从能写代码到能写工程:GLM-5 的 Agent 能力到底强在哪

从能写代码到能写工程:GLM-5 的 Agent 能力到底强在哪

程序员NEO
发布于 2026-04-29 19:36:39
发布于 2026-04-29 19:36:39
跑分归跑分,能不能真用起来,是两码事。
说实话我之前也是这个心态。团队里 Agent 相关的项目跑的是 Claude,偶尔拿国产模型试试水,效果嘛……对于简单对话还行,一到长程任务和复杂工具调用,稳定性就拉胯。
但这次 GLM-5 出来之后,我花了差不多一周时间认真跑了一轮。
结论先放前面:这是我第一次在真实项目里觉得,某些场景下国产模型可以替代 Claude 了。
下面聊聊我到底看到了什么,踩了哪些坑,以及怎么迁移的。
先说硬参数,GLM-5 的底子到底怎么样
在聊体感之前,得先把关键规格摆出来,不然容易变成"感觉很好"的玄学评测。
GLM-5 的核心参数:
- • 总参数量:744B(激活 40B)—— 对比上一代 GLM-4 系列的 355B(激活 32B),直接翻倍
- • 预训练数据:28.5T tokens
- • 上下文窗口:200K
- • 最大输出:128K tokens
- • 输入/输出模态:文本 → 文本

几个值得展开说的技术细节:
1. 异步强化学习框架 "Slime"
这个名字挺逗的,但做的事情不简单。传统的 RLHF 在大参数量模型上效率会很差,Slime 框架做的是异步智能体强化学习——让模型能从长程交互中持续学习。
我理解这就是 GLM-5 Agent 能力变强的核心原因之一。不是简单加数据、加参数,而是训练范式变了。
2. DeepSeek Sparse Attention
GLM-5 首次集成了稀疏注意力机制。这个对实际部署很关键——200K 的上下文窗口如果用 Full Attention,推理成本会爆炸。Sparse Attention 能在保持长文本效果的前提下大幅降本。
说白了,长文本能力是真的有,不是"理论支持 200K 但实际用不了"那种。
3. 对齐 Claude Opus 4.5 的编程能力
