第二组导读:算法如何落到工程

第二组导读:算法如何落到工程

anzhsoft
发布于 2026-07-01 21:09:02
发布于 2026-07-01 21:09:02
第一组解决的是“系统怎么转”。我们从“AI 后训练不是一个训练脚本”开始,依次拆了 HybridFlow、Single Controller、ResourcePool/WorkerGroup、DataProto,最后按 RayPPOTrainer.fit()走完一轮 PPO/GRPO step。到这里,读者已经知道一轮 RL 后训练不是单次 backward,而是 rollout -> reward -> old/ref logprob -> value/advantage -> actor/critic update -> weight sync这条分阶段流水线。
第二组要解决的是“算法怎么落地”。同样叫 PPO、GRPO、DAPO、KL、reward,它们在论文里是算法概念,在 verl 代码里却会变成角色、字段、loss、mask、配置和资源路径。本文是第二组的入口:先说明它如何承接第一组,再给出这一组的阅读地图。
核心判断是:第二组不是算法综述,而是算法工程合同的走读。每一篇都要回答三个问题:这个算法概念在 fit()的哪个阶段出现?它消费 DataProto 里的哪些字段?它改变了哪个 worker、loss 或配置约束?
下面这张图把第一组和第二组接起来。看图时重点看右侧:第二组的文章不是并列讲几个名词,而是逐步拆开 actor、critic、ref、reward、advantage、KL、长度和数据入口之间的合同。
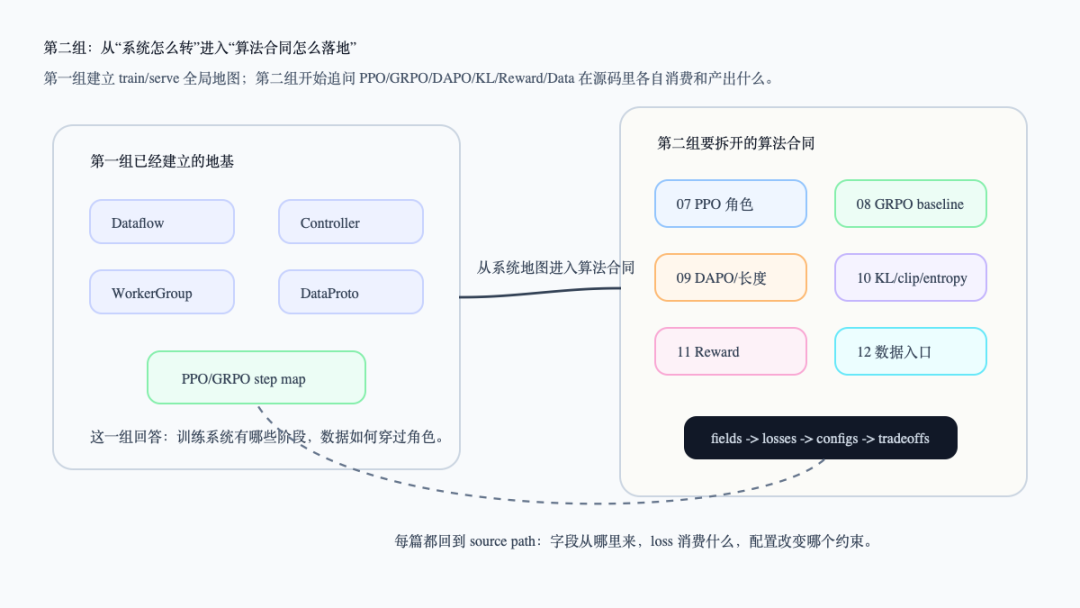
从第一组全局地图到第二组算法工程合同
这张图对应的源码主线仍然是 RayPPOTrainer.fit():它把 rollout、reward、old/ref logprob、value、advantage、actor/critic update 和 weight sync 串起来(verl/trainer/ppo/ray_trainer.py:1274-1586)。第二组只是把焦点从“阶段顺序”移到“每个算法机制在阶段里签了什么合同”。
1. 为什么第一组之后必须进入算法工程合同
只理解第一组,读者会知道系统如何跑起来,但还不能判断训练语义是否改变。比如同样是一轮 step,打开 critic 和关掉 critic 是不同的资源路径;KL 放在 reward 里和放在 actor loss 里是不同的约束位置;loss_agg_mode=token-mean和 seq-mean-token-sum-norm会改变长短 response 的权重。
这些问题不能只靠系统图回答。系统图告诉我们 DataProto 在流动,第二组要进一步问:DataProto 里的 old_log_probs、ref_log_prob、values、advantages、returns、response_mask、token_level_rewards分别被谁消费,谁对训练目标有直接影响。
所以第二组的阅读方法是:先看问题和角色,再看字段合同,最后看配置旋钮。源码事实尽量落到 ray_trainer.py、core_algos.py、losses.py、reward manager 和示例脚本。
2. 第二组的六篇文章各自解决什么
第 07 篇《PPO 在 LLM 后训练里真正训练了什么》先拆角色:actor 是被 policy loss 更新的主策略,critic 是 value baseline,reference policy 提供偏离基准,reward 提供偏好信号。它解决的是“到底谁在训练,谁只是定义训练问题”。
第 08 篇《GRPO 为什么能省掉 critic》接着拆 baseline:GRPO 不是没有 baseline,而是把 baseline 从 critic value 换成同一 prompt 的多条 response 的组内相对 reward。它解决的是“省掉 critic 的源码证据在哪里,以及代价转移到哪里”。
