1.6万美元的人形机器人,具身智能的GPT-2.5时刻来了

1.6万美元的人形机器人,具身智能的GPT-2.5时刻来了

老周聊架构
发布于 2026-06-01 17:45:19
发布于 2026-06-01 17:45:19
这是中国宇树科技(Unitree)G1 的价格。折合人民币约 11.6 万元,比一辆比亚迪秦还便宜。
而大洋彼岸,特斯拉的 Optimus 还在工厂里练习叠衣服,预计售价 2-3 万美元。
一边是硅谷做"高端制造",另一边是中国打"价格战"。听起来是不是很熟悉?没错,这和十年前智能手机的故事一模一样——苹果定义品类,中国厂商卷价格,最终所有人用上了智能机。
只是这次,"智能机"变成了"智能体"——会走路、会抓东西、会看、会听、会思考的人形机器人。
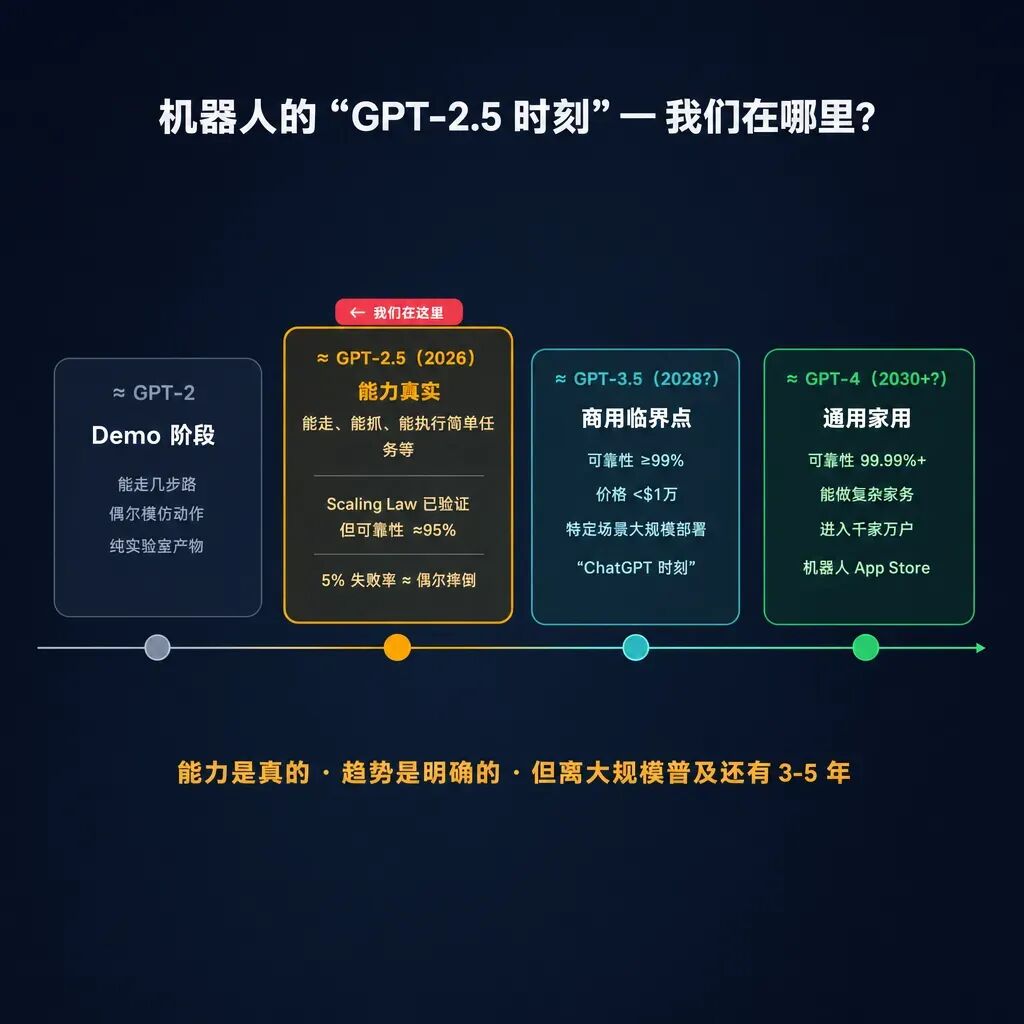
Bessemer Venture Partners 在 2026 年 5 月给出了一个精准的定位:机器人行业正处于"GPT-2.5 时刻"——能力是真实的,规模化规律开始显现,但离 99.9% 可靠性还有距离。
今天拆开来看,这个"GPT-2.5 时刻"到底是什么意思,技术上走到了哪一步,以及——作为技术人,我们能做什么。
一、"机器人的 GPT-2.5 时刻":能用,但还不够稳
GPT-2.5 时刻是什么意思?
