ESMC, ESMFold2, & ESM Atlas | 结构预测之后,蛋白质 AI 的下一道问题

ESMC, ESMFold2, & ESM Atlas | 结构预测之后,蛋白质 AI 的下一道问题

MindDance
发布于 2026-05-29 13:14:08
发布于 2026-05-29 13:14:08

AlphaFold 之后,蛋白质 AI 的叙事一度很清楚:给定一条氨基酸序列,预测它会折成什么三维结构。这个问题已经被显著推进,AlphaFold Protein Structure Database 公开了超过 2 亿个蛋白结构预测,成为很多研究流程的默认入口。
但进入真实研发场景后,问题很快变得不止是折叠。
药物发现里,研究者常常关心的是另一组问题:一个未知蛋白可能做什么;某个疾病靶点附近有没有可利用的结合口袋;能否设计一个蛋白或抗体片段,既能紧密结合,又足够特异、稳定,并且在细胞实验里产生预期功能。结构预测给出了重要坐标,但它还没有自动回答这些问题。
Biohub 这次发布的 ESMC、ESMFold2 和 ESM Atlas,值得看的地方正在这里。它并不只是把一个折叠模型做得更快,或把数据库做得更大,而是试图把蛋白序列模型、结构预测、结合物设计和大规模可搜索图谱组织成一个连续系统。Biohub 将其称为 protein biology 的 world model:一个基于进化序列训练、用于表示、预测、设计和发现蛋白的开放式科学引擎。
它到底在做什么
这套系统有三个核心部件。
第一个是 ESMC。它是蛋白语言模型,输入是氨基酸序列,训练目标接近自然语言模型里的完形填空:遮住序列中的一部分氨基酸,让模型根据上下文预测它们。不同之处在于,这里的上下文不是人类语句,而是进化留下的蛋白序列记录。Biohub 公告称,ESMC 训练于约 28 亿条跨生命树的序列,用来学习蛋白折叠、相互作用和功能背后的统计规律。
第二个是 ESMFold2。它把 ESMC 学到的序列表征转成原子分辨率的三维结构预测。它支持从单条序列预测,也可以在困难靶点上加入多序列比对,也就是 MSA,以提升准确性。模型卡还说明,ESMFold2 相比早期 ESMFold,可处理蛋白、DNA、RNA、小分子和修饰氨基酸组成的复合体系。
第三个是 ESM Atlas。它把 ESMC 的内部表征扩展到 68 亿个蛋白序列和 11 亿个预测结构上,使研究者可以在一个大规模图谱中检索结构和功能邻域。Atlas 还引入稀疏自编码器,Sparse Autoencoder,简称 SAE,把 ESMC 内部表征拆成约 1.6 万个可解释特征,并用自动化流程把这些特征关联到已知蛋白数据库中的功能线索。
这三个部件对应三种不同任务:ESMC 负责读懂序列,ESMFold2 负责把读懂的东西落到结构和相互作用上,ESM Atlas 负责把这些表征变成可搜索、可解释的蛋白空间。
问题为什么会出在这里