官方给的数据:
- • SWE-bench-Verified:77.8(开源最高)
- • Terminal Bench 2.0:56.2(开源最高)
- • 超过 Gemini 3.0 Pro
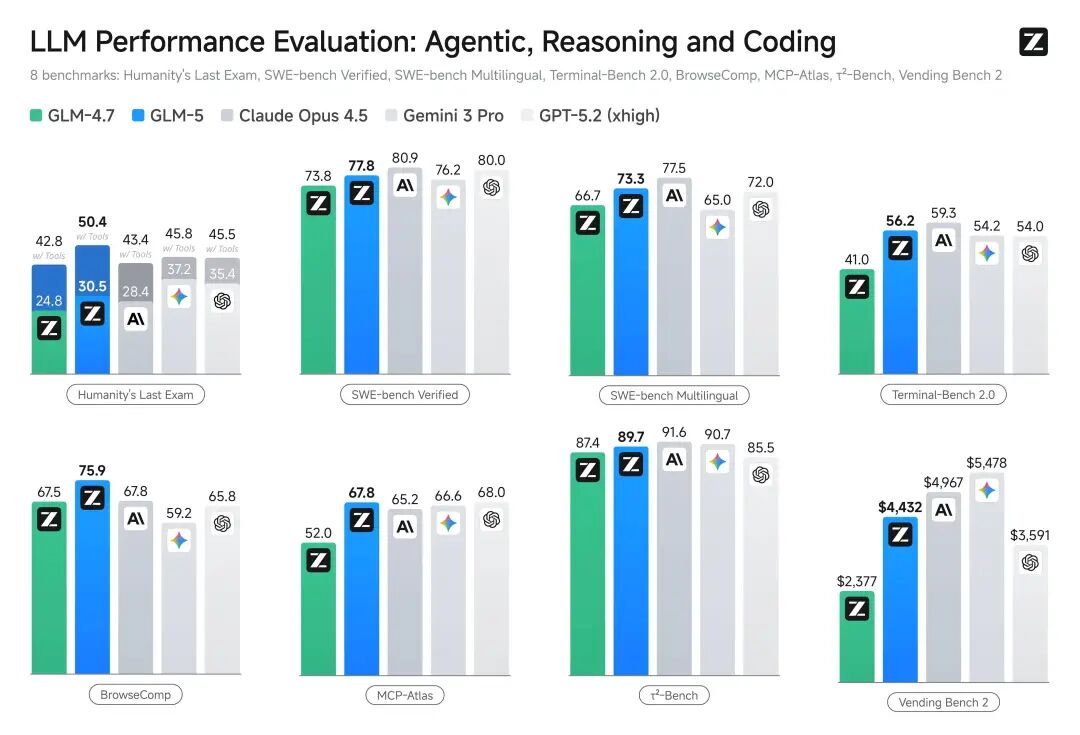
GLM-5 编程能力评测
GLM-5 编程能力评测
这里得说句公道话:跑分超过不代表所有场景都能打。但在内部的 Claude Code 评估集合里,GLM-5 在前后端、长程任务上确实显著超过了 GLM-4.7,逼近 Opus 4.5 的使用体感。

GLM-5 vs GLM-4.7 对比
GLM-5 vs GLM-4.7 对比
Agent 能力才是我最关注的
说实话,单纯的代码生成能力大家差距在缩小。真正拉开差距的是 Agent 场景下的长程任务执行能力。
为什么这么说?
因为在我们的实际项目里,Agent 要做的事情不是"回答一个问题",而是:
- • 理解一个模糊目标
- • 自己拆解成多个子任务
- • 调用不同的工具去执行
- • 中间出错了要能自检和恢复
- • 整个过程可能持续几十轮交互
这种场景下,模型的目标一致性、资源管理能力、多步骤依赖处理才是核心。
GLM-5 在这块的评测数据:
- • BrowseComp(联网检索与信息理解):开源第一
- • MCP-Atlas(工具调用和多步骤任务执行):开源第一
- • τ²-Bench(复杂多工具场景下的规划和执行):开源第一
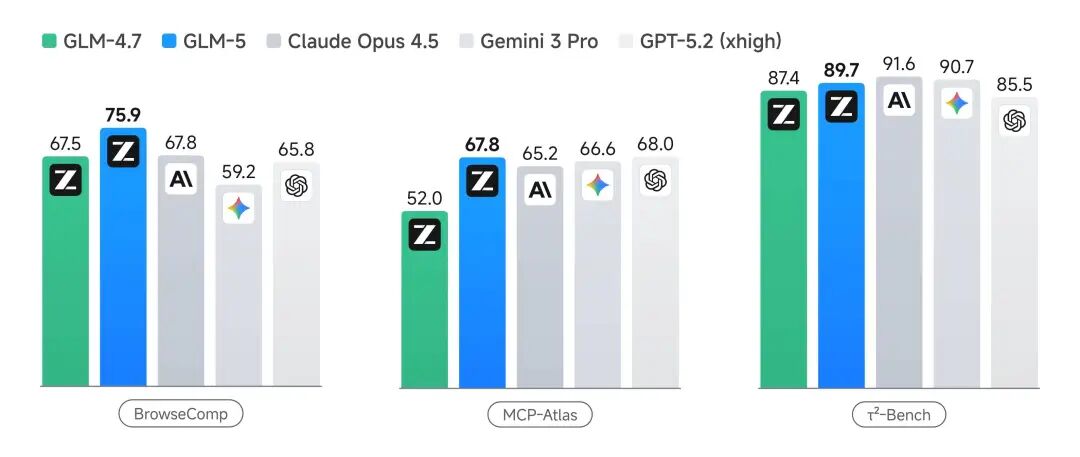
GLM-5 Agent 能力评测
GLM-5 Agent 能力评测
三个 Agent 评测基准全部开源最高,这个确实有点东西。
我自己实际体验下来,最明显的感受是 GLM-5 在长程任务里"不容易跑偏"了。之前用 GLM-4.7 做复杂 Agent 任务,经常到第 15-20 步就开始"忘了自己在干啥",GLM-5 这个问题改善很大。
实战迁移:从 GLM-4.x 升级到 GLM-5
OK,参数和评测聊完了,接下来是最实际的部分——你的项目怎么迁移过来?