回忆一下大语言模型的发展路径:
- GPT-2(2019):能写出看似通顺的段落,但经常胡说八道。有人觉得惊艳,有人觉得是玩具。
- GPT-3(2020):能力大幅提升,开始有人用它做真实任务,但可靠性不够,出错率高。
- GPT-3.5/ChatGPT(2022):突破临界点,普通人也觉得"这东西有用了"。
- GPT-4(2023):可靠性达到商用标准,大规模落地。
人形机器人现在大约处在 GPT-2 和 GPT-3 之间——所以叫"GPT-2.5 时刻"。
具体来说:
- 能力是真实的:能走路、能抓物体、能执行简单任务链
- 规模化规律开始显现:更多数据 + 更大模型 = 更好的表现,这个 scaling law 已经被验证
- 但可靠性不够:成功率可能是 90-95%,而不是商用需要的 99.9%
5% 的失败率,在聊天机器人里是"偶尔说错话"。在人形机器人里,是"偶尔摔倒砸到人"。
这就是为什么大语言模型用了 3 年就从 GPT-2 到 ChatGPT,而人形机器人可能需要 5-8 年才能走完同样的路——物理世界不容许"幻觉"。
二、VLA 模型:机器人的"大脑"
从 LLM 到 VLA
大语言模型的训练范式是:从海量文本中学习语言规律。
机器人基础模型的训练范式是:从海量视频中学习物理世界的规律。
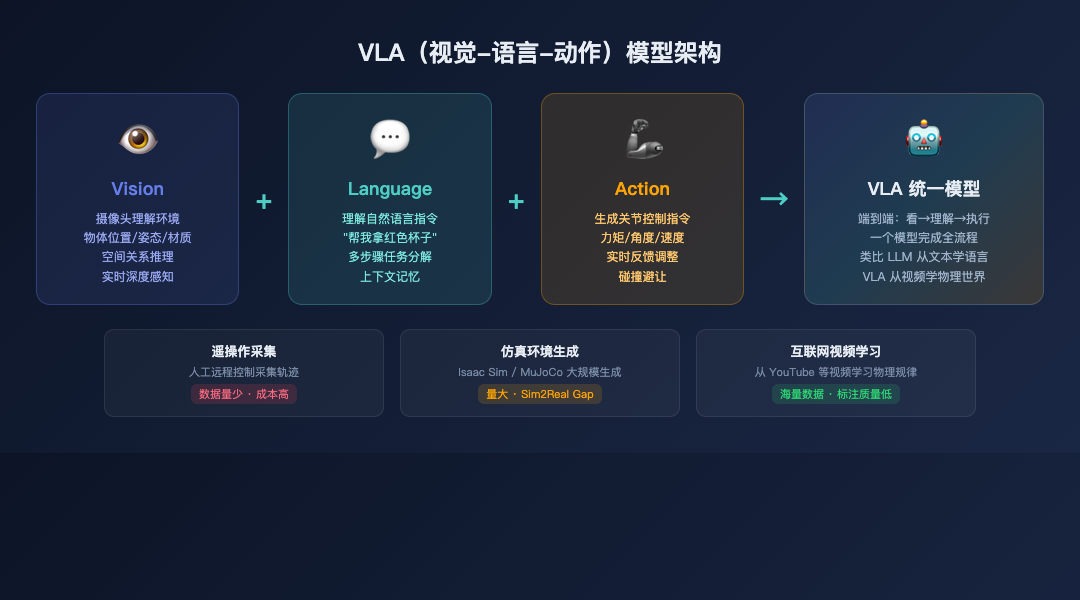
这就是 VLA(Vision-Language-Action)模型——视觉-语言-动作模型。
VLA 是当前具身智能最核心的技术主线。它把三种能力统一在一个模型里:
VLA模型架构
Vision(视觉):通过摄像头理解周围环境。不只是"看到一个杯子",而是理解杯子的位置、姿态、材质、是否有水、能不能抓。
Language(语言):理解自然语言指令。"帮我把桌上的红色杯子拿过来"——需要理解"桌上"、"红色"、"杯子"、"拿过来"的含义,并映射到具体动作。
Action(动作):生成机器人的关节控制指令。每个关节在每个时间步应该转到什么角度、施加多大力矩——这些底层控制信号由模型直接输出。
VLA 的训练数据从哪来?
