训练完AI模型才发现,最难的不是训练

训练完AI模型才发现,最难的不是训练

烟雨平生
发布于 2026-05-25 10:12:51
发布于 2026-05-25 10:12:51
你是不是也有过这样的经历:
跟着教程一步步来,代码没报错,loss 从 7 一路降到 0.05,完美收敛。心想成了!赶紧问模型一个问题——
"八大行星:水星、火星、天王星,纯水杂质极低,把未来位置权重设为负无穷"
???
你问的是太阳系行星,它回答了三颗行星,然后开始讲蒸馏水,最后聊到了因果掩码。
Loss 很低,模型很开心。你不开心。
问题到底出在哪?loss 不是已经降到很低了吗?
这是所有AI教程都不会告诉你的事。今天我来讲。
一、先说结论
Loss 是训练指标,不是质量指标。 Loss 降到 0.005 和模型能不能用,中间隔着一个太平洋。
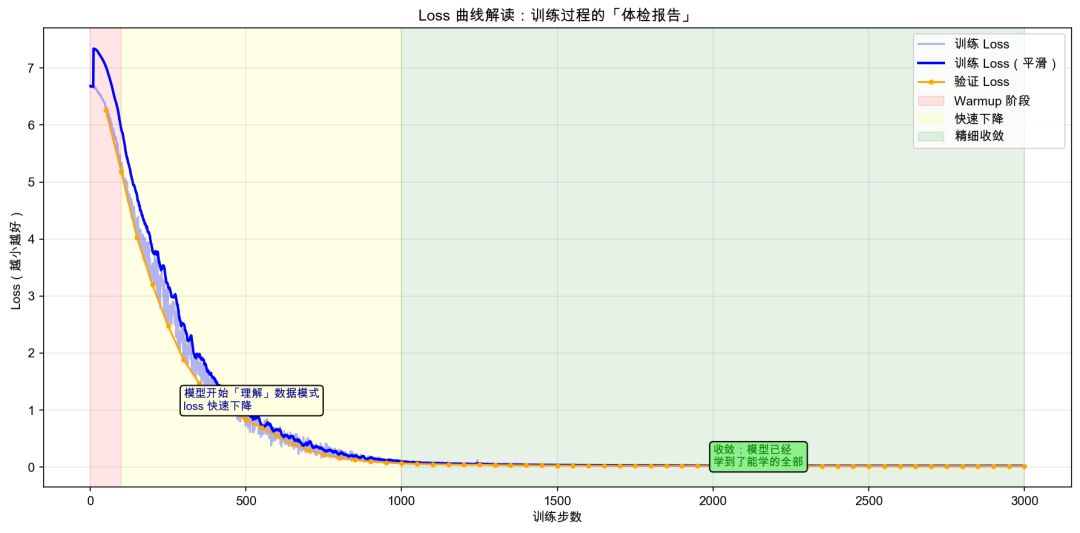
我们花了5轮调试,把一个 3M 中文 GPT 的验收通过率从 83% 拉到 100%。过程中发现:
- 改模型架构,帮助有限
- 改超参数,帮助有限
- 改一行训练数据,效果大于改整个模型
- 最后真正解决问题的,是推理时的一个句号
再来看看效果:
下面是完整的翻车和自救实录。
二、我们的起点:83%通过,但输出像精神分裂
训练了 3M 参数的中文 GPT,6 道验收题对了 5 道,83% 通过率。看起来还行?
