RAG 应用的测试策略设计

RAG 应用的测试策略设计

AI智享空间
发布于 2026-06-03 19:30:51
发布于 2026-06-03 19:30:51
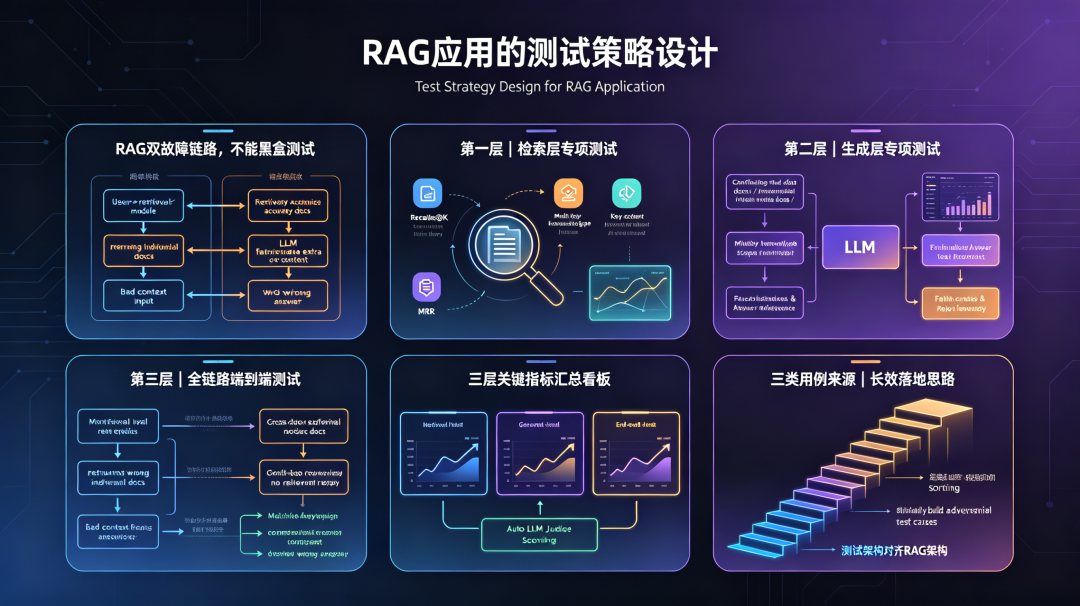
RAG(检索增强生成)的核心架构是这样的:用户提问 → 检索模块从知识库里找相关文档 → 把文档和问题一起送给 LLM → LLM 生成最终回答。
看起来简单。但这个架构意味着,系统里有两条独立的失效链路。
第一条:检索出了问题。找到的文档不相关、不完整、排序错误——LLM 拿到的材料就是错的,再强的模型也救不回来。
第二条:生成出了问题。检索结果明明是对的,但 LLM 没有正确利用它,忽略了关键信息,或者在文档之外自行“补充”了内容。
这两条链路相互独立,失效模式完全不同,却共同决定最终输出的质量。
把 RAG 当黑盒来测,你看到的只是最终答案对不对。但你不知道答案错了是因为检索失败,还是因为生成失败。这两个原因对应的修复方向完全不同——一个要调向量模型和索引策略,一个要调 prompt 和上下文处理逻辑。
所以 RAG 的测试策略,必须分层设计。
一、测试分层:三层独立验证
RAG 应用的测试应该分成三层,每层有独立的目标、方法和评估指标。层层验证,而不是只看最终输出。
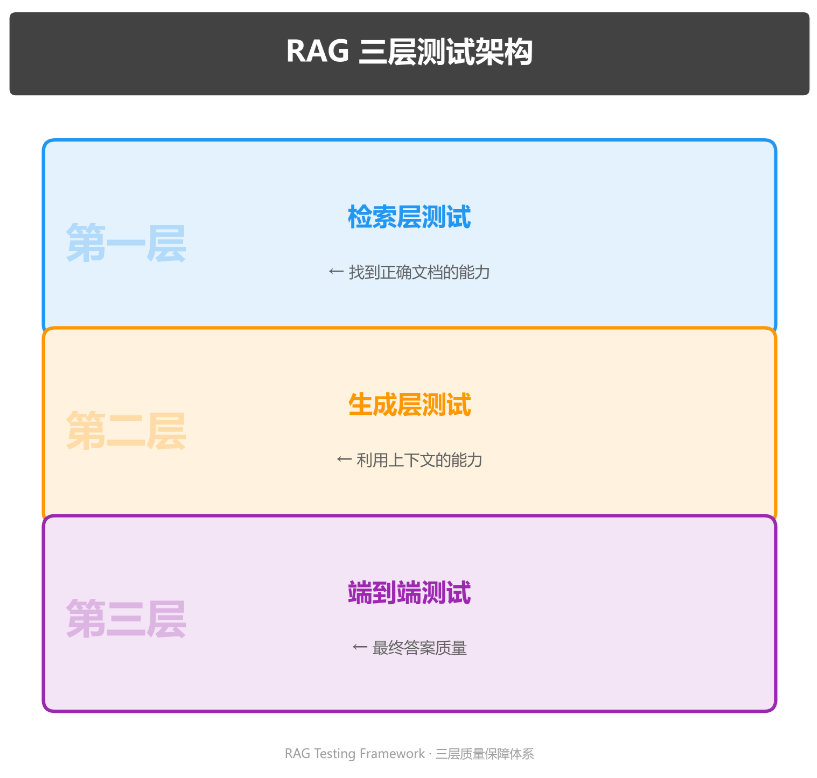
三层从下往上验证,下层是上层的基础。检索层有问题,生成层再好也没用;生成层有问题,检索层再准确也会被浪费。
二、第一层:检索层测试
检索层的核心问题只有一个:给定用户的提问,系统能不能找到正确的、相关的文档?
这一层的测试,和 LLM 没有任何关系。你测的是向量检索、BM25、重排序模型等检索组件的质量。
核心指标
