Cell Syst. | 机器学习辅助的细胞表面抗原高通量抗体发现

Cell Syst. | 机器学习辅助的细胞表面抗原高通量抗体发现

DrugAI
发布于 2026-06-29 13:45:38
发布于 2026-06-29 13:45:38
机器学习有潜力改变抗体设计与筛选流程,但其成功高度依赖经过良好整理的抗体–抗原相互作用数据集。研究人员开发了一种合成 Fab 酵母展示文库,使其能够与机器学习流程无缝衔接,并重点将序列多样性集中在重链互补决定区 CDRH3 环上。该文库从人类 B 细胞抗体库中提取关键序列特征,并将其压缩到一种紧凑的抗原识别模块格式中。该文库以 VH1-69 重链和四种轻链为基础,针对十种人源和小鼠细胞表面抗原进行评估,其中包括 PD-L1、TIGIT 和 ROBO1 等靶点。该方法获得了数百个具有良好生物物理性质的抗体,其中部分抗体通过流式细胞术和免疫组织化学得到验证。此外,研究人员还利用机器学习从汇总测序数据中识别出针对 ROBO2 和 PD-L2 的额外抗体。该公开数据集建立了一个适用于机器学习的框架,旨在加速并简化抗体发现与开发流程。

抗体展示技术为发现高质量抗体提供了重要替代路径,其获得的抗体在某些情况下能够与来自患者或动物免疫的单克隆抗体相媲美。在这类技术中,研究人员可以在酵母细胞或噬菌体等生物载体上展示大量候选结合分子,并通过分子生物学方法控制文库组成,使这些候选分子暴露于目标抗原并接受筛选。
纯合成展示文库的优势在于流程可控、稳定且可重复,这非常适合构建机器学习辅助的“计算—实验”混合抗体发现体系。与依赖特定物种免疫的传统方法相比,合成文库还能够更好地发现针对高度保守抗原的抗体,例如神经系统和发育过程中涉及的蛋白,这些靶点往往难以通过传统单克隆抗体方法获得理想试剂。然而,当前用于治疗性抗体开发的先进展示文库通常依赖患者或动物来源的复杂 CDR 组合,并结合多种筛选技术。这种复杂性虽然可以扩大抗体空间,但也会使数据结构不够简洁,从而增加构建大型机器学习模型训练数据集的难度。