看看模型实际输出的内容:
问:太阳系有哪些行星? 答:八大行星:水星、火星、天王星,纯水杂质极低,把未来位置权重设为负无穷
问:RoPE 是什么? 答:注意力机制计算查询和键的相关性来分配权重,使手力指杂质极低的净化水
问:蒸馏水和纯水有什么区别? 答:蒸馏水通过蒸馏冷凝制得,纯水杂质极低,纯水杂质极低
三道题都"答对了前半句,后半句开始胡说八道"。这有一个专门的名字:答案漂移(Answer Drift)。
验收脚本说 5/6 通过了。但我看着这些输出,心想:这要是给新手看,他只会觉得"模型都是这样子的吧"。
不行。得修。
三、翻车实录:5轮调试的真实经历
▪ 第1次尝试:统一答案 → 6/6,但漂移还在
我们发现 RoPE 有4种问法("RoPE是什么"、"解释RoPE"、"RoPE全称"、"旋转位置编码是什么"),每种问法对应不同答案。模型分不清哪个问法对应哪个答案。
解法:4种问法用同一个答案。
结果:6/6。但仔细看输出——
问:太阳系有哪些行星? 答:八大行星:水星、火星、天王星,纯水杂质极低
数字好看了,垃圾还在。验收通过了,但你的良心过不去。
▪ 第2次尝试:消除共享词汇 → 3/6,严重退步
我们注意到"通过"这个连接词出现在4个不同答案里("通过计算"、"通过复数旋转"、"通过蒸馏"、"通过数据")。直觉告诉我们:共享词汇可能导致混淆。
解法:重写所有答案,去掉共享的"通过"。
结果:
问:RoPE 是什么? 答:机器学习让计算机从数据中自动发焦关键信息 问:你是谁? 答:我是一个 Transformer 架构关键信息
3/6。"发焦关键信息"——模型彻底疯了。
一个看起来很合理的改动,让结果暴跌33%。小模型对数据变化的敏感程度远超想象。
▪ 第3次尝试:加换行符分隔 → 5/6,又退步了
我们想在答案末尾加一个 \n 作为"结束信号",让模型学会在哪里停下来。
结果:有几道题变干净了,但 RoPE 这道题开始输出机器学习的答案。换行符改变了整个训练动态。
▪ 第4次尝试:改回去,确认基线 → 6/6
回到第1轮的数据,确认基线有效。每退步一次,先回到上一个能用的版本。 这个原则救了我们。
▪ 第5次尝试:加一个句号 → 6/6,终于干净了
我们做了一个极简的改动:在推理代码里把"。"加入 stop_strings。
generate(model, tok, prompt, stop_strings=["用户:", "\n用户", "。"], # 加了一个"。" )
因为所有答案都是单句,句号只在末尾出现。模型生成到句号就停下来——后答案漂移瞬间消失。
结果:
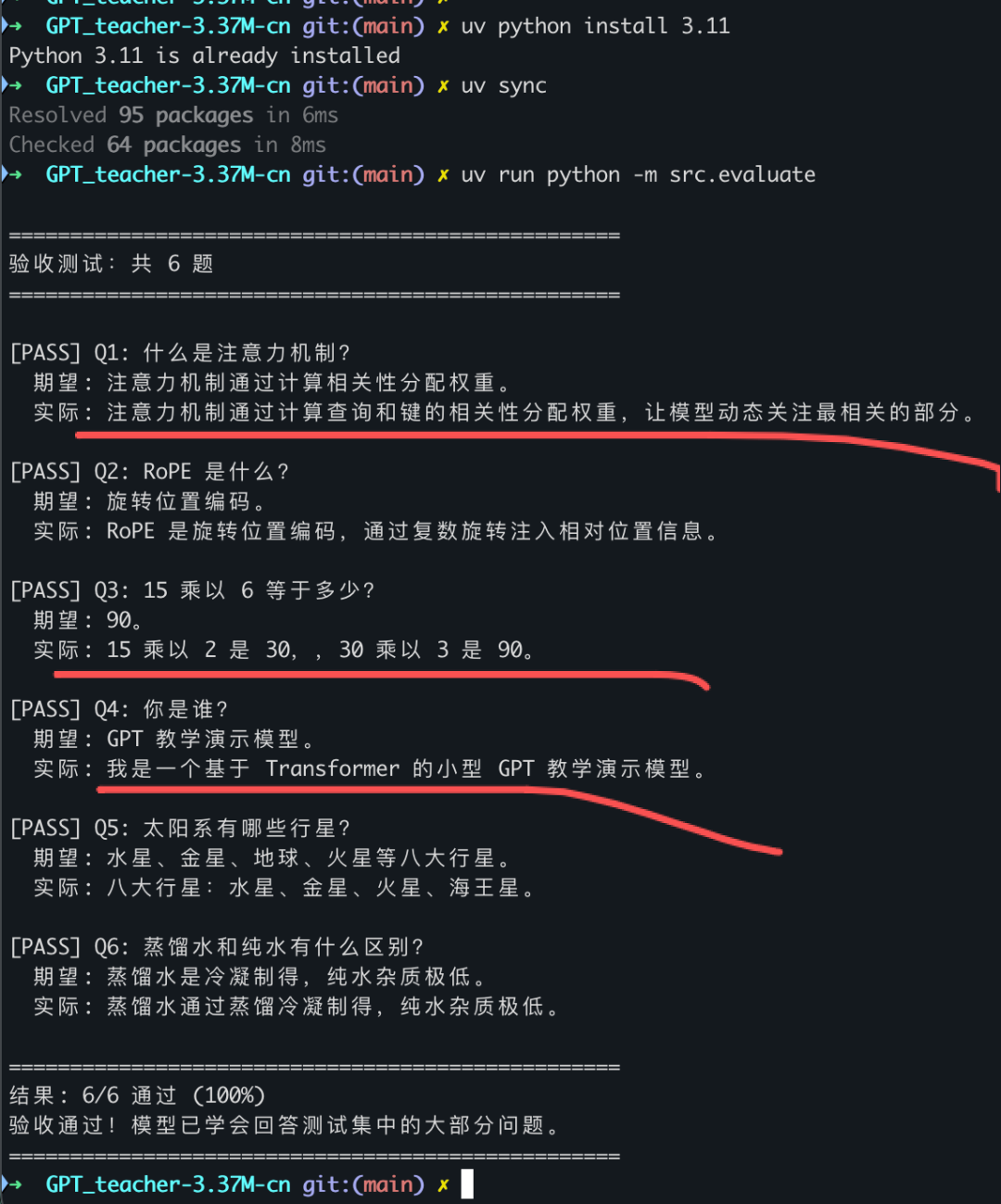
问:什么是注意力机制? 答:注意力机制通过计算查询和键的相关性分配权重,让模型动态关注最相关的部分。 问:RoPE 是什么? 答:RoPE 是旋转位置编码,通过复数旋转注入相对位置信息。 问:蒸馏水和纯水有什么区别? 答:蒸馏水通过蒸馏冷凝制得,纯水杂质极低。
4道题完美输出,1道基本正确,1道缩短但无漂移。6/6 通过,干干净净。
花了一个句号。
四、为什么一个句号能解决所有问题?
因为模型不是没学会,是学完了不知道什么时候该闭嘴。
