12288张B300组网:1536节点RoCEv2存算分离、混合架构与CPO/LPO演进

12288张B300组网:1536节点RoCEv2存算分离、混合架构与CPO/LPO演进

AGI小咖
发布于 2026-06-29 13:53:23
发布于 2026-06-29 13:53:23
一、背景
随着大模型训练需求的爆发,单台 8 卡 B300 服务器的市面造价已从早期的 400 万人民币推高至1000万元。面对单体设备资产投入超 150 亿元(1,536台 × 1,000万元)的超大规模算力底座,如何设计一套高可用、高性价比的万卡集群组网,成为了落地交付的核心突破口。
本文重点围绕1,536 台 8 卡 B300 算力节点(例如 Supermicro SYS-822GS-NB3RT 等机型)展开,重点阐述如何搭建一个规模达 12,288 张 B300 GPU 的 RoCEv2 存算分离万卡集群,需要重点说明的是集群采用异构混合组网模式——核心计算网络选用 NVIDIA Spectrum-4 SN5600 交换机,而在后端存储网络层面则选用搭载 Broadcom 51.2T 交换芯片的 OEM 设备。单台8 卡 B300 算力节点的核心网络端口配置主要分为4种类型:
① 计算网络:主机内置 8 张 NVIDIA ConnectX-8 SuperNIC网卡,统一对外提供 8 个 800G OSFP 光口;
② 存储网络:搭载 2 张单端口 400G BlueField-3 DPU,其关键价值搭建无损存储专网,为海量多模态数据提供高效、可靠的NVMe-oF 传输;
③ 带内网络:利用服务器 OCP 3.0 扩展槽按需配置双端口 25G/100G 网卡,独立消化带内管理、K8s/Slurm 调度等高频业务流量。
④带外网络:标配 1 个 1G RJ45 电口。

二、方案设计
2.1 计算网络:对称双平面与多轨拓扑协同优化
本次万卡网络集群采用对称双平面轨道优化(Rail-Optimized)架构设计,其拓扑演进与分流策略解构如下:
2.1.1 接口拆分与轨道优化
如下组网图1所展示,每台算力节点配备的 8 个 800G OSFP 高密光口,通过底层双通道技术被逻辑剥离为 16 个 400G 独立端口,随后对称映射至完全物理隔离的 Plane A 和 Plane B 双平面中。在单平面架构内部, 8 条独立轨道(Rail 1--8)与底层 GPU 硬件建立了高亲和属性的强拓扑映射。整套多轨拓扑规划的核心出发点,就是为了在软硬件底层锁死流量边界,从而完美支撑起智算网络内部两级平面流量的精准分流。
对于机内的 Scale-Up 域而言,张量并行与序列并行(TP/SP)流量对时延的挑剔程度几乎到了极点,我们将TP/SP流量直接交由双向带宽高达 14.4 TB/s 的本地 NVLink 5.0 域进行底层硬件卸载,强行在节点内部完成数据闭环,绝不占用宝贵的外部网卡带宽。
而一旦流量跨出节点来到 Scale-Out 域,情况则完全不同。说白了,要把万卡规模的 All-Reduce 大带宽集合通信性能跑满,最关键的就是让跨机流量别瞎跑。本方案引入分层拓扑感知调度机制,确保跨节点通信序列严格限制在同一轨道内。此举使得同轨 RDMA 流量仅需在首层 Leaf 交换机处进行单跳接入即可构建高效的通信环路,从架构源头上杜绝了跨轨道流量引发的 Spine 层拥塞与长尾延迟。
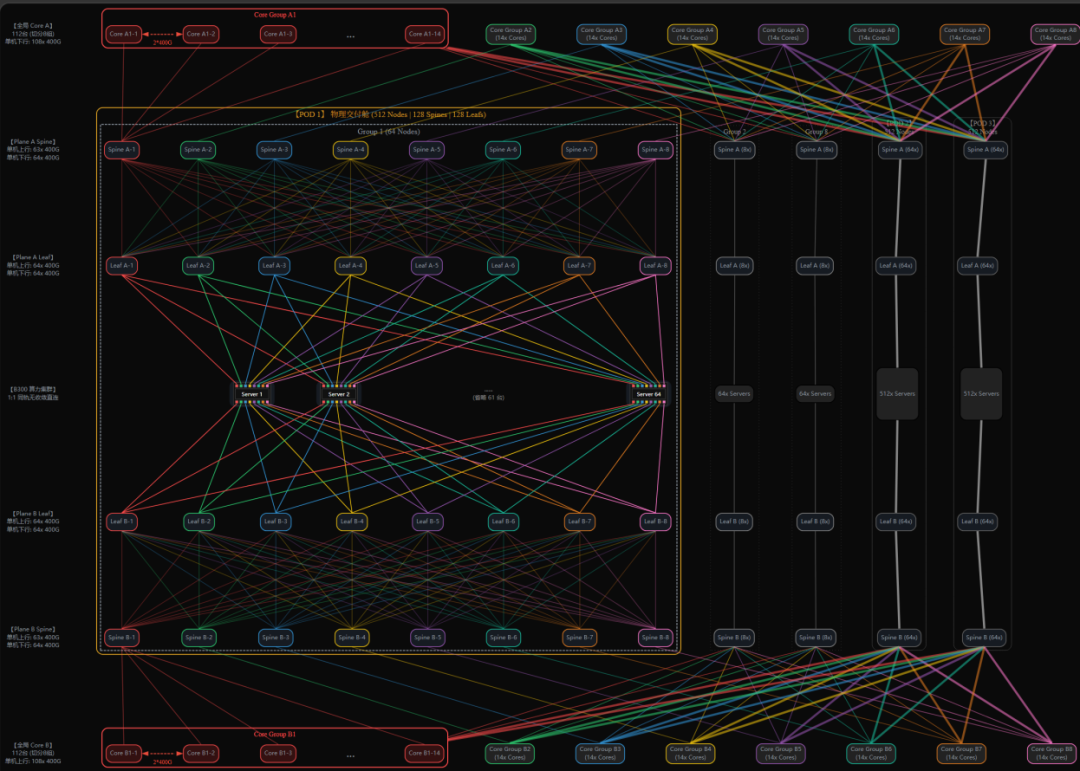
2.1.2 三级 Clos 拓扑与1:1无收敛设计
