大模型硬件集成的实现原理:把AI模型刻进芯片是怎么做到的?

大模型硬件集成的实现原理:把AI模型刻进芯片是怎么做到的?

chouheiwa
发布于 2026-05-06 21:39:45
发布于 2026-05-06 21:39:45
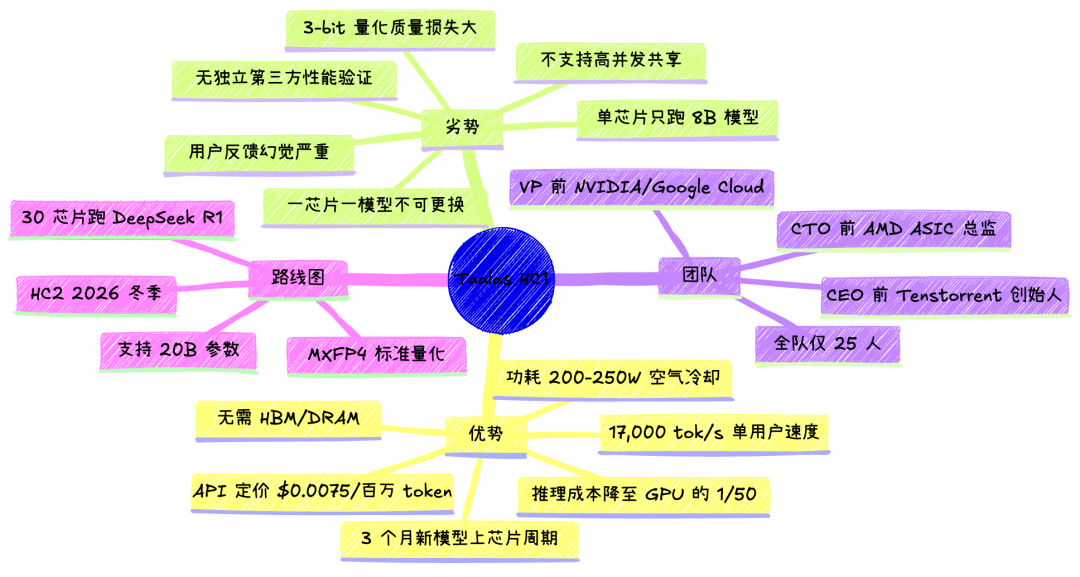
我每天用 Claude Code 写代码,一天下来 API 费用就是几十块钱。前段时间从 Claude Max 切到 opencode 省钱,又研究了一圈 AnyRouter、NVIDIA NIM 做模型路由,核心焦虑就一个字:贵。推理成本是 AI 落地的最大瓶颈,这个判断在 2026 年已经是行业共识了。但你猜怎么着,有一家 25 个人的加拿大初创公司,用了一种几乎所有芯片工程师看了都会摇头的方式,把推理成本干到了 GPU 方案的 1/50。
这家公司叫 Taalas,它干的事情用一句话概括就是:把大模型的权重参数,在芯片制造阶段,直接刻进晶体管里。不是加载到显存里,不是放在 HBM 里,是物理蚀刻到硅片上,跟芯片一起从台积电产线出来的时候,模型就已经"长"在里面了。出厂即推理,通电即运行,每秒吐 17,000 个 token。
钛媒体给这个路线起了个绰号叫邪修,中科院的研究员赵永威评价说目前没有应用价值,但可能是一颗有历史意义的芯片。说白了,这就是 AI 芯片界的行为艺术:它可能是天才之作,也可能是昂贵的一次性实验。但不管怎样,理解它怎么做到的,对软件开发者来说是一次很好的硬件认知升级。
我是做 iOS 开发的,本科化工专业出身,对硬件的理解基本停留在"知道 CPU 有缓存、GPU 并行快"这个水平。但化工给我留下一个很有用的思维工具:控制变量法。分析 Taalas 这种看起来很玄的技术,最好的办法就是一层一层拆,每次只看一个变量。
▶先搞清楚一件事:GPU 跑大模型,瓶颈到底在哪
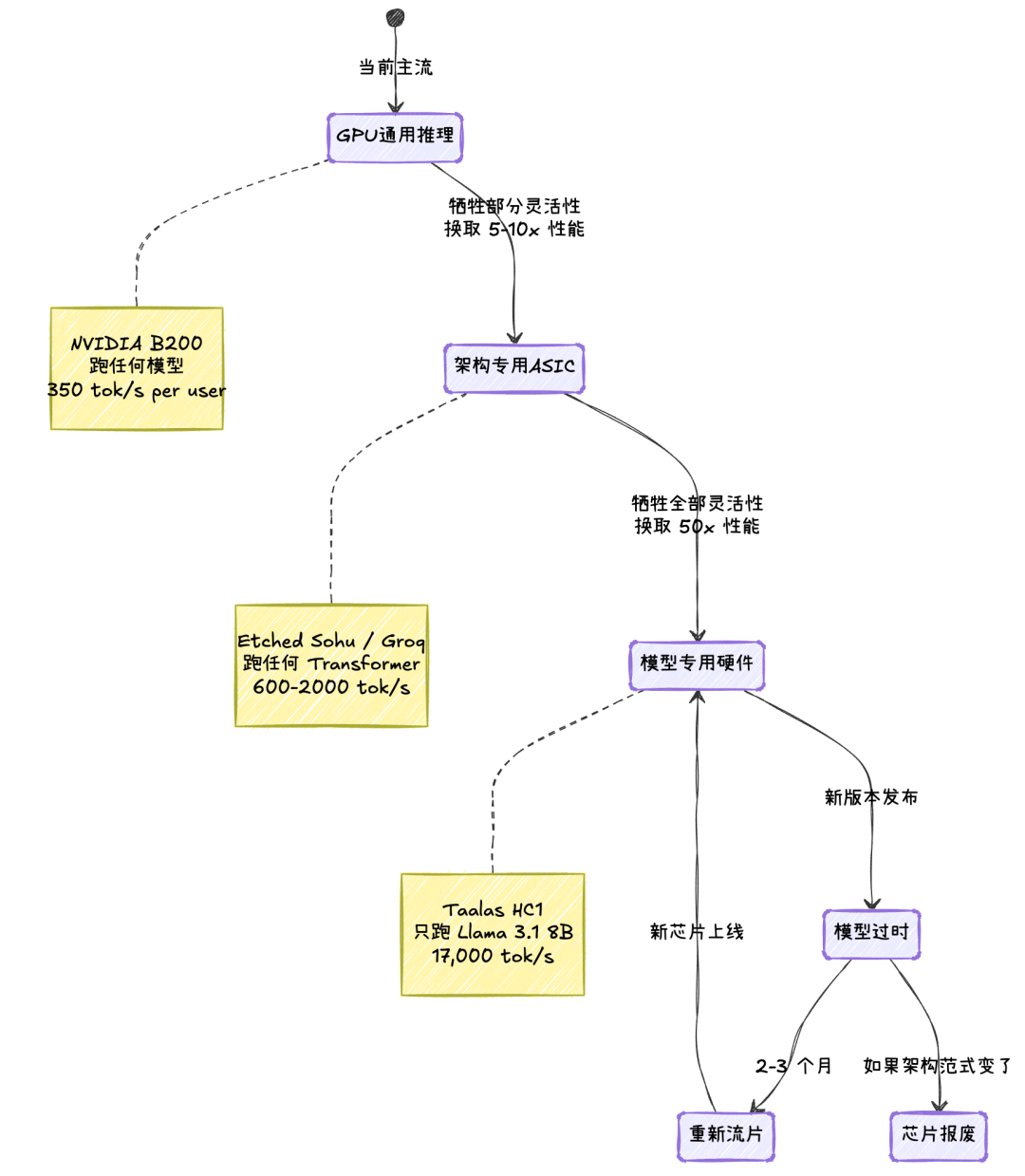