在天然免疫识别中,重链 CDRH3 环通常对抗原特异性识别具有关键作用,是抗体结合表位的重要核心区域。因此,如果将抗体互补位的主要序列空间从六个 CDR 缩小到 CDRH3,就可以显著约束抗原–抗体相互作用语言,使其更适合计算建模和机器学习分析。已有一些合成文库尝试只在 CDRH3 区域引入多样性,但许多方法使用固定的随机氨基酸频率。这类随机序列容易引入导致多反应性、聚集或降解的氨基酸基序,而这些不良基序在天然免疫系统中通常会被 B 细胞选择过程清除。
为解决这一问题,研究人员构建了一种合成 Fab 酵母展示文库。该文库在 CDRH3 区域引入来自初始 B 细胞抗体库的位置特异性氨基酸频率,同时去除可能导致抗体聚集和多反应性的不良氨基酸基序。CDRH3 序列后接一个核苷酸层面的条形码,用于追踪轻链配对;二者共同构成抗体的抗原识别模块,也就是 ARM。由于 ARM 被编码为一段短核苷酸序列,因此非常适合深度测序,并可作为抗体互补位的紧凑表示。研究人员进一步将该 Fab 文库用于十种具有生物学和治疗价值的细胞表面抗原筛选,并结合大规模下一代测序数据和机器学习,探索低频但功能良好的 Fab 克隆,从而建立一种面向机器学习的高通量抗体发现框架。
方法
研究人员首先根据人类初始 B 细胞抗体库设计 CDRH3 序列空间,并去除与多反应性、聚集或化学不稳定性相关的不良基序。随后,研究人员以 VH1-69 重链作为固定分子支架,搭配四种轻链,构建带有紧凑 ARM 的合成 Fab 酵母展示文库。文库通过磁珠分选和多轮流式分选针对十种细胞表面糖蛋白抗原进行筛选,并在每一轮筛选后对 ARM 区域进行深度测序,以追踪候选 Fab 克隆的富集变化。研究人员根据 CDRH3 序列聚类选择代表性克隆,重组表达为 IgG1 或兔嵌合抗体,并通过尺寸排阻色谱、多特异性反应检测、表面等离子体共振、细胞展示滴定、流式细胞术、免疫组织化学和表位分箱等方法评估其表达、稳定性、特异性、亲和力、交叉反应性与实际应用潜力。对于实验筛选中被低估或丢失的克隆,研究人员进一步利用基于 k-mer 特征的逻辑回归模型,从早期分选轮次的深度测序数据中重新识别潜在功能性抗体。
结果
ARM 的设计与序列分析
为了建立适合高通量抗体发现和机器学习分析的平台,研究人员开发了一个最小化合成 Fab 文库。该文库的核心是 ARM,即抗原识别模块。ARM 是一段短核苷酸序列,覆盖重链 CDRH3 区域及其邻近框架区,并在其后加入轻链条形码,用于追踪不同重链与轻链的配对关系。由于这一模块长度较短,能够通过深度测序高效读取,因此可以作为抗体识别特征的简洁编码。
