PaddleOCR的API开放了!撸⼀套视频字幕提取⼯具,体验完美!

PaddleOCR的API开放了!撸⼀套视频字幕提取⼯具,体验完美!

开源星探
发布于 2026-03-16 20:04:59
发布于 2026-03-16 20:04:59
最近在探索⼤模型应⽤开发时,我尝试将多模态能⼒与OCR技术结合,构建⼀套⾼度⾃动化的【AI视频字幕提取⼯具】。
这个⼯具不仅实现了全流程可视化操作,还能完整保留原始JSON结果与坐标信息,⼤幅降低了视频字幕处理的⻔槛。
今天就来分享我的搭建过程与测试效果,希望能为有类似需求的朋友提供⼀种轻量化解决⽅案。
为什么要做字幕提取?
说到视频字幕提取,很多⼈第⼀反应是“直接⽤播放器不是有吗?”但实际上,很多场景下原⽣字幕不可⽤,或者需要做定制化处理:
- • 剪辑视频时,需要将字幕与视频分离,⽅便后期编辑和重制;
- • 做内容检索,希望快速找到视频中的某⼀句话;
- • ⾃动翻译,需要获取准确的字幕⽂本,对接翻译API;
- • 数据分析,获取字幕出现时间和位置坐标,⽅便可视化展示;
- • ⽆字幕视频,需要⾃动⽣成字幕,提升内容质量。
过去我⽤过⼀些OCR模型,在⽂字的定位和识别⽅⾯,开源的 PaddleOCR 中的 PP-OCR 系列模型断崖式领先,不过之前PaddleOCR有⼀个天然的弊端,就是这些模型没有API,我需要将这些模型部署到我⾃⼰的设备上,奈何我本地没有任何GPU,所以只能在云平台租GPU来做相关的事情。
近期关注到 PaddleOCR 官⽹开放的 API,对我来说⾮常有吸引⼒,这相当于我可以省去租GPU的费⽤,可以零成本使⽤顶级的 OCR 能⼒。
