意图层/会话层:意图层负责多意图识别与query改写,会话层重点关注上下文工程,比如多轮会话及长短期记忆能力。Agent层负责固定流程与ReActAgent/PlanAgent的构建与Multi-Agent协同。
质量与稳定性管理:包括AI可观测/AI评测/Agent安全三大模块,保障系统可用性SLA。
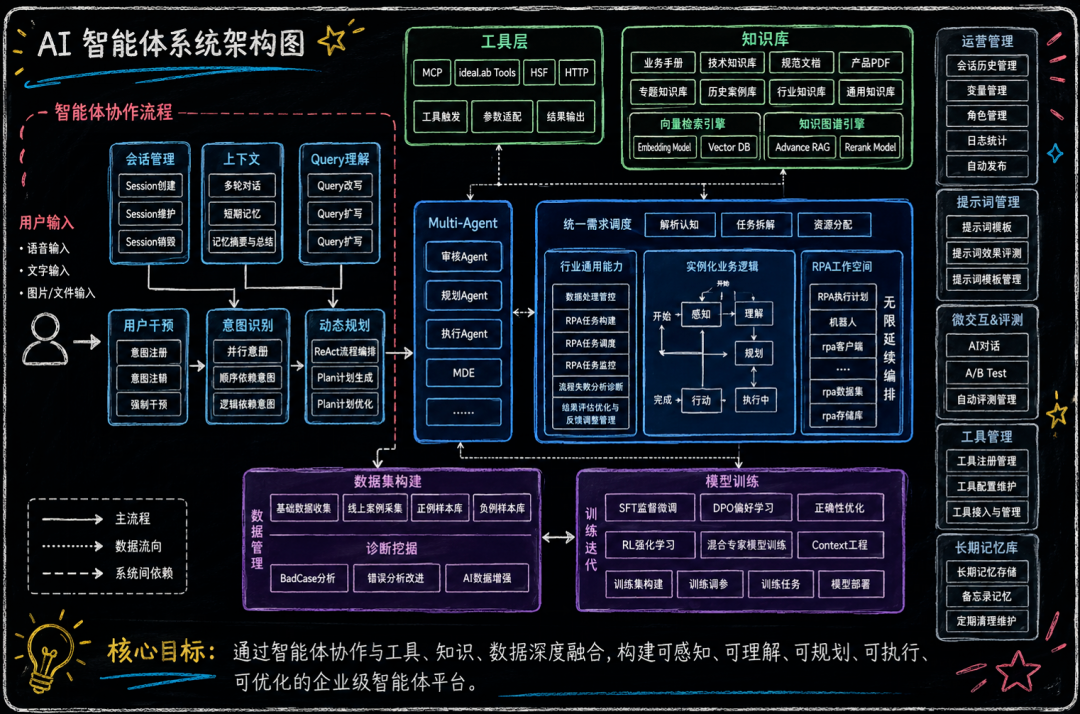
ReAct到Multi-Agent:分布式自主决策,ReAct范式是通过Thought-Action-Observation的循环工作,单步思考更擅长解决理性类问题,由Plan产出全局计划,由ReAct执行细分领域的推理。
而Multi-Agent则可以视为一个中心化决策模型,将任务细分为多领域子Agent,每个领域Agent采用ReAct&Plan范式的Agent负责,由中心化的Agent统一做意图识别与任务分发,形成MOE形态。
未来需要面向Agent设计工具,原有的Restful接口逻辑需要改造为AI Friendly API,比如工具原子接口改造适用于Agent推理过程选择,工具入参改造,接口拟人化出入参尽量KV平铺,仅保留核心字段。对于Error处理,预期内的error提供简短描述便于模型推理决策,预期外的error,提供堆栈信息便于模型识别原因。