研究人员分别为不同长度的 CDRH3 设计寡核苷酸池,覆盖 11 到 17 个残基的长度范围。每个位置的氨基酸频率来自 Observed Antibody Space 数据库中的大量初始 B 细胞 CDRH3 序列。研究人员还调整了不同 CDRH3 长度的比例,以避免某些长度被过度或不足采样。此外,研究人员有意排除了半胱氨酸、甲硫氨酸以及与不良生物物理和化学性质相关的氨基酸基序,从而减少抗体聚集、多反应性和异质性风险。
该文库以 VH1-69 重链胚系序列作为分子支架。VH1-69 是常见的人类抗体重链胚系,在治疗性抗体和广谱中和抗体中均有较好代表性。研究人员还选择了四种轻链与其配对,其中 VK1-39、VK3-15 和 VK3-20 形成相对平坦的互补位表面,而 VK4-1 具有较长的 CDRL1 环,能够形成更凹陷的互补位,从而可能识别不同类型的表位,例如肽类表位。
深度测序显示,在两个 VH1-69 子文库中共检测到大量独特 CDRH3 序列,且没有明显优势克隆。根据稀释曲线估计,每个子文库都具有极高分子多样性;由于总共构建了四个子文库,整个 VH1-69 文库的真实分子多样性接近十亿个独特 Fab。序列比较显示,不同子文库之间的 CDRH3 重叠较低,说明各子文库可以独立贡献多样性。进一步分析表明,ARM 文库的氨基酸频率总体上能够较好地再现天然初始 B 细胞库的特征,同时显著减少不良氨基酸基序。k-mer 使用模式也与天然初始 B 细胞 CDRH3 序列高度相关,说明该设计既保留了天然抗体库的序列规律,又增强了文库的可开发性。
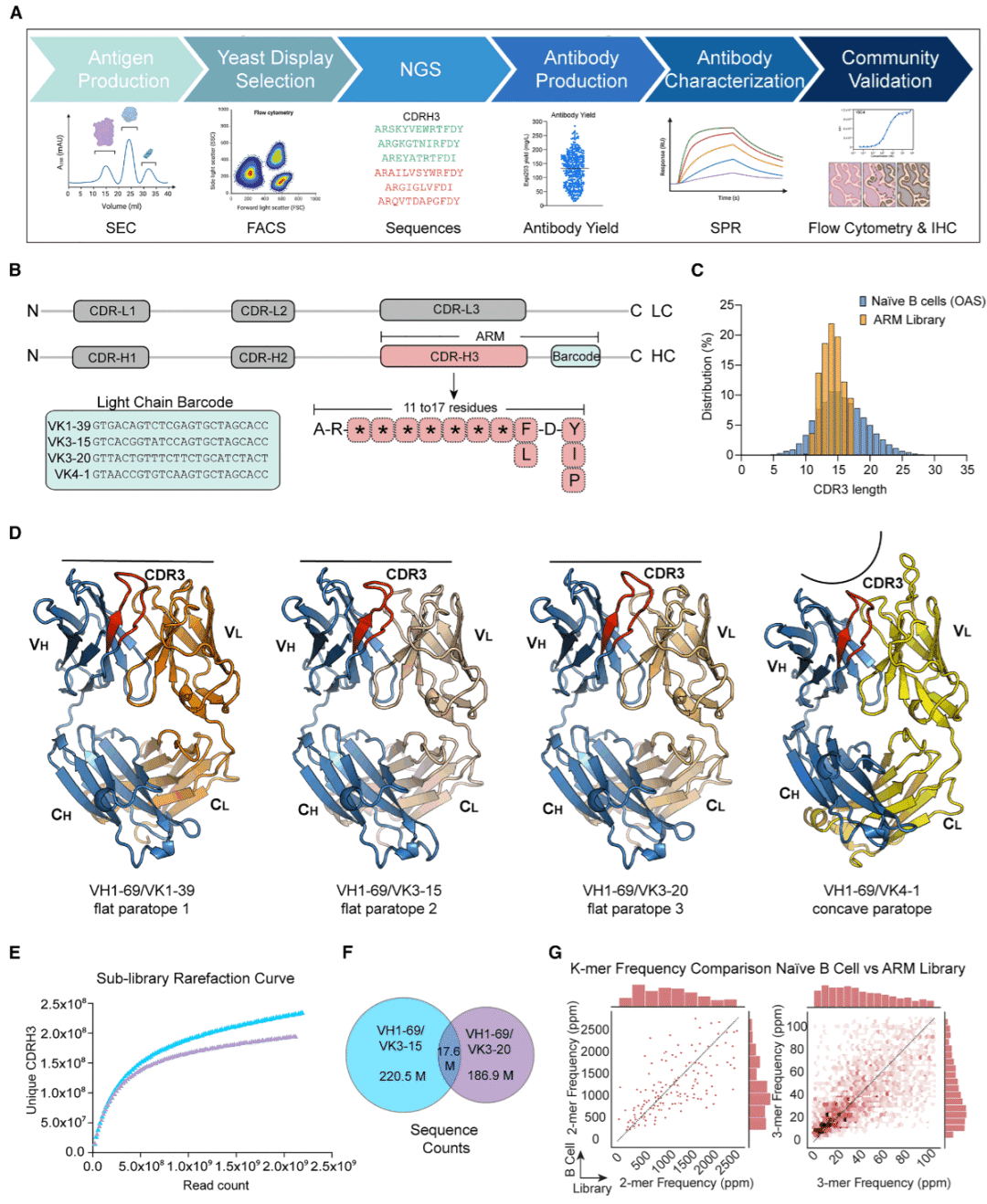
图1:用于 Fab 酵母展示的 ARM 文库构建。
高通量抗体发现流程为十个靶点产生试剂级和治疗先导级抗体
为检验最小化 Fab 文库是否能够针对多样化抗原产生有效抗体,研究人员并行开展了一次针对十种细胞表面靶点的抗体发现活动。这些靶点包括免疫检查点相关蛋白 PD-L1、PD-L2 和 TIGIT,脂蛋白相关受体 LOX1,Wnt 信号拮抗因子 DKK1,细胞因子受体 IL-23R,神经系统相关受体 DCC、ROBO1 和 ROBO2,以及人类病毒融合样蛋白 syncytin-2。这些抗原在大小、序列相似性和结构类型上差异明显,因此能够较全面地挑战文库的适用范围。