要拉起一个承载 1,536 个节点、总计 12,288 张 B300 GPU 的万卡存算分离矩阵,网络平面的选型必须足够硬核。为此,计算网络层面我们选用NVIDIA Spectrum-4 SN5600 以太网交换机(标配 64 个 800G OSFP 物理端口,可通过一分二物理线缆灵活拆分为 128 个 400G 端口)来构建1:1 线速无收敛的三层 CLOS 计算通信平面,如下图2所示以Plane A为例自下而上剖析三层CLOS架构组成:
先看 Leaf 层(共 384 台):全局划分为3个POD(每个POD包含512节点),每个POD下设8个SU(每个SU包含64节点)。以Plane A为例,在单个POD中配置64台Leaf交换机,每台Leaf利用自身的64个400G下行端口直连本SU内64台服务器的同轨网卡,剩余64个400G上行端口则悉数推向Spine层,实现1:1无收敛的数据转发。
再往上走是 Spine 层(共 384 台):同样以Plane A为例,单个POD配置64台Spine,每条轨道部署8台来实施同轨Full-Mesh交叉互联策略——也就是说,任何一台 Leaf(比如 Leaf A-1)向同轨内的 8 台 Spine(如图中的 Spine A1--A8)各拉出 8 根 400G 光纤。往上看每台Spine的64×400G下行端口汇聚Leaf流量,再腾出剩余的 63 个 400G 上行端口对接全局 Core 层。
顶层则是 Core 层(共 224 台)与非对称拓扑下的动态包级喷洒:Plane A 与 B 各配置 112 台(分为 8 轨,每轨14台)。展开看单轨的微观链路,3 个 POD 内部一共产出了 24 台 Spine,每台吐出 63 条上行链路;与之对齐,单轨里的 14 台 Core 交换机,每台提供 108 条下行链路。
必须要指出来的是,面对 Spine 上行 63 口无法均分给 14 台 Core 层交换机,这势必引发行业内棘手的“非对称条带化互联”(实际工程中表现为 4+5 的非均衡连线拓扑),加之集群在承载混合 MoE 架构专家并行(EP)All-to-All 突发流量时的“哈希极化”效应、集合通信长尾延迟问题。
为了应对上述挑战,本方案充分利用 NVIDIA Spectrum-4 SN5600 原生内置 160MB 全局共享单片缓冲区,通过全量激活自适应路由(Adaptive Routing, AR)与细粒度路由(Fine-Grained Routing, FGR)两大特性,促使交换机底座完全摆脱了物理层非对称链路的不均束缚。具体来看,网络内部的 GPU 通信以“数据包(Packet)”为最小调度颗粒,交换芯片得以实时高频感知单轨内 14 台 Core 交换机各物理路径的实时队列深度,将传统哈希极化下的庞大“大象流”智能拆解,实时、均匀地喷洒至微秒级视界中最空闲的物理路径中,大幅度释放了万卡集群的并发训练吞吐率。

2.1.3 光模块与光纤通信设计
首先看底层的接入层平面(算力节点/数据处理器(DPU)到 Leaf 组网,距离在 50 米以内):采用 800G(2×400G-SR4/VR4)双通道短距多模链路方案,利用 MPO APC(Base-8)多模跳线实现高容错、低功耗的本地无损入网。
再往上看,进入 POD 内部的汇聚层(Leaf 到 Spine 组网,距离同样在 50 米以内):采用 800G(2×400G-SR4/VR4)双通道多模光模块配合 2×MPO APC(Base-8)多模线缆,最大化利用 NVIDIA Spectrum-4 SN5600交换机的原生高密 800G 端口,大幅优化了机柜走线的空间占用率。
