00-第三组导读-推理如何嵌入训练

00-第三组导读-推理如何嵌入训练

anzhsoft
发布于 2026-07-03 17:13:49
发布于 2026-07-03 17:13:49
第二组把算法从名字翻译成了工程合同:数据入口给出 raw_prompt、reward_model和 extra_info,reward 形成 token 级训练信号,PPO/GRPO/DAPO/KL/clip/entropy 决定 actor 如何被更新。到这里,读者已经能判断“训练目标是否成立”。第三组要继续回答另一个问题:这些训练目标依赖的 response,是如何在训练系统里被推理服务生产出来的?
这一组的核心判断是:rollout 不是训练脚本里的一次 model.generate(),而是 RL step 内部的推理服务层。它决定样本能不能按时生成,决定生成结果能不能重新进入 DataProto,也决定训练权重、KV cache、后端引擎和 agent loop 如何被串成一个训推闭环。
先看承接关系。读这张图时注意:第二组关注训练信号是否可信,第三组关注这些信号上游的 response 是否能由一个可调度、可同步、可复用显存的推理系统持续生产。
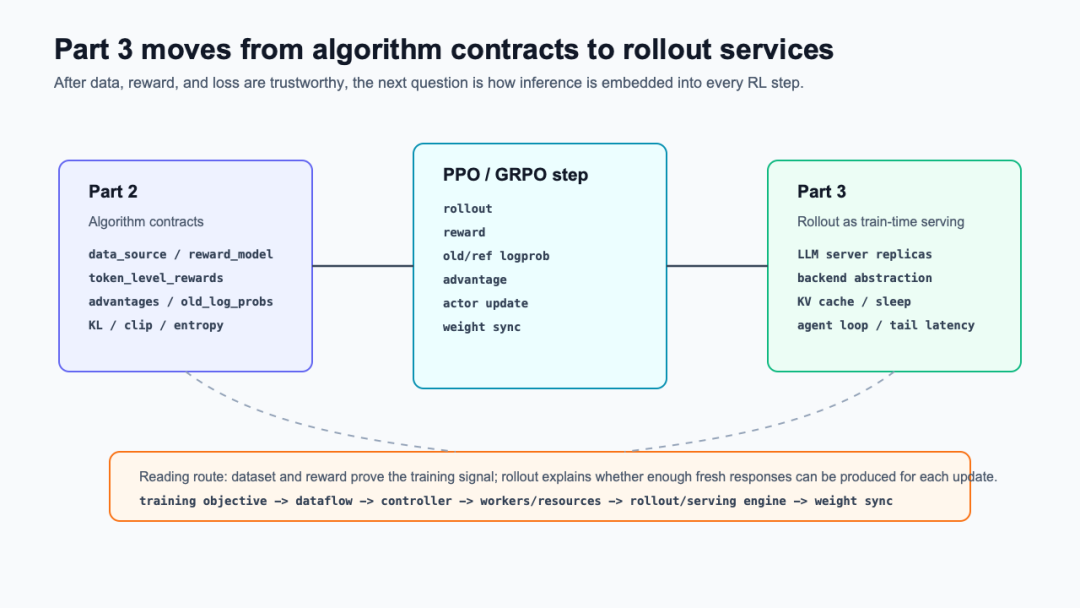
从算法工程合同到 rollout 推理服务
这张图对应的主源码路径仍然回到 RayPPOTrainer.fit():主循环把 batch 包成 DataProto,生成 gen_batch,按 rollout.n扩展请求,调用 async_rollout_manager.generate_sequences(),再把生成结果并回训练 batch(verl/trainer/ppo/ray_trainer.py:1343-1409)。第三组会把这个 generate_sequences()背后的服务层拆开。
1. 为什么算法合同之后必须看 rollout
第二组说明了 reward、advantage 和 loss 如何塑造训练方向,但这些机制都有一个共同前提:系统必须先生成足够多、足够新、字段完整的 response。GRPO 要同一 prompt 的多条 response 做组内比较,DAPO/Dr. GRPO 会放大 response length 的影响,reward manager 依赖 data_source、reward_model、extra_info,这些都把压力推回 rollout。
因此,第三组不把 rollout 当成“推理引擎选型”来写,而是把它放回训练系统:controller 什么时候发起生成?rollout server 如何接 request?vLLM、SGLang、TRT-LLM 如何被统一成一个接口?KV cache 和 sleep/resume 为什么会影响训练吞吐?多轮 agent 和工具调用又如何让“生成一次 response”变成“驱动一段轨迹”?