要理解 Taalas 为什么要把模型刻进芯片,得先搞清楚传统 GPU 推理的瓶颈在哪。我用 Claude Code 跑代码的时候,后端大概率是 NVIDIA 的 H100 或 B200 在干活。这些卡的算力其实是过剩的,真正卡脖子的是内存带宽。
一个 Llama 3.1 8B 模型,FP16 精度下权重大约 16GB。每生成一个 token,GPU 需要把这 16GB 的权重从 HBM 显存读一遍,送到计算单元做矩阵乘法,算完再写回去。B200 的 HBM3e 带宽是 8 TB/s,听起来很猛,但 16GB 的权重读一次就要 2 毫秒,而计算本身只需要零点几毫秒。说白了,GPU 大部分时间不是在算,是在等数据搬运。
这就是所谓的内存墙(Memory Wall),也是 2025-2026 年所有 AI 芯片创业公司瞄准的核心问题。Groq 的 LPU 把权重全放 SRAM 里消除内存墙,Cerebras 搞了一整片晶圆大小的芯片塞了 44GB SRAM,Etched 把 Transformer 架构硬编码进 ASIC 减少调度开销。每家的思路都不一样,但目标一样:让数据离计算单元更近,或者干脆不搬数据。
Taalas 把这个逻辑推到了极限:既然搬数据是瓶颈,那我干脆不搬了。把数据变成电路的一部分,数据就是芯片,芯片就是数据。
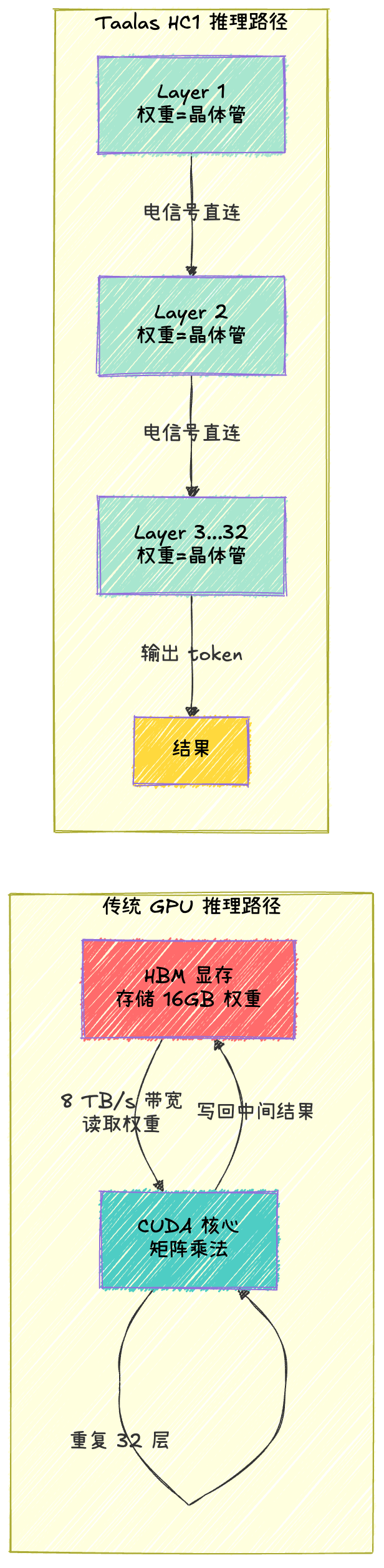
上面这张图是理解 Taalas 的关键。左边是传统 GPU,数据在显存和计算单元之间反复搬运;右边是 HC1,数据作为电信号直接从第一层流到第三十二层,中间没有任何内存访问。这就是为什么它能快 50 倍。
▶Taalas 到底怎么把模型"刻"进芯片的
好了,概念搞清楚了。接下来拆解具体实现,这部分是这个回答的核心。我尽量用软件开发者能理解的类比来说。
Taalas 的核心技术叫 HCI(Hard Coded Inference),官方博客用了三个关键词:Mask ROM Recall Fabric、Single-Transistor Multiply、Structured ASIC。分别对应三层问题:权重怎么存、乘法怎么做、新模型怎么换。
