ICML 2026|过程泛化才是真泛化!AlignedNorm:重新理解多模态提示学习

ICML 2026|过程泛化才是真泛化!AlignedNorm:重新理解多模态提示学习

Amusi
发布于 2026-07-03 20:30:26
发布于 2026-07-03 20:30:26
【导读】 现有方法通常在微调终点寻找兼顾适应性与泛化性的理想结果,却较少追问:从可见类别上学到的变化规律,能否同样作用于未见类别?AlignedNorm 将这种变化建模为耦合提示场,并通过两级范数对齐增强其跨类别一致性,在无需额外教师模型或解耦推理的情况下兼顾适应性与泛化性。 提示学习通过少量可学习的上下文向量,使 CLIP 等视觉—语言预训练模型适配下游任务。 然而,提示学习长期面临适应性与泛化性之间的权衡(Base-New Tradeoff,BNT):强化对可见类别的适应,往往会损害未见类别性能;过度保护预训练空间,又会限制下游适应能力。 前沿方法主要从微调结果出发,即先设想模型应当到达的理想终点,再围绕这个终点设计训练或推理策略。端到端方法通常需要一个理想参考:早期依赖自正则化,当自身参考不再足够理想时,便转向外部教师模型。解耦方法则认为可见与未见类别的理想结果并不重合,因此分开建模;但这往往要求测试时预知样本的类别身份。在真实世界的开放场景中,理想外部模型和类别身份先验并不总能获得,内生的泛化微调机制仍值得研究。 AlignedNorm 将关注点从微调后的结果转向微调所引起的变化。