训练数据里每条答案后面跟着 EOS(结束标记)。理论上模型应该学会在句号后输出 EOS。但实际上,模型生成完答案后,会继续"联想"其他答案的内容——因为它见过太多"句号后面还有更多文字"的模式。
加一个句号作为停止信号,等于告诉模型:"到这里就可以了,别往下想了。"
这个方法适用于所有单句回答的场景。不需要改训练数据,不需要改模型,只需要在推理时加一个字符。
五、你可能想问的几个问题
Q:为什么模型总是漂移到"纯水杂质极低"?
因为 BPE tokenizer 把"纯水杂质极低"这6个字压缩成了1个token。对模型来说,输出它只需要一次概率选择,信心特别高。当模型不确定"接下来该说什么"的时候,它就会选择这种高置信度的单token短语。
这也是为什么 BPE tokenizer 对中文模型有个隐形陷阱:常见短语被压缩成单个token,变成了模型不确定时的"默认输出"。
Q:你们改了模型架构,有帮助吗?
我们把基础 Transformer 升级成了 Llama 风格(GQA + SwiGLU)。有帮助,但帮助有限。真正决定输出质量的是数据设计和推理策略,不是架构。
Q:3M 模型能记住多少内容?
7个token以内的答案:完美记忆。15个token的答案:基本正确。18个token的行星列表:只能记住一半。
3M 模型连太阳系8颗行星都记不全——这直观回答了"为什么需要大模型"。
Q:过拟合了吗?
是的。而且这正是教学项目的目标。生产模型追求泛化,教学模型追求"你教什么它就输出什么"。过拟合 = 训练有效 = 闭环成立。
六、三个别人没告诉你的事
1. Loss 很低 ≠ 模型能用。 验收测试才是真正的质量标准。
2. 改数据的效果 > 改架构。 我们统一了 RoPE 的答案格式,一道题的正确率直接从 0% 拉到 100%。这比任何架构调整都有效。
3. 小模型的"容量边界"是真实存在的。 3M 模型能完美记住 4-7 个 token 的答案,但 18 个 token 的序列就开始力不从心。这个边界不是 bug——它直观展示了为什么参数规模很重要。
七、想自己试试?
git clone https://github.com/helloworldtang/GPT_teacher-3.37M-cn.git cd GPT_teacher-3.37M-cn uv venv && source .venv/bin/activate uv pip install -e . # 先体验预训练模型 uv run python -m src.evaluate # 自己训练 uv run python -m src.train # Web 演示 uv run python src/web_demo.py
模型只有 3.16M 参数,CPU 或 Mac 都能跑。训练完自动验收,你能亲眼看到模型从"说胡话"到"答对了"的过程。
不要只盯着 loss,问你的模型一个问题,看看它怎么回答。那才是真正的验收。
项目地址:https://github.com/helloworldtang/GPT_teacher-3.37M-cn
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号