2. 第三组的六篇文章各自解决什么
第 13 篇《Rollout:训练系统里的推理服务》先把 rollout 放回一轮 PPO/GRPO step。它解决的问题是:为什么生成阶段不是附属步骤,而是决定 RL 吞吐、样本形状和后续 reward/logprob 的服务边界。
第 14 篇《vLLM、SGLang、TRT-LLM 在 verl 里如何被抽象》继续拆 backend。它解决的问题是:trainer 为什么不直接依赖某个推理引擎 API,而是通过 rollout.name、BaseRollout、server manager、replica 和 backend adapter 形成一层薄抽象。
第 15 篇会进入《KV Cache、sleep/resume 与显存复用》。第 13、14 篇会证明 rollout 是训练内的推理服务,15 篇则解释训推共卡时,为什么显存状态切换会成为系统设计的一等问题。
第 16 篇会写《Agent Loop:为什么 RL 训练需要 token-in/token-out》。当 rollout 不再只是单轮补全,而是多轮工具交互,系统要保留的不只是 response,而是 request state、message、tool schema、mask 和 token 边界。
第 17 篇会写《Tool Calling 和 Sandbox:环境如何成为 reward 的一部分》。它会把工具、环境、轨迹和 reward 接起来,说明 agentic RL 中“环境反馈”为什么不能只理解成模型外部的分数。
第 18 篇会写《长尾 rollout:为什么 agent RL 容易让 GPU 空转》。前几篇建立机制后,这一篇会回到调度和吞吐:长 prompt、长 response、多轮等待、工具耗时和异步 server 如何制造尾部延迟。
3. 阅读第三组要抓住三个边界
第一个边界是训练 batch 和推理 request。DataProto 进入 rollout 前要带着 prompt、uid、sampling 参数、reward 所需字段和多模态字段;rollout 返回后又必须形成 responses、attention_mask、position_ids、response_mask等后续训练要消费的字段。这个边界错了,reward 和 loss 再正确也没有意义。
第二个边界是统一抽象和后端差异。BaseRollout提供 resume()、update_weights()、release()和 generate_sequences()的基类合同,registry 会把 ("vllm", "async")、("sglang", "async")、("trtllm", "async")映射到不同 adapter(verl/workers/rollout/base.py:29-104)。但生成参数、logprobs、多模态、PD disaggregation、sleep/wake 的细节仍然会泄漏到 adapter。
第三个边界是训练权重和推理状态。ActorRolloutRefWorker.update_weights()明确区分 colocated sync 的 naive 路径和 disaggregated checkpoint engine 路径,并在更新前后处理 rollout weights 与 KV cache(verl/workers/engine_workers.py:663-740)。这就是第三组后半部分要继续展开的训推桥。
小结:第三组开始进入 rollout/serving engine
到第二组结束,我们已经知道训练目标、reward、advantage 和数据合同如何成立。第三组把焦点推进到系列地图里的下一段:
training objective
-> dataflow
-> controller
-> workers/resources
-> rollout/serving engine
-> weight sync
-> production train/serve system
读完第三组,读者应该能从 RayPPOTrainer.fit()里的 generate_sequences()继续追下去,知道一个 response 如何从训练 batch 变成推理 request,再从 backend server 的 token output 回到 RL 训练数据结构里。
本文源码索引
verl/trainer/ppo/ray_trainer.py:1343-1409:主循环中 DataProto、_get_gen_batch()、rollout.n、generate_sequences()和结果合并的路径。verl/workers/rollout/base.py:29-104:BaseRollout的基本接口和 async rollout backend registry。verl/workers/rollout/llm_server.py:146-220:LLMServerClient如何做请求分发并调用 server generate。verl/workers/rollout/llm_server.py:222-334:LLMServerManager如何创建 rollout replicas 和 load balancer。verl/workers/engine_workers.py:663-740:训练权重同步到 rollout 的生命周期。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号