第一层:权重存储用 Mask ROM
Mask ROM 是最古老、最原始的只读存储器。它的原理简单到离谱:在芯片制造时,通过光刻掩膜决定某个位置有没有通孔连接,有连接就是 1,没连接就是 0。数据在制造那一刻就写死了,后续不可修改。你家里的老式游戏卡带、计算器芯片里都用过这玩意。
Taalas 用 Mask ROM 存储模型权重的好处是密度极高。因为不需要像 SRAM 那样每个 bit 用 6 个晶体管,也不需要像 DRAM 那样配电容和刷新电路,Mask ROM 每个 bit 只需要一个晶体管的位置。这就是为什么 HC1 能在 815mm² 的面积上塞进 530 亿个晶体管来编码 Llama 3.1 8B 的全部参数。Taalas 还申请了一个 WIPO 专利(WO/2025/217724),标题就叫 Mask Programmable ROM Using Shared Connections,专门优化了 ROM 的布线密度。
第二层:单晶体管同时存数据和做乘法
这是 Taalas 最核心也最神秘的技术点。CEO Bajic 在 EE Times 采访中确认,HC1 里每个权重单元用一个晶体管同时存储 4 bit 数据并完成对应的乘法运算。他强调这是纯数字电路实现,不是模拟计算。具体怎么做到的他没公开细节,原话是这不是什么核物理难题,只是一个巧妙的电路技巧。
用软件开发者能理解的方式说:传统推理是"先从内存读权重 w,再读输入 x,然后 ALU 算 w×x"。Taalas 的方式是"晶体管本身的物理连接方式就编码了 w 的值,当输入信号 x 流过这个晶体管时,输出信号就已经是 w×x 了"。说白了,存储即计算,硬件即软件。
第三层:Structured ASIC 解决换模型问题
很多人第一反应是:模型刻死了,新版本出来这芯片不就废了?Taalas 用 Structured ASIC 方法论缓解了这个问题。HC1 的芯片底层是一大片通用的逻辑门和晶体管阵列,大约 100 多层金属布线中,只有最上面两层是模型特定的。这两层编码了权重数据和数据流路由。