本文所谓“过程泛化”,不是指训练轨迹本身可以迁移,而是指模型在可见类别上学到的变化规律,仍能一致地作用于未见类别,并为二者带来正向增益。结果泛化关注“新类上准不准”,过程泛化关注“学到的改变能否跨类别成立”。

论文标题:AlignedNorm: Prompting Vision-Language Models via Coupled Prompt Field 项目主页:https://qbytem.github.io/alignednorm 开源代码:https://github.com/QByteM/AlignedNorm 论文地址:https://openreview.net/forum?id=aQAWAtrxxe 中文版论文:https://qbytem.github.io/files/AlignedNorm_CN.pdf
只优化结果,为什么不够?
应对 BNT 的常见思路,是先定义一个兼顾适应性与泛化性的理想微调结果,再据此设计正则项或模型结构。然而,仅凭可见类别,很难推断未见类别应当到达怎样的理想终点;在开放场景中,也很难假设外部教师模型或类别身份先验总是可用。
AlignedNorm 不再直接预测这一终点,而是将提示微调在特征空间中诱导的整体变化建模为提示场。提示场描述特征空间不同位置上的变化方向和作用强度。当这种整体变化在可见与未见类别之间保持耦合,并同时为二者带来正向增益时,就形成了耦合提示场(Coupled Prompt Field,CPF)。
