打破认知:GPU Warp的“分工革命”——从SIMT到最优调度

打破认知:GPU Warp的“分工革命”——从SIMT到最优调度

GPUS Lady
发布于 2026-05-08 12:43:00
发布于 2026-05-08 12:43:00

提到GPU的并行计算,很多人都知道一个基础概念:GPU会将线程分成32个一组的“线程束”(warp)来执行。但今天我们要聊的,远不是这个入门知识点——而是一个更深入、更能体现GPU性能精髓的高级话题:线程束专业化(warp specialization),我会用最通俗的方式,把它的来龙去脉拆解开。
先从我们熟悉的基础逻辑说起:默认情况下,每一个线程束都会执行相同的代码,只是处理不同的数据——这就是GPU并行计算的核心模式,标准的SIMT(单指令多线程)架构。简单理解,就像一支整齐的仪仗队,所有人做着同样的动作,但各自对应不同的位置,高效完成统一任务,这也是GPU能快速处理海量数据的基础原理之一。
而线程束专业化,恰恰打破了“同一线程束执行相同代码”这个固有假设。它让不同的线程束承担完全不同的任务:有的线程束专门负责搬运数据,有的专门执行矩阵乘法(GEMM),它们之间通过共享内存(SMEM)传递信息,并且在需要的时候进行同步,就像工厂里不同的工序流水线,各司其职又紧密配合。
为什么要搞这种“分工”?核心原因只有一个:避免阻塞同步(blocking synchronization)带来的性能浪费。
在NVIDIA的Hopper(如H100 GPU)和Blackwell(如B200/GB300 GPU)两代架构中,有一个关键细节:当要使用矩阵乘法(GEMM)的计算结果时,必须执行一条显式的等待指令。这个等待指令会阻塞整个线程束——也就是说,这个线程束里的所有线程都会“暂停干活”,直到等待结束。如果我们把softmax(深度学习中常用的激活函数)也安排在同一个线程束里,那么在等待期间,softmax也无法执行,相当于GPU的算力被白白浪费了。
既然如此,解决方案就很直接:把softmax转移到另一个独立的线程束中。这样一来,一个线程束在等待矩阵乘法结果时,另一个线程束可以同时执行softmax,互不干扰,问题看似完美解决。
但凡事过犹不及——人们很快把这个逻辑推向了极端。此后,行业内形成了一种主流认知:一个线程束负责加载数据(加载线程束),一个线程束负责计算(计算线程束)。这种分工清晰、简单易懂,却隐藏着一个致命问题:它是错的。
近期,斯坦福大学和NVIDIA联合发表了一篇名为Twill的论文,彻底颠覆了这种简单化的分工认知。该论文提出了一种全新的方法,无需依赖经验判断,而是通过纯约束求解,自动为Flash Attention(一种高效的注意力机制算法)找到最优的线程束专业化调度方案。要知道,Flash Attention的核心优势就是解决大模型训练中的数据搬运瓶颈,而线程束的调度效率,直接决定了这种优势能否充分发挥。