最后,是跨 POD 的骨干层长距互联(Spine 到全局 Core 组网,距离超过 50 米):采用 800G(2×400G-DR4)单模光模块、配合 2×MPO APC(Base-8)单模硅光线缆来构建跨机房的长距高速物理互联,直接承载全局自适应路由(AR)在跨 POD 大交叉时的高速包级流量。
无论属于哪一层级,全网所有物理链路的连接端面强制采用8度斜面物理接触 (Angled Physical Contact, APC) 端面,有效避免高功率光信号反射导致的链路微小抖动与优先级流量拥塞控制。
2.2 存储网络设计
为了避免存储 NVMe-oF 流量与计算网络训练流量发生资源争抢,集群采用存算网络分离设计,即搭建完全物理独立的 RoCEv2 Lossless 无损以太网存储专网。
本方案采用搭载博通 Tomahawk 5 (TH5) 为核心交换芯片的 51.2T规格交换机,构建 Leaf-Spine 收敛比为 1:1 的无损以太存储网络,合计需要66台交换机:
Leaf接入层(共 54 台):包含48 台计算接入 Leaf 交换机与 6 台全闪存储 Leaf 交换机,采用搭载博通 Tomahawk 5 (TH5) 核心交换芯片的 51.2T OEM 交换机构建而成。单台 Leaf 交换机在逻辑上提供 128×400G 高密端口:一半端口下行接入 1,536 台 8 卡 B300 节点服务器配置的 2 张单端口 400G BlueField-3 DPU;另一半端口上行以全互联方式均匀连向 32 台存储 Spine 交换机。
Spine汇聚层(共 32 台):采用搭载博通 Tomahawk 5 (TH5) 核心交换芯片的 51.2T OEM 交换机构建而成。每台 Spine 交换机提供 128×400G 最大支持128个双向400的物理上联链路。
在实际布线中,Leaf 接入侧与 Spine 骨干侧的光模块选型略有不同:8卡B300节点连接Leaf全量采用 400G-SR4/VR4 原生多模光模块;Leaf与Spine互联全面采用 800G(2×400G-SR4/VR4)双通道多模光模块。所有光纤链路统一适配MPO APC 8度斜面跳线,以此达成线速抗反射直连的目的。
针对全闪存阵列高并发读写极易诱发的网络微拥塞与头部阻塞现象,本存储专网在 PFC 与 ECN 的基础之上,深度集成了博通 Tomahawk 5 芯片级动态负载均衡(Dynamic Load Balancing, DLB)硬件加速机制——以纳秒级精度动态感知多维上行链路的实时队列深度,将突发的存储大象流实施自适应路由调度,彻底粉碎了传统哈希寻址造成的链路极化瓶颈。同时,借助GPU显存直接存储 (GPUDirect Storage, GDS) 零拷贝直通架构,远端 NVMe-oF 数据流抵达节点后,依托高速外设部件互连标准交换机旁路机制与 BlueField-3 DPU 硬件卸载引擎,将海量多模态张量数据直接线速写入 8 卡 B300 节点的第五代高带宽显存 HBM3e中。
2.3 带内和带外网络设计
为了保障集群的灾难级管控与调度的高可用性,管理网统一采用基于 Broadcom 交换芯片生态的 OEM 设备来部署标准的两级 Clos 拓扑:
宿主带内管理网:全网由 66 台 Leaf 交换机(搭载博通 Trident 3 / TD3 核心芯片的 48×25G + 8×100G交换机)与 8 台 Spine 交换机(搭载博通 Tomahawk 3 / TH3 核心芯片的64×100G交换机)构建而成。