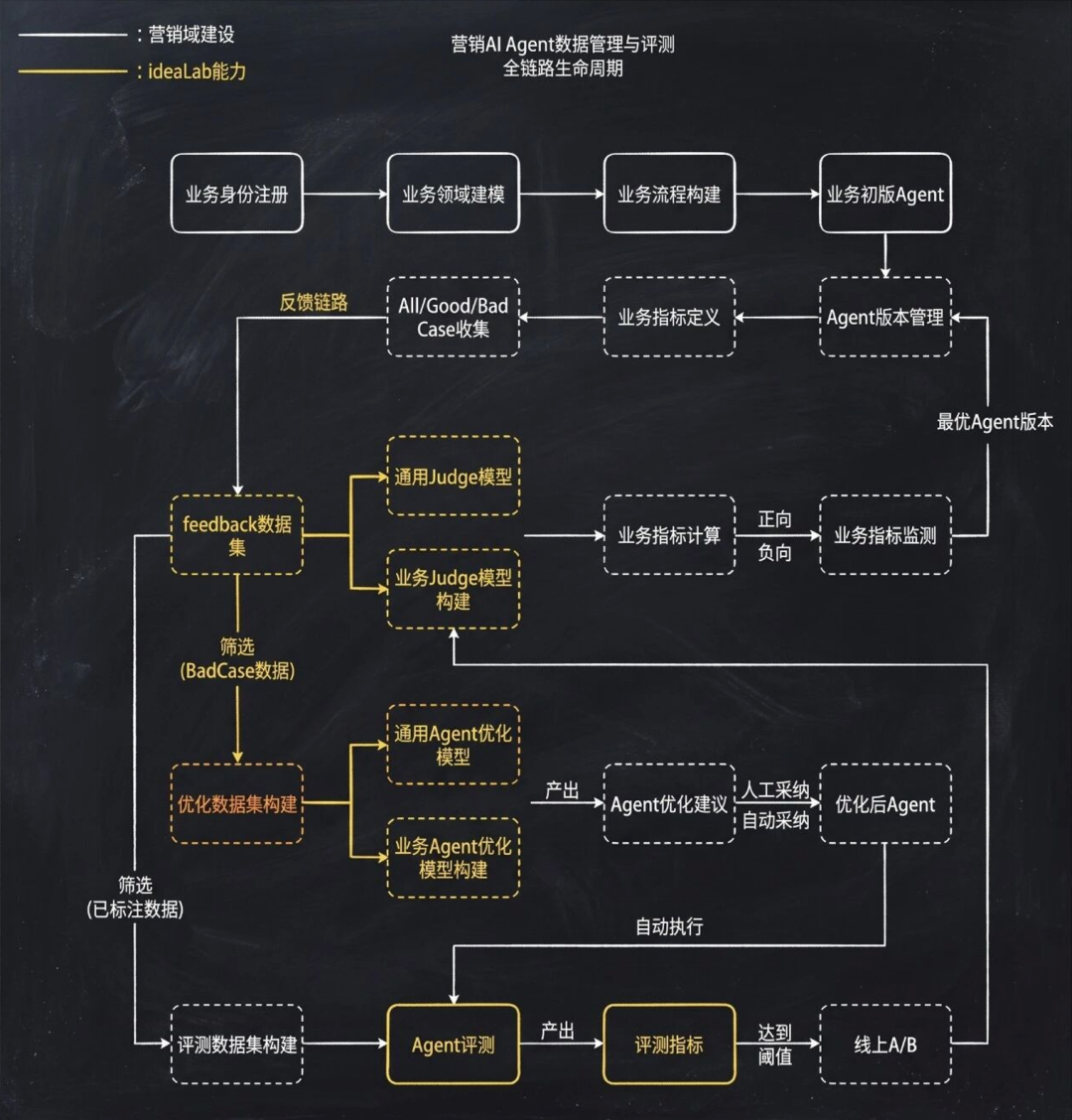
Agent整个loop需要提供可观测/可审计的能力,涵盖了从数据集采集-管理-评测全流程。
线上数据采样--样本集构建--自动/人工评测--工具优化/模型微调--线上ABtest--指标观测的闭环。
可观测能力可以采用传统监控机制,比如鹰眼/SkyWalking等看到服务延迟与错误率,AI的可观测则需要深入到LLM或Agent层面,关注Agent的执行路径/首token响应时间/token消耗与成本/tpm等。
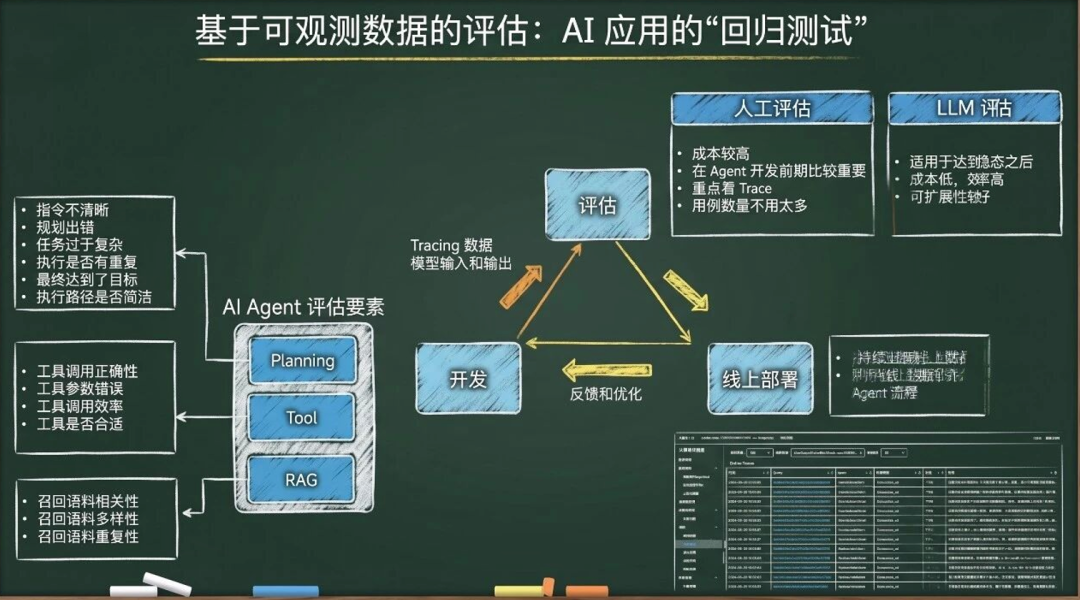
构建可观测数据的评估体系,如人工评估/LLM评估。
Agent Loop背后需要一套AI Friendly架构,包含三范式(确定性→概率性、结构化→语义化、静态→动态),含Multi-Agent系统、Context Engineering等能力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号