蛋白研究的困难,不只是实验慢。
一个蛋白序列可能有结构,有功能,有相互作用对象,也可能只是在宏基因组测序里被看见过一次。很多蛋白有序列,没有实验结构;有结构,没有清晰功能;有功能注释,但缺少细粒度机制。随着测序规模扩大,未注释蛋白空间增长得比实验表征更快。
这正是蛋白语言模型被反复尝试的原因。进化不是随机保留序列。能在自然界中留下来的蛋白,通常满足一定的稳定性、折叠约束和功能约束。ESMC 的思路是:如果模型能在数十亿条序列上学会预测被遮住的氨基酸,那么它内部可能会形成对结构和功能约束的压缩表示。Biohub 在 ESMC 介绍中强调,结构和功能信息可以在无监督序列训练中从内部表征里浮现出来,而模型训练时并不直接看结构或功能标签。
这条路线并不是第一次出现。ESM3 已经展示过更强的生成能力:它同时处理蛋白的序列、结构和功能,并被用于生成一个与已知荧光蛋白只有 58% 序列相似性的绿色荧光蛋白 esmGFP,作者估计其距离相当于超过 5 亿年自然进化。这个结果说明,蛋白语言模型不只是能给已有蛋白打分,也可以在远离已知序列的位置生成有功能的蛋白。
这次 ESMC、ESMFold2 和 ESM Atlas 的组合,把问题从单点生成推进到系统化使用:先把蛋白空间表示出来,再预测结构与相互作用,最后让研究者能在大规模图谱里寻找功能线索。
方法是怎么组织起来的
ESMC 做的是表示学习。它把一条蛋白序列转成高维表征,这个表征不是简单的序列相似性,而是模型在预测氨基酸过程中压缩出来的结构和功能信号。Biohub 早期 ESMC 说明中给出过三个模型规模:3 亿、6 亿和 60 亿参数,并报告结构信息随训练计算量和模型规模提升而持续增长。
要判断 ESMC 是否只是参数更大,需要看它是否在结构相关任务上形成更强内部表征。
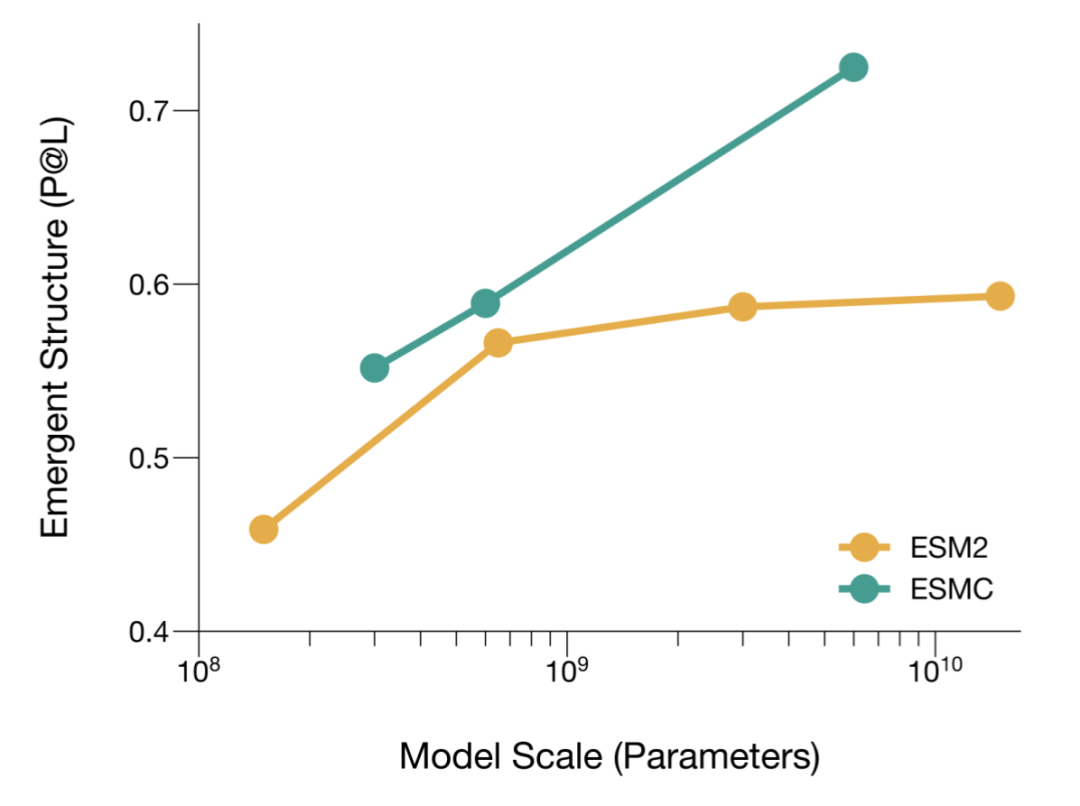
上图比较了 ESMC 与 ESM2 随模型参数规模变化时,内部表征中可读出的长程结构信息。P@L 越高,说明模型表征中包含的残基接触关系越强。
上图比较了 ESMC 与 ESM2 随模型参数规模变化时,内部表征中可读出的长程结构信息。P@L 越高,说明模型表征中包含的残基接触关系越强。
ESMC 的结构信息随规模扩大继续提升,而 ESM2 在更大规模下增益趋缓。这里的重点不是模型直接输出了结构,而是序列模型内部已经编码了可被简单读出的残基接触关系。Biohub 的评估方法使用逻辑回归从表征中读出接触图,并在 CASP15 或时间留出的 PDB 结构集合上计算 P@L。
ESMFold2 接上这一层表征。它使用 ESMC 6B 的语言模型嵌入,再结合结构预测架构,把序列或复合物输入转成三维坐标。模型文档称,ESMFold2 可以直接从氨基酸序列预测高分辨率、全原子三维结构,也可以在困难任务中加入 MSA;其 Fast 版本则面向单序列快速推理。