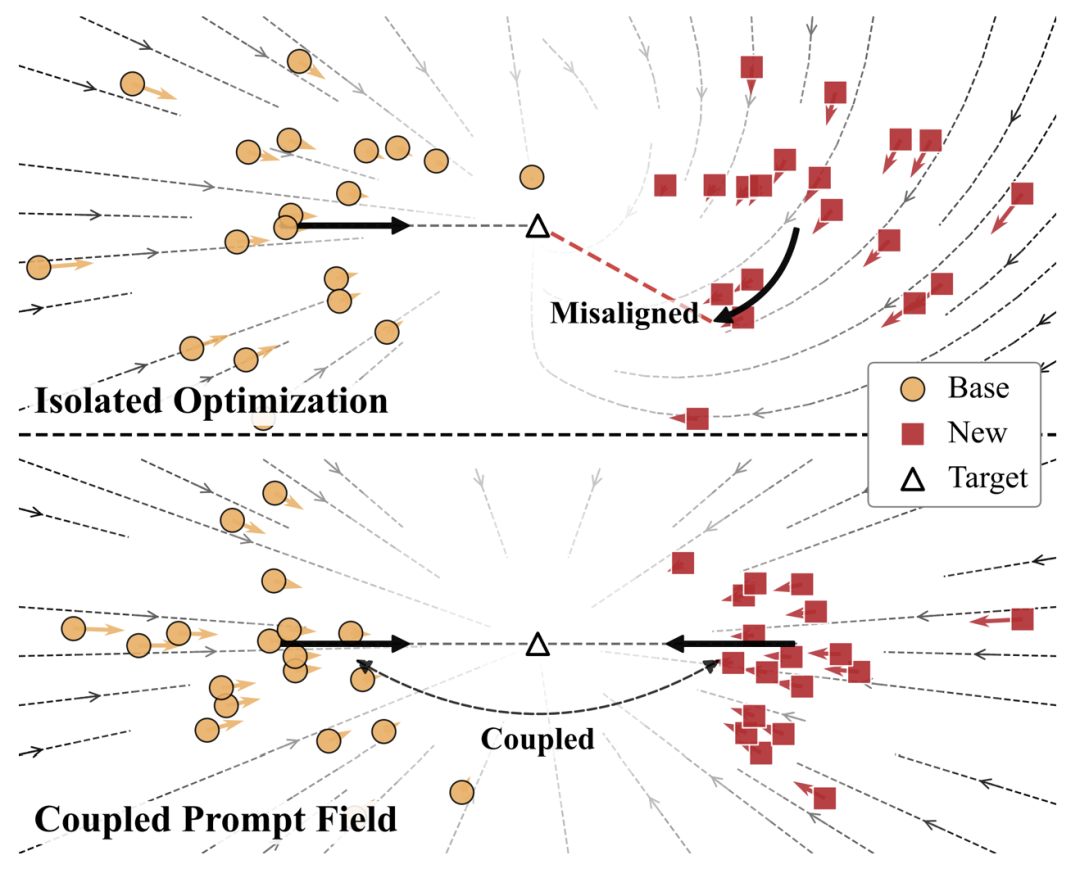
孤立优化为不同类别寻找目标位置;耦合提示场关注能否共享同一变化规律。
从结果对齐到提示场约束
现有正则方法通常约束微调特征与可靠参考表征之间的角度关系,使微调结果向预训练模型或教师模型提供的目标对齐。其核心仍是定义并约束理想的微调结果,而不是直接建模提示微调在特征空间中诱导的整体变化。
从 CPF 的视角看,泛化的关键不只是单个特征能否到达理想位置,还在于特征之间的相对关系能否得到协调,从而使提示场在不同类别之间保持耦合。然而,现有方法主要约束特征与参考表征之间的对齐,对于如何有效约束整体的相对关系,仍缺乏合适的工具。
针对这一问题,理论推导表明,在 CPF 的定义下,特征范数(Norm)是影响特征间相对关系和提示场耦合的关键因素之一。它不仅影响提示场的尺度,还会影响优化稳定性和中间层的注意力交互。具体而言,缺少范数约束会从三个方面影响提示场及其优化过程:
- 跨类别的尺度一致性:范数异常将导致同一提示场对不同类别产生不同强度的修正,破坏全局耦合的一致性;
- 更新敏感性:梯度和随机噪声更容易被范数异常放大,使提示场对有限训练数据和随机优化扰动更加敏感;
- 全局信息交换:范数异常容易使注意力分数进入饱和状态,进而阻碍全局信息交换,引发纠缠坍塌(Entanglement Collapse)。