这是 VLA 模型面临的最大挑战之一。
大语言模型的训练数据是文本——互联网上有几万亿 Token的文本可以用。
VLA 模型需要的是"带有动作标注的视频数据"——机器人在真实环境中执行任务的录像,并且每一帧都要标注机器人的关节状态和施加的力。
这种数据极度稀缺。
目前获取 VLA 训练数据的三条路:
路径一:遥操作采集。 人类操作员穿上动作捕捉设备,远程控制机器人执行任务。每一次操作都被记录为训练数据。但这很慢——一个操作员一天能采集 几十到几百条轨迹,而 VLA 模型需要几百万到几千万条。
路径二:仿真环境生成。 在 NVIDIA Isaac Sim、MuJoCo 等仿真平台中大规模生成训练数据。优点是速度快、成本低。缺点是 Sim-to-Real Gap——仿真中学到的策略,在真实世界中可能不管用(物理引擎再精确也不是真实物理)。
路径三:从互联网视频中学习。 让模型看 YouTube 上人类做家务、做饭、搬东西的视频,学习物理世界的规律。这是数据量最大的来源,但标注质量最差——视频中没有机器人的关节角度信息,需要模型自己推理。
谁能解决数据问题,谁就能在 VLA 竞赛中胜出。 这和当年大语言模型的竞争逻辑一样——数据规模和质量决定上限。
三、特斯拉 vs 宇树:西方造制造,东方压价格
特斯拉 Optimus:高举高打
特斯拉 Optimus 的策略是典型的马斯克风格——先造最难的,然后往下降维。
Optimus 的技术路线:
- 自研 FSD(Full Self-Driving)芯片做计算平台
- 基于特斯拉自动驾驶积累的视觉能力做环境理解
- 先在特斯拉工厂内部验证(搬运、分拣、质检)
- 目标售价 2-3 万美元,大规模量产后降到 2 万美元以下
优势:特斯拉有全球最大的视觉数据采集网络(几百万辆车上的摄像头),自研芯片能力强,垂直整合度高。
劣势:进度慢。Optimus 目前还在做工厂内部的简单任务,距离"走进千家万户"还有很长的路。
宇树 G1:中国式降维
宇树科技的 G1 走了完全不同的路——先把价格打下来,让更多人用得起。
G1 的核心参数:
- 身高约 1.3 米,体重约 35 公斤
- 售价约 1.6 万美元(约 11.6 万人民币)
- 支持基本的行走、抓取、搬运
- 开放 SDK,支持二次开发

特斯拉 vs 宇树竞争格局
1.6 万美元意味着什么?