ESM Atlas 则把模型能力从单条序列扩展为一个可浏览空间。Atlas 不只是保存结构,它还按照 ESMC 学到的关系组织蛋白,使研究者能看到传统序列相似性或结构相似性检索不容易暴露的功能邻域。Biohub 公告特别提到,Atlas 能把一些基因编辑酶在生命树远端分支上的演化联系暴露出来,其中很多生物学内容尚未注释。
旧方案为什么会卡在专业场景里
AlphaFold 类模型改变了结构生物学的工作基线,但结构预测并不等同于蛋白设计。AlphaFold2 的经典架构利用了原始序列、同源序列形成的 MSA,以及可用模板;这对已知同源关系丰富的蛋白非常有效,但当任务转向新设计蛋白、蛋白-蛋白界面、抗体-抗原结合姿态和高通量虚拟筛选时,瓶颈会转移到速度、搜索空间和实验可验证性上。
另一方面,传统数据库检索常依赖序列同源性、结构相似性或已有注释。对未注释蛋白、远缘同源关系和功能趋同关系来说,这些检索方式容易漏掉信号。ESM Atlas 的设计正是把模型内部表征作为新的组织轴,让蛋白之间的关系不只由显式序列或已知结构决定。
这不是说旧方案失效了。更准确地说,旧方案解决了结构预测中的一大块确定性问题,而专业场景还需要处理选择、设计、排序、解释和验证。ESM 这次发布的系统,把这些环节尽量放进同一条计算管线。
新设计解决了什么
第一个变化是速度与规模。ESMFold2 的单序列模式减少了对 MSA 构建的依赖,README 中称可带来一个数量级的折叠加速;这种速度优势在处理 68 亿蛋白序列和 11 亿结构预测时尤其关键。
第二个变化是面向相互作用。很多药物设计任务不是预测一个蛋白自己怎么折,而是预测两个分子是否以正确姿态结合。Biohub 报告称,ESMFold2 在蛋白-蛋白复合物和抗体-抗原复合物预测基准上表现达到或超过 AlphaFold3 等模型;在使用与 AlphaFold 相同的 MSA 信息时,ESMFold2 在两个基准上为最强预测器。这个结论需要限定在其报告的基准和评价设置内,不能直接外推到所有药物研发任务。
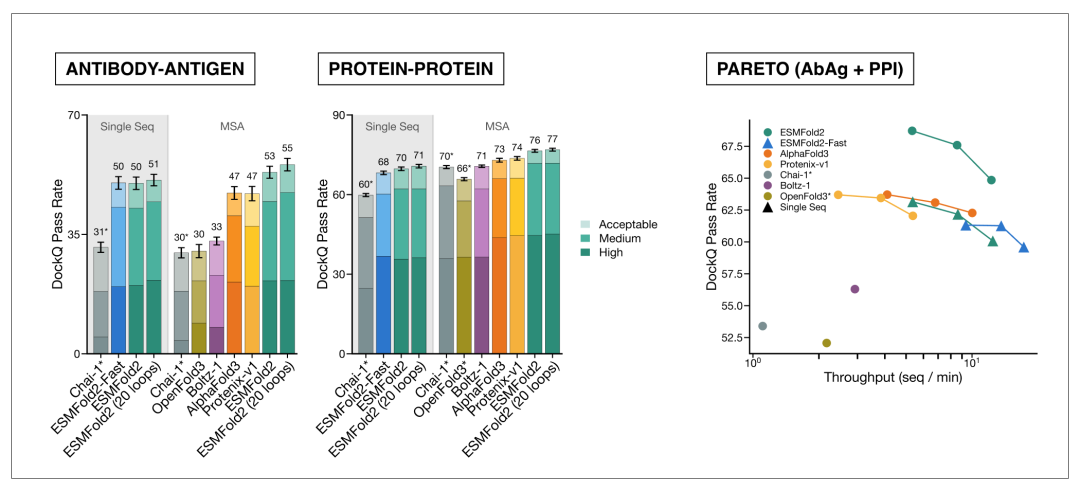
上图比较了 ESMFold2 与 AlphaFold3、Boltz-1、Protenix-v1 等模型在抗体-抗原和蛋白-蛋白复合物预测中的 DockQ 通过率,并展示了准确率与推理吞吐量之间的关系。
上图比较了 ESMFold2 与 AlphaFold3、Boltz-1、Protenix-v1 等模型在抗体-抗原和蛋白-蛋白复合物预测中的 DockQ 通过率,并展示了准确率与推理吞吐量之间的关系。
抗体-抗原复合物比一般蛋白-蛋白复合物更难,模型间差距也更明显;同时,ESMFold2 在增加推理预算时准确率继续提升,说明它的优势不只来自一次前向预测,还来自对结构解空间的搜索和自置信度排序。