研究人员分别对三种平坦互补位轻链组合和 VK4-1 凹陷互补位组合进行筛选,以评估互补位整体形状是否会影响 Fab 选择。筛选流程包括一轮磁珠分选和三轮流式分选,并在筛选过程中逐渐降低抗原浓度,以富集更强结合的 Fab 展示酵母群体。每轮筛选后,研究人员都会扩增并测序 ARM 区域,从而追踪不同 CDRH3 克隆在筛选过程中的富集情况。
根据最终流式分选轮次中最频繁出现的 ARM 序列,研究人员对 CDRH3 序列进行聚类,并为每个选定聚类订购代表性重链合成基因。由于每个插入片段长度较短,这种策略具有较好的成本效率。研究人员共订购 429 条重链,并将其与对应轻链共表达,最终获得 424 个具有足够产量的抗体。尺寸排阻色谱显示,其中 301 个抗体没有明显聚集或降解;多特异性反应检测显示,354 个抗体没有对亲和素、DNA、胰岛素或昆虫细胞膜制备物产生非特异反应;综合两项检测,共有 285 个抗体通过质量控制。
研究人员进一步通过高通量表面等离子体共振测定结合动力学,并使用细胞展示实验测量抗体对完整抗原胞外结构域的结合效力。许多通过完整性和多反应性测试的抗体表现出良好动力学和较高细胞结合效力,其中一批抗体达到可作为试剂抗体或治疗性先导分子的水平。针对 TIGIT 和 LOX1 的优选抗体在流式细胞术应用中表现出与商业抗体相当的效力。针对 ROBO1、ROBO2 和 syncytin-2 的代表性抗体还显示出较高热稳定性,表现可与成熟治疗性抗体相媲美。
ROBO1 和 ROBO2 是轴突导向受体,当前可用于免疫组织化学的高质量抗体较少。虽然筛选抗原为人源 ROBO1 和 ROBO2,但细胞展示实验显示部分抗体对小鼠同源蛋白也具有强交叉反应。研究人员将优选 ROBO 抗体转换为带兔恒定区的嵌合抗体格式,以便更适合组织染色应用。小鼠胚胎脊髓和端脑组织切片染色结果显示,这些 ROBO1 和 ROBO2 抗体能够产生清晰的免疫染色模式,并与已验证商业抗体的染色结果相似。这表明该最小化 Fab 文库不仅能产生结合抗体,也能产生适合实际生物学实验使用的高质量试剂抗体。