API如何调⽤?
申请 PaddleOCR API 其实⾮常简单,⼏步就能搞定: 1、访问 PaddleOCR官⽹(www.paddleocr.com),注册并登录账号;
2、点击“API”,进⼊ API 示例代码界⾯;
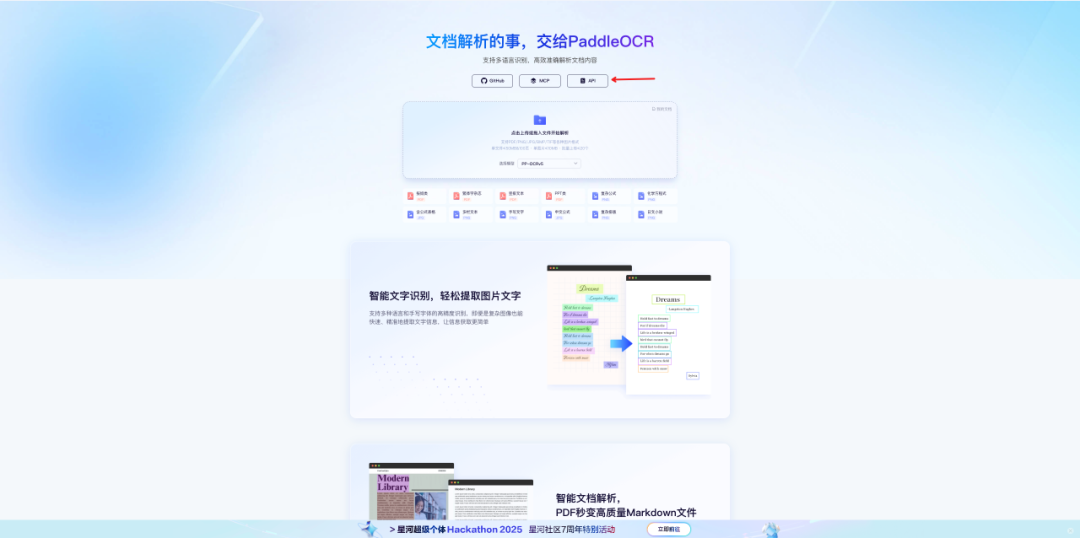
3、由于我需要进⾏的是字幕提取,只需要获取抽取帧的⽂本内容和位置信息就⾏了,所以这⾥选择适⽤于⽂本定位和识别任务的 PP-OCRv5。
如果你有⽂档解析需求,还可以选择 PaddleOCR-VL 或 PP-StructureV3,听说这⼏个模型效果都挺不错;
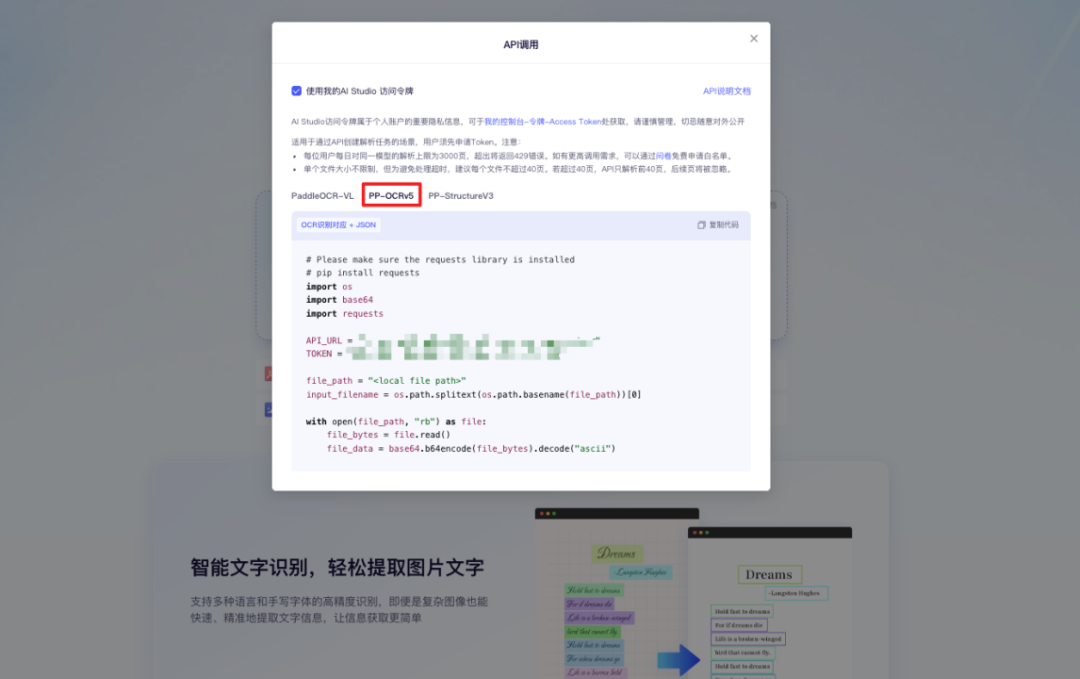
4、在示例代码⾥就能直接看到 API_URL 和 TOKEN,把这两个参数拷⻉下来,结合官⽅示例代码,就能轻松集成到⾃⼰的项⽬⾥调⽤了;
5、为了确保识别效果,在开始之前可以先基于官⽅示例代码来⼀波效果测试,截图⼀帧视频图像可以看到官⽅API返回的官⽅可视化结果。
从可视化结果可以看 PP-OCRv5 能够准确的识别图中全部的⽂字并且能够给出每⾏⽂字的坐标信息,所以我们可以通过这个坐标信息对⾮字幕区域的⽂字进⾏后续的过滤处理了,不过这些都可以交给⼤模型来帮我们实现。

6、官⽅⽬前针对同⼀模型的解析上限为 3000 ⻚,如果有更⼤需求也可以继续申请。
(🔗申请链接为:https://paddle.wjx.cn/vm/mePnNLR.aspx?udsid=716530)
对于⼤多数个⼈开发者来说,3000 ⻚完全够⽤!