第 09 篇《DAPO、Dr. GRPO 与长度偏置》继续拆 GRPO 之后的新问题:省掉 critic 后,reward 形状、advantage 归一化和 loss 聚合会把 response length 变成核心变量。它解决的是“长度偏置如何从 reward、advantage、loss 三条路径进入训练”。
第 10 篇会写《KL、clip、entropy:给模型更新装限速器》。前面几篇说明了 reward 和 advantage 如何推动 actor 更新,这一篇要解释为什么还需要 KL、clip、entropy 这些稳定性机制,以及它们分别在 reward、policy loss 和 metrics 里出现在哪里。
第 11 篇会写《Reward 不是一个分数函数这么简单》。到这里我们已经知道 reward 会进入 token_level_scores和 token_level_rewards,但 reward 本身可能来自规则、reward model、sandbox、工具或环境。这一篇要把 reward 从“一个 float”拆成系统接口。
第 12 篇会写《数据进入 RL 前经历了什么》。第二组最后回到数据入口:parquet、chat template、prompt length filter、多模态字段和 reward_model 字段如何决定后面 DataProto 能不能形成正确的训练证据。
3. 这一组要避免的误读
第一种误读是把算法名当成完整解释。说“这是 GRPO”不够,还要说 rollout.n是多少,advantage 是否按 std 归一,actor loss 怎么聚合,KL 放在哪里,reward manager 是什么。
第二种误读是把所有模型都叫训练对象。PPO/GRPO 后训练里有 actor、critic、reference、reward、rollout,但它们不承担同一种职责。第 07 篇会先把这个边界定住。
第三种误读是把性能问题和算法问题拆得太干净。比如长度偏置既是 reward/advantage/loss 的训练语义问题,也是 dynamic batch、sequence balancing、rollout 长尾和 token budget 的系统问题。第 09 篇开始会反复强调这条线。
小结:第二组开始把算法名翻译成源码合同
第一组给了读者系统地图:controller 怎么调度,worker 怎么执行,DataProto 怎么流动,一轮 step 怎么完成。第二组要在这张地图上继续标注算法合同:
actor/ref/reward/critic 的职责
-> PPO/GRPO 的 advantage 来源
-> DAPO/Dr. GRPO 的长度和尺度管理
-> KL/clip/entropy 的稳定性约束
-> reward 和数据入口的系统接口
读完第二组,读者应该不只是知道“verl 支持 PPO/GRPO/DAPO”,而是能看懂这些名字在源码里分别改变了哪些字段、哪些 loss、哪些 worker,以及哪些系统瓶颈会随之移动。
本文源码索引
verl/trainer/ppo/ray_trainer.py:1274-1586:第二组所有算法合同最终回到的 PPO/GRPO step 主循环。verl/trainer/ppo/ray_trainer.py:135-230:compute_advantage()中 PPO/GRPO 等 estimator 的分支入口。verl/trainer/ppo/core_algos.py:267-331:GRPO group-relative advantage 的核心实现。verl/workers/utils/losses.py:57-144:actorppo_loss()如何消费 old logprob、advantage、mask 和 ref logprob。verl/workers/reward_manager/dapo.py:25-132:DAPO reward manager 和 overlong reward penalty。verl/trainer/config/actor/actor.yaml:81-112:actor loss aggregation 与 KL loss 相关配置。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号