Agent Memory:从概念到架构的完整解析

Agent Memory:从概念到架构的完整解析

烟雨平生
发布于 2026-04-21 14:18:29
发布于 2026-04-21 14:18:29

为什么需要Agent Memory?今天的大语言模型(LLM)在单次会话中已经足够聪明,但面临一个根本性挑战:没法把昨天学到的东西,以一种可靠、可更新、可追责的方式带到今天。
核心痛点
- 上下文窗口的物理极限
- 128K、1M甚至100M的上下文窗口,在长期交互中依然不够用
- O(N²)复杂度的Attention计算导致首字延迟(TTFT)飙升
- 每次API调用都要把历史记录重新灌给模型,成本变成填不满的黑洞
- 执行型Agent的爆发
- 以OpenClaw、Hermes为代表的主动执行型Agent,需要深度理解用户偏好、习惯和过往行为模式
- 没有长期记忆的Agent,就像一个每天上班都要重新培训一遍的实习生
- 自我演化的终极目标
- 当前AI依赖离线的预训练与后训练,模型出厂后智能就此冻结
- 真正的AI需要在持续交互中,基于用户与环境的反馈持续演进
一、核心概念:什么是Agent Memory?
1.1 定义
Agent Memory保存的是可跨时延续并影响未来决策的结构化历史——所谓"结构化",指的是带来源、作用域、时间权重和可修正性的历史对象,而不是"把聊天记录再存一份"。
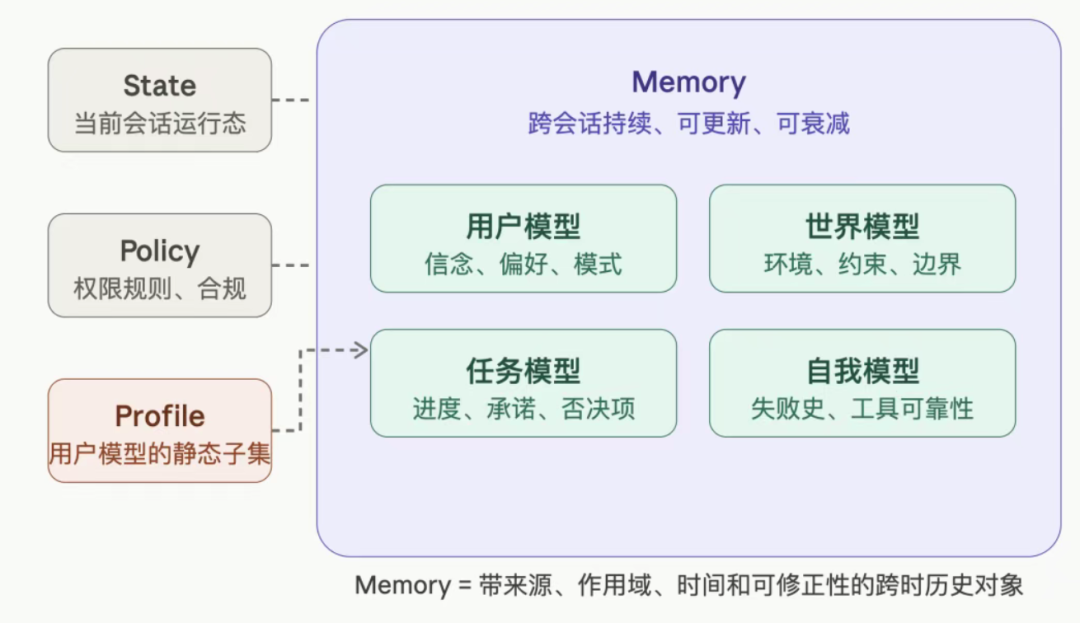
1.2 与相关概念的区别
Memory vs State
- State是当前session内的短期运行态:对话上下文、工具调用的中间结果
- State 随 Session 结束即销毁
- Memory 则跨 Session 持久存在,并持续影响未来决策。
Memory vs Policy
- Policy管的是"允许与禁止":权限边界、安全规则、合规约束
- Memory不应能改写自己的权限规则,那是越权而非记忆进化
Memory vs Profile
- Profile是用户模型的一个低维、显式、便于消费的快照层
- Profile是记忆的一个输出产物,不是记忆本身
- 把Profile等同于Memory,就像把一张名片等同于你对一个人的全部理解
1.3 Memory不是蒸馏
很多人把"蒸馏"和"记忆"混用,这是不对的。摘要、reflection、session summary——这些都是memory pipeline里管理环节的一个操作,而不是memory本身。
蒸馏的局限:
- 擅长留下结论,不擅长留下形成结论的轨迹
- 一条摘要能写下"用户偏好TypeScript",却很难保留这条偏好是如何形成的、在什么上下文下成立、最近是否正在漂移
核心区别:
- 蒸馏试图把过去压缩成一句话
- 记忆试图把过去构建成一个可继续更新、可继续推理的动态模型
二、Memory的建模对象