这些分析表明,显式控制特征范数是约束提示场、促进跨类别耦合的一种有效方式。
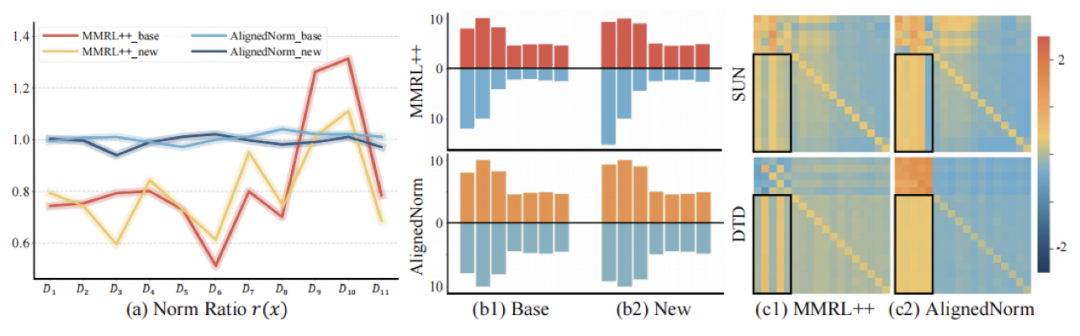
(a):AlignedNorm 缩小了可见与未见类别的范数比差异;(b):提示向量与类别标记的尺度更加一致;(c):提示向量与其他标记之间的注意力交互得到改善。
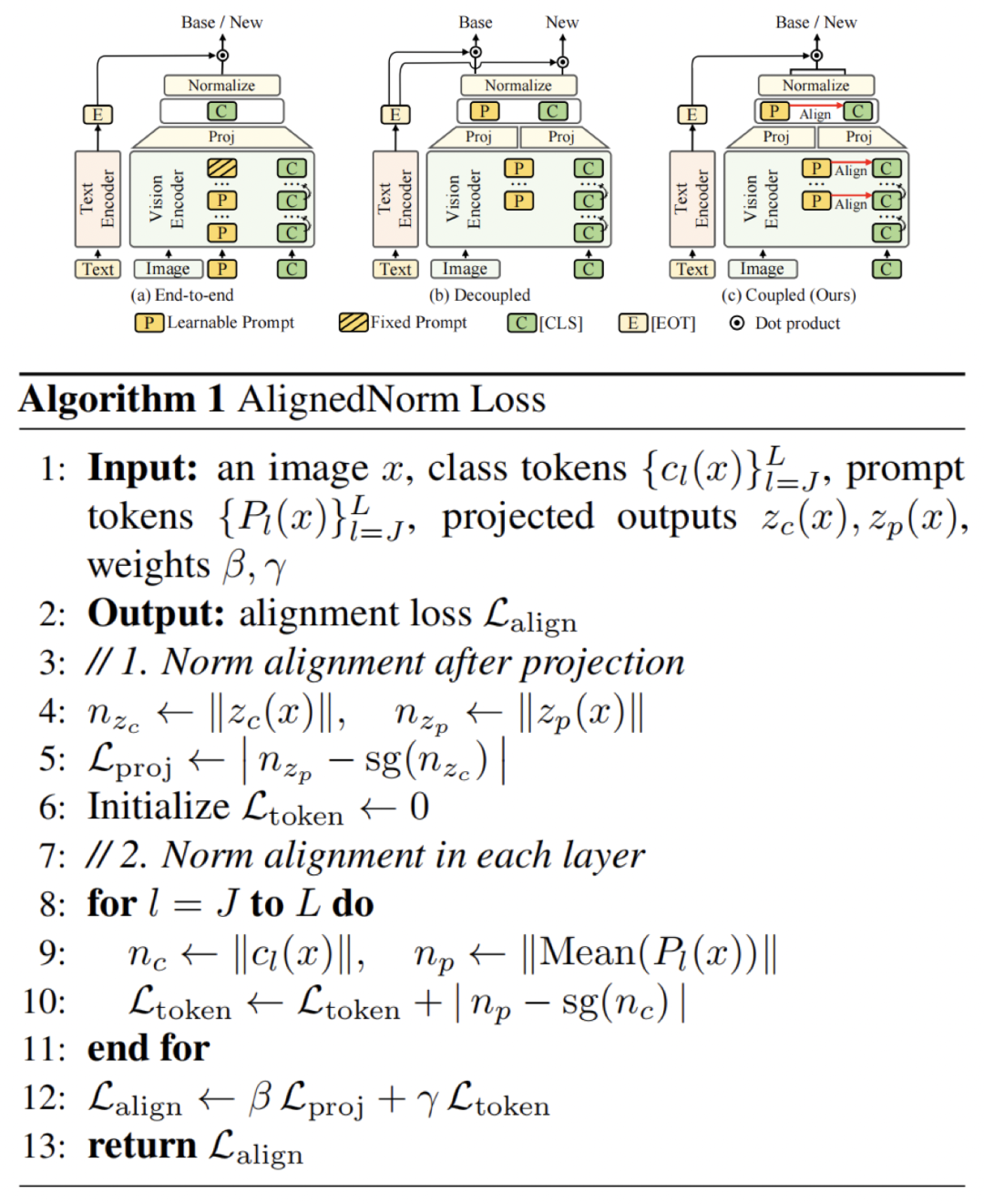
两级范数对齐
基于上述分析,AlignedNorm 提出了两级范数对齐机制:
- 编码层范数对齐 在每个注入了提示向量的 Transformer 层中,以 [CLS] 表征为参考,约束提示向量的尺度,从而维持中间层的信息交换。
- 投影层范数对齐 在特征进入图文共享空间之后、归一化之前,对齐提示向量与 [CLS] 表征的范数,从而稳定最终的提示场。
参考尺度动态地来自对应表征,而非人工设定的固定常数。这种设计在抑制尺度漂移的同时,不直接限制提示向量需要学习的具体内容。两种对齐机制仅在训练阶段生效,不增加可学习参数和推理开销。
实验结果
如果过程泛化能够带来更可靠的结果泛化,应当表现为三个方面:同一推理规则能够兼顾可见与未见类别,模型原有的特征结构得到较好保持,并且这种收益能够延伸到类别泛化之外的迁移场景。
AlignedNorm 在 15 个分类数据集、4 类评测设置下进行了实验:
在可见到未见泛化任务中,解耦类方法在不使用外部参考的方法中表现最为突出。然而,这类方法在推理时假设已知待测样本属于可见类别还是未见类别。移除这一假设后,其泛化性能大幅下降。在统一推理设定下,AlignedNorm 的平均 Base / New / HM 达到 85.46 / 77.79 / 81.45。相比 MMRL++ 的统一推理版本,Base 基本保持稳定,New 提升 1.31 个百分点,HM 提升 0.74 个百分点。
除准确率外,AlignedNorm 的均匀性(Uniformity)更接近原始 CLIP,同时保持了与 CLIP 相当甚至更高的容忍度(Tolerance),说明模型在全局分布均匀性与同类样本聚合性之间保持了更好的平衡。
在跨数据集迁移、小样本学习和域泛化中,AlignedNorm 同样取得了更优或相当的结果,说明其收益并不局限于可见到未见泛化设置。
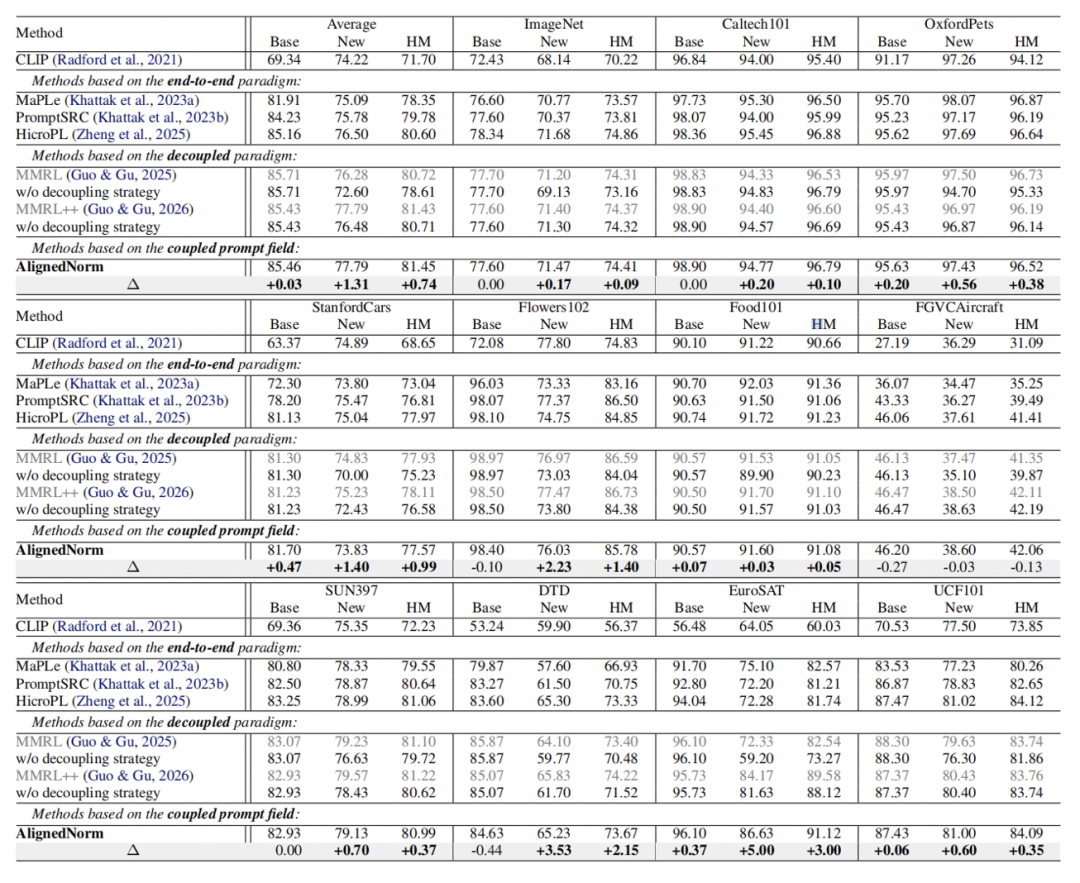
可见到未见泛化结果
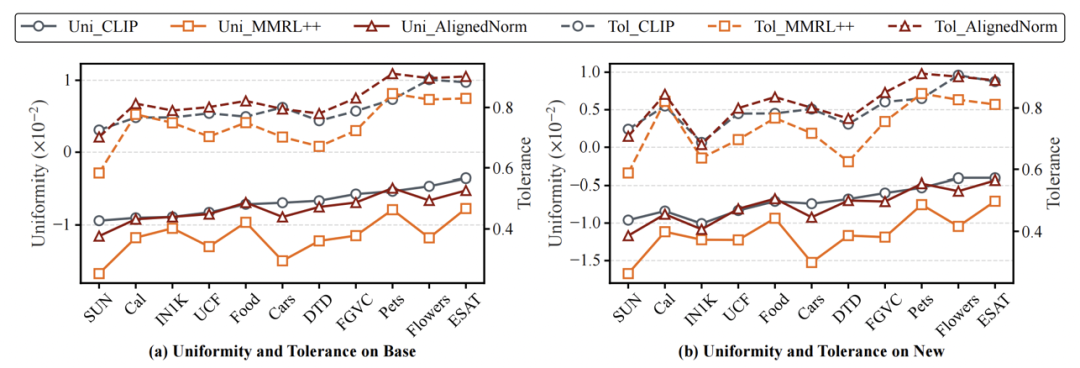
均匀性(Uniformity)和容忍度(Tolerance)
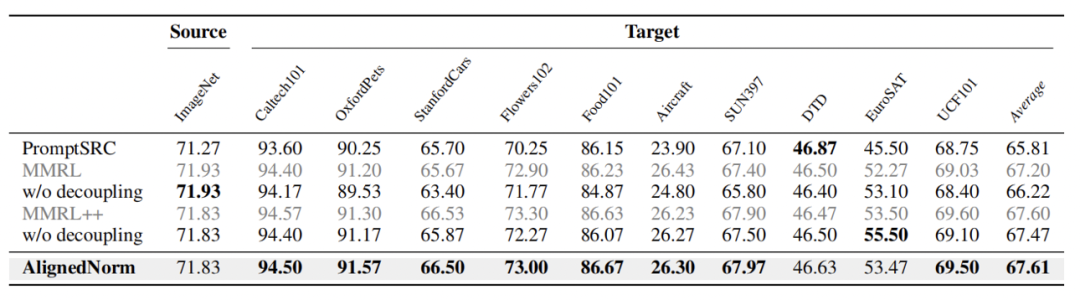
跨数据集迁移结果
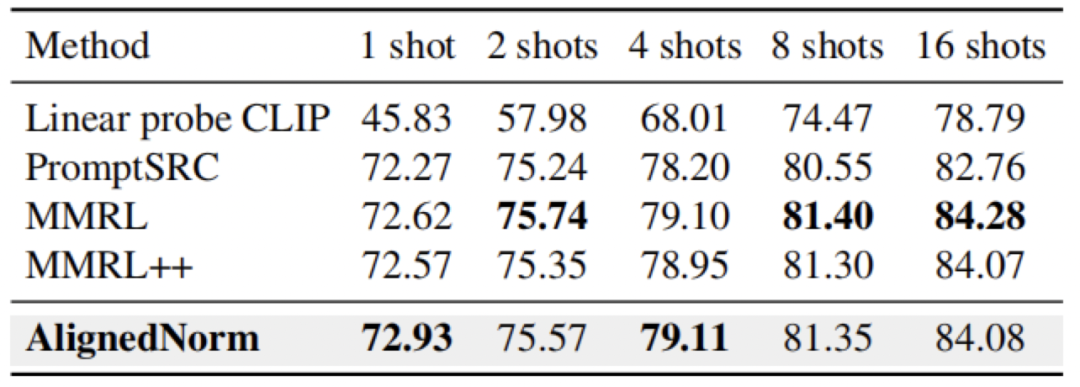
小样本学习结果
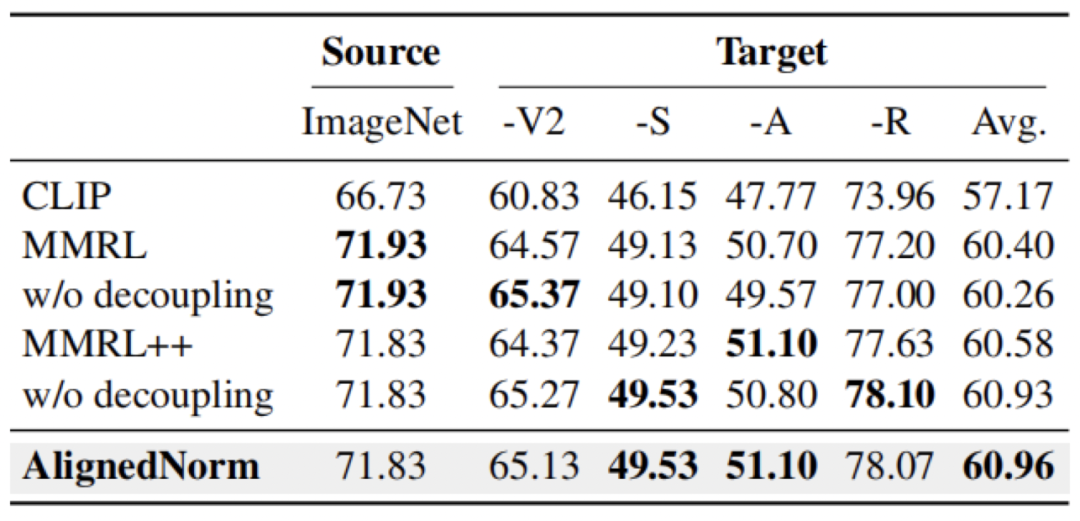
域泛化结果