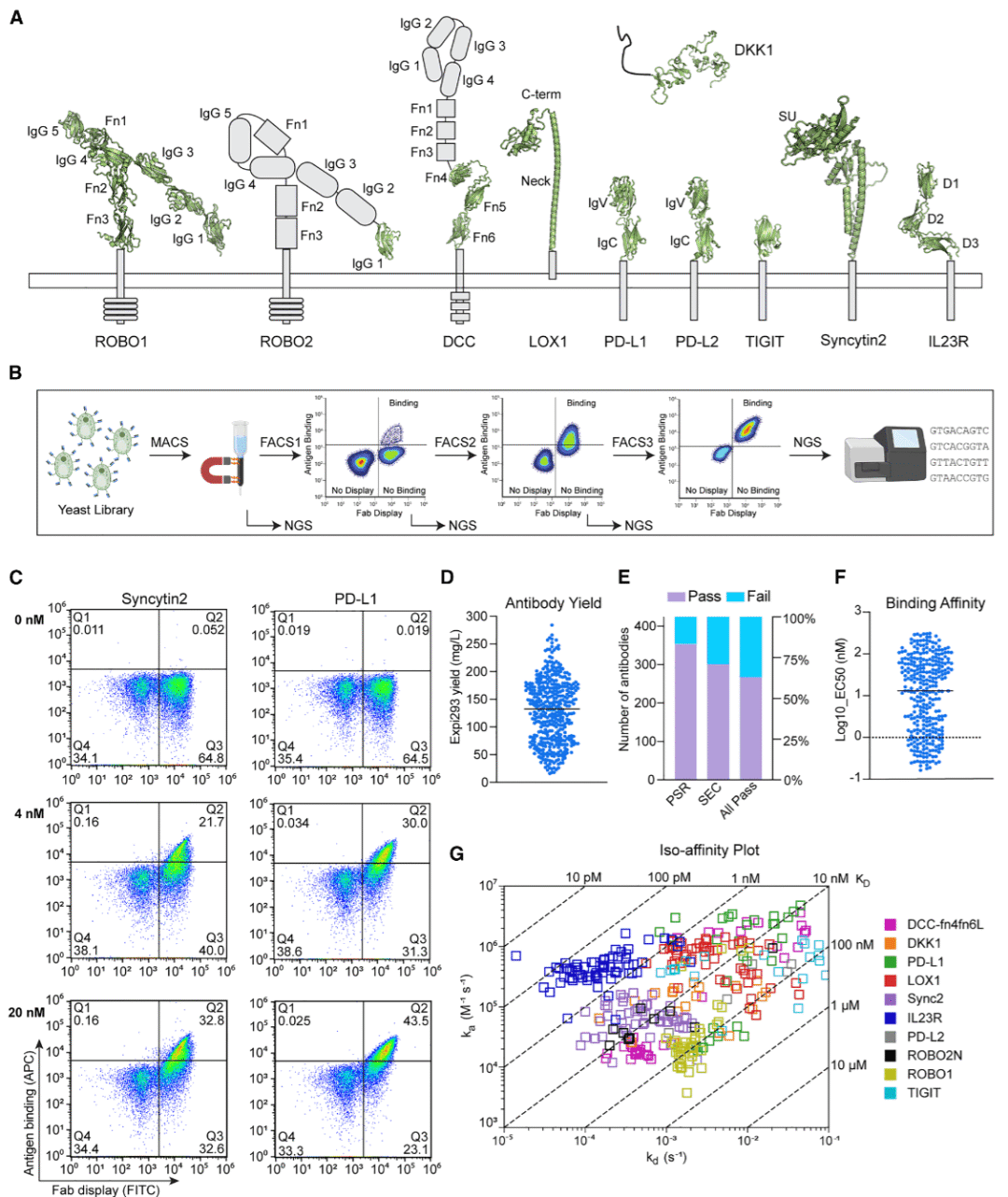
图2:针对十种细胞表面糖蛋白的抗体发现活动。
深度测序分析显示 ARM 文库具有稳健性和特异性
深度测序揭示了多个显著富集的相关 ARM 序列聚类。研究人员发现,在同一抗原筛选过程中,许多相关 CDRH3 序列会独立富集,并形成具有共同识别模式的序列家族。例如,IL-23R 的一个富集聚类在 CDRH3 环的基部显示出较高序列一致性,而在环顶部保留一定变异,说明文库中存在多个相似但不完全相同的功能性结合模式。
对于高度同源的 ROBO1 和 ROBO2N,研究人员在独立筛选中观察到几乎相同的 ARM 序列聚类。这说明当两个抗原共享高度保守表位时,文库能够收敛到相似的抗体识别模式。与此同时,针对不同抗原的筛选结果也显示出明显特异性。随着筛选轮次推进,十个抗原中的 CDRH3 聚类数量从第一轮流式分选中的大量候选逐步减少到第三轮中的约百级规模,而每个聚类所包含的相关 CDRH3 序列数量增加。这表明筛选过程并非简单随机放大少数克隆,而是在抗原驱动下富集结构相关的识别模式。
研究人员还分析了不同抗原筛选活动之间的 CDRH3 序列相似性。对于未经筛选的随机 CDRH3 序列,不同序列之间的归一化汉明距离通常较高;对于来自无关抗原的抗体,序列距离也同样较高。PD-L1 和 PD-L2 虽然结构相似,但外结构域序列相似性有限,且表面缺少保守表位斑块,因此二者筛选得到的 CDRH3 序列几乎没有重叠。相比之下,ROBO1 和 ROBO2N 在重叠表位区域具有很高序列相似性,因此筛选出的部分 CDRH3 聚类也存在明显相关性。
这些结果说明,ARM 文库能够根据抗原表面特征产生可重复、稳健且具有抗原驱动性的序列富集。对于高度同源抗原,它可以产生交叉反应性抗体;对于差异较大的抗原,它又能维持互补位序列的特异性。这种特性使该文库特别适合为机器学习提供结构化、可解释、可追踪的抗体–抗原互作数据。
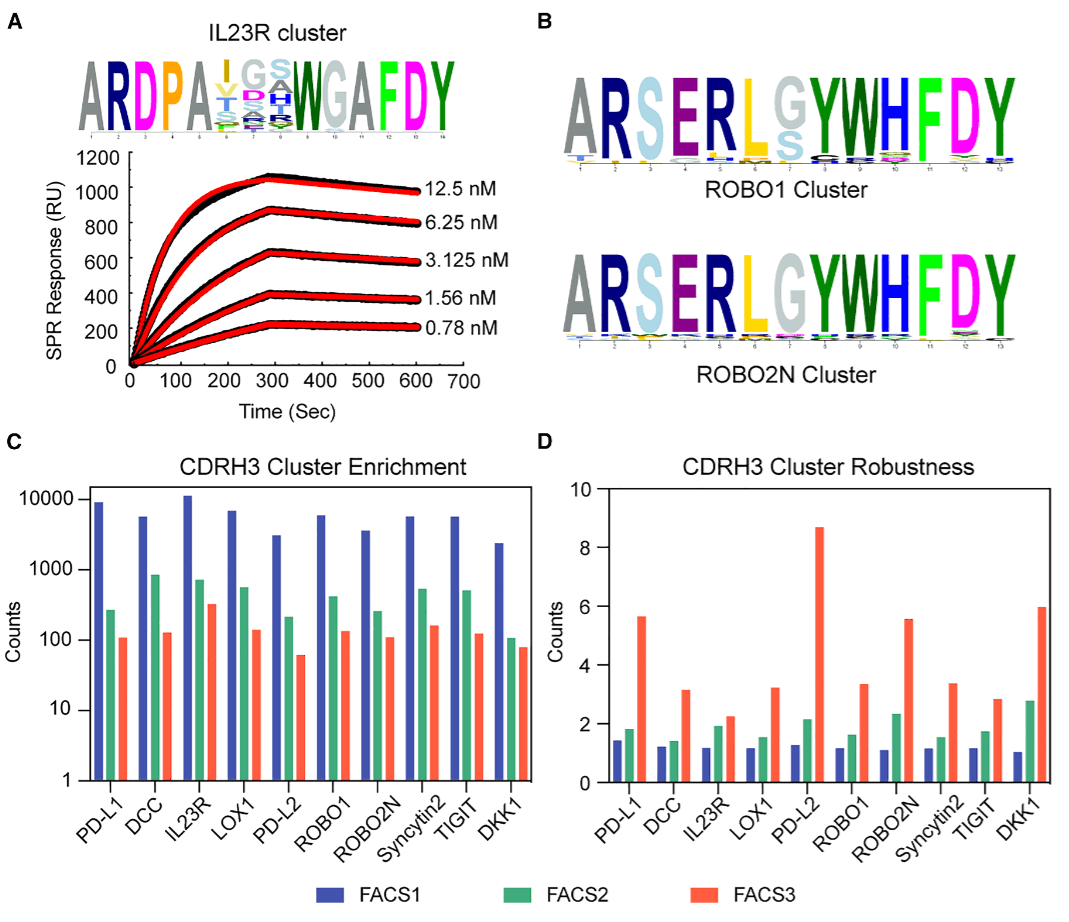
图3:抗原驱动的序列富集显示稳健且独特的 CDRH3 序列模式。
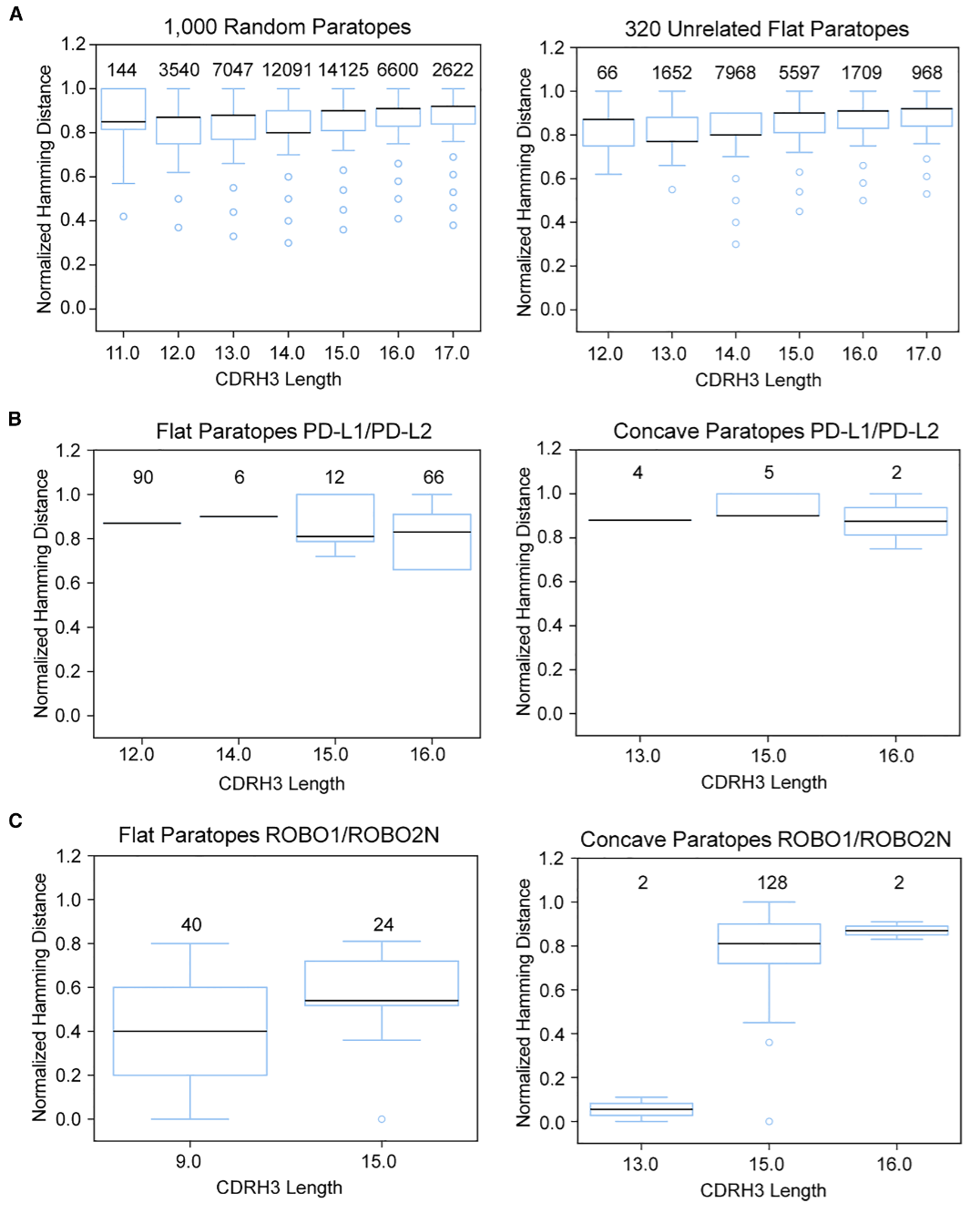
图4:使用归一化汉明距离评估不同抗体筛选活动之间的序列多样性。