第三个变化是从预测走向设计。Biohub 团队使用 ESMFold2 设计了针对 EGFR、PDGFRβ、PD-L1、CTLA-4 和 CD45 五个癌症与免疫相关靶点的蛋白结合物。官方报告给出的实验结果是:紧凑型 minibinder 的命中率为 36–88%,抗体来源的 scFv 格式命中率为 15–29%,并在实验中确认了结合;其中 PD-L1 设计结合物在实验中恢复了 T 细胞信号,阻断了获批免疫检查点疗法所针对的同一路径。
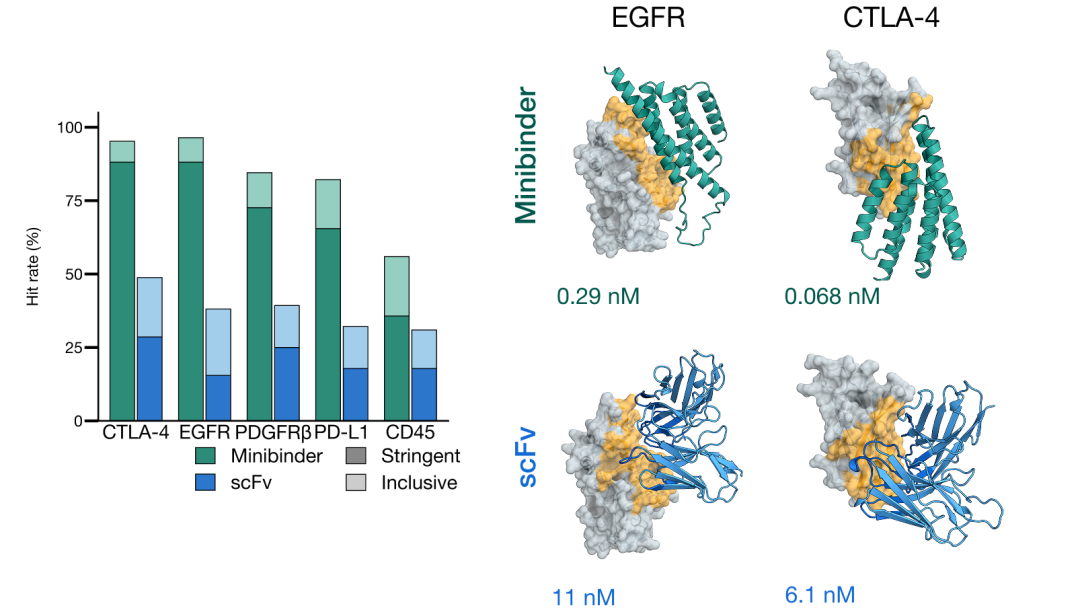
上图展示了 ESMFold2 设计的 minibinder 与 scFv 在多个癌症和免疫相关靶点上的实验命中率,并给出部分代表性结合结构与亲和力结果。
上图展示了 ESMFold2 设计的 minibinder 与 scFv 在多个癌症和免疫相关靶点上的实验命中率,并给出部分代表性结合结构与亲和力结果。
计算设计已经能把实验筛选的起点向前移动。模型先在表征空间和结构空间里产生候选,再把更可能成功的设计送入实验验证。命中率的提升来自计算预筛选,但最终结论仍然来自湿实验。
结果到底说明了什么
ESMC 的结果说明,蛋白语言模型的规模化仍然能带来结构表征增益。任务是从模型内部表征读出残基接触关系,数据是 CASP15 或时间留出的 PDB 结构集合,比较对象是上一代 ESM2。结果显示,ESMC 在相近或更小参数量上取得更强结构信号,60 亿参数版本进一步扩大差距。机制上可以理解为:更多训练数据、更有效训练和更强模型容量,使序列预测任务中隐含的远程约束更充分地进入内部表征。
ESMFold2 的结果说明,结构预测竞争的焦点正在从单体折叠转向复合物界面和推理时搜索。抗体-抗原结合姿态是更接近药物发现的问题,因为错误的界面预测会直接影响候选设计。Biohub 报告中,ESMFold2 在这类任务上相对 AlphaFold3、Boltz-1、Protenix-v1 等模型具有优势,尤其是在允许更多推理预算时表现继续上升。这里的边界也很清楚:这是结构与姿态预测基准,不等同于体内有效性、免疫原性、成药性或临床成功。
Binder 设计实验说明,这套系统已经跨过了纯计算预测,进入了实验闭环。五个靶点覆盖癌症和免疫研究中的典型对象,比较对象不再只是其他模型,而是实验中的结合、特异性、稳定性和功能读出。36–88% 与 15–29% 的命中率范围说明不同设计格式和靶点难度差异很大;PD-L1 的 T 细胞信号恢复实验则表明,至少在这个局部任务上,模型设计的结合物不只是能粘上靶点,还能干预相关生物通路。
Atlas 的结果更像基础设施。它把 68 亿蛋白和 11 亿结构放进一个可检索图谱,再用 SAE 特征提供解释入口。下面这张表适合放在文章中段,帮助读者把规模感具体化。
数据类型 | 规模 |
|---|---|
蛋白序列 | 68 亿个蛋白 |
预测结构 | 10 亿级结构;平台页列为 1B,公告列为 11 亿 |
SAE 特征 | 覆盖 68 亿蛋白的蛋白级和残基级特征向量 |