这⼀步体验下来,感觉不是在申请,⽽是直接拿来就⽤,体验⾮常棒~
⼯具设计和搭建
有了想法和 API,接下来就可以正式动⼿设计⼩⼯具了。
其实整体流程⾮常简单,基于⼤模型辅助设计,先把官⽅示例代码发给⼤模型,然后项⽬代码⼤部分由AI⽣成。
本⼈主要进⾏逻辑调整与界⾯优化。关键步骤如下:
- 1.
视频分帧:按照设定的时间间隔,⾃动抽取关键帧; - 2.
帧图 OCR 识别:对每⼀帧图⽚调⽤ PaddleOCR API,获取识别结果(包括⽂本和坐标信息); - 3.
结果聚合与优化:由于字幕的持续时间不固定,同⼀段字幕可能会在多个帧被重复识别,因此需要做以下处理: ◦ 按照坐标位置过滤,剔除⾮字幕区域的识别结果; ◦ 按帧时间⾃动排序,保证字幕时间线准确; ◦ 对相邻帧中⾼度重复的⽂本⾃动合并,避免冗余; ◦ 结合字符串相似度和时间窗⼝进⾏去重,确保输出简洁。 - 4.
识别结果保存:API 返回的⽂本、原始 json、坐标等信息都会本地保存,⽅便后续查阅和分析,安全可控。 - 5.
导出格式:⽀持⼀键导出为 SRT 字幕格式,可直接⽤于视频剪辑、翻译或数据分析等场景。
整个流程实现了⾼度⾃动化,基本做到“喂视频,出字幕”,省时省⼒,⼤幅提升处理效率。
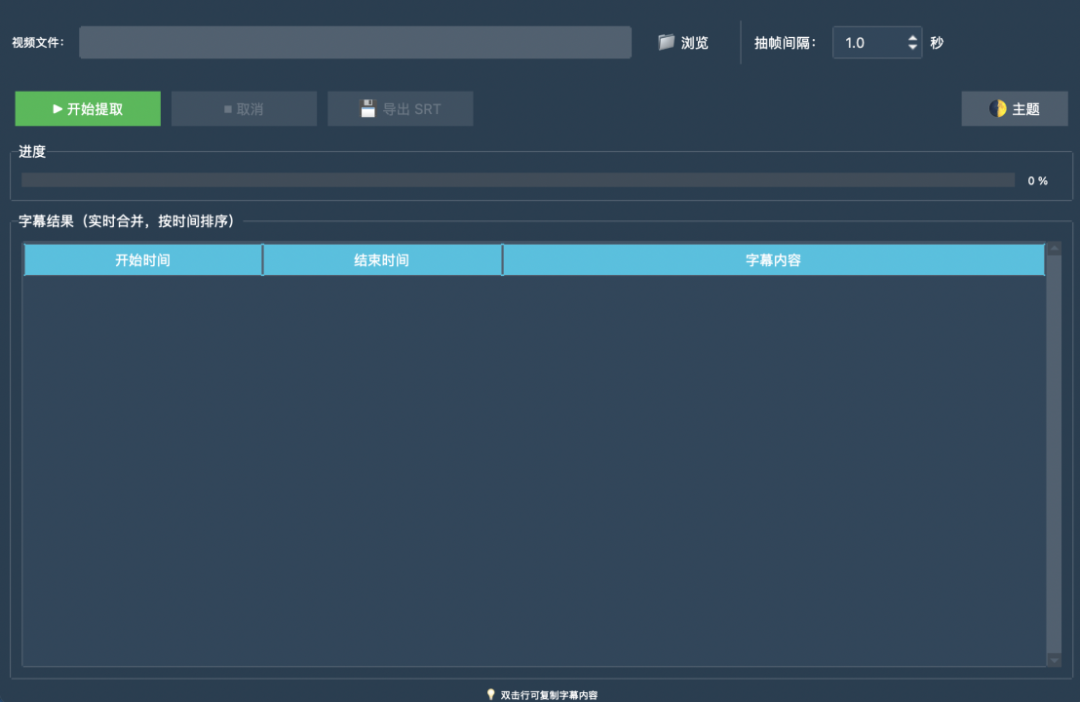
可视化操作界⾯
经过⼀番与⼤模型的代码交互,很快就实现了符合需求的⼩⼯具。
界⾯⽅⾯,我⽤ Python 的 Tkinter 库搭建,⻛格简洁直观,具体功能如下:
- • ⽀持本地选择视频⽂件,⾃定义抽帧间隔;
- • ⼀键“开始提取”,⾃动分帧识别,进度条实时显示;
- • 字幕结果可视化展示,⾃动聚合排序,⽀持双击复制;
- • SRT 字幕⽂件⼀键导出,兼容主流剪辑⼯具;
- • 所有原始识别结果(json、坐标等)本地保存,⽅便⼆次开发和数据分析。
效果测试
测试视频:选取⼀段B站电影预告⽚(含中英双语字幕)进⾏测试。
操作流程:
- 1. 在⼯具界⾯选择本地视频⽂件,设置抽帧间隔(如每秒1帧);
- 2. 点击“开始提取”,⼯具⾃动分帧并调⽤ PaddleOCR API 逐帧识别字幕;
- 3. 识别结果会按时间顺序⾃动合并、排序,去除重复内容,最终以表格形式在界⾯展示;
- 4. 所有字幕内容、时间戳和排序结果都⽀持⼀键导出为 SRT ⽂件,可直接⽤于剪辑或翻译;
- 5. 每⼀次识别的原始 JSON 结果和坐标信息⾃动保存到本地,便于后续数据分析或⼆次开发。
测试结果:
如下图所示,⼯具可以稳定识别出绝⼤部分字幕内容。
抽帧间隔设置为 1 秒,字幕⽂本在界⾯表格中⾃动按时间合并与排序,基本没有多余的重复。导出的 SRT ⽂件与原视频语⾳对⻬度⾼,能直接⽤于剪辑或翻译。
识别结果位置图⽚和原始JSON数据也全部保存在本地,后续可以做更细致的数据分析。
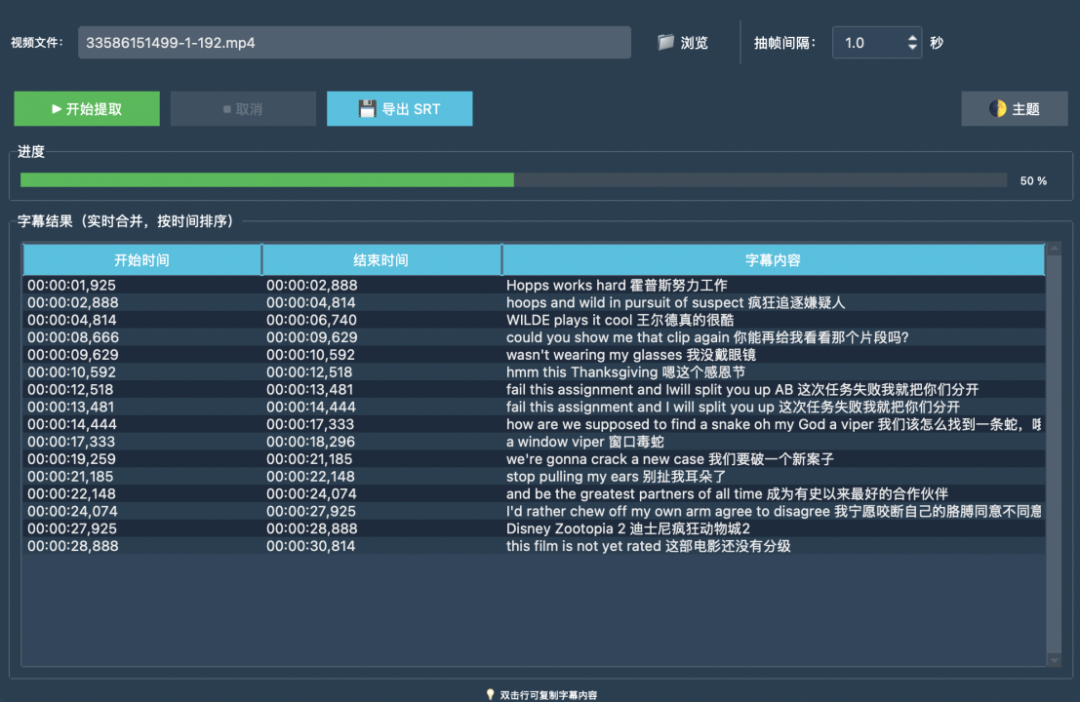
(字幕提取结果)

(提取到的字幕结果)
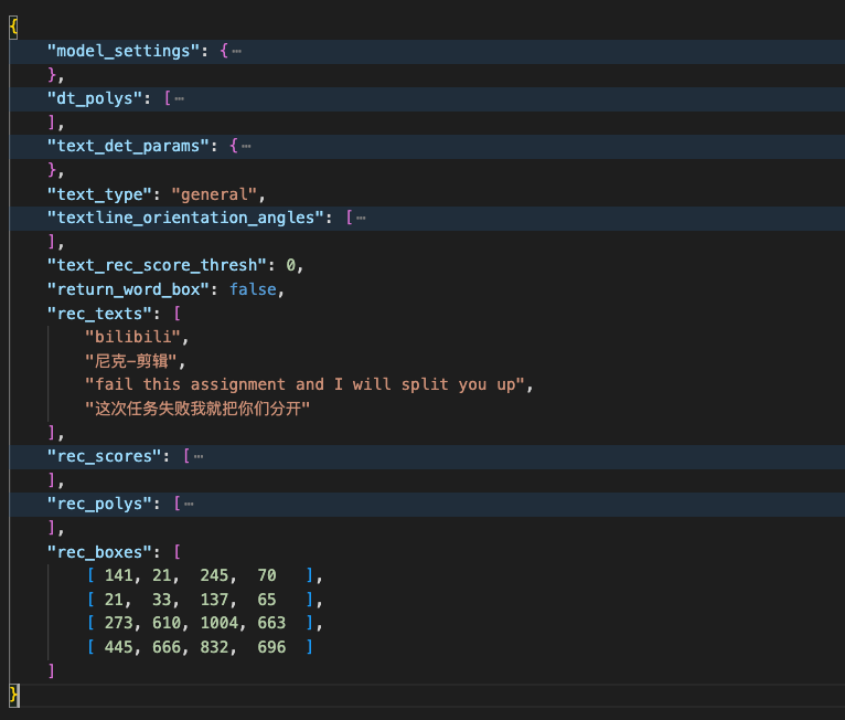
(保存下来的原始JSON数据)