运维底座带外网:全网由 64 台 Leaf 交换机(搭载博通 StrataXGS Hurricane 核心芯片的 48×1G + 4×10G 交换机)与 8 台 Spine 交换机(搭载博通 Trident 3 / TD3 核心芯片的 48×25G + 8×100G 交换机)构建而成。
三、核心设备配置清单
以下为 1536 节点(12288 张 GPU)计算网络、存储网络、带内管理网络、带外管理的设备物料清单:
网络平面 | 设备角色 | 核心规格参数 | 数量 |
|---|---|---|---|
计算网络 | Leaf | NVIDIA Spectrum-4 (SN5600) 64×800G | 384 台 |
计算网络 | Spine | NVIDIA Spectrum-4 (SN5600) 64×800G | 384 台 |
计算网络 | Super-spine | NVIDIA Spectrum-4 (SN5600) 64×800G | 224 台 |
计算网络 | 多模光模块 | 800G (2×400G-SR4/VR4) | 24,576 个 |
计算网络 | 多模光纤 | MPO APC (Base-8) 高密跳线 | 24,576 根 |
计算网络 | 多模光模块 | 800G (2×400G-SR4/VR4) | 24,576 个 |
计算网络 | 多模光纤 | 2×MPO APC (Base-8) 多模线缆 | 12,288 根 |
计算网络 | 单模光模块 | 800G (2×400G-DR4) 单模硅光 | 24,192 个 |
计算网络 | 单模光纤 | 2×MPO APC (Base-8) 单模长距光缆 | 12,096 根 |
存储网络 | Leaf | Broadcom TH5 51.2T OEM 交换机 (逻辑切分为 128×400G) | 54 台 |
存储网络 | Spine | Broadcom TH5 51.2T OEM 交换机 (逻辑切分为 128×400G) | 32 台 |
存储网络 | 多模光模块 | 400G-SR4/VR4 原生多模 | 6,144 个 |
存储网络 | 多模光纤 | MPO APC (Base-8) 多模跳线 | 3,072 根 |
存储网络 | 多模光模块 | 800G (2×400G-SR4/VR4) 双通道 | 3,456 个 |
存储网络 | 多模光纤 | 2×MPO APC (Base-8) 多模线缆 | 1,728 根 |
带内管理 | Leaf | 搭载Broadcom TD3 核心芯片的48×25G + 8×100G | 66 台 |
带内管理 | Spine | 搭载Broadcom TH3 核心芯片的64×100G | 8 台 |
带内管理 | 多模光模块 | 100G QSFP28 模块 | 1,056 个 |
带内管理 | 多模光纤 | MPO / LC 多模跳线,适用于带内100G 上行链路 | 528 根 |
带外管理 | Leaf | 搭载Broadcom Hurricane 芯片的48×1G + 4×10G | 64 台 |
带外管理 | Spine | 搭载Broadcom TD3 核心芯片的48×25G + 8×100G | 8 台 |
带外管理 | 多模光模块 | 10G SFP+ 光模块 | 512 个 |
带外管理 | 多模光纤 | LC-LC 多模双芯跳线 | 256 根 |
四、后续拓展演进方案