利用早期筛选多样性和机器学习发现额外抗体
尽管多轮细胞分选可以富集结合抗体,但它并不是完美过程。某些克隆可能因为展示效率、轻重链配对、酵母增殖速率或筛选动力学等因素,在后续轮次中被低估甚至丢失。研究人员在 ROBO2N 筛选中观察到,最终流式分选轮次被一个优势克隆主导,而早期轮次中仍然包含丰富的 ARM 多样性。因此,研究人员尝试利用机器学习从早期分选数据中重新挖掘潜在结合抗体。
研究人员针对 ROBO2N 数据集训练逻辑回归模型。该模型使用 ARM 序列中的 k-mer 频率作为特征,并根据第一轮流式分选相对于磁珠分选的富集情况,将序列分为富集和未富集两类。研究人员比较不同正则化策略,并用训练集、测试集和第三轮流式分选数据进行评估。随后,研究人员对第一轮流式分选中具有足够计数的 1,909 个 ROBO2N ARM 进行评分,从中选择了 29 个机器学习高评分、但在后续分选中被耗竭或忽略的 ARM 序列。
为了保证这些候选序列与已实验订购的 ROBO1 或 ROBO2N 抗体足够不同,研究人员要求它们与既有抗体序列保持足够编辑距离。随后,研究人员将这些机器学习筛选出的 ARM 转换为带兔恒定区的抗体,并通过表面等离子体共振和细胞展示检测其结合性质。结果显示,排名靠前的机器学习抗体中大部分具有较强结合动力学,且其解离表现优于实验筛选中占优势的短 CDRH3 克隆。细胞展示滴定进一步确认有多个机器学习抗体能够结合 ROBO2。由于 ROBO1 和 ROBO2N 之间高度相似,这些机器学习抗体也表现出对 ROBO1 的交叉反应,但没有观察到对 PD-L1、PD-L2、DCC 和 LOX1 等阴性对照抗原的非目标交叉反应。
研究人员进一步通过表面等离子体共振进行 ROBO1 和 ROBO2N 抗体的表位分箱。结果显示,ROBO1 抗体可分为多个表位箱,其中一个主导表位箱包含大量抗体,说明这些抗体集中识别同一区域;ROBO2N 抗体同样存在一个主导表位箱,并由多个周边较小表位箱环绕。值得注意的是,两个机器学习发现的 ROBO2N 抗体可以彼此同时结合,说明它们识别的是不同表位,从而扩展了实验筛选获得的表位空间。