我自己迁移的过程踩了几个坑,这里按顺序说清楚。
第一步:改 model 字段
这步最简单,把 model 从 glm-4 / glm-4.5 / glm-4.7 改成 glm-5 就行:
resp = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": "简述 GLM-5 的优势"}]
)但别急着以为这就完了。
第二步:采样参数得重新调
这里是我踩的第一个坑。
GLM-5 的默认参数跟之前的版本不一样:
- •
temperature默认值变成了 1.0 - •
top_p默认值是 0.95
如果你之前在 GLM-4 上精心调过参数,直接迁移过来输出风格可能会变。
我的建议:
- • 只调一个,别同时改
temperature和top_p - • 需要创意输出 → 调
temperature(推荐) - • 需要稳定输出 → 调
top_p
# 方案 A:用 temperature 控制(推荐)
resp = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": "写一段更具创意的品牌介绍"}],
temperature=1.0
)
# 方案 B:用 top_p 控制
resp = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": "生成更稳定的技术说明"}],
top_p=0.8
)第三步:深度思考模式,建议按场景开
GLM-5 延续了 GLM-4.7 的深度思考能力,但默认是开启状态。
这个要注意——开启深度思考 = 更长的推理时间 + 更高的 token 消耗。
对于简单问答场景,其实没必要开。我们项目里的做法是:
- • 复杂推理 / 代码生成 / 架构设计 → 开
- • 简单对话 / 信息抽取 → 关
resp = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": "为我设计一个三层微服务架构"}],
thinking={"type": "enabled"}
)第四步:流式工具调用(这是 GLM-5 的新能力)
这里是我踩的第二个坑,也是最大的一个。
GLM-5 新增了 tool_stream 参数,可以在工具调用的过程中实时流式输出参数,而不是等整个 function call 完成后再一次性返回。
这个能力很实用,特别是在 Agent 场景下——用户可以实时看到模型正在调用什么工具、传了什么参数。
但坑在哪?
你得同时开启 stream=True 和 tool_stream=True,缺一个都不行。 而且流式返回的工具调用参数是分片的,你需要自己拼接。
完整示例:
response = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": "北京天气怎么样"}],
tools=[
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定地点当前的天气情况",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "城市,例如:北京、上海"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
],
stream=True,
tool_stream=True,
)
# 初始化流式收集变量
reasoning_content = ""
content = ""
final_tool_calls = {}
reasoning_started = False
content_started = False
# 处理流式响应
for chunk in response:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
# 流式推理过程输出
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
if not reasoning_started and delta.reasoning_content.strip():
print("\n🧠 思考过程:")
reasoning_started = True
reasoning_content += delta.reasoning_content
print(delta.reasoning_content, end="", flush=True)
# 流式回答内容输出
if hasattr(delta, 'content') and delta.content:
if not content_started and delta.content.strip():
print("\n\n💬 回答内容:")
content_started = True
content += delta.content
print(delta.content, end="", flush=True)
# 流式工具调用信息(参数拼接)
if delta.tool_calls:
for tool_call in delta.tool_calls:
idx = tool_call.index
if idx not in final_tool_calls:
final_tool_calls[idx] = tool_call
final_tool_calls[idx].function.arguments = tool_call.function.arguments
else:
final_tool_calls[idx].function.arguments += tool_call.function.arguments
# 输出最终的工具调用信息
if final_tool_calls:
print("\n📋 命中 Function Calls :")
for idx, tool_call in final_tool_calls.items():
print(f" {idx}: 函数名: {tool_call.function.name}, 参数: {tool_call.function.arguments}")这段代码里最关键的逻辑是 delta.tool_calls 的参数拼接——每次流式返回的 arguments 只是一个片段,你必须按 index 把它们拼起来,最后才能得到完整的 JSON 参数。
第五步:上线前的回归测试 Checklist
迁移不是改完代码就完事。我整理了一个自查清单,建议你对照着过一遍:
- •
model字段 → 改为glm-5 - • 采样参数 →
temperature默认 1.0,top_p默认 0.95,只调一个 - • 深度思考 → 按场景决定开关
- • 流式响应 → 正确处理
delta.reasoning_content和delta.content - • 流式工具调用 → 同时开启
stream+tool_stream,参数分片拼接 - •
max_tokens→ GLM-5 最大支持 128K 输出 - • Prompt → 配合深度思考,指令要更明确
- • 回归测试 → 关注随机性变化、延迟、工具调用参数完整性
SDK 调用速查
迁移过程中你可能需要快速查代码,这里按语言整理了最常用的调用方式。