面向未来十万卡级别的超大规模集群扩容,底层网络架构主要考虑最新一代 102.4T 芯片技术趋势与 CPO/LPO 光电协同封装技术的演进路径:
4.1 英伟达 102.4T与 CPO 演进
随着 NVIDIA ConnectX-8 网卡底层固件与驱动体系的全面成熟,计算网络将摒弃当前的 400G Breakout 拆分方案,单口全面释放原生 800G 吞吐能力。在交换机侧(Leaf/Spine)全面升级至英伟达最新一代拥有102.4T 交换容量的 Spectrum-6 平台(典型如 Spectrum SN6810,单机提供 128×800G 端口),方案带来的可见演进红利是:
首先,Spectrum-X Photonics (CPO) 光电共封装技术带来的能效跃升:CPO彻底摒弃传统的可插拔光模块,选择将电光转换引擎直接与 Spectrum-6 ASIC 封装在同一基板上;正是由于光纤直达芯片边缘让高频电信号传输损耗降至极限的 ~4dB,单端口功耗骤降至 9W,进而将整体光互联能耗削减近 70%。
再来看两层CLOS 拓扑对三层CLOS架构的扁平化重构:得益于 102.4T 交换机翻倍的高基数(128×800G 端口)端口密度,在承载当前的 12288 卡集群规模时,网络拓扑可直接从“三层 Clos”扁平化为“两层 Clos”架构,也就是说,这种极简组网不仅彻底消除Core交换机(224台),更绝的是还将跨 POD 的 All-to-All 集合通信跃点数减少了一半,进而驱动纳秒级尾部延迟的断崖式下降。

Spectrum-6 Ethernet Switch
4.2 博通 51.2T+ LPO 光模块组合
此外,计算网络亦可另辟蹊径,计算网络引入基于Broadcom Tomahawk 5 (TH5)核心交换芯片的 51.2T OEM 交换机(如锐捷网络 RG-S6900 系列等),与之配套部署 400G/800G LPO光模块,该方案的工程价值在于:能够在保持现有1,536 节点“双平面轨道优化”三层 Clos 拓扑架构以及物理布线完全不变的前提下,无缝达成底层核心交换芯片的平滑交替与架构归一。
得益于 LPO 光模块去除了内部功耗极高、重定时开销极大的 DSP 芯片,单路光链路功耗与时延双双实现颠覆性优化(参考光为科技的 LPO 模块实测数据为例:400G VR4 LPO 功耗较 DSP 方案下降 70%,800G DR4 LPO 功耗节省高达 75%的电能,尤为关键的是数据处理时延从传统 DSP 的 80-120ns 断崖式缩减至仅仅 5-10ns),这无疑能为智算集群注入极致的 TCO 收益与纳秒级通信表现助力。
4.3 博通 102.4TCPO演进方案
在拓扑演进层面,计算网络计划引入博通 Tomahawk 6 (TH6) 102.4T OEM 设备(如锐捷 S6990 系列交换机)。依托单芯片 102.4T 交换容量,在承载相同规模(1536 节点、12,288 张 B300 卡)集群时,网络仅需搭建极简两层 CLOS 架构即可线速落地万卡集群。更进一步来看,方案将深度联动 TH6 特有的全局认知路由与动态负载均衡硬件级加速机制,促使底层网络具备包级(Packet)动态喷洒能力,在极度扁平的拓扑内精准规避由局部哈希极化造成的链路长尾延迟。此外,该演进路线也能够充分发挥以太网的开放生态优势,借助 ESUN 最终达成低碳绿色能效技术与高可靠高性能计算网络的深层次交融。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号