为了测试模型是否能跨相似抗原预测结合模式,研究人员将基于 ROBO2N 训练的逻辑回归模型用于给 ROBO1 抗体打分。结果表明,识别 ROBO1 N 端共享表位的抗体通常获得较高模型分数,而识别其他区域或未能结合靶标的抗体得分较低。这说明该评分方法不仅能从早期筛选中抢救被忽略的克隆,也能在相似抗原旁系同源物之间预测共享表位相关的结合模式。
研究人员还将这一“计算—实验”混合策略应用于 PD-L2。PD-L2 的原始实验筛选只得到少数良好结合抗体,且假阳性率较高。通过逻辑回归模型,研究人员从早期分选数据中选择了新的 ARM 序列,并发现其中相当一部分抗体在细胞展示中具有可比较的结合效力,虽然其表面等离子体共振表现相对较弱。总体而言,ROBO2N 和 PD-L2 的结果证明,深度测序产生的 ARM 数据集中包含大量未被传统分选流程充分利用的信息,机器学习可以帮助恢复这些隐藏候选。
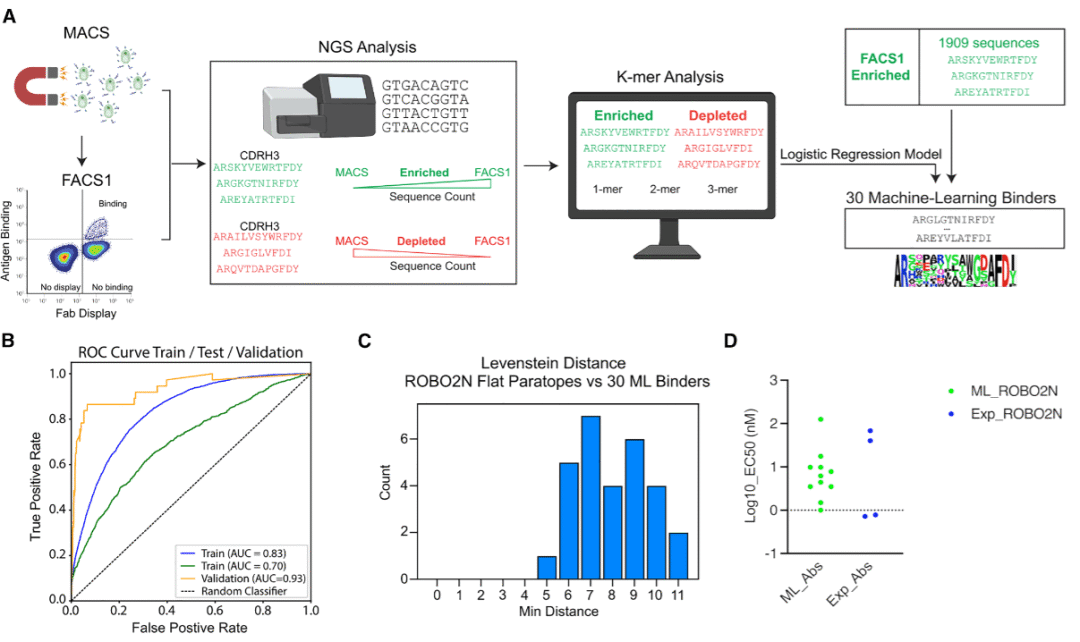
图5:逻辑回归模型从早期分选群体中抢救被动力学细胞分选丢失的 ROBO2N 结合抗体。
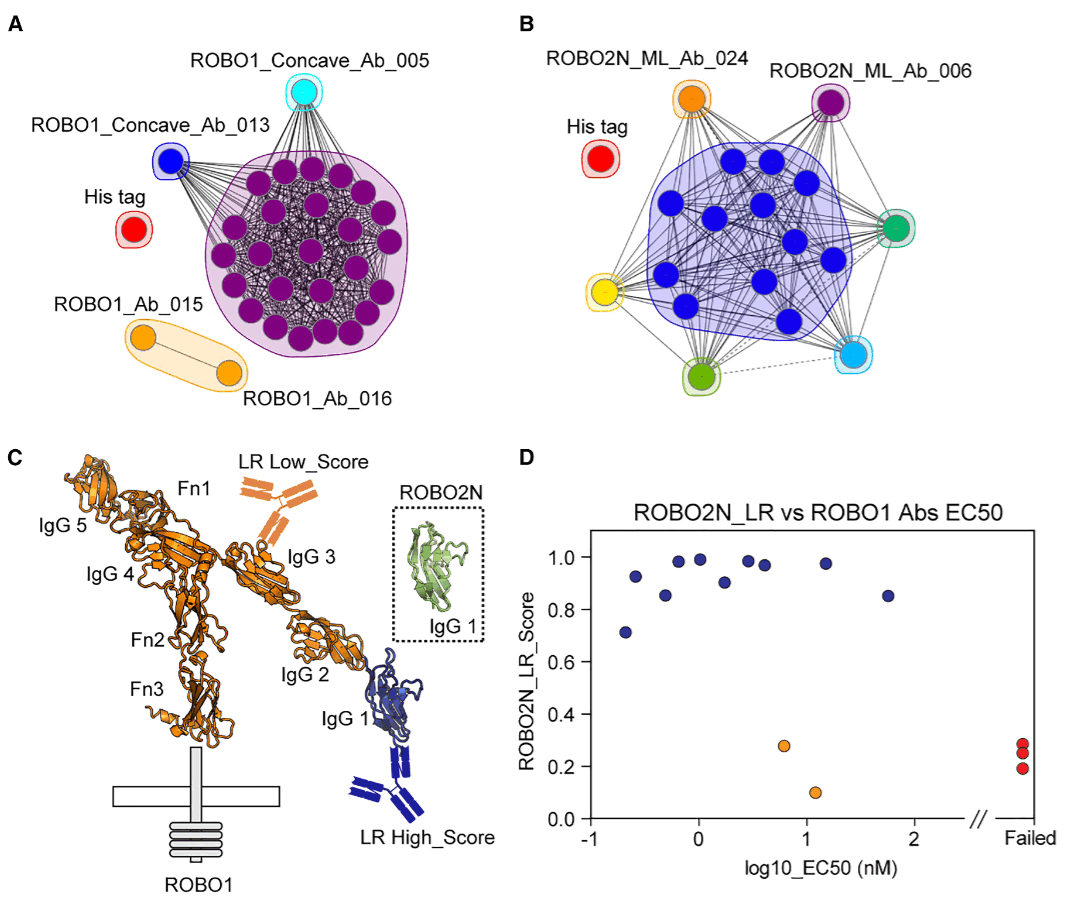
图6:利用逻辑回归模型进行交叉反应抗体的表位分箱与评分。
讨论
机器学习已经推动了蛋白质复合物预测和蛋白质相互作用建模的发展,但许多方法仍依赖深度序列比对、已有三维结构或丰富的界面信息。对于抗体–抗原相互作用而言,真正从头预测特异性抗体仍然困难,尤其是在缺少高质量结构数据和大规模实验互作数据的情况下。合成抗体文库有潜力为机器学习生成系统化数据集,但以往文库通常覆盖多个 CDR 区域,序列空间过于复杂,不利于建立紧凑、可追踪、可学习的抗体表示。
研究人员提出的 ARM 文库通过将主要多样性集中在 CDRH3 区域,大幅压缩了抗体互补位序列空间。由于 ARM 同时包含 CDRH3 和轻链条形码,它可以以短序列形式编码抗原结合特征,便于深度测序、聚类分析和机器学习建模。研究人员在十种不同细胞表面抗原上并行测试该文库,结果显示多数抗体来自相关氨基酸序列聚类,而每个抗原又产生独特的互补位模式。这表明文库既具有筛选稳健性,也能够产生抗原特异性识别模式。