换模型的时候,不需要重新设计整颗芯片,只需要重新生成这两层掩膜。台积电的 N6 工艺可以在大约 2 个月内完成这两层掩膜的制造,而不是全定制芯片的 6 个月以上。Taalas 内部有一个类似编译器的工具链,输入模型权重文件,大约一周就能输出芯片版图。从模型发布到芯片量产,整个周期可以压到 3 个月左右。
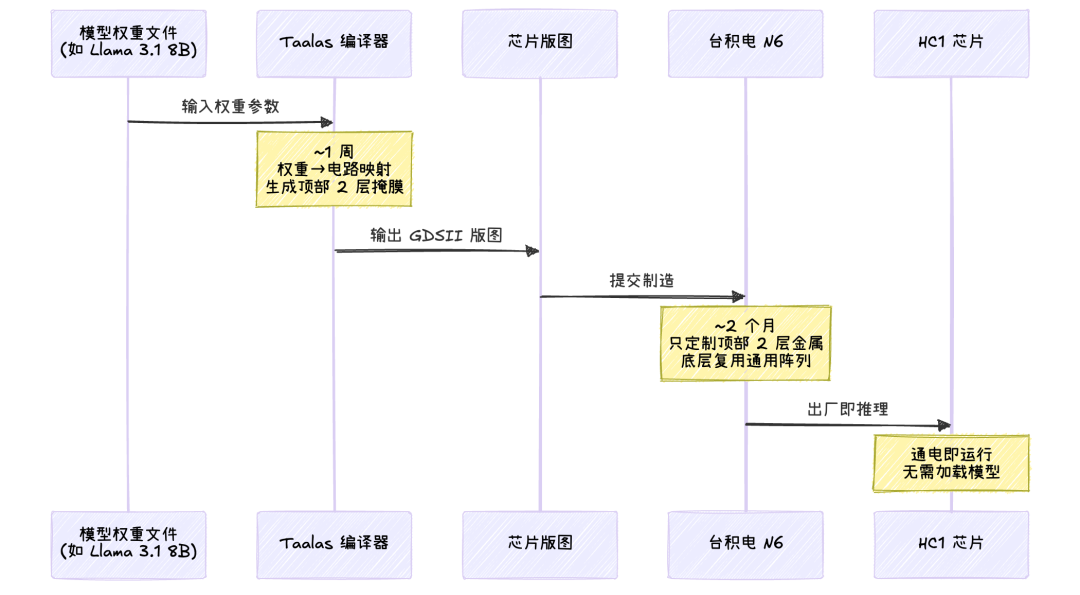
其实吧,这个"只改两层"的方案在芯片行业不算全新概念。早年 Altera 和 eASIC 做过类似的结构化 ASIC,区别是它们改的是逻辑功能,Taalas 改的是数据内容。思路是一脉相承的:用制造灵活性换运行效率。
▶17,000 tok/s 的真实含义和水分在哪
数字很震撼,但做软件的人都知道,benchmark 这东西最怕的就是不控制变量。我化工出身最在意这个,所以逐条拆一下。
HC1 跑 Llama 3.1 8B 的 17,000 tok/s 是单用户、1K 输入 / 1K 输出条件下的数据。作为对比,Cerebras 的晶圆级引擎跑同一个模型大约 1,936 tok/s,SambaNova 约 916 tok/s,Groq 的 LPU 约 609 tok/s,NVIDIA B200 约 350 tok/s。倍数差距确实大。
但这里面有几个关键变量没控制住:
精度不同。 HC1 用的是 Taalas 自研的 3-bit 底层格式 + 6-bit 参数混合量化。而 GPU 跑 benchmark 通常用 FP16 或 INT8。3-bit 量化意味着模型质量会显著下降。德国科技媒体 heise online 独立测试确认速度确实在 15,000-16,000 tok/s,但用户在 chatjimmy.ai 上实际体验后反馈说幻觉严重、回答质量明显低于 GPU 版本的同参数模型。