消融结果表明,两级范数对齐协同使用时效果最佳。相较于统一推理基线,单独使用编码层对齐会使 Base 和 New 性能同时下降;投影层对齐提供主要收益,编码层对齐则在此基础上通过改善中间层信息交换进一步增益。
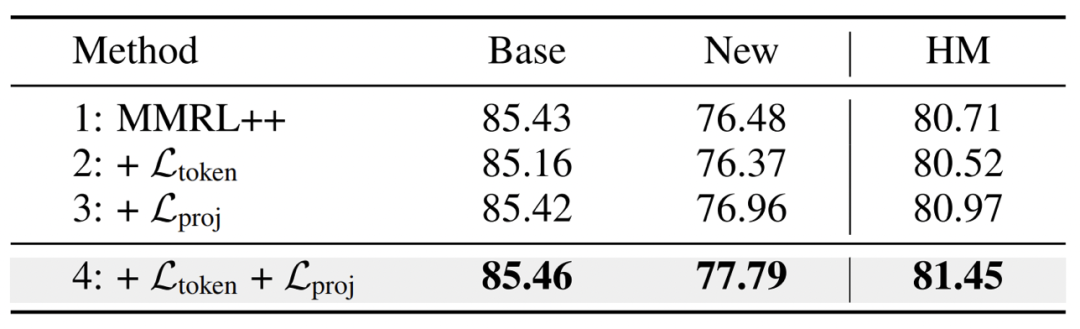
消融实验表明两种范数对齐机制具有协同效应
结语:过程泛化才是真泛化
AlignedNorm 并非只是提出一种用于提升指标的正则化损失,其核心思想是避开对开放场景下难以刻画的微调结果进行建模,转而建模微调所诱导的提示场。实验结果进一步表明,范数是影响提示场耦合的重要因素之一,显式范数约束为改善这种耦合提供了一条简单有效的路径。
AlignedNorm 带来的启示是:泛化不应只被理解为在某组未见数据上获得更高的最终指标,还应追问产生这一结果的变化规律能否作用于未见类别,并在不同迁移场景中保持稳定效果。“过程泛化才是真泛化”并不是否认结果指标,而是强调可靠的结果泛化应当建立在可迁移的变化规律之上。
作者简介
论文第一作者为南开大学计算机学院视觉计算与智能感知实验室(VCIP)2024 级博士生马琦,通讯作者为南开大学范登平教授。南开大学王晨洋和西北工业大学高德宏副教授共同参与了该项研究。研究团队长期聚焦多模态模型、参数高效微调与泛化等领域。
本文系学术转载,如有侵权,请联系CVer小助手删文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号