Nat. Rev. Bioeng.|机器学习驱动抗体多目标设计与优化

Nat. Rev. Bioeng.|机器学习驱动抗体多目标设计与优化

DrugOne
发布于 2026-07-03 17:45:38
发布于 2026-07-03 17:45:38
近日,美国密歇根大学Peter M. Tessier团队在《Nature Reviews Bioengineering》发表综述文章,题为“Multi-objective antibody design and optimization using machine learning”。文章系统梳理了人工智能与机器学习在抗体工程中的应用进展,重点讨论如何在亲和力、特异性、多反应性、稳定性、聚集倾向、免疫原性和表达量等多个目标之间实现协同优化,并进一步展望了从头设计多参数优化抗体的可能路径。

背景
治疗性抗体是当前生物医药领域最重要的药物类型之一,已广泛应用于肿瘤、自身免疫疾病、感染性疾病等治疗场景。传统单克隆抗体凭借高亲和力和高特异性成为抗体药物的主流形式,而单域抗体、双特异性抗体和多特异性抗体等新型分子形式,也正在扩展抗体药物可作用的靶点空间和治疗机制。例如,VHH纳米抗体由于分子量小、结合表面凸出,可识别常规抗体难以进入的隐蔽表位;双特异性抗体则可同时识别两个靶点或介导免疫细胞与肿瘤细胞形成特定空间构型。
然而,抗体药物开发并不是只要“能结合靶点”即可。一个具有临床转化潜力的抗体候选物,往往需要同时具备高亲和力、高特异性、低非特异性结合、低自结合、良好热稳定性、低聚集倾向、较高溶解度、可接受的黏度、较低免疫原性以及较好的表达和生产属性。任何一个性质出现明显短板,都可能在后续工艺开发、制剂、药代、安全性或临床给药阶段带来风险,甚至导致项目终止。
更棘手的是,这些性质之间往往存在相互牵制。提高亲和力可能伴随更强的非特异性结合或自结合;提升人源化程度可能牺牲结合活性;增强稳定性和溶解度也可能改变抗原结合区域构象。因此,抗体优化本质上是一个典型的多目标优化问题,而非单一指标最大化问题。
AI和机器学习重塑抗体多目标优化流程