模型大小不同。 8B 参数在 2026 年只算入门级模型。真正的生产力场景用的是 70B、405B 甚至更大的模型。Taalas 目前只能在单芯片上跑 8B。他们模拟了 DeepSeek R1(671B 参数)的方案,需要约 30 颗 HC 芯片协同工作,预计 12,000 tok/s,但这只是仿真数据。
并发场景缺失。 17,000 tok/s 是单用户独占一颗芯片的数据。GPU 的优势恰恰在高并发:B200 在大 batch size 下能跑到约 60,000 tok/s per GPU,只不过这个吞吐是分摊给上百个并发用户的。Taalas 的芯片架构决定了它天然是 1 芯片 = 1 用户的模型,想服务更多用户就得线性堆芯片。
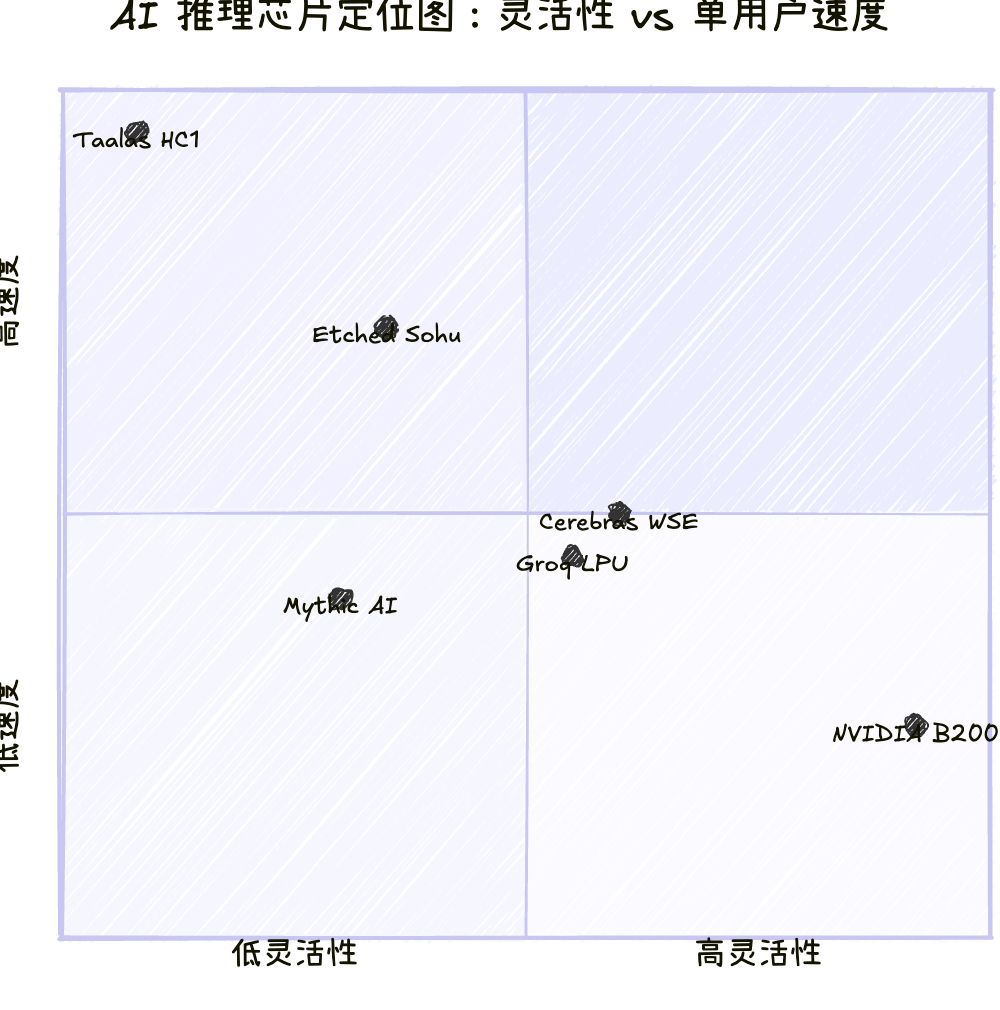
说白了,Taalas 把灵活性 slider 拉到了最左边、速度 slider 拉到了最右边。这是一个极端的 trade-off,适不适合你取决于你的场景容不容得下这种极端。
▶那个绕不开的问题:模型更新了,芯片怎么办
这是所有人看到 Taalas 第一个想到的问题,也是中文科技圈讨论最激烈的焦点。模型刻死在芯片里,Meta 发了 Llama 4 怎么办?你这芯片就变成一块精美的硅片收藏品了?
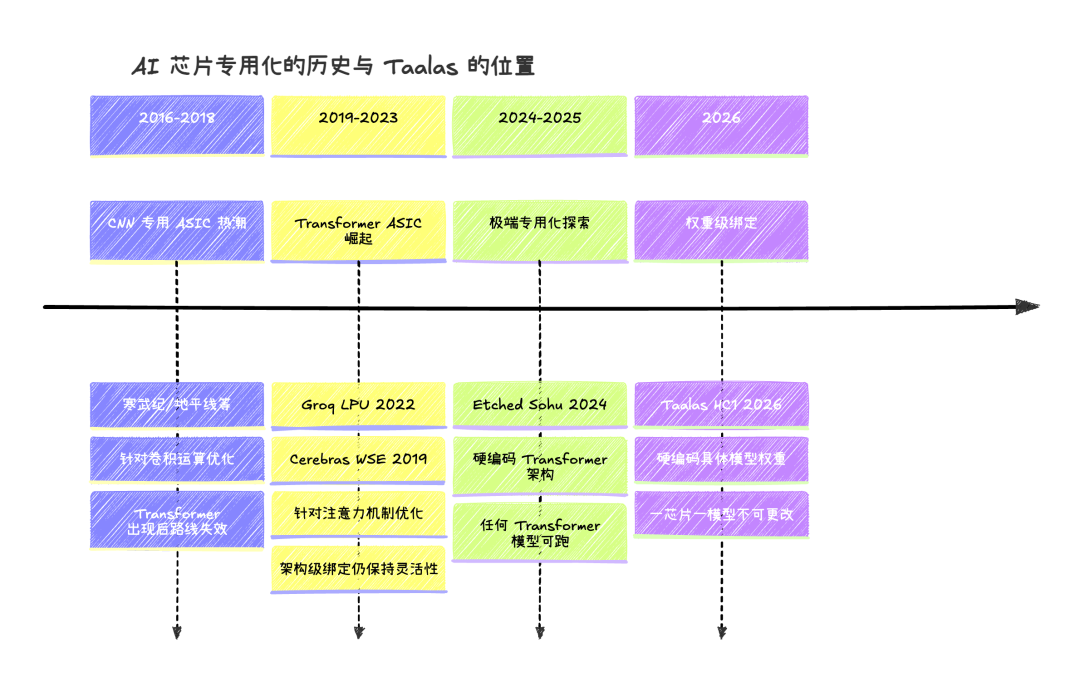
36 氪的深度分析提了一个很好的历史类比:2016-2018 年那波 CNN 专用 AI 芯片热潮。当时国内好几家公司(寒武纪最典型)做了针对卷积神经网络优化的 ASIC,结果 Transformer 架构一出来,整个 CNN 加速器路线就凉了。Taalas 比那些公司走得更极端,人家好歹是架构级别的绑定,Taalas 是权重级别的绑定。
但 Taalas 团队的反驳也有道理。CEO Bajic 的论点是这样的:如果推理成本降到 GPU 的 1/50,那每年换一批芯片的总成本,依然远低于 GPU 的运行成本。他的 Structured ASIC 方案让新模型从发布到芯片量产只要 3 个月。而且很多企业场景,比如客服机器人、文档处理、嵌入式设备,完全可以锁定一个模型版本跑一两年。