研究人员也指出,细胞分选本身存在局限。尽管多轮筛选能够产生大量候选抗体,但克隆多样性会在筛选过程中丢失,而最终富集的克隆并不一定总是最优结合抗体。ROBO2N 和 PD-L2 的结果说明,早期分选轮次中保留了大量有价值的信息。通过逻辑回归模型,研究人员能够从这些早期深度测序数据中重新发现被传统实验流程忽略的功能性抗体。这种混合式策略缓解了酵母展示中克隆丢失和富集偏倚的问题,使低丰度但有潜力的抗体也能进入后续验证流程。
表位分箱实验进一步揭示,ROBO1 和 ROBO2N 上存在抗体识别热点,多数抗体集中于相近表位区域,以至于不同抗体之间会因空间位阻而互相竞争。这可能反映了抗原本身存在优势可结合表面,也可能与文库设计中只主要改变 CDRH3、固定 CDR1 和 CDR2 有关。也就是说,最小化文库提高了机器学习友好性和筛选可控性,但也限制了那些依赖其他 CDR 区域多样性的互补位类型。未来如果要覆盖更广泛的表位空间,可能需要引入更多重链和轻链支架,或在保持可学习性的同时扩展其他 CDR 区域的多样性。
该研究的一个重要贡献是公开了大规模下一代测序数据和数百个抗体的实验表征结果。这些数据不仅可用于当前的抗体筛选,也可支持未来开发计算表位分箱、亲和力成熟、抗体排序和零样本抗体发现模型。随着更多抗原、更多支架和更多实验标签被纳入,类似 ARM 的紧凑抗体表示有望成为机器学习抗体发现的重要数据接口。
总体而言,研究人员建立了一种可扩展的高通量抗体发现框架,将合成 Fab 酵母展示、深度测序、抗体生物物理表征和机器学习筛选整合在一起。该方法能够针对多种细胞表面抗原快速产生具有良好性质的抗体,并利用机器学习从实验筛选遗漏的低频序列中发现额外功能性抗体。这项工作为抗体发现从单纯实验筛选走向“实验—计算闭环”的混合模式提供了一个可操作范式,也为未来面向大规模抗体设计模型的数据集建设奠定了基础。
整理 | DrugOne团队
参考资料
Kothiwal D, Kollasch A, Anuganti M ...
High-throughput machine learning-aided antibody discovery for cell surface antigens
Cell Systems, 2026
https://doi.org/10.1016/j.cels.2026.101645

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号