面向工程实现,记忆的建模对象可以分成四类:
2.1 用户模型
- 内容:偏好、风险偏好、沟通习惯、决策模式
- 示例:用户从"抵触TypeScript"到"逐渐接受"再到"主动要求重写"的转变轨迹
2.2 任务模型
- 内容:哪些方案被否决过,哪些结论已确认,哪些artifact是当前真实版本
- 示例:AI失败不是不懂你,而是不记得事情已经推进到了哪一步
2.3 世界模型
- 内容:操作环境、仓库结构、API约束、系统边界、组织规则、数据新鲜度
- 示例:大量"个性化错误"本质上不是没记住你,而是没记住你所在的环境已经变了
2.4 自我模型
- 内容:试过什么、哪条路径失败过、哪个工具在什么场景下不稳定
- 示例:没有这层memory,Agent不是在学习,只是在重复犯错
意图不是被单独存储的——它是这四层模型长期耦合后浮现出来的上层能力,就像一个跟了你三年的助理,他"懂你"不是因为背了一本偏好手册,而是因为他同时理解你的脾气、你的项目进度、你的组织环境和他自己的能力边界。
三、Memory的本质架构
3.1 核心命题
命题A:Memory不是"存储",而是可被决策利用的外部状态
如果把Agent看成一个从输入到输出的函数,仅仅"存了很多历史"并不构成能力。能力来自:在当前状态下,历史能否以某种形式影响决策分布。Memory负责从历史中提取当前可用的信息,并把它提供给推理层,共同产生决策。
命题B:Memory的最小闭包不是"文档块",而是
- Raw Ledger(权威记录):追加式记录每次写入/更新/删除发生了什么
- Derived Views(派生视图):面向检索/推理的派生状态(向量索引、keyword/hybrid、KG/TKG、timeline、skill index等)
- Policy(控制层):决定何时读、读多少、何时写、如何更新、如何遗忘
Raw Ledger像"账本/黑匣子";views像"缓存+索引+物化视图";policy像"调度器/控制回路"。
命题C:Memory的基本单位应当是event序列,但"直接用event流"不等于可用系统
event序列是"真相来源",但它太底层。真正把历史变成能力的是views(对event的重组织/压缩/索引/时序化/技能化)和policy(决定什么时候触发哪些view、怎么更新view)。
3.2 System 1 + System 2 设计
System 1:General Agent(快速回路)
- 通用LLM/Agent(推理、规划、工具调用)
- 提供基线能力(通用性)
System 2:Agentic Memory(慢速回路)
- PreThink → Retrieve (loop) → Evidence Accumulate → Early Stop
- Memory Infra(Raw Ledger + Derived Views)
- 提供个性化、任务特化、时序修正、经验复用
为什么需要System 2?
