英伟达出手,美国参数量最大的大模型开源,强化Agent能力

英伟达出手,美国参数量最大的大模型开源,强化Agent能力

Ai学习的老章
发布于 2026-06-02 14:34:38
发布于 2026-06-02 14:34:38
大家好,我是 Ai 学习的老章
老黄在 GTC San Jose 2026 上又放了个大招——NVIDIA 直接把自家最大的开源模型 Nemotron 3 Ultra 丢出来了,550B 总参数,55B 活跃参数,美国开源阵营的天花板,直接拉满

之前搞开源大模型,提到顶级选手,不是 Qwen 就是 DeepSeek,跟别说Kimi、GLM、Minimax了,美国这边一直缺一个真正能打的超大规模 base 模型,这次 NVIDIA 算是把底牌翻出来了
简介
Nemotron 3 Ultra 是 NVIDIA 目前开源的最大模型:550B 总参数,通过 MoE 架构实际每个 token 只激活 55B 参数,稀疏度达到 90%
架构上用的是 Hybrid Mamba-Transformer MoE(混合 Mamba-Transformer 混合专家架构),预训练采用 NVFP4 精度,和之前的 Nemotron 3 Super 一脉相承,但规模直接翻了好几倍
关键定位:这是一个 base 模型(预训练检查点),没有做 instruction tuning,也没有做 alignment——也就是说,你不能直接拿来当 ChatGPT 用,它是给你拿来做二次训练的底座
适合谁?做垂直领域微调的团队、搞 RLHF 后训练的研究者、需要一个超强起点来构建自己产品的公司,如果你只想开箱即用聊天,等后训练版本发布再说
三大核心技术
下面这张图把三大技术创新点的关系讲清楚了:
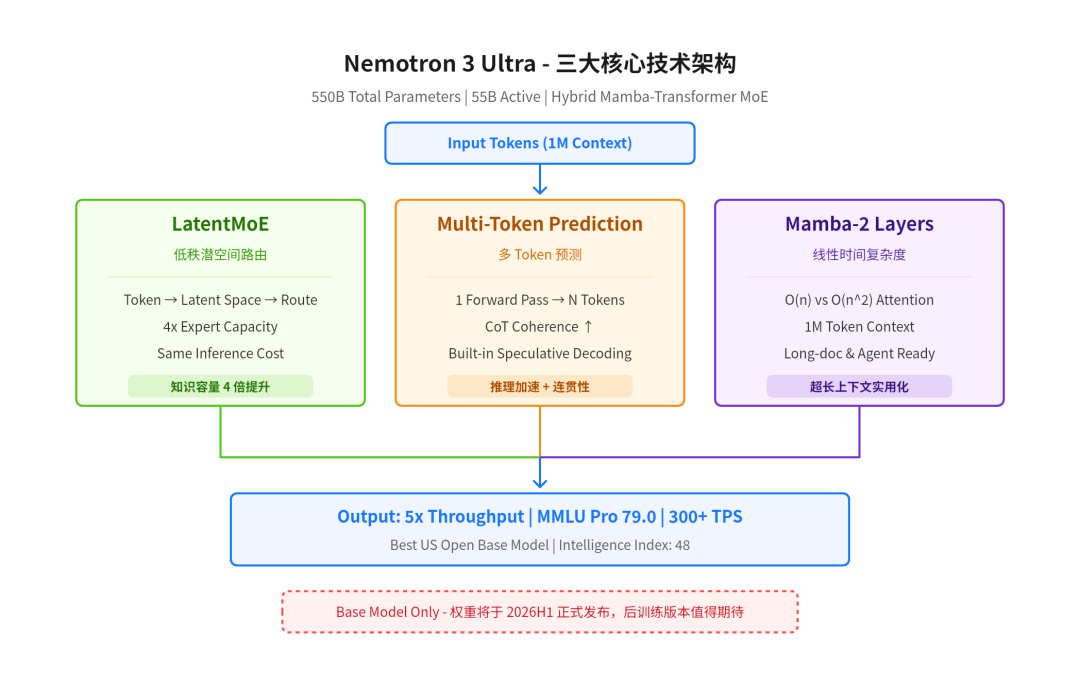
Nemotron 3 Ultra 三大核心技术架构
Nemotron 3 Ultra 三大核心技术架构
这个模型有三个技术创新点,每一个都相当硬核:
1. LatentMoE:低秩潜空间路由
传统 MoE 路由开销大,Nemotron 的做法是先把 token 压缩到一个低秩潜空间(latent space)里再做路由,好处是什么?同样的推理成本下,能塞进去 4 倍数量的专家
这意味着模型的"知识容量"远超同等推理开销的竞品,专家越多、分工越细、回答越精准
2. Multi-Token Prediction(MTP)
一次前向传播预测多个未来 token,带来两个直接收益:
- 训练时:chain-of-thought 连贯性更强,模型学会"看远一步"
- 推理时:天然支持 speculative decoding(投机解码),不用额外小模型配合就能加速
3. 1M Token 上下文
Mamba-2 层提供线性时间复杂度,让 100 万 token 的上下文在实际部署中真的可行,对比纯 Transformer 的二次方复杂度,这是质的飞跃
长文档处理、多轮 Agent 对话、代码库级别的理解——这些场景终于不用担心上下文窗口不够用了
跑分对比
NVIDIA 在 GB200 NVL72 上做了基准测试,对手是 GLM-4.5-355B(智谱)和 Kimi-K2-1026B(月之暗面):
基准 | Nemotron 3 Ultra 550B-A55B | GLM-4.5-355B-A32B | Kimi-K2-1026B-A33B |
|---|---|---|---|
MMLU Pro | 79.0 | 65.6 | 69.3 |
MMLU | 89.1 | 86.3 | 88.0 |