Python(新版 SDK)
安装:
pip install zai-sdk
# 或指定版本
pip install zai-sdk==0.2.2基础调用:
from zai import ZhipuAiClient
client = ZhipuAiClient(api_key="your-api-key")
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的口号"},
{"role": "assistant", "content": "当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱AI开放平台"}
],
thinking={
"type": "enabled",
},
max_tokens=65536,
temperature=1.0
)
print(response.choices[0].message)流式调用:
from zai import ZhipuAiClient
client = ZhipuAiClient(api_key="your-api-key")
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的口号"},
{"role": "assistant", "content": "当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱AI开放平台"}
],
thinking={
"type": "enabled",
},
stream=True,
max_tokens=65536,
temperature=1.0
)
for chunk in response:
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end='', flush=True)
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end='', flush=True)Python(旧版 SDK)
如果你还在用旧版 zhipuai 包,先升级到 2.1.5.20250726:
pip install zhipuai==2.1.5.20250726用法基本一致,就是 import 不同:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="your-api-key")
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "智谱AI开放平台"},
],
thinking={"type": "enabled"},
max_tokens=65536,
temperature=1.0
)
print(response.choices[0].message)建议尽早迁移到新版 zai-sdk,旧版后续可能不会更新新特性的支持。
Java(Maven)
<dependency>
<groupId>ai.z.openapi</groupId>
<artifactId>zai-sdk</artifactId>
<version>0.3.3</version>
</dependency>基础调用:
import ai.z.openapi.ZhipuAiClient;
import ai.z.openapi.service.model.ChatCompletionCreateParams;
import ai.z.openapi.service.model.ChatCompletionResponse;
import ai.z.openapi.service.model.ChatMessage;
import ai.z.openapi.service.model.ChatMessageRole;
import ai.z.openapi.service.model.ChatThinking;
import java.util.Arrays;
public class BasicChat {
public static void main(String[] args) {
ZhipuAiClient client = ZhipuAiClient.builder().ofZHIPU()
.apiKey("your-api-key")
.build();
ChatCompletionCreateParams request = ChatCompletionCreateParams.builder()
.model("glm-5")
.messages(Arrays.asList(
ChatMessage.builder()
.role(ChatMessageRole.USER.value())
.content("作为一名营销专家,请为我的产品创作一个吸引人的口号")
.build(),
ChatMessage.builder()
.role(ChatMessageRole.ASSISTANT.value())
.content("当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息")
.build(),
ChatMessage.builder()
.role(ChatMessageRole.USER.value())
.content("智谱AI开放平台")
.build()
))
.thinking(ChatThinking.builder().type("enabled").build())
.maxTokens(65536)
.temperature(1.0f)
.build();
ChatCompletionResponse response = client.chat().createChatCompletion(request);
if (response.isSuccess()) {
Object reply = response.getData().getChoices().get(0).getMessage();
System.out.println("AI 回复: " + reply);
} else {
System.err.println("错误: " + response.getMsg());
}
}
}cURL
curl -X POST "https://open.bigmodel.cn/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-5",
"messages": [
{
"role": "user",
"content": "作为一名营销专家,请为我的产品创作一个吸引人的口号"
},
{
"role": "assistant",
"content": "当然,要创作一个吸引人的口号,请告诉我一些关于您产品的信息"
},
{
"role": "user",
"content": "智谱AI 开放平台"
}
],
"thinking": {
"type": "enabled"
},
"max_tokens": 65536,
"temperature": 1.0
}'补一个大家问得最多的问题:GLM Coding Plan 支持 GLM-5 了吗?
