从零实现 LLM 中的 KV 缓存机制,提升推理速度 5 倍!

从零实现 LLM 中的 KV 缓存机制,提升推理速度 5 倍!

山行AI
发布于 2026-03-13 19:42:06
发布于 2026-03-13 19:42:06
本文较为精简,更详细的内容可见三人行AI从零开始理解与编码 LLM 中的 KV 缓存机制
KV(Key-Value)缓存是实现大语言模型(LLM)在生产环境中高效推理的关键技术之一。本文将从概念和代码两个层面出发,通过从零构建、可读性强的实现,详细解释它是如何工作的。
🧭 内容导航
•1. 什么是 KV 缓存[1]•2. KV 缓存的核心思想[2]•3. KV 缓存的对比图示[3]•4. 从零实现 KV 缓存[4]•5. KV 缓存的性能对比[5]•6. KV 缓存的优缺点[6]•7. KV 缓存的优化技巧[7]•8. 结语:权衡与实用性[8]
1. 什么是 KV 缓存?
在 LLM 推理(inference)阶段,模型生成每一个 token 时都需要重新计算此前所有输入的 attention 结构,包括 Query、Key、Value 向量。
这是一种冗余操作 —— 因为这些 Key 和 Value 在每轮生成中并未发生改变。
📌 示例说明:
以 prompt 输入 “Time” 为例,模型逐词生成 “Time flies fast”。
•每生成一个新 token,如 "fast",模型需要重新计算前面 "Time" 和 "flies" 的 key/value 向量。•如下图所示:
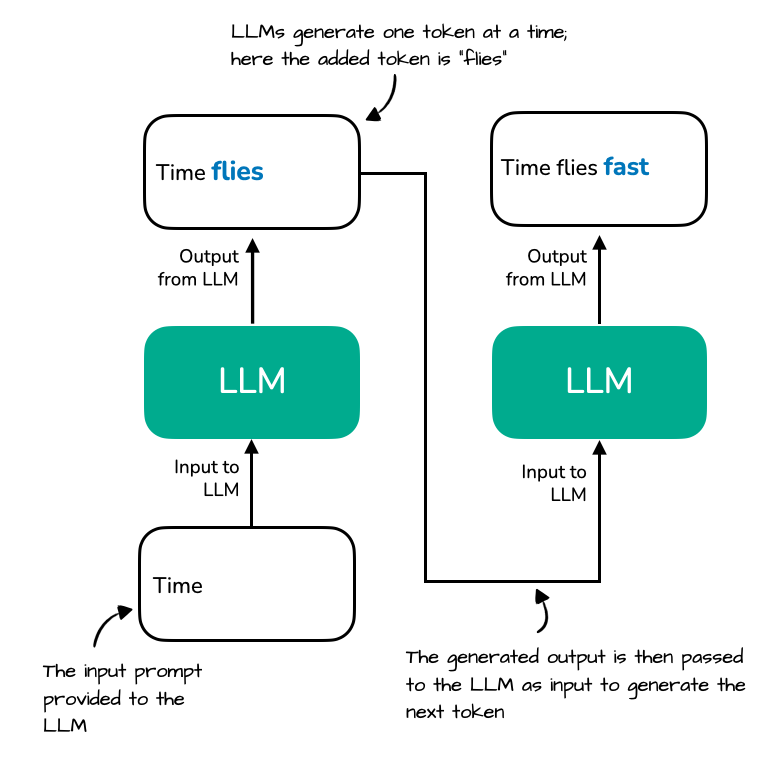
请注意,LLM 文本在生成输出过程中存在一些冗余,如下图所示:
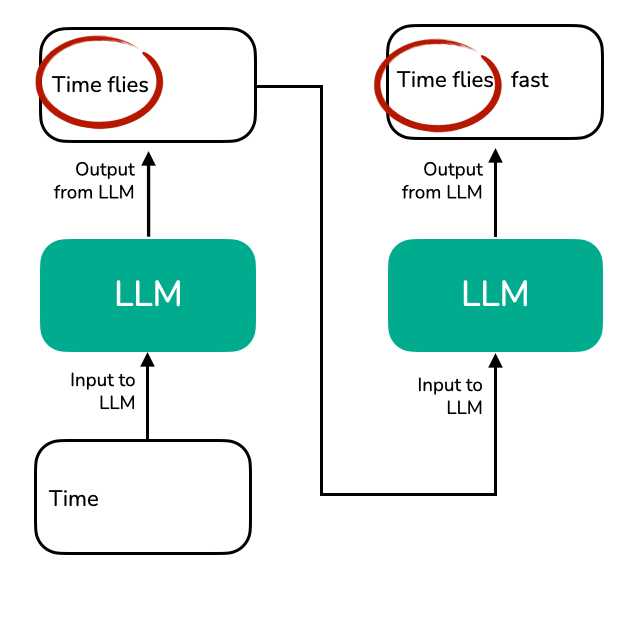
在每一步生成过程中,LLM 都需要重新处理完整的上下文 “Time flies”,才能生成下一个 token(如 “fast”)。由于 未对中间的 key/value 向量进行缓存,模型不得不反复对整个序列进行编码,造成了不必要的计算冗余。
2. KV 缓存的核心思想
为避免重复计算,KV 缓存机制的目标是:
缓存每一步生成的 Key 和 Value 向量,并在后续步骤中复用。
✅ 工作流程:
步骤 | 有无缓存 | 说明 |
|---|---|---|
第一步 | 计算并缓存当前 token 的 Key/Value | 初始化缓存 |
后续步骤 | 复用缓存,仅计算新 token 的 Key/Value | 节省计算资源 |
3. KV 缓存的对比图示
🔁 无 KV 缓存:
每次生成新 token,都重新编码之前所有输入。
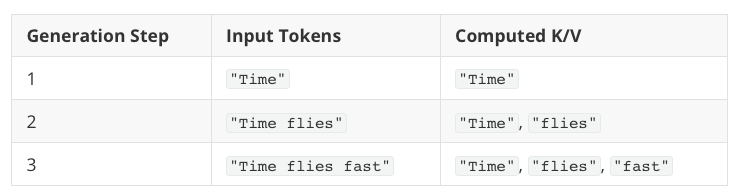
(不断重复 Key/Value 计算)
✅ 有 KV 缓存:
只计算当前 token 的 Key/Value,前面的向量从缓存中直接读取。
✅总结:计算和缓存步骤一览表