- 记忆能力和LLM本身的其他Agent能力是"相对"正交的
- 外置化的System 2在可插拔、可迁移、可归因方面带来大量工程好处
- 可以适当牺牲一点Memory System的上限,来获得大量的好处
四、Memory的三条链路
记忆系统不是一个容器,而是三条链路的闭环:
4.1 写入链路:预算分配
写入本质是一次decision under budget。这里的预算不只是存储空间,还包括:
- 未来的检索成本
- 推理时的注意力开销
- 后续的冲突管理代价
在这些约束下,写入要做的是决定:哪些信息值得获得对未来决策的影响力。
这意味着写入不能只看"这条信息有没有价值",而要看它相对于已有记忆的边际价值。
关键原则:
- 行为证据通常比口头表态更值得写入预算
- 新信号和已有信念冲突时,这个偏移本身就是高价值信号
4.2 管理链路:最容易偷懒也最关键
管理链路决定了记忆系统是长成资产还是长成垃圾堆,它至少处理五件事:
- 整合:把碎片信号聚合成结构化信念
- 冲突处理:用户在不同时间表达了相反偏好怎么办?更合理的做法是保留矛盾,建模为"此维度上的偏好是情境依赖的"
- 衰减与遗忘:不能忘的系统会被旧判断拖死。遗忘不是Bug,是防止记忆系统对现实过拟合的必要机制
- 来源追踪:没有provenance,Agent无法判断自己的信念有多可信
- 权限治理:用户必须能查看、编辑、删除Agent的记忆
4.3 读取链路:任务约束优先
传统RAG式语义相似度召回有一个根本局限:它默认相关性由表层语义决定,而实际决策中最有价值的记忆往往与此并不一致。
所以读取应该从语义相似召回,升级为任务约束驱动的检索-推断耦合。
五、基本记忆单元
如果记忆不是一句摘要,那它到底是什么?若把记忆做成可计算对象,至少需要六个维度:
5.1 内容(Content)
这条记忆说了什么。例如:"用户在性能和开发体验之间倾向选择性能。"
5.2 类型(Type)
至少区分五种:
- event:发生了什么
- assertion:用户明确声明了什么
- belief:Agent推断出来的
- constraint:不可违反的边界
- commitment:Agent做出但尚未完成的承诺
5.3 置信度(Confidence)
Agent对这条记忆有多确信。主要适用于belief和commitment。
5.4 来源(Source)
这条记忆从哪来:
- 用户明确表达的
- 从行为推断的
- 从环境观察到的
- Agent自己生成的
5.5 作用域(Scope)
它在什么上下文下成立。"偏好性能优先"在后端架构决策中成立,在前端原型阶段未必。
5.6 时间与衰减(Time & Decay)
什么时候产生的,上次被确认或引用是什么时候,衰减权重是多少。
六、进阶架构:从基础到自进化
6.1 时序记忆
问题:时序不是metadata,而是Memory OS的结构维度
为什么必须把时序提升到架构骨架层?
- LLM对时间天然不敏感(尤其是隐含时间、相对时间、跨时区)
- 纯语义检索会把"过去的高相似事实"错当成"现在仍为真"
- 决策层出现"过时事实复活"、"被纠正的事实仍反复召回"
解决方案:
- Raw Ledger:需要能表达"事后纠错"而不破坏审计
- Views:检索不是"相关即可",而是"在某个查询时间语境下成立"
- Policy:默认time_scope=current意味着"宁可漏,不可错"
6.2 程序化记忆
问题:RAG擅长把"信息片段"检索回来,却很难直接检索并复用"推理过程/操作流程/可执行技能"
解决方案:将成功的交互历史形式化为可执行技能单元
ProcMEM的三元结构:
skill = {trigger: "在什么情况下触发", execution: "具体的执行步骤", termination: "何时结束" } ProcMEM的三个阶段:
- 生成:使用语义梯度做事后归因,总结"这条技能为什么在这段轨迹里导致成功或失败"
- 验证:用PPO风格的信任域门控做反事实验证
- 维护:基于评分的在线维护机制,得分长期为非正的技能会被淘汰
6.3 Skills自进化
核心思想:让Agent在交互中自动提炼技能,将复杂任务成功率最高相对提升
进化闭环:
对话 → 经验提取 → 语义聚类 → 技能涌现 → 检索应用 → 更好的对话 → ... 技能特性:
- 技能即SOP:不是模糊建议,而是可执行的标准操作流程