SAE 聚类 | 750 万个聚类 |
全量数据 | 377 TB |
Atlas 把蛋白 AI 从模型推理扩展成数据资源。研究者可以从一个疾病相关蛋白、一个未知结构域或一个功能关键词出发,在模型组织出的邻域里寻找候选关系。它给出的仍然是计算假设,但假设生成的覆盖面和速度发生了变化。
END
这项工作的长期意义,不在于宣布蛋白设计已经被解决,而在于把问题重新组织了。
过去,很多流程是先找同源序列、查数据库、跑结构预测、人工筛候选、再进入实验。ESM 的新系统试图让模型表征贯穿这些环节:序列被嵌入同一个空间,结构由同一套表示驱动,未知蛋白可以在 Atlas 中被检索,设计候选可以通过 ESMFold2 排序后进入实验。
这会让早期探索更像虚拟实验。研究者可以先在计算空间里提出更多假设,再把有限实验资源集中到更有希望的候选上。Benchling 对 Biohub 团队的访谈中也提到,ESMFold2 的速度使大规模虚拟筛选、de novo binder 生成和交互组层面的结构探索变得更实际。
但边界需要同时写清楚。
ESMFold2 模型卡明确指出,模型输出应被视为需要实验验证的假设,不能替代 X 射线晶体学、冷冻电镜或核磁等实验结构测定;它也不面向未经进一步验证的临床或治疗用途。模型还可能受到 PDB、AlphaFold DB 等训练数据偏倚影响,对欠代表蛋白类型、动态构象、多构象和无序区域表现下降。
开放也带来责任问题。Biohub README 称,团队在发布前对 ESMC、ESMFold2、SAE、ESM Atlas 和 binder 设计系统进行了生物安全与生物安保风险评估,并在平台上设置了针对受控病原体和毒素关键词及序列的限制;代码、权重、Atlas 数据和 binder 设计系统则在风险评估后开放发布。
所以,更稳妥的判断是:ESM 这次发布把蛋白 AI 的任务从预测一条序列的结构,推进到组织蛋白空间、预测相互作用、生成实验候选和解释未知功能。它不会直接替代实验,也不会绕过药物开发中的安全性、有效性和可制造性验证。但它确实让很多过去分散的步骤,第一次有机会在同一套开放模型和数据底座上连续运行。
这可能是结构预测之后,蛋白 AI 更现实的一步。
参考文献
[1] Biohub. Biohub releases a world model of protein biology. 2026. https://biohub.org/news/world-model-of-protein-biology/
[2] Biohub GitHub. A world model of protein biology: ESMC, ESMFold2, & ESM Atlas. 2026. https://github.com/Biohub/esm
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号