HC1 的 SRAM 层还支持 LoRA 适配器,也就是说基础权重虽然刻死了,但可以通过小参数量的微调来适应不同下游任务。这有点像你手机的 ROM 系统不能换,但 APP 可以随便装。对于垂直场景来说,这个灵活度可能够用了。
其实吧,CNN 专用芯片凉掉,"专用化"本身不背锅。真正的问题是整个计算范式变了。从 CNN 到 Transformer,底层计算模式从卷积变成了注意力机制,硬件加速的基础假设全部失效。而当前 Transformer 架构已经统治了 5 年以上,LLM 的迭代更多是在参数规模、训练方法、对齐技术上,底层的矩阵乘法 + 注意力计算范式并没有变。Taalas 赌的就是这一点:Transformer 会继续统治足够长的时间,让它的芯片在报废之前收回成本。
▶25 个人、3000 万美元、530 亿晶体管
Taalas 的团队背景值得单独说一下,因为它解释了为什么这种看起来疯狂的方案能做出来。
创始人 Ljubisa Bajic 是 Tenstorrent 的联合创始人,2016 年创立了 Tenstorrent 并担任 CEO,直到 2022 年底 Jim Keller 接手后离开。他在 AMD、NVIDIA 做了 20 多年 ASIC 和 GPU 架构设计。CTO Drago Ignjatovic 是 AMD 的 ASIC 设计总监出身,后来在 Tenstorrent 任硬件工程 VP。产品 VP Paresh Kharya 之前在 NVIDIA 数据中心业务做高级总监,再之前在 Google Cloud 负责 GPU 和 TPU 基础设施。
这帮人是真正在 NVIDIA 和 AMD 内部做过顶级芯片的人,不是 PPT 创业。整个团队只有 25 人,2023 年 8 月成立,HC1 在 2024 年 Q3 完成 tape-out(流片),2026 年 2 月 19 日正式亮相。总共花了 3000 万美元研发费用。作为对比,一颗同等规模的全定制 ASIC 通常需要几亿美元和几年时间。Structured ASIC 方法论是压低成本的关键。