应⽤场景拓展
除了最常⻅的字幕提取,基于这个⼯具我还发现了很多有趣的应⽤:
- • ⾃动视频摘要:结合⼤模型,把所有字幕聚合⽣成视频摘要;
- • 智能搜索:通过字幕内容实现视频内容检索,⽀持关键词定位;
- • 多语种同步:⾃动分离不同语种字幕,结合翻译API实现⾃动配⾳;
- • 内容安全审核:对视频中的字幕做敏感词过滤,⾃动标记⻛险内容;
- • 个性化特效:根据字幕坐标,⾃动⽣成⾼亮、弹幕遮罩、互动特效等。
这些场景,原先都是需要⼤量⼈⼯或⾼成本的接⼝,现在API 开放后,个⼈开发者也能轻松实现。
总结与展望
在⼤模型时代,⼯具的搭建就像变魔术⼀样简单,但这背后那些好⽤的基础能⼒才是真正的魔法。
通过本次实践,PaddleOCR 在视频字幕提取场景中展现了其核⼼价值:精准的识别能⼒确保了字幕⽂本的准确提取,⽽完整的坐标和结构化输出则为后续的时序对⻬、位置过滤和可视化展示提供了坚实基础。
其技术成熟度和稳定性⽀撑了整个处理流程的顺畅运⾏。PaddleOCR的API让我免去了配置环境的问题,本地⼏⾏代码就完成了关键的字幕识别。
搭配上⼤模型的写代码能⼒,⼩⽩开发者⾃⼰动⼿做的⼩⼯具已经能实现视频字幕⾃动提取、可视化展示、原始json结果导出等⼀系列功能。
⽆论你是做剪辑、内容分析、⾃动翻译,还是搞特效,都能派上⽤场。
接下来,我计划继续优化这个⼯具,⽐如增加⽀持批量视频处理、智能字幕纠错、⾃动翻译和多语种同步等⾼级功能。如果你也有类似的需求,欢迎⼀起来交流,薅这波技术⽺⽑,探索更多有趣的可能性!