召回率(Recall@K) 在返回的前 K 条结果里,包含了多少应该被找到的相关文档。这是最重要的指标。召回率低,意味着 LLM 根本拿不到回答问题所需的材料,后面的一切都是白搭。
计算方式:相关文档被检索到的数量 / 应该被检索到的相关文档总数。
精确率(Precision@K) 在返回的前 K 条结果里,有多少是真正相关的。精确率低,意味着 LLM 拿到了一堆噪声,上下文被无关内容稀释。
平均排名倒数(MRR,Mean Reciprocal Rank)第一条相关文档排在第几位?排名越靠前,LLM 越容易利用它。这个指标衡量的是检索结果的排序质量。
上下文相关性(Context Relevance)检索出来的文档片段,和用户的提问到底有多相关?不只是“找到了”,还要“找对了”。
测试用例设计
构建“问题-文档”标注集
这是检索层测试的核心工作,也是成本最高的部分。你需要为每个测试问题,标注出知识库里哪些文档(或文档片段)是回答这个问题所必需的。
标注集至少要覆盖四类场景:
- 直接匹配:问题中的关键词直接出现在文档里。这是最简单的情况,检索系统必须能处理好。
- 语义匹配:问题和文档的表达不同,但语义一致。比如问“如何取消订单”,文档里写的是“订单撤销流程”。这是向量检索应该解决的核心问题。
- 多跳检索:回答问题需要综合多个文档的信息。比如“A 产品和 B 产品在价格上的差异”,可能需要同时检索到两个产品的文档。
- 无答案场景:知识库里根本没有相关文档。系统应该检索不到有效内容,而不是检索到不相关的内容然后让 LLM 硬答。
Chunk 策略的边界测试
RAG 系统里,文档会被切分成若干片段(chunk)再建索引。切分策略直接影响检索质量。需要专门测试:
- 答案恰好横跨两个 chunk 的边界时,系统能不能同时检索到两个相关片段?
- Chunk 太小时,单个片段缺乏上下文,LLM 能否正确理解?
- Chunk 太大时,相关内容被稀释在大段无关文本里,检索排序是否还准确?