融资方面,三轮合计 2.19 亿美元:2023 年 9 月种子轮 1200 万,2024 年初追加 3800 万,2026 年 2 月 Quiet Capital、Fidelity 领投的 1.69 亿。投资人里有半导体行业传奇投资人 Pierre Lamond。
他们的下一代芯片 HC2 计划 2026 年冬季推出,工艺升级后单芯片支持 200 亿参数,量化格式从自研的 3/6-bit 切换到标准的 MXFP4(4-bit 浮点),预计模型质量会有显著提升。
▶对软件开发者来说,这意味着什么
作为每天用 AI 工具写代码的人,我对 Taalas 的关注点不在它现在能不能用,而在它指向的趋势。
2026 年有一个明确的行业转折点:推理支出超过训练支出。ASIC 在 AI 推理中的份额预计从 2024 年的 15% 增长到 2026 年的 40%。NVIDIA 2025 年底以 200 亿美元收购 Groq,Etched 以 50 亿美元估值融了 5 亿美元,Cerebras 在 2025 年尝试 IPO。整个行业都在朝"推理专用硬件"方向跑,Taalas 只是跑到了最极端的位置。
对写代码的人来说,核心判断是这样的:如果推理成本在未来两年内真的降一到两个数量级,那 AI 在软件里的用法会发生根本变化。现在我用 Claude Code 还得想着怎么省 token,prompt 写得精简再精简。如果 token 不要钱了呢?如果每个用户请求背后都有一颗专属芯片在跑推理呢?
Taalas 自己做的 DeepSeek R1 仿真给出了一个想象空间:671B 参数的推理模型,30 颗芯片协同,12,000 tok/s,每百万 token 7.6 美分。如果这个数字是真的,那 AI Agent 7×24 小时运行的成本就从"只有大厂用得起"变成了"创业公司也可以用"。
