YAML+ Markdown

YAML+ Markdown

用户11705094
发布于 2026-07-02 09:19:16
发布于 2026-07-02 09:19:16

YAML 头部 + Markdown 正文数据格式通常被称为 Front Matter(前置元数据)。
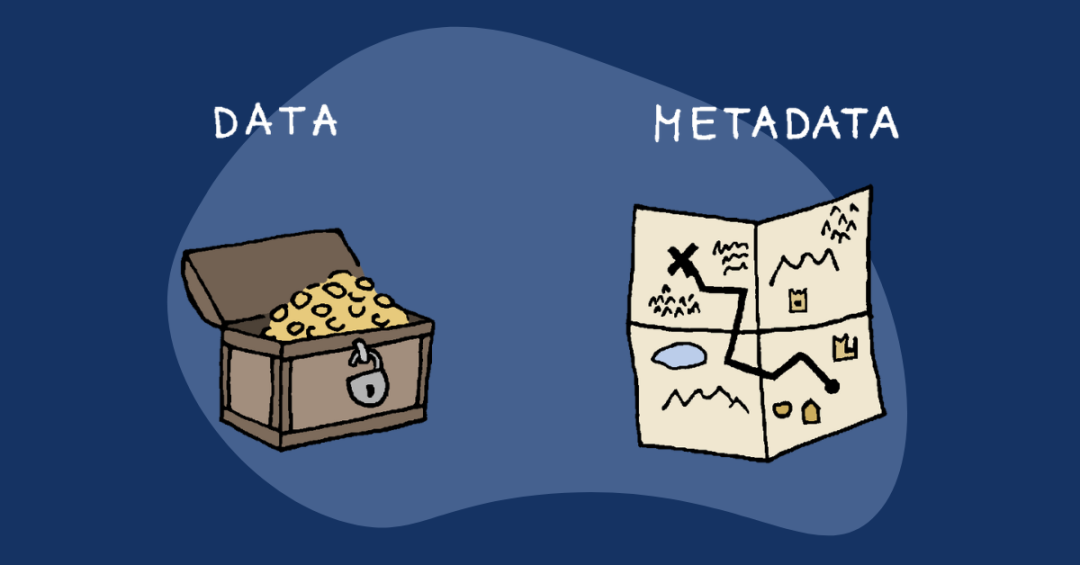
我将这种架构称为数字时代的标准集装箱,是一种静态的知识容器,目的是存储。
就像集装箱外部写着货物清单(YAML),内部装着实际货物(Markdown),这种结构完美地解决了数据管理与消费分离的问题。

它由两部分组成,上半部分是给机器(程序、AI)看的结构化数据,下半部分是给人类(或者 AI 的语义理解模块)看的自然语言内容。
中间通过三根短横线 --- 进行物理分隔。
这种架构代表了一种极简主义的技术哲学。
它通过牺牲多余的视觉修饰,换取了跨越时空的兼容性与可编程性。
它是真正意义上的数字资产,能够随着 AI 技术的进化而不断增值。

YAML 头部 (Front Matter)
这部分位于文档的最顶端。
它采用键值对的形式存储数据。
它负责定义文档的属性,例如标题、日期、作者、分类、标签,甚至是针对 AI 的特定指令。
它的存在让文档具备了数据库的特征。
由于 YAML 语法极其严谨,程序可以瞬间提取这些字段进行排序、筛选和索引。

Markdown 正文 (Body Content)
这部分紧随其后。
它负责承载具体的思想、逻辑和叙述。
它使用轻量级的标记符号来定义文本的语义层级,例如一级标题、二级标题、代码块、数学公式和超链接。
它的存在保证了内容的高度可读性。
即便是在最基础的文本编辑器中,人类也能顺畅地理解其表达的含义。
这种架构的高明之处在于关注点分离。
对于人类作者(专注内容流)
你在写作时,Markdown 的部分让你专注于叙事、逻辑和表达。
你不需要关心标题在网页上是红色还是蓝色,也不用关心这篇文章会被归档到哪个文件夹。
你只需要在头部填好 tags: NLP,系统会自动处理后续的分类。
对于软件系统(专注逻辑流)
各类工具(如 Obsidian, Hugo, Jekyll, Next.js)在读取文件时,会先“切下”头部。
系统读取 date: 2026-02-11,决定把它放在时间轴的什么位置。
系统读取 status: draft,决定不在网站上公开显示它。
系统读取 title,将其放入网页的 <title> 标签中以利于 SEO。
对于 AI 系统(专注数据流)
这是最激动人心的部分。
训练阶段:我们可以写一个简单的 Python 脚本,提取所有 tags 包含 "Tutorial" 且 complexity 为 "Hard" 的 Markdown 正文。这瞬间就构建了一个高难度技术教程数据集。
RAG阶段:当用户问“有哪些关于 NLP 的进阶教程?”时,AI 不需要扫描全文。它只需要检索向量数据库中存储的 YAML 元数据,就能瞬间定位到这篇文章,大大降低了计算成本,提高了响应速度。

为了让文档库具备长久的生命力,建议遵循以下规范:
- 保持 YAML扁平化:尽量使用简单的键值对或列表,避免在 YAML 里嵌套过深的层级,这能提高解析速度。
- 保持头部简洁:YAML 应该只包含核心的元数据,过多的描述性文字应当下放到 Markdown 正文区域。
- 标准化 Key 值:在团队内部建立统一的 YAML 字段规范,避免出现标签命名的混乱。例如,不要有的文件用 date,有的用 create_time,统一使用 date。
- 引用资源显性化:如果文章引用了其他文件,可以在 YAML 中建立一个字段 related_ids: [id1, id2]。这为 AI 建立知识图谱提供了明确的边(Edge)关系。
- 摘要前置:务必在 YAML 中包含 description 或 summary 字段。在很多场景下,AI 或搜索引擎只需要读取这 100 个字,而不需要加载几兆的正文。
- 善用 LaTeX 和代码块:在正文中使用标准符号处理复杂内容,这能确保文档在未来的跨平台迁移中保持稳定性。
案例:个人知识库(Obsidian/Notion 模式)
这是最基础的用法。
你正在写一篇关于深度学习的笔记。你希望这篇笔记既能被人阅读,又能被软件自动归类、索引。
---
# === YAML 头部 (元数据层) ===
uuid: "20250520-DL-BASICS"
title: "深度学习基础概念解析"
date: 2025-05-20
tags: ["AI", "Deep Learning", "Neural Networks"]
status: "finished"
related_notes:
- "机器学习概论"
- "反向传播算法"
aliases: ["DL入门", "神经网络基础"]
---
# === Markdown 正文 (内容层) ===
## 什么是深度学习?
深度学习是机器学习的一个子集,它模仿人类大脑的结构和功能。
## 核心组件
1. **输入层**:接收原始数据。
2. **隐藏层**:进行特征提取和数学变换。
3. **输出层**:给出预测结果。
> 关键点:深度学习的核心在于多层非线性变换。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-12,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 magicyuan的AI随笔记 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号