结论:Max 和 Pro 套餐已经支持 GLM-5 了。 Lite 暂时还不行,官方说等新老模型资源迭代完成后会跟上。
不过有一点要注意——现阶段调用 GLM-5 会比历史模型消耗更多的套餐额度。这个可以理解,毕竟 744B 的推理成本摆在那里。所有套餐仍然支持 GLM-4.7 和更早的文本模型,所以不是说升级了就只能用 GLM-5。
如果你在用 Claude Code 接入 GLM,这里有个关键信息——环境变量和 GLM 模型的默认对应关系:
Claude Code 环境变量 | 默认对应 GLM 模型 |
|---|---|
ANTHROPIC_DEFAULT_OPUS_MODEL | GLM-5 |
ANTHROPIC_DEFAULT_SONNET_MODEL | GLM-4.7 |
ANTHROPIC_DEFAULT_HAIKU_MODEL | GLM-4.5-Air |
这里有个坑:即使你的套餐已经支持 GLM-5,默认配置不一定会自动切过去。
你需要手动去改 Claude Code 的配置文件,路径是 ~/.claude/settings.json,把模型改成 GLM-5。
"ANTHROPIC_DEFAULT_OPUS_MODEL": "GLM-5",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7"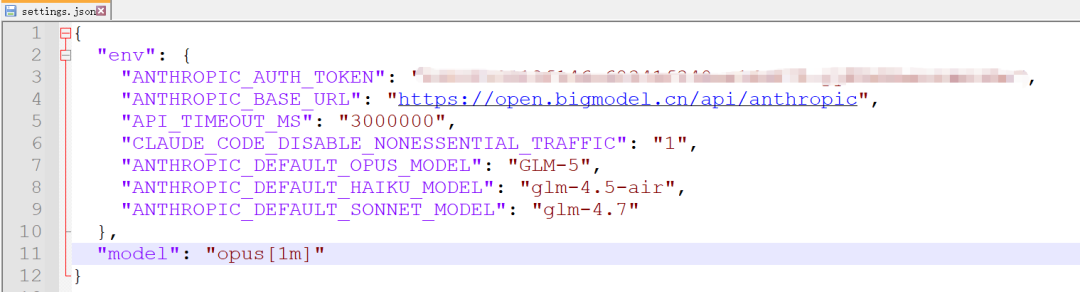
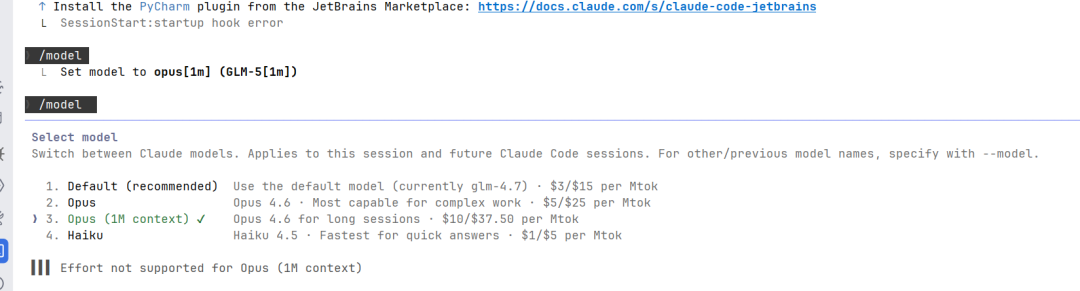
不改的话,可能还是在用 GLM-4.7 跑 Opus 的任务,效果差异会很明显。
写在最后
说实话,GLM-5 让我对国产大模型的信心拉高了一个档位。
不是说它已经全面超越 Claude——在某些细腻的代码理解和重构场景上,Opus 4.5 依然更稳。但 GLM-5 在 Agent 长程任务、工具调用稳定性、200K 长上下文 这几个维度上,确实做到了"能用、好用、敢用"的程度。
特别是对于预算敏感、对数据隐私有要求、或者需要私有化部署的团队来说,GLM-5 可能是目前最值得认真评估的选项。
一句话总结:GLM-5 不是"又一个跑分很高的国产模型",而是第一个让我在 Agent 生产项目里敢拿来替换的。
相关资源:
- • 体验中心:https://bigmodel.cn/trialcenter/modeltrial/text?modelCode=glm-5
- • API 文档:https://docs.bigmodel.cn
相关文章推荐:
如果这篇文章帮到了你,不妨点个分享给同样需要的朋友吧! 你的每一次支持,都是我持续创作的动力!💪
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号