最后,你有什么有趣的应⽤场景?评论区⼀起交流吧!
【附:⼯具部分核⼼代码,欢迎关注后续更新】
def ocr_image(file_path: str, frame: int) -> str:
try:
with open(file_path, "rb") as f:
file_data = base64.b64encode(f.read()).decode("ascii")
headers = {"Authorization": f"token {TOKEN}", "Content-Type": "application/json"}
payload = {
"file": file_data,
"fileType": 1,
"useDocOrientationClassify": False,
"useDocUnwarping": False,
"useTextlineOrientation": False,
}
resp = requests.post(API_URL, json=payload, headers=headers, timeout=20)
if resp.status_code != 200:
return ""
result = resp.json().get("result", {})
if not result.get("ocrResults"):
return ""
texts, height = [], result.get("dataInfo", {}).get("height", 720)
boxes = []
y_threshold = height * 6 / 7
if not os.path.exists("output"):
os.makedirs("output")
for res in result["ocrResults"]:
pruned = res.get("prunedResult", {})
ocr_res_image_url = res.get("ocrImage", "")
if ocr_res_image_url:
response = requests.get(ocr_res_image_url)
if response.status_code == 200:
with open(f"output/frame_ocr_{frame}.jpg", "wb") as f:
f.write(response.content)
with open(f"output/frame_ocr_{frame}.json", "w") as f:
json.dump(pruned, f)
else:
print("图片下载失败:", response.status_code)
else:
print("没有ocrImage字段")
for txt, box in zip(pruned.get("rec_texts", []), pruned.get("rec_boxes", [])):
if box[1] >= y_threshold or box[3] >= y_threshold:
texts.append(txt)
boxes.append(box)
src_img = cv2.imread(file_path)
for text, box in zip(texts, boxes):
color = get_random_color()
draw_transparent_rectangle(src_img, (box[0], box[1]), (box[2], box[3]), color, alpha=0.5)
src_img = draw_text_with_pil(src_img, text, (box[0], box[1]-20),color=(0,0,255))
result_text = " ".join(texts).strip()
cv2.imwrite(f"output/frame_result_{frame}.jpg", src_img, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
return result_text
except Exception as e:
print(f"An error occurred: {e}")
return ""
def extract_subtitles(video_path: str, interval: float, progress_cb=None, ui_queue=None, cancel_event=None):
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS) or 25
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_gap = int(fps * interval)
temp_dir = tempfile.mkdtemp()
tasks, frame_num = [], 0
while True:
if cancel_event and cancel_event.is_set():
break
ret, frame = cap.read()
if not ret:
break
if frame_num % frame_gap == 0:
img_path = os.path.join(temp_dir, f"f{frame_num}.jpg")
cv2.imwrite(img_path, frame)
tasks.append((frame_num, img_path))
frame_num += 1
cap.release()
if cancel_event and cancel_event.is_set():
return []
sorted_map = SortedDict()
lock = threading.Lock()
def _ocr(task):
fnum, fpath = task
time.sleep(0.1)
txt = ocr_image(fpath, fnum)
with lock:
if not txt:
return
start = fnum / fps
end = (fnum + frame_gap) / fps
sorted_map[fnum] = (start, end, txt)
merge_neighbor(sorted_map, fnum, fps)
if progress_cb:
progress_cb(len(sorted_map) / len(tasks) if tasks else 0)
if ui_queue is not None:
ui_queue.put(list(sorted_map.values()))
with ThreadPoolExecutor(max_workers=1) as exe:
futures = [exe.submit(_ocr, t) for t in tasks]
for f in as_completed(futures):
if cancel_event and cancel_event.is_set():
for fut in futures:
fut.cancel()
break
try:
f.result()
except Exception:
pass
# 清理
for f in os.listdir(temp_dir):
try:
os.remove(os.path.join(temp_dir, f))
except Exception:
pass
try:
os.rmdir(temp_dir)
except Exception:
pass
return [{"start": v[0], "end": v[1], "text": v[2]} for v in sorted_map.values()]
如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号