传统抗体发现主要依赖杂交瘤、单B细胞筛选、噬菌体展示、酵母展示、核糖体展示或哺乳动物细胞展示等技术。这些方法能够从大规模文库中筛选结合分子,但往往在后期才对候选抗体进行可开发性评价。若此时发现候选分子存在高聚集、低溶解度或高非特异性结合等问题,就需要重新进行优化,增加时间和成本。
AI/ML将可开发性考虑提前嵌入抗体发现和优化流程。一类方法通过抗体子库构建、高通量筛选、深度测序和机器学习建模,将实验数据转化为可预测的序列-功能关系。另一类方法则基于结构、能量函数、语言模型或逆折叠模型,直接预测具有更优多参数组合的抗体变体。随着蛋白语言模型、抗体专用语言模型、逆折叠模型和扩散模型的发展,计算方法不仅能在已有抗体基础上做优化,也开始进入从头设计阶段。
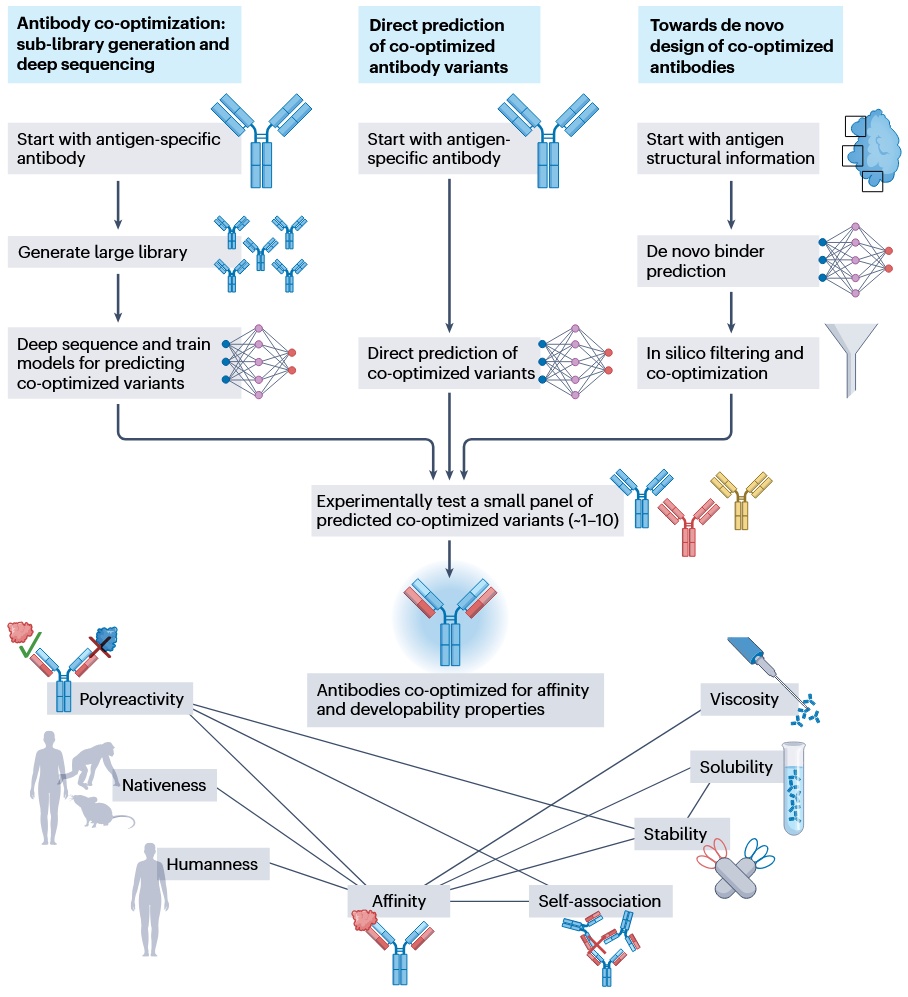
图1 概括了AI/ML驱动抗体多目标优化的三类路径:第一,通过子库生成和深度测序优化已有抗体;第二,直接预测具有共优化性质的抗体变体;第三,面向从头设计,生成同时兼顾功能和可开发性的抗体分子。
子库生成与深度测序:在更大突变空间中寻找Pareto最优解
文章首先介绍了通过实验子库与机器学习结合优化已有抗体的策略。以曲妥珠单抗为例,研究人员随机多样化其重链CDR3区域,通过荧光激活细胞分选获得高亲和力和低亲和力群体,并进行深度测序。测序得到的富集比可用于训练模型,预测哪些变体具有接近或优于亲本抗体的结合能力。随后,预测候选还可进一步按净电荷、疏水性、溶解度和免疫原性等指标过滤,从而实现亲和力与可开发性之间的联合筛选。
另一个典型案例是emibetuzumab。该抗体处于临床阶段,但具有较高非特异性结合。研究人员围绕重链CDR中溶剂暴露、富含疏水或正电荷的位点构建突变文库,通过抗原结合和多反应性筛选获得数据,再训练线性判别分析模型预测亲和力与多反应性。模型不仅能够区分高低亲和力和高低多反应性,还能沿Pareto前沿寻找在亲和力和低多反应性之间取得更优平衡的变体。该研究显示,结合深度测序与机器学习,可以在传统筛选难以覆盖的突变空间中发现超越原有权衡边界的候选抗体。