4. 从零实现 KV 缓存
🗂️ 参考文件:
•gpt_ch04.py[9]:原始实现,无缓存。•gpt_with_kv_cache.py[10]:新增 KV 缓存逻辑。
🔧 核心改动如下:
4.1 注册缓存变量
self.register_buffer("cache_k",None, persistent=False)
self.register_buffer("cache_v",None, persistent=False)4.2 前向传播添加 use_cache 参数
def forward(self, x, use_cache=False):
# 新 Key/Value
keys_new =self.W_key(x)
values_new =self.W_value(x)
if use_cache:
# 初始化或拼接缓存
...
else:
keys, values = keys_new, values_new4.3 清空缓存
def reset_cache(self):
self.cache_k,self.cache_v =None,None4.4 顶层模型中添加位置跟踪 current_pos
if use_cache:
pos_ids = torch.arange(self.current_pos,...)
self.current_pos += seq_len4.5 文本生成逻辑
def generate_text_simple_cached(model, idx, max_new_tokens, use_cache=True):
...
logits = model(next_idx, use_cache=True)5. KV 缓存的性能对比
📊 实验结果:(Mac mini + 1.2亿参数小模型)
模式 | 总时间 | 提速倍数 |
|---|---|---|
无缓存 | 13.7 秒 | - |
有缓存 | 2.8 秒 | 约 5 倍提升 |
📷 (插图:KV 缓存 vs 非缓存耗时对比图)
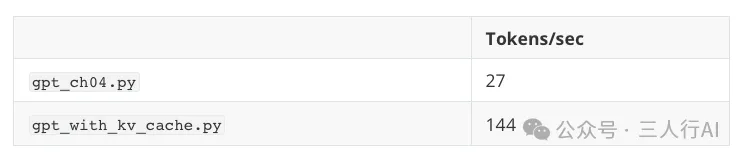
图片
✅ 模型输出一致,说明实现正确。
6. KV 缓存的优缺点
✅ 优点
•显著加速:复杂度从 O(n²) 降至 O(n)•推理阶段表现优越
⚠️ 缺点
•占用更多显存(随序列长度增长)•实现更复杂,需要管理状态
7. KV 缓存的优化技巧
💡 Tip 1:预分配内存
cache_k = torch.zeros((B, H, L, D), device=device)💡 Tip 2:滑动窗口缓存
cache_k = cache_k[:,:,-window_size:,:]避免 GPU 内存暴涨,适用于长上下文生成任务。
8. 结语:权衡与实用性
虽然 KV 缓存增加了实现复杂度和内存占用,但它带来的推理效率提升是实实在在的,尤其在实际部署 LLM 时。
🚀 推荐实践
•初学者:可直接阅读 gpt_with_kv_cache.py 并通过 # NEW 标签查看核心改动;•高阶开发者:参考 gpt_with_kv_cache_optimized.py 实现更高效版本;•推理部署:优先启用 KV 缓存并考虑显存约束、滑窗机制。
祝你编码愉快!👨💻🚀
References
[1] 1. 什么是 KV 缓存:#1-什么是-kv-缓存
[2]2. KV 缓存的核心思想:#2-kv-缓存的核心思想
[3]3. KV 缓存的对比图示:#3-kv-缓存的对比图示
[4]4. 从零实现 KV 缓存:#4-从零实现-kv-缓存
[5]5. KV 缓存的性能对比:#5-kv-缓存的性能对比
[6]6. KV 缓存的优缺点:#6-kv-缓存的优缺点
[7]7. KV 缓存的优化技巧:#7-kv-缓存的优化技巧
[8]8. 结语:权衡与实用性: #8-结语权衡与实用性
[9] gpt_ch04.py: https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/03_kv-cache/gpt_ch04.py
[10] gpt_with_kv_cache.py: https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/03_kv-cache/gpt_with_kv_cache.py
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号