MiniMax-M2.7:能“自我进化”的AI,是噱头还是真革命?

MiniMax-M2.7:能“自我进化”的AI,是噱头还是真革命?

沈宥
发布于 2026-04-21 13:43:41
发布于 2026-04-21 13:43:41
它能自己改代码、自己做实验、自己优化性能——这听起来像科幻,但 MiniMax 的 M2.7 模型,真的在这么干。
最近,国产大模型厂商 MiniMax 发布了其最新力作 M2.7。官方宣称,这是他们首个深度参与自身进化的模型。乍一听有点玄乎,但细看技术细节,确实让人眼前一亮。
那么,这个“会自我进化”的 AI,到底强在哪?值不值得我们开发者去尝试?今天,我们就抛开营销话术,用通俗语言+真实实践视角,带你看清 M2.7 的真实能力边界与落地价值。
🔍 一、M2.7 到底“进化”了什么?
官方描述中,最抓眼球的是这句话:
“一个内部版本的 M2.7 自主优化了一个编程框架超过100轮——分析失败原因、修改代码、运行评测、决定保留或回滚,最终性能提升30%。”
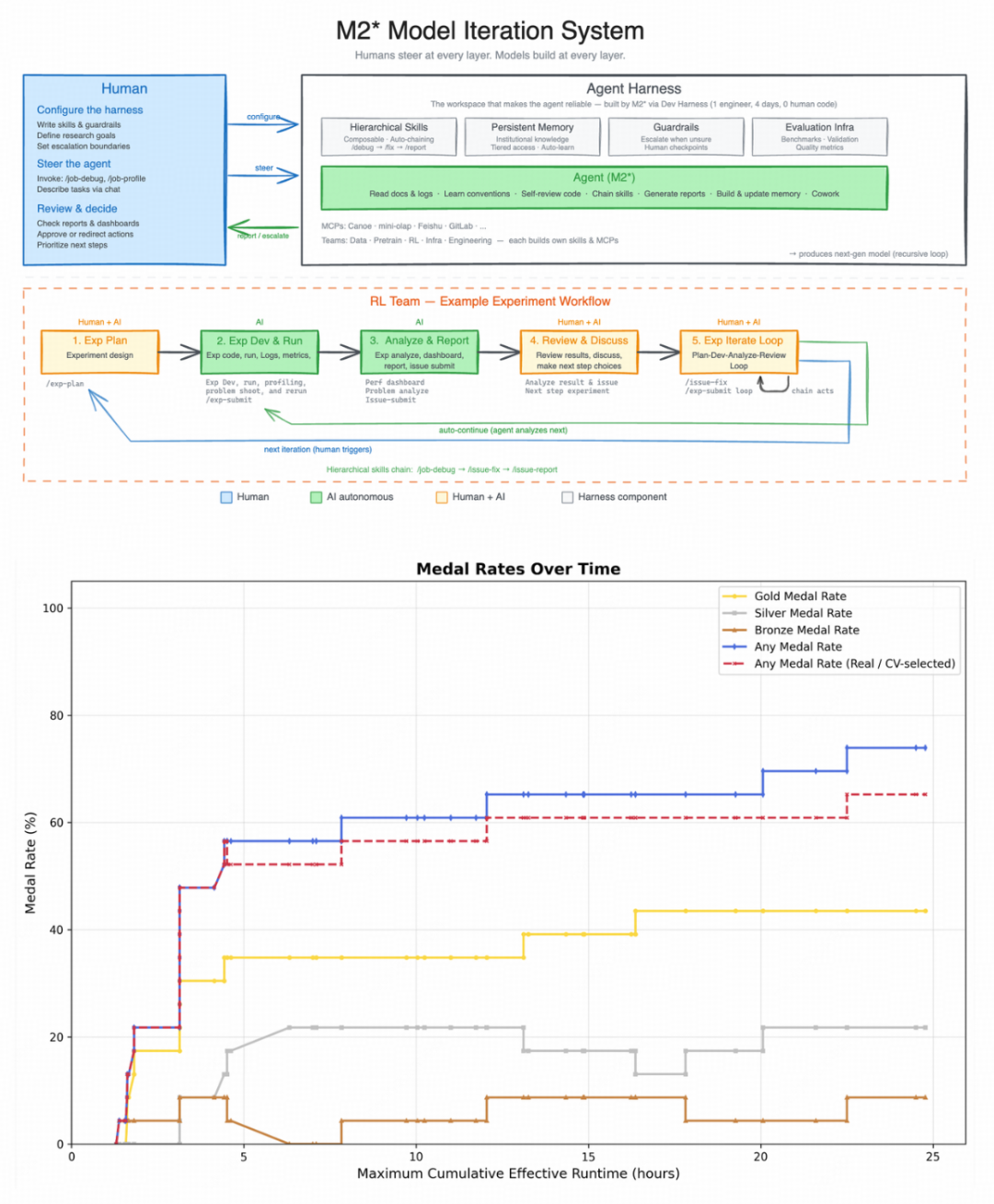
这可不是简单的“自动调参”,而是一个完整的科研闭环:
- 发现问题(代码跑不通/效果差)
- 提出假设(哪里可能出错了?)