但我必须说,从一个经历过太多技术 hype cycle 的开发者视角来看,现在断言 Taalas 能成功为时尚早。他们的路线图要求在 2026 年内完成四次 tape-out(中等推理模型春季、20B Llama 夏季、HC2 冬季),这对一个 25 人的团队来说是极其激进的。而且他们到现在还没有公开任何独立第三方的完整性能验证,官方 demo 的质量反馈也不乐观。
▶回到这个问题本身
题主问的是"将大模型直接写入硬件是怎么实现的",核心答案就三句话:
第一,权重变电路。 用 Mask ROM 技术,在芯片制造时把每个权重参数编码为晶体管的物理连接状态,一个晶体管存 4 bit 数据并同时完成乘法运算。
第二,推理变物理。 把 Transformer 的 32 层顺序排列在硅片上,输入数据作为电信号从第一层流到最后一层,全程不经过任何内存总线,数据流就是电流流。
第三,迭代变制造。 通过 Structured ASIC 方法,只定制顶部两层金属掩膜来编码不同模型,底层芯片结构复用。新模型从权重文件到芯片量产约 3 个月。
最后说一个我自己的判断。我是化工转软件的人,"某某技术将颠覆某某行业"这种故事听多了,免疫力比较强。化工里也有类似的东西,比如把催化剂配方直接烧结到反应器管壁上,让催化剂成为反应器的一部分而不是填充物。这在特定反应里效率确实高很多,但通用性很差。Taalas 干的事情本质上是一样的:把"软件"变成"硬件",用灵活性换极致效率。
这条路能走多远,取决于一个核心变量:大模型的迭代速度会不会慢下来。如果 Llama 5 发布后能管用两三年,那 Taalas 的经济账就算得过来。如果模型每隔三个月就有质的飞跃,那刻在芯片里的权重就是在跟时间赛跑。
但不管 Taalas 这家公司最后成不成,它证明了一件事:AI 推理的物理极限,远没有被当前的 GPU 架构触及。内存墙不是不可逾越的,只要你愿意付出足够极端的代价。这个认知本身,对所有做 AI 基础设施的人都有价值。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号