一个常见陷阱
很多团队在做检索层测试时,只测“能不能找到”,不测“找到的排序对不对”。但对 LLM 来说,第一条结果和第五条结果的权重是不一样的——排在前面的内容,LLM 更容易采纳。召回率高但排序混乱,同样会导致最终答案质量不稳定。MRR 和排序相关的指标,不能省。
三、第二层:生成层测试
假设检索层工作正常,文档已经准确找到了。接下来测的是:LLM 能不能正确利用这些文档来生成答案?
这一层的测试,需要把检索结果固定——用标准的、已知质量的文档作为输入,专门测 LLM 的上下文理解和生成能力。
核心指标
忠实性(Faithfulness) LLM 的回答,有没有超出提供的上下文?回答里的每一个声明,是否都能在检索到的文档里找到依据?
这是 RAG 生成层最重要的指标。RAG 的核心价值就是“有据可查”——如果 LLM 开始在文档之外自行发挥,RAG 就失去了它最重要的意义。
答案相关性(Answer Relevance)生成的回答,有没有真正回答用户的问题?有时候 LLM 会生成一段看起来和文档高度相关的文字,但其实没有直接回答用户的具体问题——内容对,但答非所问。
上下文利用率(Context Utilization) 检索到了 5 段文档,LLM 实际用到了几段?如果关键信息在第 3 段,但 LLM 只关注了第 1 段,后面的信息被忽略,说明模型对长上下文的处理有问题。
专项测试场景
文档冲突测试(Conflicting Context)
给 LLM 提供两段内容互相矛盾的文档,观察它的行为。
好的处理方式:明确指出文档之间存在矛盾,给出两种说法,说明无法确定哪个正确。
需要关注的问题:直接采信其中一方,完全忽视另一方,甚至把两段矛盾信息“融合”成一个错误的新结论。
这类测试在知识库内容来自多个来源(不同时间的文档、不同部门的规定)时尤为重要。
无关文档注入测试(Noise Injection)
在正确的检索结果里混入几段完全不相关的文档,观察 LLM 的抗干扰能力。
好的处理方式:正确识别并忽略无关文档,基于相关文档给出准确回答。
需要关注的问题:被无关文档“带跑”,在回答里引入了不相关的信息,甚至把无关文档的内容误当作答案。
知识边界测试(Knowledge Boundary)
给 LLM 提供的文档里完全没有回答问题所需的信息,观察它是否会老老实实说“根据提供的文档,无法回答这个问题”,还是会用自身参数知识来“补全”答案。
这是 RAG 系统里最常见的幻觉来源之一:检索没找到相关文档,但 LLM 不说不知道,而是凭空生成一个看起来合理的答案。
位置偏见测试(Position Bias)
把同一段关键文档放在上下文的不同位置(第一段、中间、最后一段),观察 LLM 的回答质量是否因位置不同而变化。
研究表明,很多 LLM 对位于上下文开头和结尾的内容注意力更高,中间部分容易被忽略。这个问题在上下文较长时尤为明显。如果你的 RAG 系统检索出 10 段文档,而关键信息在第 6 段,这个测试能告诉你系统是否存在系统性的漏读风险。
四、第三层:端到端测试
前两层分别验证了检索和生成的质量。第三层测的是完整链路在真实场景下的整体表现。
端到端测试不需要标注“哪些文档是正确答案”,它直接评估用户问题的最终回答质量。但它要配合前两层的测试结果一起看——端到端出了问题,要能快速定位是检索问题还是生成问题。
核心测试场景
多轮对话测试
RAG 系统在多轮对话中面临一个特殊挑战:用户的追问往往包含指代(“它”、“这个产品”、“上面提到的方案”),系统需要结合对话历史来理解当前问题的真实意图,再去检索。
测试重点:指代消解是否正确;多轮对话中检索质量是否稳定;前几轮的错误信息是否会污染后续回答。
知识库边界问题
用户问了一个知识库里完全没有覆盖的问题。端到端测试要验证系统能否清晰地告知用户“这个问题超出了我的知识范围”,而不是给出一个听起来合理但实际编造的回答。