- 增量式进化:每次新经验到来,通过增量操作精准迭代现有技能
- 成熟度评估:四维评分体系(完整性、可执行性、证据支撑度、清晰度)
- 信心退役机制:置信度持续下降的技能自动退役
6.4 mRAG混合检索架构
针对多模态信息的处理难题,EverOS推出了mRAG(Multimodal Retrieval-Augmented Generation)检索策略:
在数据摄入端(Ingestion):
- 支持全类型多模态数据的原生解析与存储(.pdf、.docx、.xlsx、.png、.webp、网页URL)
在检索端:
- 语义向量检索(捕捉深层语义意图)
- 稀疏关键词检索(如BM25,确保特定术语和命名实体的精确召回)
- 多模态对齐表征(实现"以文搜图"或跨模态的上下文还原)
七、实战应用:OpenClaw长期记忆系统
7.1 文件体系
OpenClaw的核心设计原则是:一切持久状态都是磁盘上的Markdown文件。
文件 | 用途 | 加载时机 |
|---|---|---|
AGENTS.md | 工作区规则、安全边界、红线指令 | 每次会话(最高优先级) |
SOUL.md | Agent个性、价值观、沟通风格 | 每次会话 |
IDENTITY.md | Agent身份元数据(名字、角色、头像) | 每次会话 |
USER.md | 用户档案(名字、昵称、时区、个人背景) | 每次会话 |
TOOLS.md | 环境配置(设备信息、SSH主机、TTS偏好) | 每次会话 |
MEMORY.md | 长期记忆(已验证事实、决策、持久学习) | 仅DM主会话 |
memory/YYYY-MM-DD.md | 日记忆(当天观察、临时笔记) | 当天+昨天自动加载 |
DREAMS.md | 梦境日记(Dreaming系统输出,仅供人类审查) | 不自动注入 |
7.2 记忆写入两条路径
路径1:Agent主动写入(LLM决策)
- 用户显式要求:用户说"记住我偏好TypeScript",Agent主动写入
- Agent自主判断:Agent在对话中认为某些信息值得保存,自行决定写入
路径2:Memory Flush自动写入(LLM决策)
- 触发条件:Token阈值(默认4000)、文件大小阈值(默认2MB)
- 作用:确保在激进的上下文裁剪之前,重要信息已被保存
7.3 Dreaming梦境系统:三阶段异步演进
Light Sleep(浅睡眠)——摄取与去重
- 信号源:日记忆文件、会话转录、短期回忆存储
- 去重:使用Jaccard相似度(默认阈值0.9)进行机械去重
REM Sleep(快速眼动睡眠)——反射与候选真理
- 主题反射:统计所有候选中的concept tags出现频率
- 候选真理选择:对每个候选计算置信度分数
confidence = avgScore × 0.45 + recallStrength × 0.25 + consolidation × 0.20 + conceptual × 0.10 Deep Sleep(深度睡眠)——六维评分与晋升
信号 | 权重 | 计算方式 | 含义 |
|---|---|---|---|
频率 | 0.24 | min(1, ln(signalCount + 1) / ln(11)) | 被回忆的总次数 |
相关性 | 0.30 | totalScore/max(1, signalCount) | 每次被检索时的平均质量分 |
多样性 | 0.15 | min(1,max(uniqueQueries, recallDays) / 5) | 不同查询/日期上下文的覆盖宽度 |
时效性 | 0.15 | exp(-λ × ageDays),λ = ln(2)/14 | 指数衰减,半衰期14天 |
巩固度 | 0.10 | max(0.55×spacing+0.45×span, groundedCount/3) | 多日重现或grounded信号强度 |
概念丰富度 | 0.06 | min(1,conceptTags.length / 6) | Concept标签密度 |
晋升门控:
score ≥ 0.80totalSignalCount ≥ 3max(uniqueQueries, recallDays.length) ≥ 3
八、业界最新实践与成果
8.1 LoCoMo10评测结果
RDSClaw记忆插件在LoCoMo10长对话记忆基准中的表现:
Category | 类型 | OpenClaw原生 | RDSClaw插件 | 准确率差值 |
|---|---|---|---|---|
Category1 | 事实查询 | 34.04% | 62.54% | +28.50% |
Category2 | 时间相关 | 57.01% | 67.07% | +10.06% |
Category3 | 推理性 | 43.75% | 65.35% | +21.60% |
Category4 | 描述性 | 68.37% | 78.18% | +9.81% |
总体 | 全部类别汇总 | 58.18% | 72.08% | +13.90% |
关键洞察:
- 事实查询提升最大(+28.50%):插件双管线+实时CRUD整合的核心优势
- 推理性问题提升显著(+21.60%):混合召回(向量+BM25)和LLM语义去重的效果
- 在不改变底层LLM的前提下,仅通过记忆管线的工程优化就实现了近14个百分点的提升
8.2 EvoAgentBench:量化Agent的自进化能力
基于QWEN3.5 397B和27B模型,测试OpenClaw的任务执行成功率:
核心发现:
- 工程实战能力进化最为显著:27B模型从11.5%跃升至38.5%,相对提升达234.8%
- 记忆是比参数量更高效的能力杠杆:27B+EverOS追平397B+EverOS的表现
- 进化不仅提升成功率,还在压缩执行路径:397B模型的任务分解轮次从36.3显著降低到24.3
- Skills自进化机制具备跨任务类型的普适性:在信息检索(↑33.4%)、推理与问题分解(↑13.5%)、软件工程(↑43.1%)三个维度上均实现正向提升
九、核心原则总结
9.1 Memory的难点从来不在容量,在治理
回看整条链路,每一步的核心问题都是同一个词:
- 写入决定什么信息获得对未来的影响力
- 管理决定什么信念继续保持有效
- 读取决定什么记忆真正进入当下决策
- 遗忘决定什么经验退出舞台
这四个动作,没有一个是容量问题,全都是治理问题——谁被允许持续影响未来。
9.2 进化 = 修正 + 遗忘
"记忆会进化"这句话需要讲实:
- 自我修正:当Agent基于记忆做出了用户不满意的响应,这个负反馈应该回溯到记忆层
- 有策略的遗忘:被后续信号反复否定的旧belief,高度情境依赖且低泛化的细节,已被更高层抽象吸收的底层event
深层洞察:僵化的不是经验本身,而是失去了持续更新与校正机制的经验。Few-shot示例、摘要、fine-tuned preference profile——它们真正的问题是,一旦脱离了持续校正闭环,就从资产变成了惯性。
9.3 从"瑞士军刀"到"数字灵魂"
17世纪英国哲学家约翰・洛克在探讨"人格同一性"(Personal Identity)时曾提出一个著名的观点:正是意识(特别是记忆)的连续性,构成了"我"之所以为"我"的核心。
如果没有记忆,昨天的我和今天的我就没有任何关联。
当前的大模型,本质上是一把无比锋利、功能齐全的"瑞士军刀"。它什么都能切,什么都能做,但它永远是一把冰冷的工具。你每次拔出它,它都不记得上次为你削过什么苹果。
而赋予AI以持续一致、个性化、可进化的记忆,就是在为这把瑞士军刀注入"数字灵魂"。
当Agent能够:
- 通过Skills引擎,记住你写代码时的缩进强迫症
- 通过mRAG准确调出你们三个月前共同探讨过的那张架构草图
- 在一次次试错中积累经验,最终形成专属于你的执行蓝图时
它就不再是一个随时可以被替换的API端点,而是一个与你共同经历岁月、拥有默契暗号、真正懂你的数字伙伴。
十、未来趋势
10.1 生成式记忆 > 检索式记忆
不再"查什么用什么",而是"缺什么生什么"。
10.2 自动记忆管理
把"写/删/改"做成Agent可调用的Tool,让LLM自己管自己。
10.3 RL全面接管记忆策略
从"人工拍阈值"到"策略网络端到端优化"。
10.4 多模态记忆
视频、音频、传感器流统一进Embedding空间。
10.5 多Agent共享记忆
角色-权限-隐私三权分立,防止"集体幻觉"。
10.6 世界模型内存
从"缓存帧"到"可查询状态模拟器"。
10.7 可信记忆
差分隐私、可验证遗忘、审计日志、用户级GDPR擦除。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号