在亲和力与“自然性”共优化方面,研究人员还利用抗体语言模型对曲妥珠单抗变体进行评分。模型先在大规模天然抗体序列数据库Observed Antibody Space上预训练,再用抗体结合实验数据微调,用于预测突变体亲和力;同时,语言模型输出的自然性评分可作为免疫原性、表达和其他可开发性属性的间接指标。结合遗传算法后,模型能够在数百万级突变组合中快速找到同时具备高亲和力和高自然性的候选序列,接近穷举搜索效果,但所需评估序列数量大幅减少。
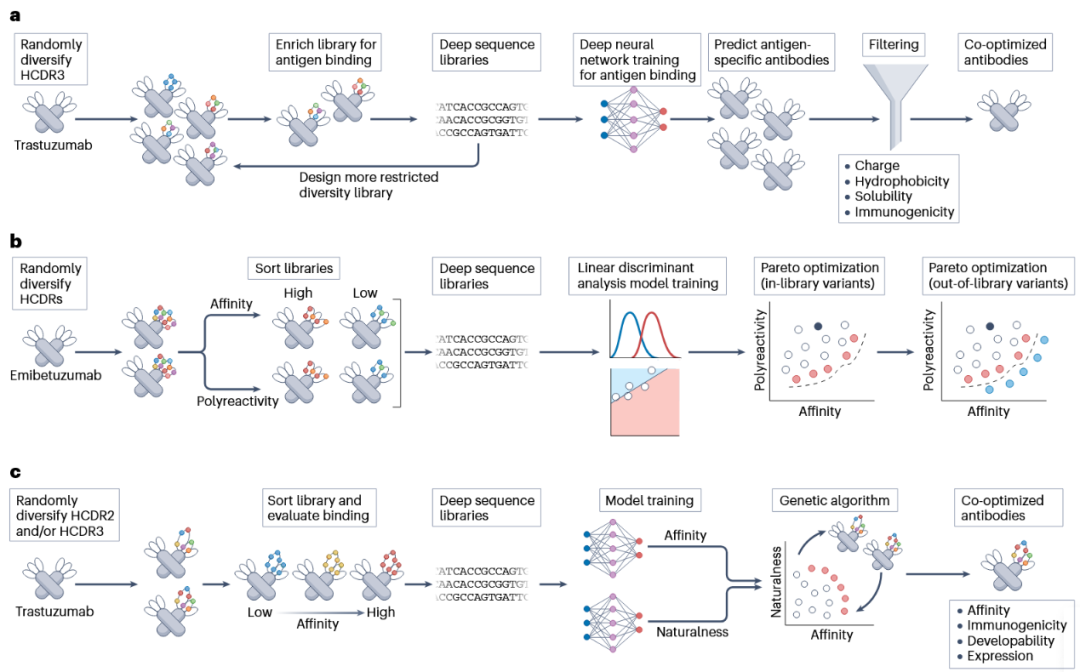
图2 展示了这类“子库-深测序-机器学习”策略如何在CDR突变空间内实现亲和力、特异性、自然性和可开发性的联合优化。
直接预测共优化抗体:从人源化到可开发性改造
第二类策略不依赖每次都重新生成大规模子库,而是直接利用结构、能量函数或可解释机器学习模型预测更优变体。人源化是非人源抗体进入临床前的重要步骤。传统CDR移植方法将非人源CDR嫁接到人源框架上,以降低免疫原性,但可能牺牲亲和力或稳定性。CUMAb方法通过组合人源V和J基因构建大量潜在人源框架,再将目标抗体CDR嫁接其上,并用Rosetta全原子能量函数评估CDR-框架结构兼容性。该方法在人源化4个鼠源抗体时,获得的候选物均保持相似结合亲和力,并具有与亲本相当或更高的折叠稳定性。进一步的特异性决定残基移植策略可提高序列人源性和生物物理性质,但可能付出亲和力下降的代价,也再次体现了多目标权衡的本质。
在降低自结合和非特异性结合方面,研究人员测量了80个临床阶段抗体的相关性质,并利用结构特征训练可解释机器学习模型。模型随后用于指导对高自结合或高非特异性结合抗体的突变设计,且避开直接参与抗原结合的表位区域。实验验证显示,多位点变体普遍降低了自结合和/或非特异性结合,其中17个变体中有12个被归为共优化抗体,9个保持了与亲本相当或更好的亲和力。这类方法的重要意义在于,它不仅给出候选突变,还能以可解释的结构特征帮助研究者理解为何某些表面电荷或疏水斑块会带来可开发性问题。
此外,文章还讨论了稳定性和溶解度共优化。高浓度制剂对于皮下注射等给药方式至关重要,但一些抗体由于溶解度低或稳定性差,难以达到超过100 mg/ml的浓度。通过CamSol、FoldX、位置特异性评分矩阵等工具,可识别影响溶解度或稳定性的残基,并预测可同时改善两类性质的突变组合。
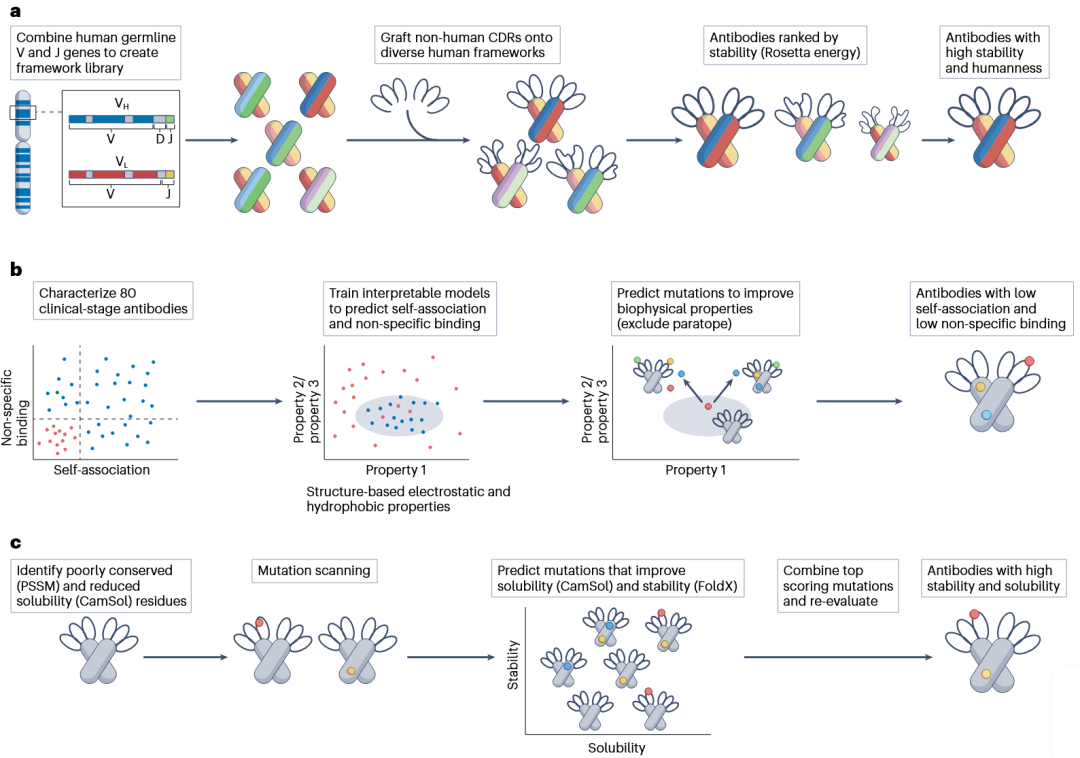