- 比特斯拉 Optimus 目标价便宜 40-50%
- 大约等于一台高配 MacBook Pro 的价格
- 进入了中小企业和科研机构的采购预算范围
宇树的逻辑和小米做手机一样:不追求最强性能,追求最优性价比。 先用低价铺量,让更多开发者和企业用上人形机器人,然后通过数据积累和生态建设逐步提升能力。
"苹果-安卓"格局正在形成
特斯拉和宇树的竞争,很像当年的 iPhone vs 安卓:
维度 | 特斯拉 Optimus | 宇树 G1 |
|---|---|---|
定位 | 高端、垂直整合 | 性价比、开放生态 |
价格 | $2-3 万 | $1.6 万 |
软硬件 | 自研闭环 | 开放 SDK |
数据来源 | 自动驾驶数据 | 社区贡献 |
目标市场 | 工厂、企业 | 科研、中小企业 |
类比 | iPhone | 安卓手机 |
最终结果大概率也和手机一样:高端市场特斯拉吃肉,中低端市场中国厂商分蛋糕,但全球出货量的大头在中国这边。
四、99.9% 可靠性:最后 5% 是最难的
从 95% 可靠性到 99.9% 可靠性,看起来只差 4.9 个百分点。
但这 4.9% 可能需要和前 95% 一样多的努力——甚至更多。
为什么最后几个百分点这么难?
长尾场景。 机器人在标准环境中表现很好,但真实世界充满了"边缘情况":地上有根电线、桌角有个不规则形状的物体、光线突然变暗、地面湿滑……这些长尾场景在训练数据中出现频率很低,但在现实中随时可能遇到。
物理约束。 软件出 bug 可以重启。机器人出 bug 可能摔倒、撞人、砸东西。物理世界不能回滚。 这要求机器人不仅要做出正确动作,还要有能力判断"这个动作有多大把握能成功",在不确定时选择保守策略。
累积误差。 一个 10 步的任务,每步成功率 99%,整体成功率只有 90.4%。如果是 50 步的复杂任务,整体成功率掉到 60.5%。要让复杂任务可靠执行,每一步的成功率必须极高。
三个技术方向
方向一:Sim-to-Real Transfer(仿真迁移)
在仿真环境中训练机器人应对各种极端场景(摔倒恢复、碰撞避让、抓取失败重试),然后迁移到真实环境。NVIDIA 的 Isaac Sim 和 Google 的 Brax 是这个方向的代表。
方向二:世界模型(World Model)
让机器人在大脑中"模拟"物理世界——在执行动作前,先在内部模拟一下结果。如果模拟结果不好,就换个策略。这本质上是给机器人装了一个"物理直觉引擎"。
方向三:人类反馈强化学习(RLHF for Robots)
类似 ChatGPT 用 RLHF 提升对话质量,让人类评价机器人的行为,通过强化学习持续优化。这需要大量的人机交互数据。
五、对技术人的三个判断
第一,VLA 是未来 3-5 年最值得关注的 AI 方向之一。
如果说 LLM 是"数字世界的大脑",VLA 就是"物理世界的大脑"。VLA 模型的研发需要同时具备计算机视觉、自然语言处理、机器人控制、强化学习的跨领域能力——这种复合型人才极度稀缺。
第二,机器人的"App Store 时刻"可能在 2028-2030 年。
当人形机器人的可靠性突破 99% 并且价格降到 1 万美元以下时,就会出现机器人版的"App Store"——开发者为机器人开发各种"技能包"(做饭、清洁、陪护、仓储分拣)。平台生态的争夺,才是真正的终极战场。
第三,中国在具身智能赛道有结构性优势。
制造业基础(伺服电机、减速器、传感器的产能和成本优势)、工程师红利(机器人工程师数量全球最多)、应用场景丰富(工厂、物流、养老)——这三个因素让中国在机器人量产和落地方面有天然优势。
宇树 G1 的 1.6 万美元定价就是这种优势的体现。特斯拉可以做出更酷的机器人,但中国厂商可以让更多人用上机器人。
写在最后
人形机器人正处于"GPT-2.5 时刻"——能力是真的,趋势是明确的,但还没到大规模普及的临界点。
就像 2020 年的大语言模型:懂行的人已经看到了未来,但大部分人还在问"这东西有什么用"。
两年后 ChatGPT 出现,所有人都不问了。
人形机器人的"ChatGPT 时刻"也会来。可能是 2028 年,可能是 2030 年。当一台机器人能像人类一样稳定地完成日常家务,并且价格不超过一辆电动车——那一天,就是分水岭。
到那时,"你家有机器人吗"这个问题,就会像今天的"你用 AI 吗"一样普通。
我们正站在这个变革的起点上。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号