Code | 85.3 | 76.2 | 75.3 |
Math | 85.4 | 72.1 | 79.5 |
Common Sense | 81.0 | 81.3 | 81.6 |
Multilingual | 89.0 | 83.3 | 84.2 |
Peak Throughput | 5× | 1× | ~2.5× |
几个关键看点:
- MMLU Pro 上直接甩开 GLM-4.5 十三个点、甩开 Kimi-K2 十个点——base 模型做到这个水平,后训练版本想想就期待
- 代码和数学能力碾压级领先,85+ 的分数说明底座本身就有极强的推理能力
- 吞吐量 5 倍于 GLM-4.5,这才是生产环境最关键的指标,光模型好没用,跑得快才是真的好
- 唯一没赢的 Common Sense 差距极小(0.6 分),可以忽略
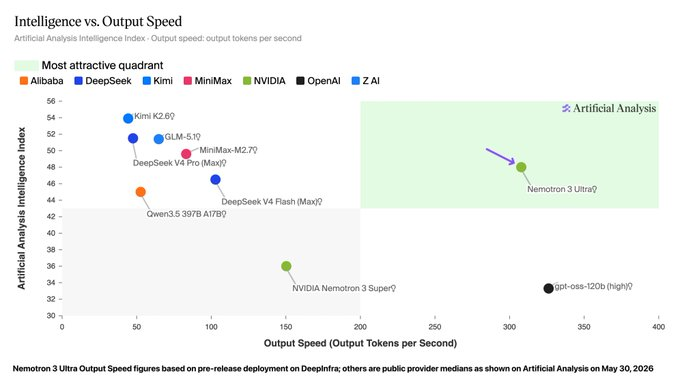
第三方评测怎么说
Artificial Analysis(独立第三方评测机构)给出的评价:
- Intelligence Index 得分 48,美国开源权重模型中最高
- 对比美国其他选手:Gemma 4 31B(39 分)、Nemotron 3 Super(36 分)、gpt-oss-120b(33 分),直接领先一个档次
- 目前全球开源第一是 Kimi K2.6(54 分),Nemotron 3 Ultra 排第二——但别忘了这还只是 base 模型
- 推理速度实测超过 300 tokens/秒,而同级别的 DeepSeek、Kimi 产品通常只有 50-100 tokens/秒
要知道,Nemotron 3 Ultra 还没做后训练,分数就已经这么猛了,等 post-trained 版本出来,大概率要把 Intelligence Index 再往上推一截
这玩意儿现在能用吗
目前不能
英伟达说法是权重将在 Nemotron 3 Ultra 正式版发布时开放,预期 2026 上半年,现在 GitHub 上只有 usage-cookbook 和 README,还没有模型权重可以下载
所以现在的状态是:NVIDIA 先亮了肌肉、给了跑分、建好了技术文档,但权重还在路上
如果你是做模型微调/后训练的,可以先开始准备:
- 了解 LatentMoE 架构的微调适配方案
- 准备好你的领域数据集
- GB200 NVL72 这种硬件先打个招呼(笑)
和竞品横向怎么比
维度 | Nemotron 3 Ultra | DeepSeek-V3 | Kimi-K2 | Llama 3.3 |
|---|---|---|---|---|
总参数 | 550B | 685B | ~1000B | 70B |
活跃参数 | 55B | ~37B | ~33B | 70B(Dense) |
上下文 | 1M | 128K | 128K | 128K |
架构 | Mamba+Transformer MoE | Transformer MoE | Transformer MoE | Dense Transformer |
后训练 | ❌ 未做 | ✅ 已做 | ✅ 已做 | ✅ 已做 |
推理速度 | 300+ t/s | 50-100 t/s | 50-100 t/s | 较快 |
核心优势:1M 上下文(Mamba 架构独有优势)、极高吞吐(5× GLM)、base 模型就有极强底座能力
核心劣势:还没后训练,不能直接用;需要 GB200 级别硬件;目前权重未发布
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号