图3 总结了直接预测共优化抗体变体的代表方法,包括CUMAb人源化、基于临床抗体数据训练的自结合/非特异性结合预测模型,以及稳定性和溶解度联合改造流程。
从头设计抗体:AI正在打开难靶点抗体发现的新入口
从头设计是面向特定靶点设计新的CDR或可变区序列。对于GPCR、离子通道、多跨膜蛋白等高价值难靶点,从头设计尤其具有吸引力。这些靶点胞外可结合区域有限,构象维持困难,传统免疫和展示筛选成功率较低,因此计算生成抗体有望提供新路径。
文章介绍了三类代表性策略。第一类是基于已有抗体的计算设计和过滤,用于优化SARS-CoV-2受体结合域抗体。研究人员结合数据库扫描、逆折叠模型、蛋白语言模型和Rosetta评分生成候选变体,并通过Therapeutic Antibody Profiler过滤潜在可开发性风险。结果显示,语言模型策略设计的12个变体均降低了聚集倾向,其中10个热稳定性提高,且多位点突变体保留了对多个SARS-CoV-2变体的结合能力。逆折叠模型也帮助识别了可同时结合多个病毒变体、低聚集且高热稳定的候选抗体。
第二类是片段匹配策略。该方法从PDB和结构抗体数据库中提取类似CDR的片段及其相互作用的抗原样片段,再将目标表位与这些结构片段匹配,组合生成新的CDR基序。该方法被用于设计结合人血清白蛋白和SARS-CoV-2 Spike RBD的纳米抗体,部分设计具有良好折叠和稳定性,并达到亚微摩尔级亲和力。其优势在于可在较少实验测试的条件下快速生成候选物,且可使用AlphaFold2预测抗原结构作为输入;不足在于亲和力仍需进一步优化,且能否扩展至完整Fv或多结构域抗体仍待验证。
第三类是扩散模型策略。RFdiffusion可在指定表位约束下预测抗体-抗原复合物结构,并与ProteinMPNN结合生成CDR序列。研究人员使用人源化VHH框架针对6个不同靶点生成de novo VHH,通过酵母展示或表达纯化及SPR筛选候选物,最佳变体亲和力达到数十纳摩尔至微摩尔范围。虽然距离稳定生成可直接开发的药物级抗体仍有差距,但扩散模型已经显示出面向指定表位设计抗体结构和序列的潜力。
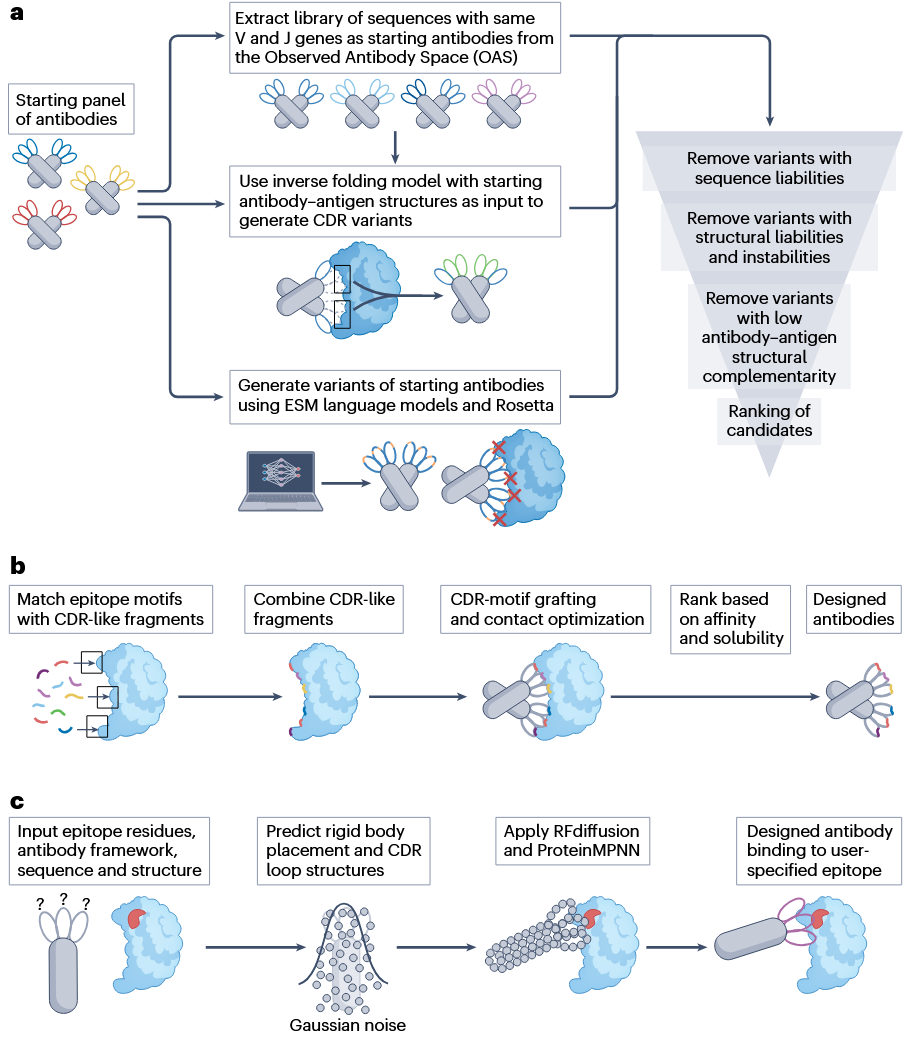