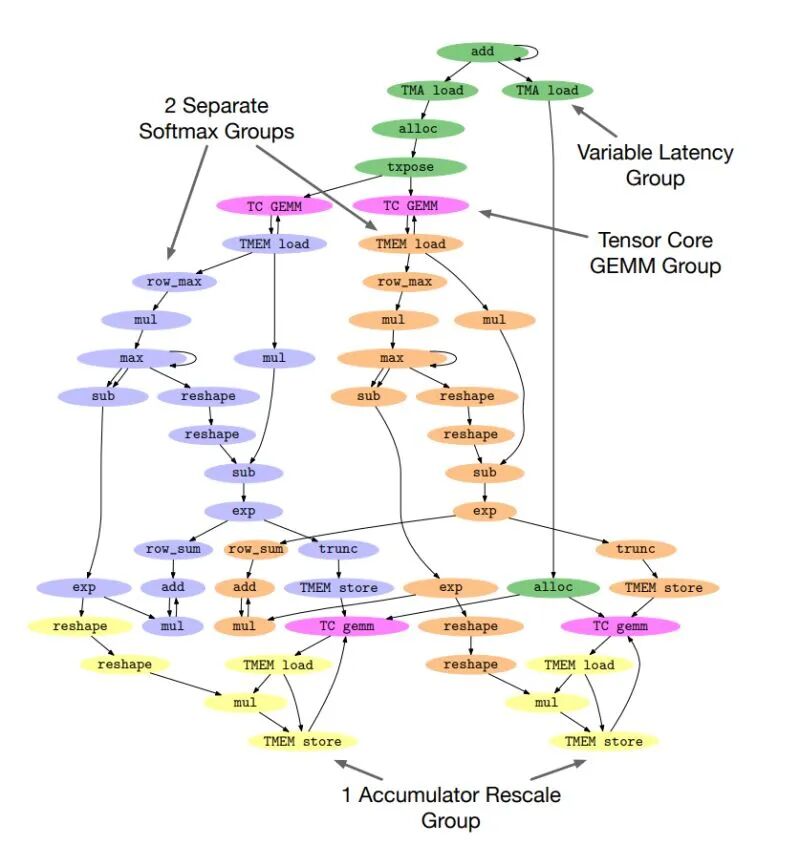
那么,针对Blackwell架构(专为大规模生成式AI优化的新一代GPU架构),最优的线程束调度到底长什么样?答案远比“加载+计算”的二分法复杂,它包含五个明确的分工角色:
- 第一组线程束:专门处理可变延迟操作(主要是TMA加载,即张量内存加速器加载,这是Hopper架构引入的高效数据搬运技术,能实现全局内存与共享内存之间的异步拷贝);
- 第二组线程束:负责TC GEMMs(第五代张量核心矩阵乘法,Blackwell架构的核心算力单元,支持4位/6位超低精度运算,大幅提升AI吞吐量);
- 第三组线程束:处理子瓦片0(sub-tile 0)的softmax运算;
- 第四组线程束:处理子瓦片1(sub-tile 1)的softmax运算;
- 第五组线程束:负责累加器重缩放(accumulator rescaling)。
没错,是五个角色,而非简单的两个。其中,累加器重缩放之所以要单独分配一组线程束,核心原因和之前的softmax类似:从张量内存(Tensor Memory)中读取累加器数据时,会产生阻塞同步。如果把这项操作和softmax放在同一个线程束里,会导致整个计算流水线停滞,因此必须为它单独分配线程束,并通过显式的跨线程束通信实现协同。
更关键的是,这种五分工的调度方案,并非靠工程师的直觉设计出来的——它是唯一能同时满足三个核心约束的分配方式:寄存器压力(避免寄存器不足导致的性能瓶颈)、阻塞同步(减少等待浪费)、跨线程束通信(保证各分工协同高效)。
这背后,还藏着一个更深层的认知升级:线程束的角色分配,从来都不是一个“可随意选择的设计决策”,而是软件流水线运行的必然结果。我们不能先确定线程束的分工,再围绕它搭建整个计算流水线;恰恰相反,线程束的分工,必须由软件流水线的需求、硬件的约束(如Blackwell的架构特性)来决定。
从“所有线程束做同样的事”,到“不同线程束做不同的事”,再到“用算法找到最优分工”,线程束调度的进化,本质上是GPU性能不断挖掘的过程。尤其是在Blackwell架构主导的大规模AI时代,这种精细化的线程束专业化调度,正是让GPU算力充分释放、支撑大模型高效训练与推理的关键之一——毕竟,在AI算力竞争日趋激烈的今天,每一分算力的浪费,都可能成为技术突破的绊脚石。
更多细节可以参考这篇论文:https://arxiv.org/pdf/2512.18134
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号