时效性测试
如果知识库里有过期的文档和最新的文档同时存在,系统应该优先采信哪个?测试系统对文档时效性的处理策略是否符合预期。
跨文档综合推理
回答问题需要综合多个文档的信息,而不是从单个文档里直接抽取。这类问题考验的是系统在检索和生成两层的协同能力。
端到端的评估方式
端到端测试的评估,无法完全依赖自动化——因为“答案质量”本身是主观的。建议采用三层评估:
自动化初筛:用 LLM-as-Judge 对答案的准确性、完整性、忠实性做初步打分,快速筛出明显的问题输出。
抽样人工审核:对自动化评分在中间区间(既不明显好也不明显差)的输出,进行人工审核,校准自动评分的可靠性。
用户反馈闭环:在生产环境里收集用户的显式反馈(点赞/点踩)和隐式信号(是否追问、是否重新提问),把这些信号定期反哺到测试用例库里,让用例库持续贴近真实场景。
五、评估指标汇总
把三层测试的核心指标整理在一起,便于建立监控体系:
层级 | 指标 | 含义 | 关注方向 |
|---|---|---|---|
检索层 | Recall@K | 相关文档被找到的比例 | 覆盖完整性 |
检索层 | Precision@K | 检索结果中相关文档的比例 | 噪声控制 |
检索层 | MRR | 第一条相关文档的平均排名 | 排序质量 |
检索层 | Context Relevance | 检索内容与问题的相关程度 | 内容匹配 |
生成层 | Faithfulness | 回答是否忠实于检索内容 | 幻觉控制 |
生成层 | Answer Relevance | 回答是否真正回答了问题 | 答非所问 |
生成层 | Context Utilization | 关键文档被实际利用的程度 | 遗漏风险 |
端到端 | 端到端准确率 | 最终答案的整体正确性 | 全链路质量 |
端到端 | 拒答率 | 无法回答时的正确拒绝比例 | 边界处理 |
每个指标都要追踪版本间的趋势变化,而不只是看单次绝对值。某个指标从上个版本到这个版本下降了,比这个版本的绝对值是多少,更值得立刻关注。
六、测试用例从哪里来
再好的测试框架,也需要高质量的测试用例来驱动。RAG 测试的用例来源有三个。
来源1:业务场景梳理
把你的 RAG 应用实际会被用来做什么,系统性地梳理出来。每个核心使用场景,至少要有 10-20 条覆盖不同难度的测试用例。这是用例库的基础。
来源2:真实用户日志
线上运行一段时间后,从用户的真实提问里抽样,转化成测试用例。用户的真实提问往往比工程师自己设计的用例更贴近实际,能覆盖到很多“没想到的场景”。尤其要重点关注:用户追问了多次的问题(说明第一次没答好),用户给了差评的回答,以及用户重新换了措辞再问的问题(说明原始问题没被理解)。
来源3:对抗性构造
主动设计“难题”:知识库里有多个相似但不同的条目时故意提容易混淆的问题;把问题措辞设计成和文档表达差异很大的形式;构造需要跨 3 个以上文档才能回答的综合性问题。这类用例能找到系统的能力边界。
结尾:测试策略的本质,是跟系统架构对齐
RAG 应用的测试策略,说到底就是一件事:让测试结构和系统架构保持一致。
系统是两层串联的,测试就必须是分层的。检索层的问题和生成层的问题,表现出来的症状可能完全一样——最终答案不对——但根因完全不同,修复方向完全不同。用黑盒测试看结果,你发现问题;用分层测试看过程,你才能定位问题。
这不是一次性的工作。知识库在更新,模型在迭代,业务场景在扩展——测试用例库需要跟着演进,检索层和生成层的指标需要持续监控,每次版本变更后三层测试都需要重新跑一遍。
RAG 测试的成本,大部分不在于搭框架,而在于持续维护这套体系,让它始终能反映系统的真实质量。这是个长期投入,但也是 RAG 应用能放心上生产的底线。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号