- 动手实验(改代码、跑测试)
- 评估结果(比之前好还是坏?)
- 做出决策(保留改进 or 回滚)
整个过程,无需人类干预。更惊人的是,在包含22个机器学习竞赛的 MLE Bench Lite 测试中,M2.7 拿下了 66.6% 的奖牌率,仅次于 Claude Opus-4.6 和 GPT-5.4 这两个闭源巨无霸。
✅ 通俗理解它的核心优势:
- **它不只是“回答问题”,而是“解决问题”**。你给它一个模糊目标(比如“优化这个推荐算法”),它能自己拆解成一系列可执行的步骤,并调用工具去完成。
- **它拥有“长期记忆”和“反思能力”**。不是问完就忘,而是能把经验沉淀下来,用于下一次任务。
- 它是“Agent 团队”的指挥官。能协调多个技能模块(如数据清洗、模型训练、结果可视化)协同工作,像一个小型AI项目组。
⚠️ 二、但别被“自我进化”冲昏头脑:它的短板也很明显
尽管 M2.7 的理念非常超前,但在真实落地场景中,我们必须清醒地看到它的局限:
❌ 1. 对任务定义要求极高
M2.7 强大的前提是,你得给它一个清晰、结构化的目标。如果你只是说“帮我做个APP”,它可能会懵。它擅长的是“在给定约束下优化”,而不是“从0到1的创意发想”。
实践结论:适合有明确KPI的技术任务(如“将API响应时间降低20%”),不适合开放式的产品设计。
❌ 2. 资源消耗巨大
能跑100多轮自主实验,背后是海量的计算资源支撑。这意味着,M2.7 很难在普通服务器甚至单张A100上高效运行。对于中小企业或个人开发者,使用成本可能远超预期。
实践结论:目前更适合有强大算力支持的大厂或研究机构,离“平民化”还有距离。
❌ 3. “黑箱”程度更高
当模型自己改代码、自己做决策时,调试和归因变得极其困难。如果最终结果出了问题,你很难知道是哪一步的“自主决策”导致了错误。
实践结论:在金融、医疗等高风险领域,这种不可解释性可能是致命的,需谨慎评估。
🛠️ 三、谁应该现在就用 M2.7?
结合我们的分析,M2.7 并非“万能神药”,但它在特定场景下,确实能带来质的飞跃:
- **✅ AI Infra 团队**:可以用它来自动化模型调优、基础设施监控告警修复等重复性高、规则明确的运维任务。
- **✅ 量化交易/算法团队**:让它在历史数据上自主回测、优化交易策略,加速研发迭代。
- **✅ 大型科技公司的内部效率工具**:构建能自主完成数据分析、报告生成、代码审查的智能助手。
💡 写在最后:自我进化,是AI走向“智能体”的关键一步
MiniMax-M2.7 的真正意义,或许不在于它当下能帮你省多少人力,而在于它验证了一条通往通用人工智能(AGI)的新路径:让AI不仅能“学”,更能“思”和“创”。
当然,这条路还很漫长。今天的 M2.7,更像是一个聪明但需要精心引导的实习生——你给它好课题,它能交出惊艳答卷;你放任不管,它也可能跑偏。
一句话总结: M2.7 不是拿来“聊天”的,而是拿来“干活”的。 如果你有明确、复杂的生产力任务,且有足够资源支撑,不妨给这位“自我进化”的新成员一个机会。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号