图4 总结了从头抗体设计的三种思路:基于语言模型和逆折叠模型优化已有结合抗体,基于结构片段匹配生成新CDR,以及利用RFdiffusion和ProteinMPNN进行表位定向生成。
临床转化与现实约束
AI抗体设计的价值并不只体现在算法性能上,还取决于能否进入真实研发流程。已有案例显示,计算设计已参与部分临床抗体工程。例如,bimekizumab在开发过程中使用结构与计算方法进行亲和力成熟;AU-007则体现了机器学习与实验数据迭代结合的设计理念,并已进入II期临床研究。这些案例说明,AI/ML方法并非停留在概念阶段,而是正在逐步融入抗体药物开发。
不过,模型开发本身也有成本。抗体研发成本高昂,据估计,每个获批药物研发成本可达13亿美元,其中临床前研发约4.3亿美元,临床研发约9.65亿美元。AI模型虽然有望降低筛选和优化成本,但也需要高质量数据、计算基础设施和具备交叉能力的研究团队。蛋白语言模型、逆折叠模型和抗体结构预测模型通常需要GPU训练,耗时可从数小时到数周不等。更重要的是,一些抗体性质如黏度、溶解度、聚集、药代动力学等难以在大规模上测量,仍然缺乏足够适合模型训练的数据。
总结
未来,该领域仍需解决几个关键挑战。首先,需要更多高质量、可共享、正负样本平衡的数据集,尤其是覆盖可开发性和体内性质的数据。其次,从头设计方法需要在更多靶点上公开验证,特别是GPCR、离子通道等复杂膜蛋白靶点。再次,模型不能只优化亲和力,还应系统纳入聚集、黏度、稳定性、免疫原性、表达和药代等多维目标。最后,计算科学家和实验科学家需要共同设计数据生成流程,让实验数据真正服务于模型训练、验证和闭环优化。
总体来看,AI不会取代抗体工程中的实验筛选,而是正在改变实验筛选的组织方式。它让研究者能够更早、更系统地评估候选抗体的多维属性,并在更大的序列和结构空间中寻找更接近临床需求的设计方案。随着数据共享、模型验证和实验闭环不断完善,机器学习驱动的多目标抗体设计有望成为下一代抗体药物研发的重要基础设施。
参考链接:
https://doi.org/10.1038/s44222-026-00444-4
--------- End ---------
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号